基于语义搜索的大模型QA系统生产落地方案 --知识铺
自助客服系统的革新:大模型QA系统
概述传统的问答(QA)系统多依赖于关键词检索,这在用户体验上存在一定的局限性。本文将介绍一种新型的QA系统,它通过语义搜索技术,结合用户生成的数据,利用大型模型来提供更为精准和人性化的回答。
业务场景分析QA系统在自助客服和自助运维等领域扮演着重要角色。以客服为例,当客户提出问题时,人工客服会根据客户的意图查询相关业务知识,并结合业务规则给出回答。优秀的客服人员还会进一步结合业务数据,为客户提供更加周到的服务。而在自助客服中,系统会根据用户的问题推荐相似的问题,并提供标准答案。
构建更有温度的自助应答系统为了提升自助客服系统的服务质量,我们提出了以下几个关键点:
- 使用语义搜索技术:提高问题查询的准确性,更好地理解用户意图。
- 重构知识结构:将业务知识与数据关联起来,使知识更加丰富和动态。
- 利用大型模型:根据业务知识和数据,智能生成回答,提供个性化服务。
主要技术以下是构建大模型QA系统所依赖的关键技术:
- 语义搜索:通过理解问题的深层含义,而非仅仅依赖关键词。
- 知识重构:将静态的业务知识与动态的用户数据相结合。
- 大模型应用:运用先进的算法模型,处理和生成回答。
实际应用该系统已在实际客服场景中得到应用,通过提供更加精准和人性化的服务,显著提升了客户满意度。
结语大模型QA系统的引入,不仅优化了自助客服的效率,也极大地丰富了客户体验。通过技术的进步,我们能够为客户提供更加周到和有温度的服务。
|
|
构建思维链是实现高效知识管理和问题解决的关键。以下是构建思维链的四个核心步骤,每个步骤都具有明确的目标和操作流程:
-
知识及业务数据重构:首先,我们需要对常见问题、知识内容和知识数据进行整合和重构。这一步骤的目的是将问题、知识和业务数据相互关联起来,形成一个结构化的知识库。除了使用MySQL数据库存储这些数据之外,我们还将问题与知识的关联信息在向量数据库中也存储一份,其中知识对应的问题是以向量化的形式存储的。我们选择的向量数据库是Milvus。
-
Milvus语义检索:在第二步中,我们将用户输入的问题进行向量化处理,然后利用Milvus提供的search功能,检索出TOP_K条语义上与用户问题相似的标准问题。这一步骤的目的是为用户提供推荐问题,帮助他们快速定位到可能的解决方案。
-
用户选择推荐问题查询:用户在前端界面上看到推荐的问题列表后,可以点击选择他们认为最符合自己需求的标准问题。一旦用户做出选择,后台系统将接收到这一选择,并查询MySQL数据库中相应的知识内容和知识所需的数据。
-
大模型生成最终应答话术:最后一步是利用大模型来生成最终的应答话术。我们将上一步查询到的知识内容和数据作为大模型的输入提示,同时以用户原始的问题作为输入,通过大模型来生成一个准确、合适的应答话术。 通过这四个步骤,我们能够构建一个高效、智能的知识管理和问题解决系统。
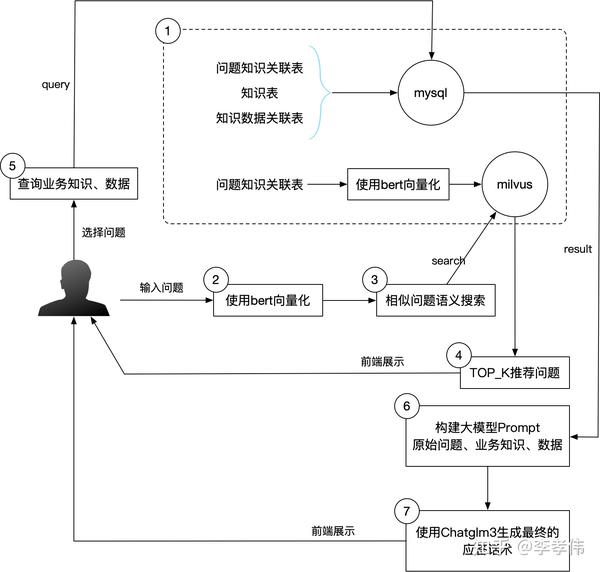
整体流程示意图
关键步骤
1. 结构化数据
- 定义:存储在MySQL数据库中的业务知识和数据。
1.1 业务知识管理
- 涉及表:问题表、知识表、知识数据表。
- 问题表:存储知识名称和常见问题。
- 知识表:记录知识名称、类型和内容。知识类型用于区分是否需要结合生产数据。
- 知识数据表:包含知识名称、数据名称、字段编码和数据所在表。
1.2 表结构设计参考
-
问题表设计:
-
知识名称:标识知识的名称。
-
常见问题:与知识相关的常见问题列表。
-
知识表设计:
-
知识名称:唯一标识知识的名称。
-
知识类型:区分知识是否需要结合生产数据。
-
知识内容:知识的详细描述。
-
知识数据表设计:
-
知识名称:与知识表中的名称关联。
-
数据名称:数据集的名称。
-
字段编码:数据字段的唯一标识符。
-
数据所在表:数据存储的具体表名。
|
|
2)用户数据管理,这里就是实际生产中用户的业务数据,通过知识数据表关联起来,无需而外创建;如果担心数据安全,可以单独抽取一张大宽表;参考如下:
|
|
2.向量数据
使用milvus存储问题表数据,其中问题表中的问题经bert模型"paraphrase-multilingual-MiniLM-L12-v2"向量化后存储,知识名称直接存储;一个collection类似一张表;参考设计如下:
|
|
3.知识创建流程
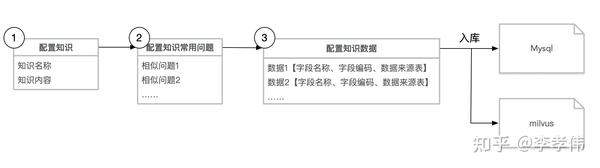
知识常见问题可以配置多个,即知识与问题是一对多关系,有助于提升准确性。
4.系统顺序图
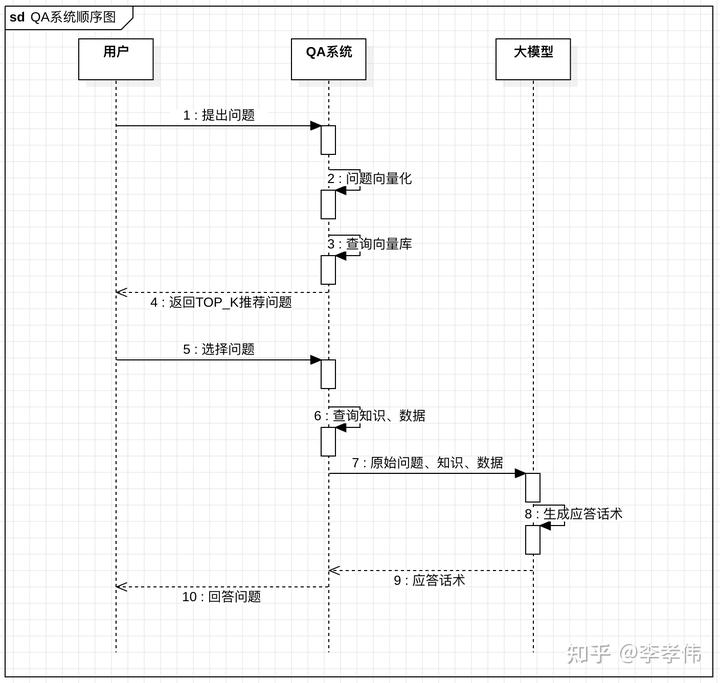
以上设计中第4、5步是借助客户选择来提升准确性,如果觉得不够友好,可以省去;
准确性调优
以上是标准流程,影响最终准确性的有以下几点:
1.大模型调优
|
|
2.语义搜索调优
|
|
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E5%9F%BA%E4%BA%8E%E8%AF%AD%E4%B9%89%E6%90%9C%E7%B4%A2%E7%9A%84%E5%A4%A7%E6%A8%A1%E5%9E%8BQA%E7%B3%BB%E7%BB%9F%E7%94%9F%E4%BA%A7%E8%90%BD%E5%9C%B0%E6%96%B9%E6%A1%88--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


