阿里RAG新框架R4性能超越Self-RAG --知识铺
大型语言模型(LLMs)在生成文本时,可能会遇到所谓的“幻觉”问题。这种问题指的是模型生成的信息与现实不符,导致错误信息的产生。尽管通过检索外部数据的方式可以减少这种幻觉,但现有方法往往忽视了检索文档与LLMs之间在细粒度结构语义交互上的重要性,尤其是在处理长文档时,这种交互对提高回答的准确性尤为关键。 目前,存在几种不同的检索增强方法范式,其中包括传统的检索器-响应器方法和更先进的增强检索器-重排序-响应器框架。这些方法强调了学习关键检索文档的排序结构的重要性,这对于帮助LLMs更有效地处理与事实知识相关的用户查询至关重要。
检索增强方法范式
- 检索器-响应器方法:这是一种基础的范式,其中检索器负责从大量数据中检索相关信息,响应器则基于检索到的信息生成回答。
- 增强检索器-重排序-响应器框架:在这种框架中,除了基本的检索和响应过程外,还加入了重排序步骤,以优化检索到的文档的顺序,从而提高LLMs生成回答的准确性。
细粒度结构语义交互的重要性
- 长文档处理:在长文档的处理中,细粒度的语义交互可以帮助模型更准确地捕捉文档中的关键信息。
- 事实知识相关性:对于与事实知识紧密相关的查询,细粒度的语义交互有助于提高回答的准确性和可靠性。
通过这些方法,我们可以期待LLMs在生成文本时更加精确,减少错误信息的产生,从而提供更高质量的回答。
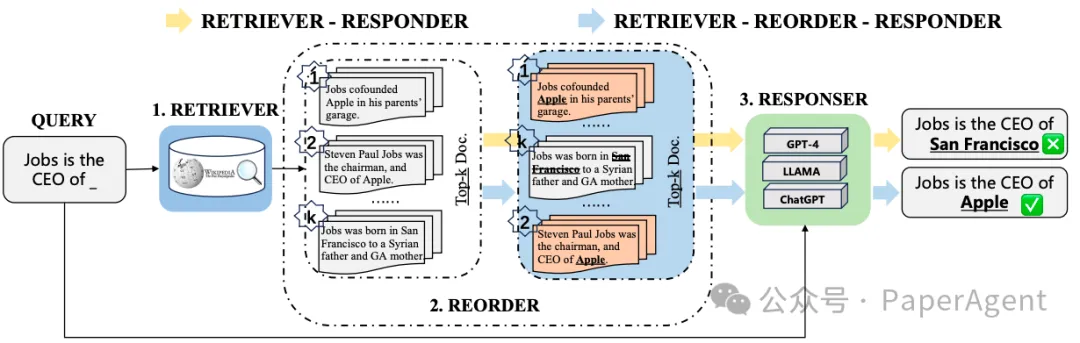
R4框架概述
R4框架,即Reinforced Retriever-Reorder-Responder(增强检索器-重排序-响应器),是一种新型的大模型框架,旨在提升信息检索和回答生成的效率与准确性。该框架由三个核心模块组成:
检索器(Retriever)
- 利用Dense Passage Retriever(DPR)技术,高效检索与查询相关的文档。
重排序器(Reorder)
- 通过图注意力学习和强化学习机制,动态调整检索到的文档顺序,以优化信息的呈现。
响应器(Responder)
- 结合查询和经过重排序的文档,生成精确且相关性强的回答。
特点分析
- 文档顺序调整:框架能够根据用户的反馈,动态调整文档在簇中的位置,以更好地满足查询需求。
- 文档表示增强:文档的表示会根据训练过程中损失函数的权重梯度进行更新,从而提高检索的准确性(建议彩色查看以获得最佳效果)。
应用场景R4框架适用于需要高效、精确信息检索和回答生成的场景,如在线客服、知识问答系统等。
技术优势
- 高效检索:DPR技术确保了检索过程的高效率。
- 智能排序:图注意力和强化学习机制使得文档排序更加智能。
- 准确回答:结合查询和优化后的文档,生成的回答更加准确和相关。
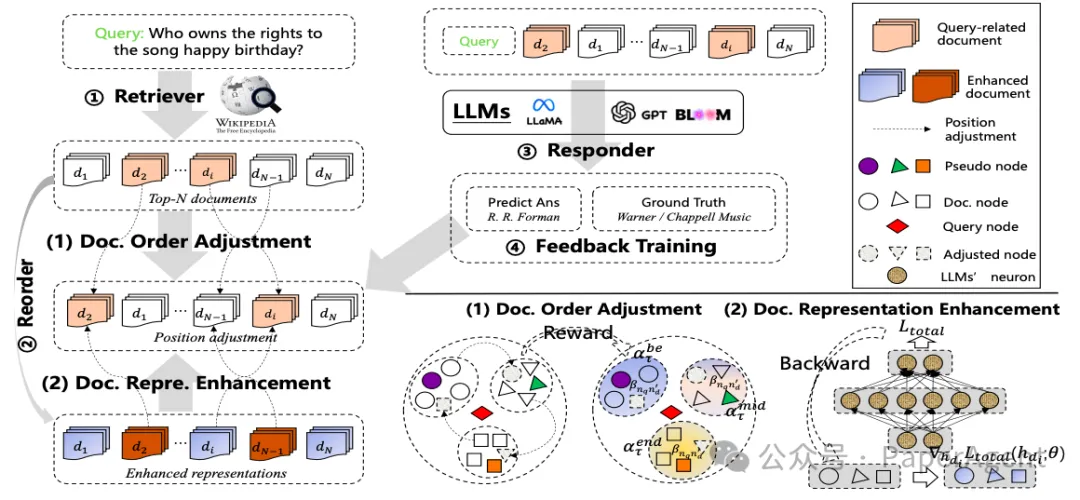
具体过程包括:
- 文档顺序调整:利用图注意力学习将检索文档动态调整到开始、中间和结束位置,以最大化回答质量的强化奖励。
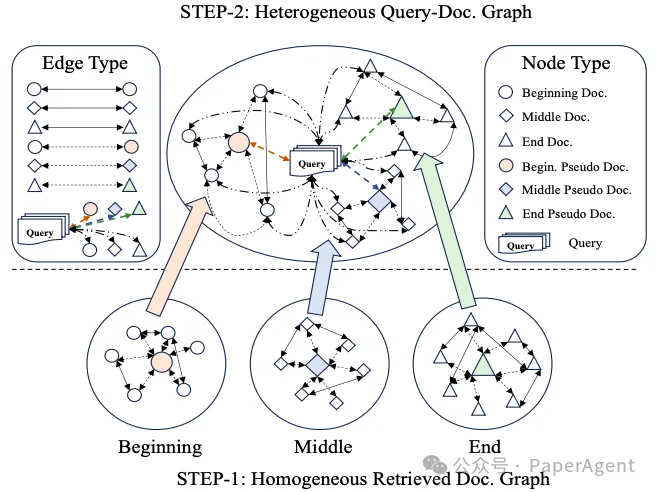
在R4框架内,查询和检索到的文档之间异构图构建过程的示意图。
文档表示增强技术概述
1. 技术背景与应用在人工智能领域,文档表示的增强技术是提升生成质量的关键。本文介绍了一种通过文档级别的梯度对抗学习来细化检索文档表示的方法。
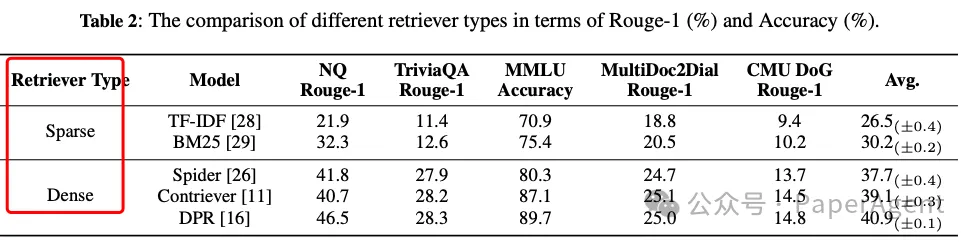
2. 实验设计与数据集实验涵盖了3类任务,并使用了5个不同的数据集,具体包括:
- 生成式问答(Generative QA)
- 多项选择问答(Multi-choice QA)
- 对话(Dialogue)
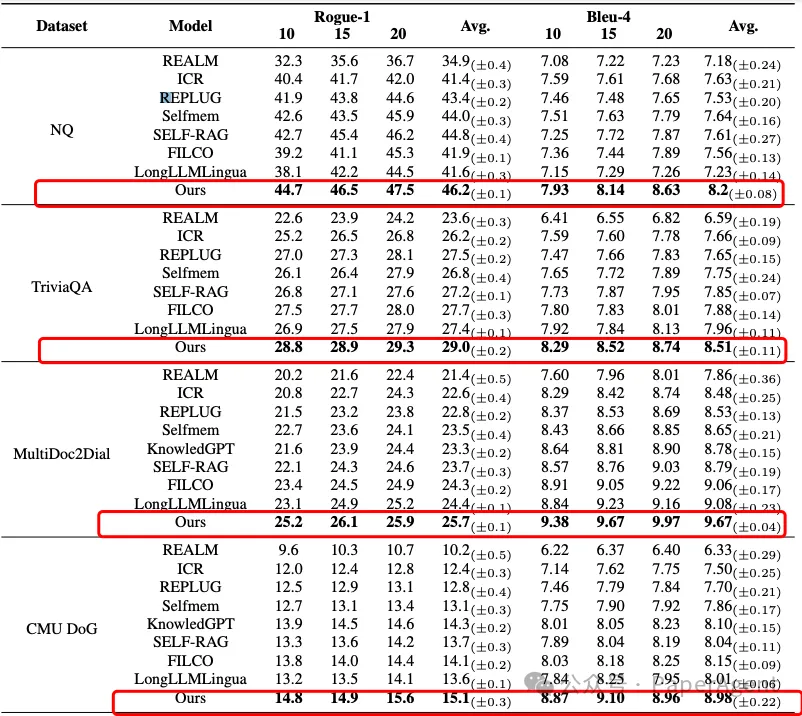
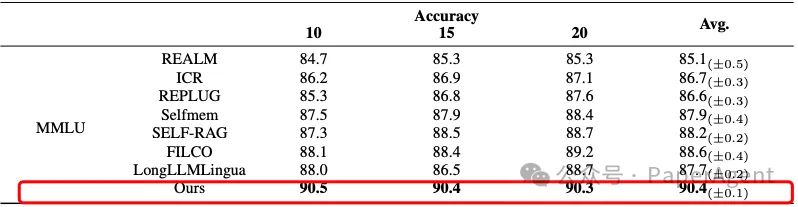
3. R4框架的性能表现R4框架在知识密集型任务上展现出卓越的性能,超越了多个基线模型,包括但不限于:
- REALM
- ICR
- REPLUG
- Selfmem
- SELF-RAG
- FILCO
- LongLLMLingu a## 4. 统计显著性分析在公共数据集上的测试结果表明,R4模型的改进在统计上是显著的。通过T检验,我们发现p值小于0.05,这进一步证明了R4模型的有效性。
5. 结论文档表示增强技术通过梯度对抗学习,显著提升了人工智能系统在问答和对话任务中的表现。R4框架的优异性能,特别是在知识密集型任务上,为未来的研究和应用提供了新的方向。
-
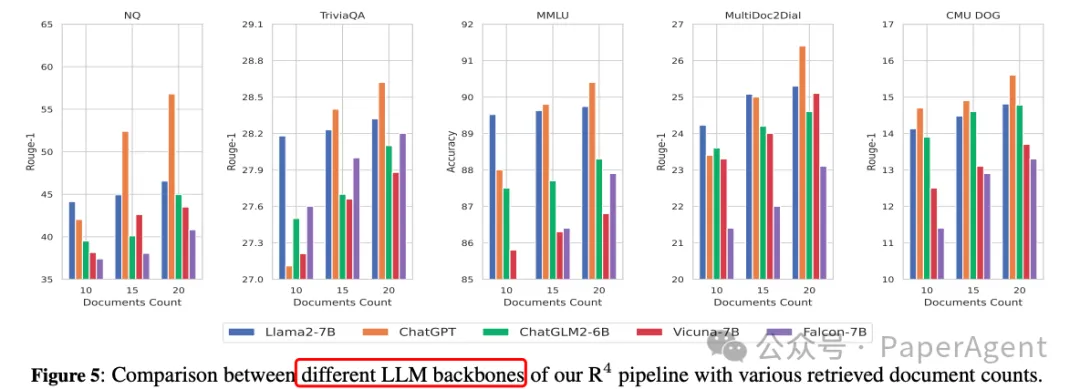
R4框架对于不同的检索器和LLMs表现出良好的适应性,证明了其在不同文档数量下的鲁棒性。
-
增加检索文档的数量(10->15->20)可以提高模型性能,但性能提升随着检索文档数量的增加而减少。
在自然语言处理领域,位置敏感性是一个重要的概念,它描述了模型在处理文本时对不同位置信息的敏感程度。以下是对上述信息的重新编写和结构化:
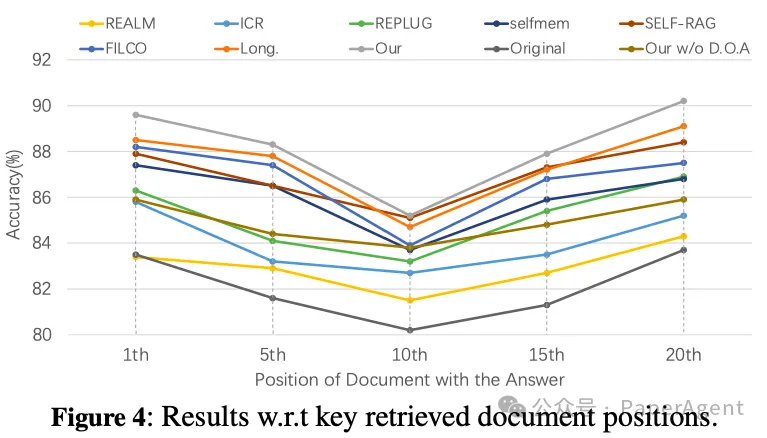
位置敏感性现象
- 在某些基线模型(如Self-RAG、REALM等)中,存在一种现象,即文本的开始和结束位置比中间位置更受模型的关注。这种现象表明,模型倾向于给予文本的首尾部分更高的权重。
R4模型的优势
- R4模型无论关键文档的初始位置如何,都能展现出稳定且强健的输出。这一点验证了一个观点:通过文档的排序和优化,可以本质上提升大型语言模型(LLMs)在RAG系统中处理用户查询的能力。
这些发现对于理解和改进自然语言处理模型具有重要意义,尤其是在提高模型对长文档的理解能力方面。
https://arxiv.org/pdf/2405.02659
推荐阅读列表
以下是为您精选的几篇深度好文,涵盖了人工智能领域的最新进展和深度解析:
- 探索了大型语言模型(LLMs)对齐算法的实证评估,包括直接偏好优化(DPO)、身份偏好优化(IPO)和卡尼曼-特沃斯基优化(KTO)。
- 分析了大模型在企业服务(ToB)领域的应用前景,Agent技术的发展,以及多模态技术的重要性。
- 讨论了基于LangChain的RAG案例在企业生产中的应用情况和面临的挑战。
- 详细介绍了从Agent到多模态Agent,再到多模态Multi-Agents系统的发展历程,以及相关的实际应用案例。
欢迎关注我的公众号“PaperAgent”,每天为您带来一篇大模型(LLM)的深度文章,通过简单的例子,探索不简单的方法,共同提升我们的思维能力。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E9%98%BF%E9%87%8CRAG%E6%96%B0%E6%A1%86%E6%9E%B6R4%E6%80%A7%E8%83%BD%E8%B6%85%E8%B6%8ASelf-RAG--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


