学习向量量化(Learning vector quantization)- AI全书 -- 知识铺 -- 知识铺
学习向量量化简介
LVQ, 或称为学习向量量化(Learning Vector Quantization),是人工神经网络领域的一种算法。它旨在克服K邻近算法(K-Nearest Neighbors, KNN)的一个主要缺点:在使用KNN时,必须保存整个训练数据集以供后续预测使用,这可能导致存储和计算上的高成本。 LVQ提供了一种更高效的方法,它允许用户预先确定要保留的训练实例的数量,并且通过学习过程来优化这些实例的特征。这种方法不仅减少了所需的存储空间,而且加快了预测速度,因为不再需要在整个数据集中搜索最近邻。 LVQ的核心思想是在特征空间中选择一组代表性的’原型向量’,这些向量能够概括数据集中的模式。在训练过程中,LVQ调整这些原型向量的位置,使得它们能够最好地表示所属类别的数据点。一旦训练完成,只有这些原型向量被保存下来用于分类新样本。
-
访问量: 70
-
发表日期: 2023-03-18
-
更新日期: 2024-03-20
-
阅读时间: 5~7 分钟
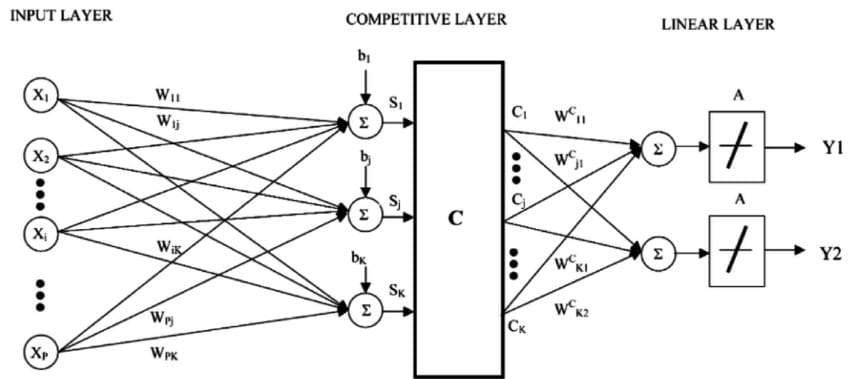
学习矢量量化算法(简称LVQ)
LVQ的表示是码本向量的集合。这些是在开始时随机选择的,并且适于在学习算法的多次迭代中最佳地总结训练数据集。在学习之后,可以使用码本向量来进行与KNN(K-Nearest Neighbors)类似的预测。通过计算每个码本矢量和新数据实例之间的距离来找到最相似的邻居(最佳匹配码本矢量)。然后返回最佳匹配单元的类值或(回归情况下的实际值)作为预测。如果将数据重新缩放到相同范围(例如0到1之间),则可获得最佳结果。
如果您发现KNN在您的数据集上提供了良好的结果,请尝试使用LVQ来降低存储整个训练数据集的内存要求。
百科介绍
百度百科(详情)
学习向量量化(Learning Vector Quantization,简称LVQ)属于原型聚类,即试图找到一组原型向量来聚类,每个原型向量代表一个簇,将空间划分为若干个簇,从而对于任意的样本,可以将它划入到它距离最近的簇中,不同的是LVQ假设数据样本带有类别标记,因此可以利用这些类别标记来辅助聚类。
维基百科(详情)
LVQ可以被理解为人工神经网络的一个特例,更确切地说,它应用了一种赢家通吃的 Hebbian学习方法。它是自组织图(SOM)的前体,与神经气体有关,也与k-最近邻算法(k-NN)有关。LVQ由Teuvo Kohonen发明。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/ai/post/20241218/%E5%AD%A6%E4%B9%A0%E5%90%91%E9%87%8F%E9%87%8F%E5%8C%96Learning-vector-quantization-AI%E5%85%A8%E4%B9%A6--%E7%9F%A5%E8%AF%86%E9%93%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


