RAG预处理增强:让FastgptDify召回更多东西 Menghuan1918's Blog -- 知识铺 --知识铺
目前的Fastgpt,Dify(或者其他同类产品),目前知识库召回的本质上还是分片块的文本,召回的还是文本信息。不过,我们可以进行一些预处理,提升其召回精度的同时,使其也能同时召回将图片与公式表格等内容。
原理以及实现
已经将下文提到的所有预处理方法加到pdfdeal包里啦(需要0.2.4或更高版本),从PYPI上直接下载使用吧:pip install --upgrade pdfdeal
原理其实也很简单,对于原本的文档(假设是PDF格式),将其通过转换工具将其转换为Markdown,再对MD文件进行一系列的预处理。整体而言分为三步:
- 转换文档,这一步中转换源文档中公式和整体结构,如果使用的工具足够强大,表格以及纯图片也应当被保留转换。
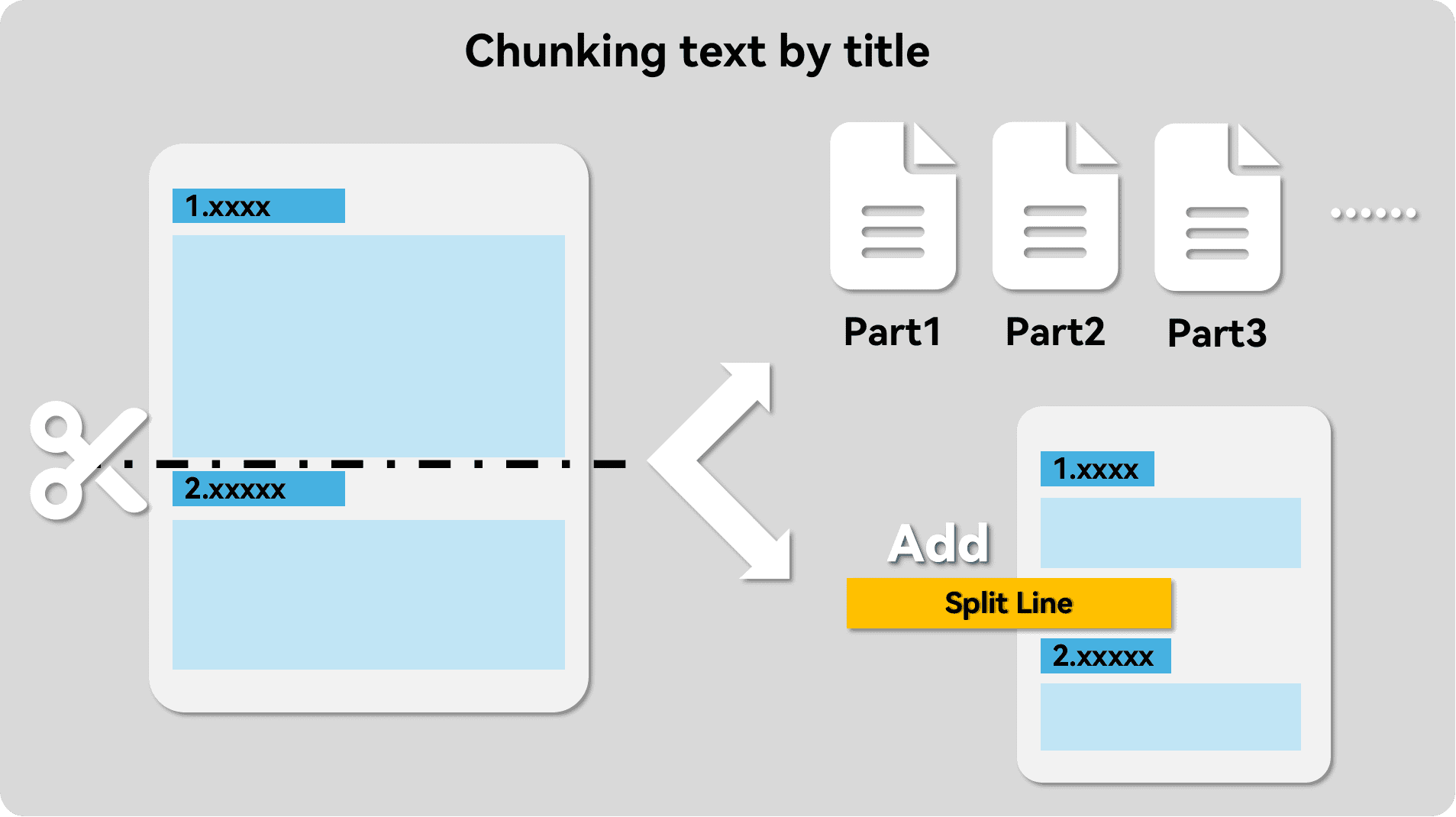
- 拆分段落,这一步将文本按照段落拆分开。对比普遍使用的滑动窗口拆分方式,其能显著加强分块内文本的相关度。
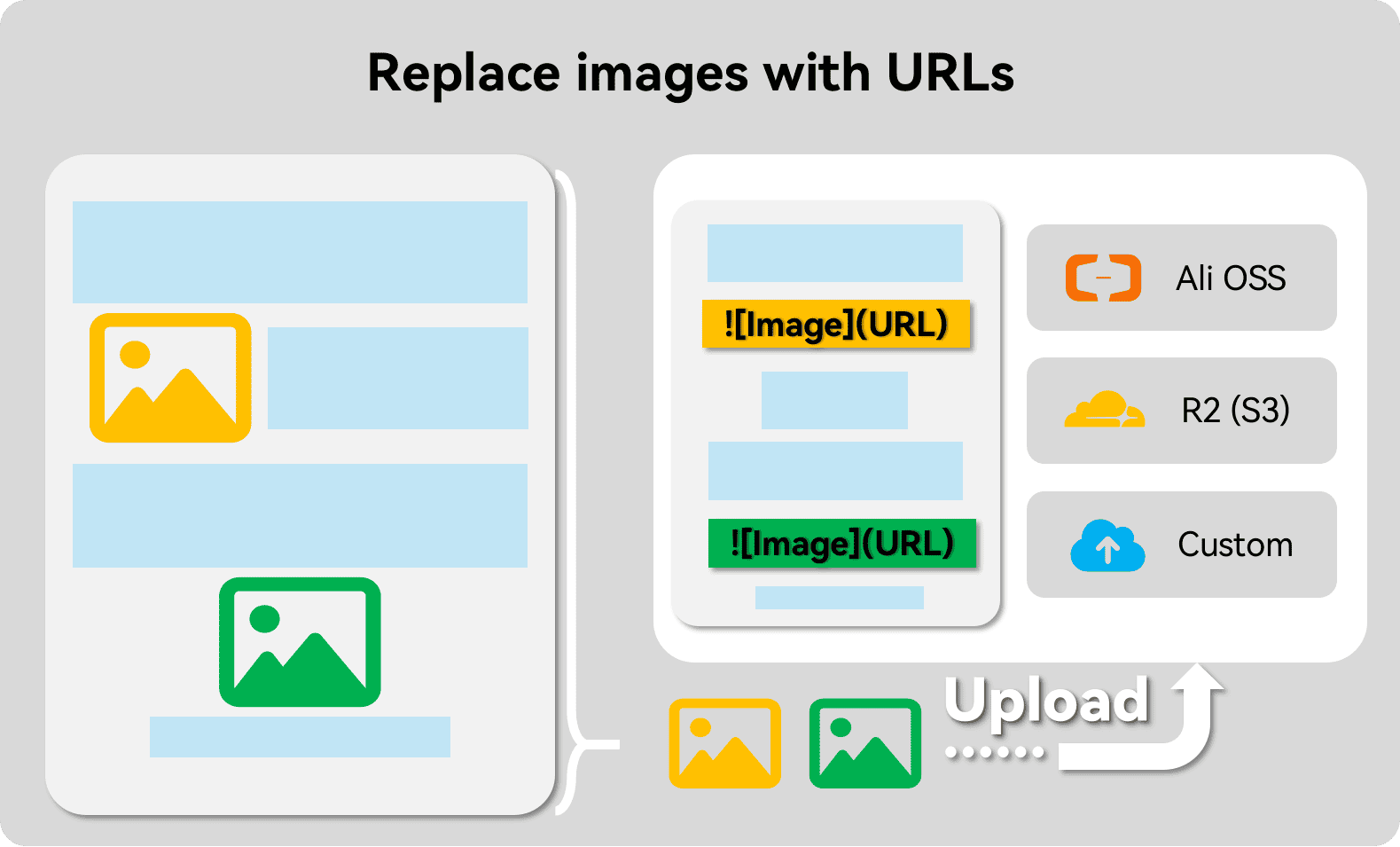
- 转换图片,这一步将不需要进行OCR的图片(例如示意图),上传至云储存(例如阿里OSS,S3,云耀R2),并以Markdown的形式的URL图片替换原有的位置。
注
题外话:上面说的纯图片是什么
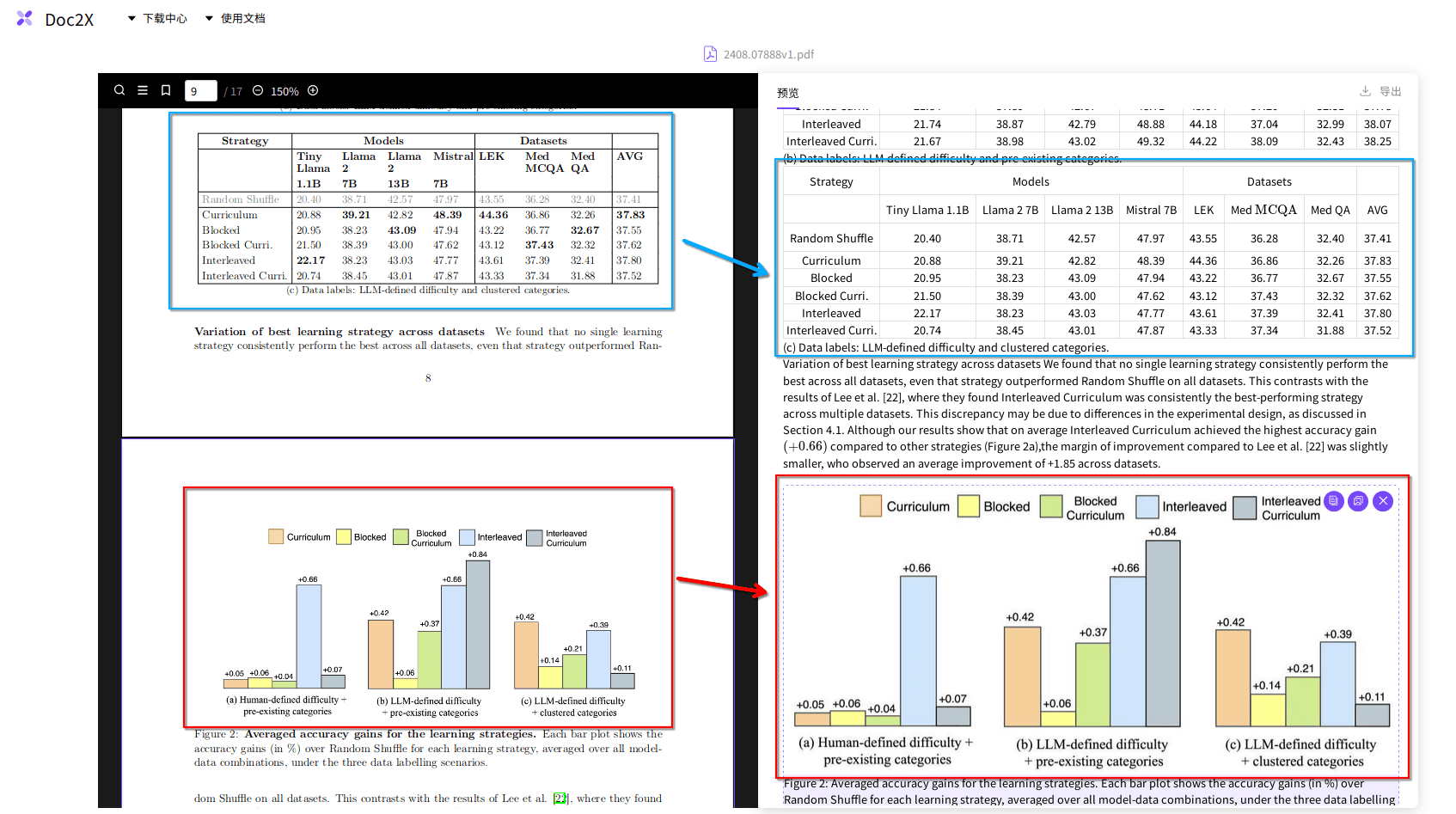
例如下图中蓝色方框部分是表格,应当进行表格识别(此处被识别为HTML格式的表格),而红色方框部分则是展示的原理图,其不应当被进行OCR,而是应当保留下来。目前主流的转换工具应当都有能力保留。
Step1:转换文档:PDF转Markdown
考虑Doc2X满足以上的所有需求,即文章结构/公式识别/表格识别/图片保留(~以及免费~),偷懒就直接用其进行转换了(同时也是pdfdeal包内置的方法)。
如果你想用其他方法,其他转换工具你可以参见我上一篇博文的这一节。
上链接未带AFF,不过我建议你使用我的邀请码
4AREZ6注册(滑稽)
from pdfdeal import Doc2X
from pdfdeal.file_tools import get_files, unzips
Client = Doc2X()
out_type = "md"
file_list, rename_list = get_files(path="./Files", mode="pdf", out=out_type)
success, failed, flag = Client.pdf2file(
pdf_file=file_list,
output_path="./Output",
output_names=rename_list,
output_format=out_type,
)
print(success, failed, flag)
zips = []
for file in success:
if file.endswith(".zip"):
zips.append(file)
success, failed, flag = unzips(zip_paths=zips)
print(success, failed, flag)
你应当得到类似的输出:
['./Output/2408.07888v1.zip', './Output/1706.03762v7.zip'] [{'error': '', 'path': ''}, {'error': '', 'path': ''}] False
['./Output/2408.07888v1', './Output/1706.03762v7'] ['', ''] False
在许多RAG(Retrieval-Augmented Generation)应用程序中,通常会提供一种功能让用户能够自定义文档的段落结构。这意味着用户可以手动插入分隔符来划分文章的不同部分。这样的做法基于一个前提,即这些应用往往使用滑动窗口技术来进行文本分割。当然,存在一些例外情况,在后续讨论中我们会进一步探讨。
通过这种方式,用户可以根据内容的逻辑和结构更加精确地控制如何对长篇文档进行处理,从而提高信息检索和生成的准确性。
Made with PPT
直接使用pdfdeal内置的方法,详细参照此处。此处我直接使用的替换源文件。
# 上接step1中的代码
from pdfdeal.file_tools import auto_split_mds
succese, failed, flag = auto_split_mds(mdpath="./Output", out_type="replace")
print(succese, failed, flag)
你应当得到类似的输出:
MD SPLIT: 2/2 files are successfully splited.
Note the split string is :
=+=+=+=+=+=+=+=+=
['./1/1706.03762v7.md', './1/2408.07888v1.md'] [{'error': '', 'file': ''}, {'error': '', 'file': ''}] False
此时再查看MD文档,可以看到其在各个分段直接已经添加上了分隔符了:

就像这样
Step3:转换图片为在线URL
到目前为止,图片的形式都还是以本地路径呈现的,其样式形如

。显而易见地,大部分RAG应用并不能显示这些图片,不过我们可以将其上传到云端储存服务从而使其能被召回。同样pdfdeal中也有相应的内置方法。
Also made with PPT
目前pdfdeal中内置有阿里OSS,云耀R2(其实就是S3协议)的上传方法,当然你也可以使用自定义的上传方程。
配置阿里OSS
此处选择使用阿里OSS,网上一堆开通的教程,自行搜索一下吧~ 其中以下是需要注意的一些权限问题:
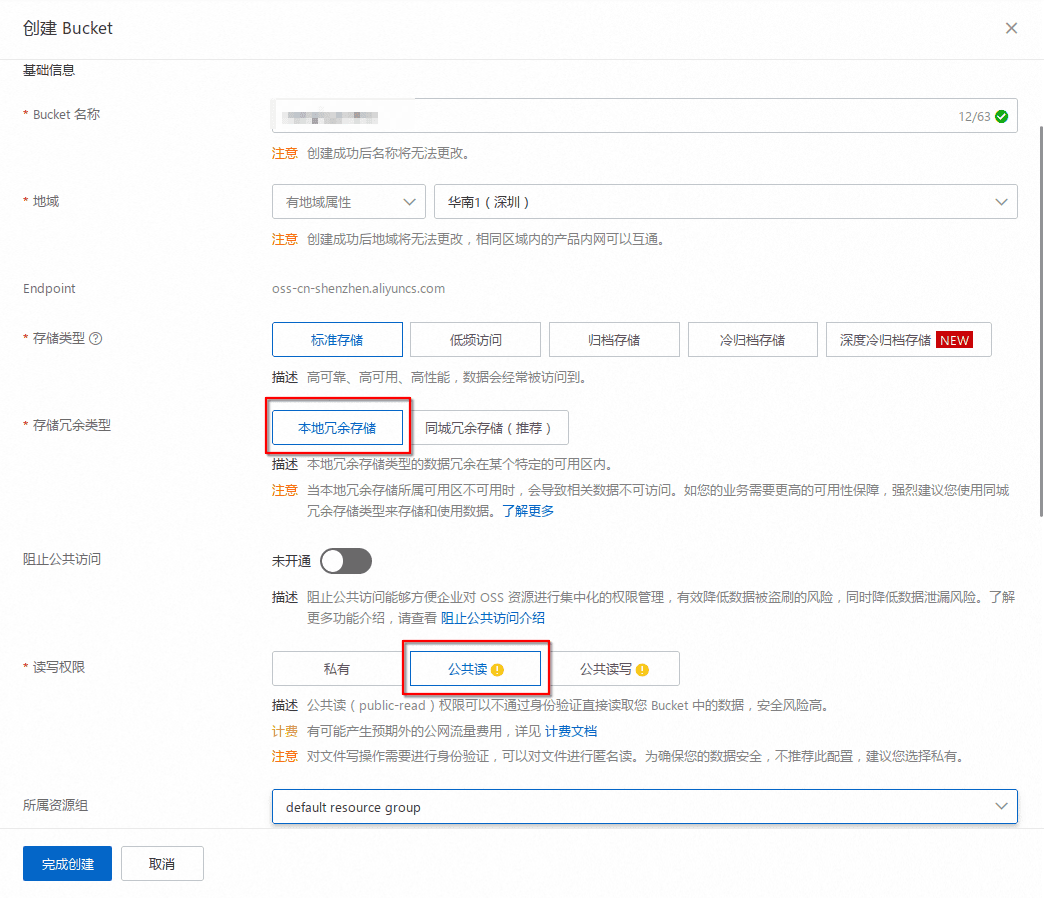
记得选择公网可访问…不然没法用
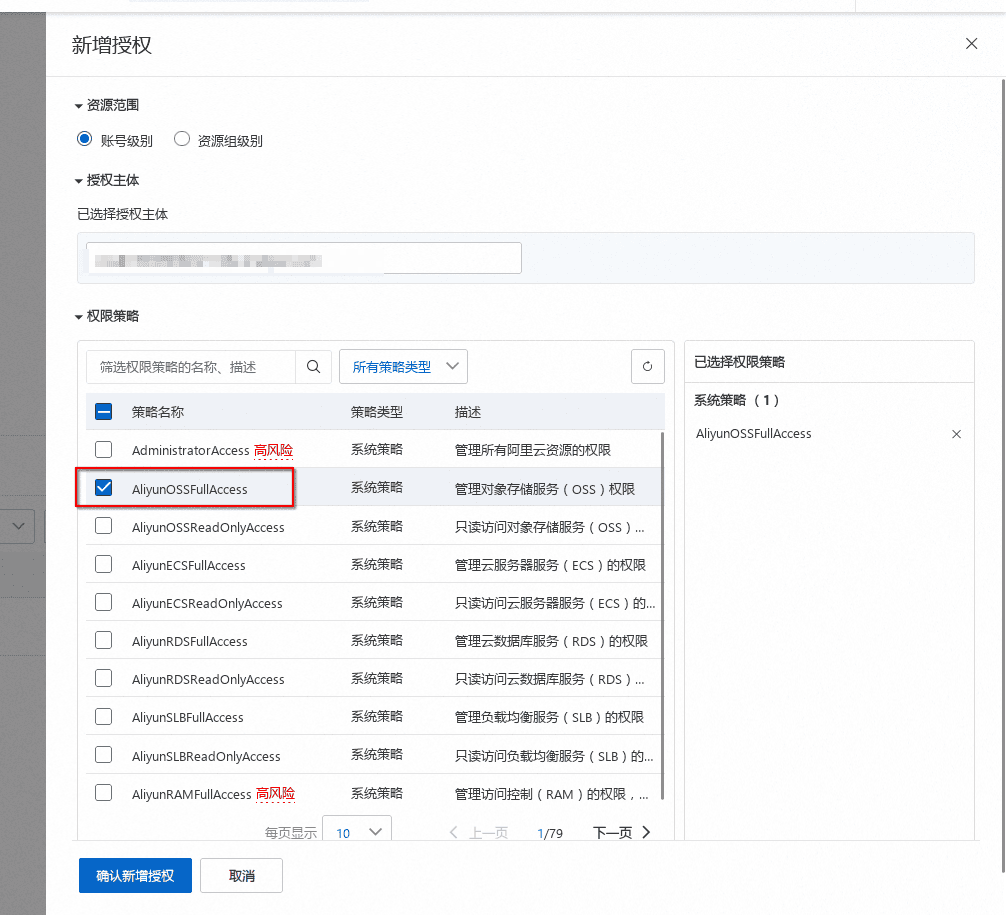
以及记得给密匙读写权限
转换为URL
以下默认环境变量中已经有密匙啥的了,由于选用的是阿里OSS,额外再安装其包 pip install -U oss2:
# 上接Step2中的代码
from pdfdeal.FileTools.Img.Ali_OSS import Ali_OSS
from pdfdeal.file_tools import mds_replace_imgs
import os
ossupload = Ali_OSS(
OSS_ACCESS_KEY_ID=os.environ.get("OSS_ACCESS_KEY_ID"),
OSS_ACCESS_KEY_SECRET=os.environ.get("OSS_ACCESS_KEY_SECRET"),
Endpoint=os.environ.get("Endpoint"),
Bucket=os.environ.get("Bucket"),
)
succese, failed, flag = mds_replace_imgs(
path="Output",
replace=ossupload,
threads=5,
)
print(succese, failed, flag)
随后再查看MD文档,现在图片已经被替换为URL啦,其在大部分的RAG应用中召回时也能直接显示了:

最后看起来是这样
完整的程序
from pdfdeal import Doc2X
from pdfdeal.file_tools import get_files, unzips, auto_split_mds, mds_replace_imgs
from pdfdeal.FileTools.Img.Ali_OSS import Ali_OSS
import os
Client = Doc2X()
out_type = "md"
file_list, rename_list = get_files(path="./Files", mode="pdf", out=out_type)
success, failed, flag = Client.pdf2file(
pdf_file=file_list,
output_path="./Output",
output_names=rename_list,
output_format=out_type,
)
print(success, failed, flag)
zips = []
for file in success:
if file.endswith(".zip"):
zips.append(file)
success, failed, flag = unzips(zip_paths=zips)
print(success, failed, flag)
succese, failed, flag = auto_split_mds(mdpath="./Output", out_type="replace")
print(succese, failed, flag)
ossupload = Ali_OSS(
OSS_ACCESS_KEY_ID=os.environ.get("OSS_ACCESS_KEY_ID"),
OSS_ACCESS_KEY_SECRET=os.environ.get("OSS_ACCESS_KEY_SECRET"),
Endpoint=os.environ.get("Endpoint"),
Bucket=os.environ.get("Bucket"),
)
succese, failed, flag = mds_replace_imgs(
path="Output",
replace=ossupload,
threads=5,
)
print(succese, failed, flag)
Fastgpt
简介
Fastgpt是一款高效的数据处理工具,它能够帮助用户快速地导入、处理并分析数据。
特点
-
易于使用:提供直观的操作界面,使得即使是非技术人员也能轻松上手。
-
功能强大:支持多种数据处理方式,包括但不限于清洗、转换等。
-
灵活性高:允许用户通过自定义处理规则来满足特定需求。
-
兼容性强:可以与市面上大多数数据库系统无缝对接。
使用流程
- 数据准备:首先准备好需要导入的数据文件。
- 导入数据:登录到Fastgpt平台后,选择相应的项目,然后上传你的数据文件。
- 数据处理:在数据处理阶段,你可以选择默认处理方案或是设置自己的处理规则。比如,在这里我们采用了自定义处理规则,指定了特定的分隔符
- 结果预览:完成数据处理后,Fastgpt会展示处理结果供你查看。
- 导出数据:最后,你可以选择合适的形式导出已处理的数据。
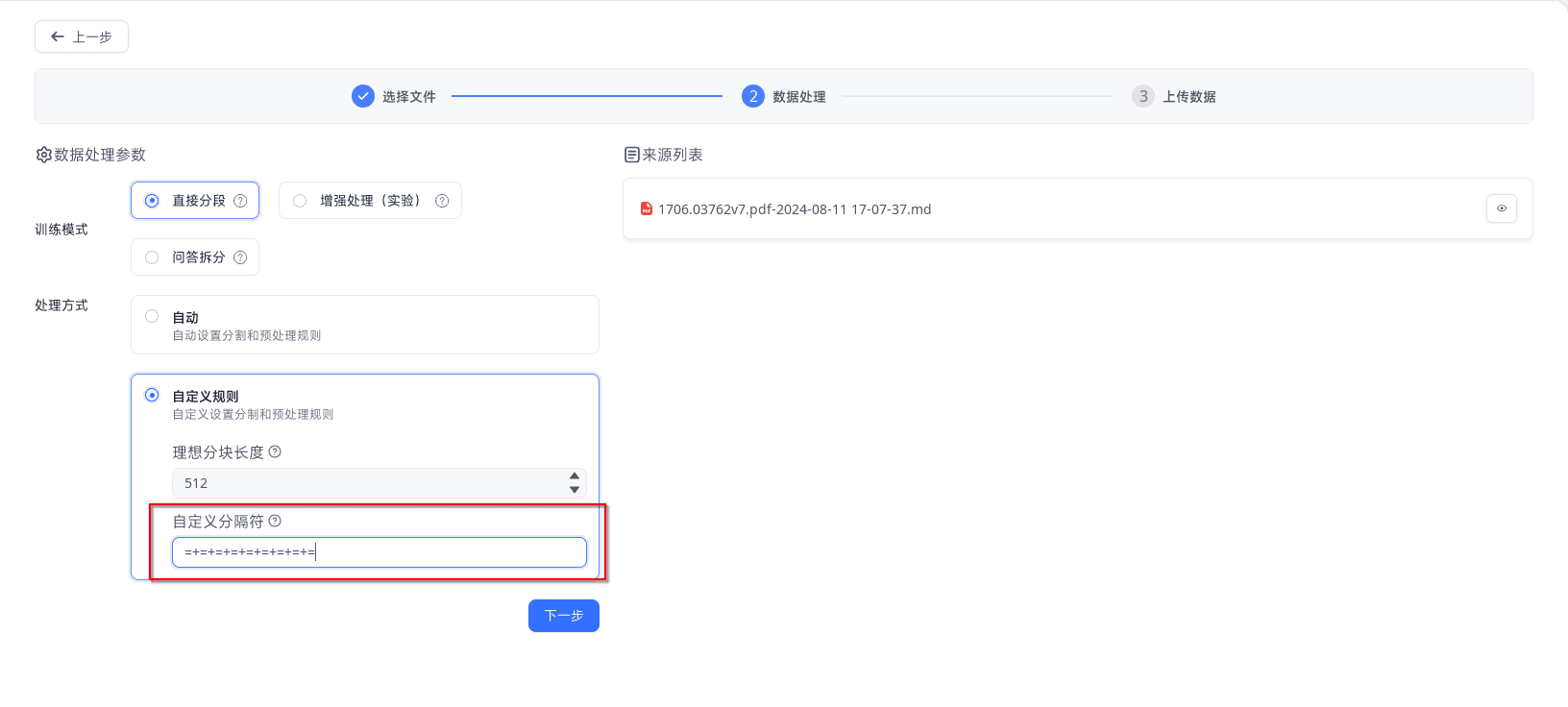
填入分隔符
可以看到其数据中是严格按照段落分段的:

这个自动在每个分块中加入标题是Fastgpt的功能
以下是一个召回的效果演示:
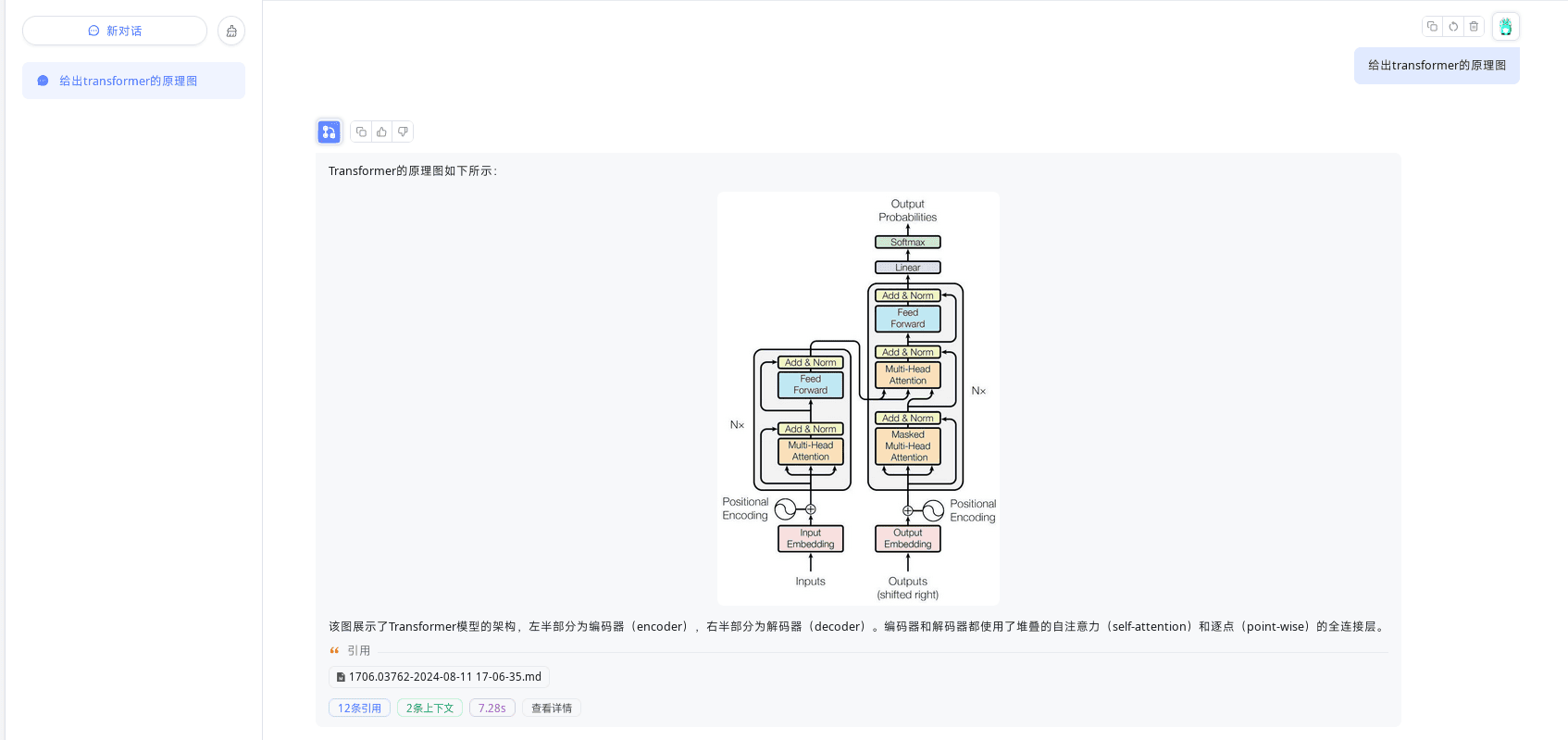
内容
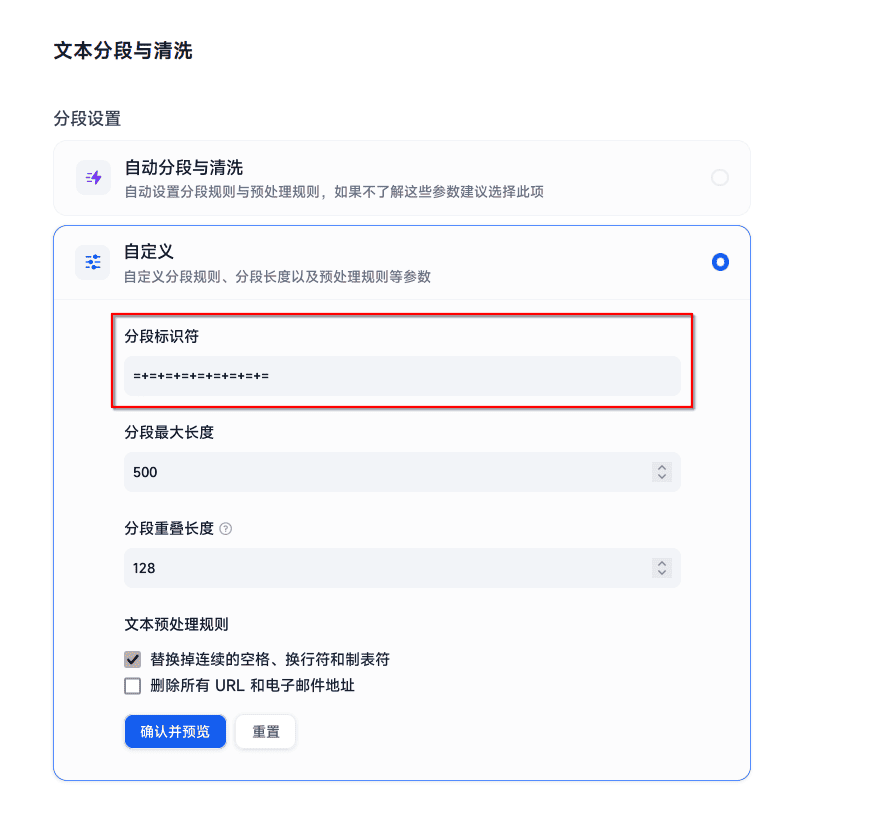
填入分段标识符
可以看到其数据中是严格按照段落分段的:
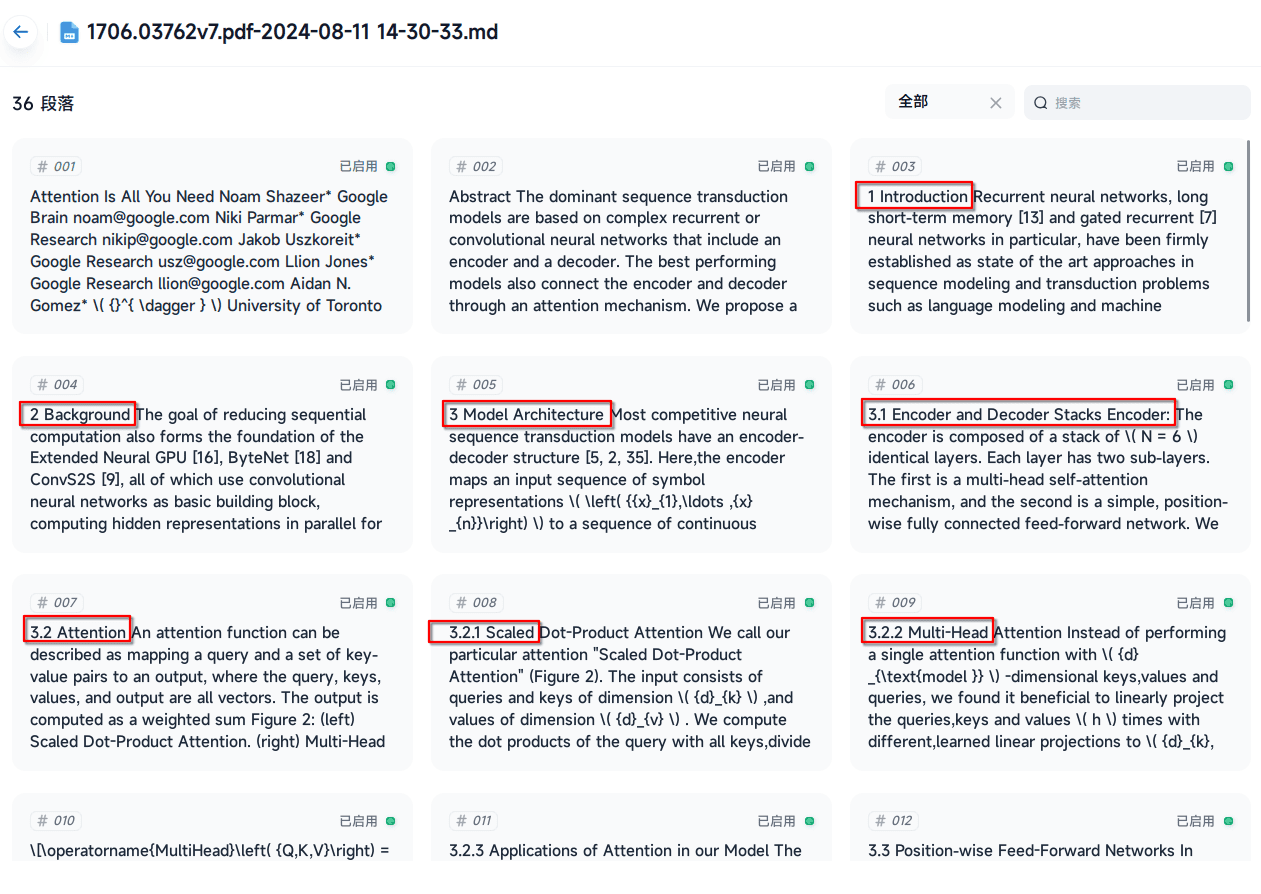
就像这样
以下是一个召回的效果演示:
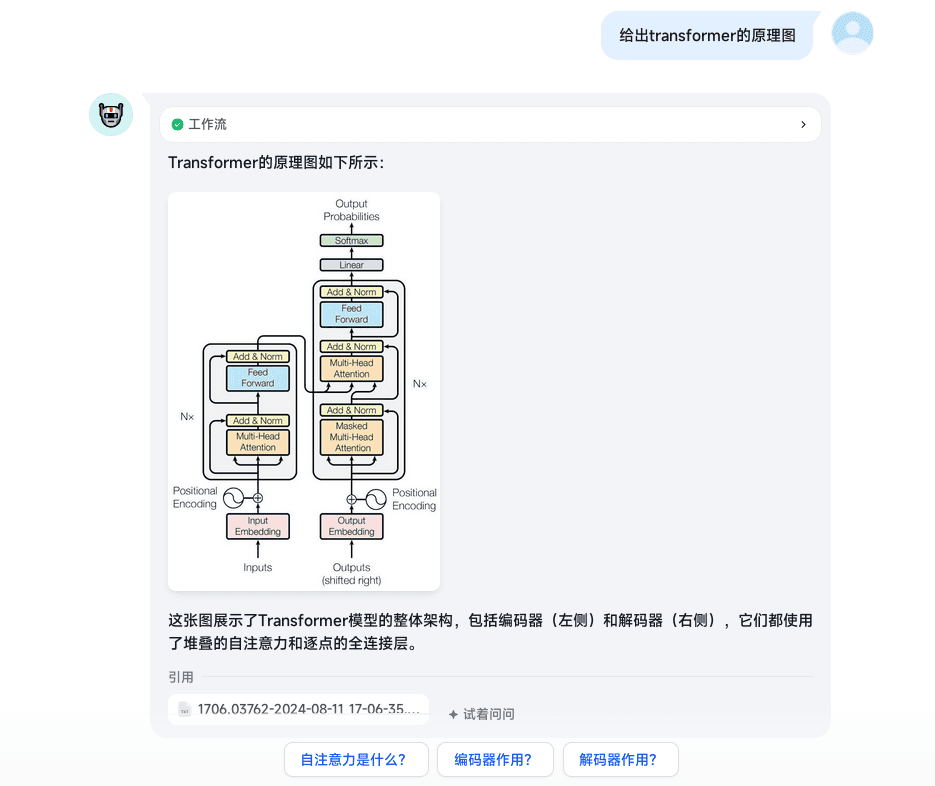
就是这样
公式/表格召回
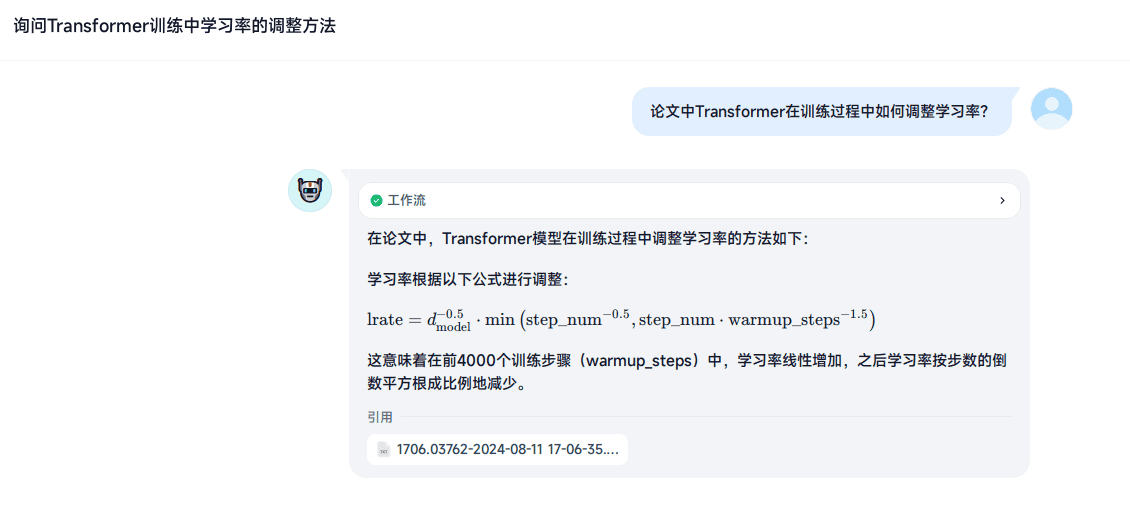
公式召回
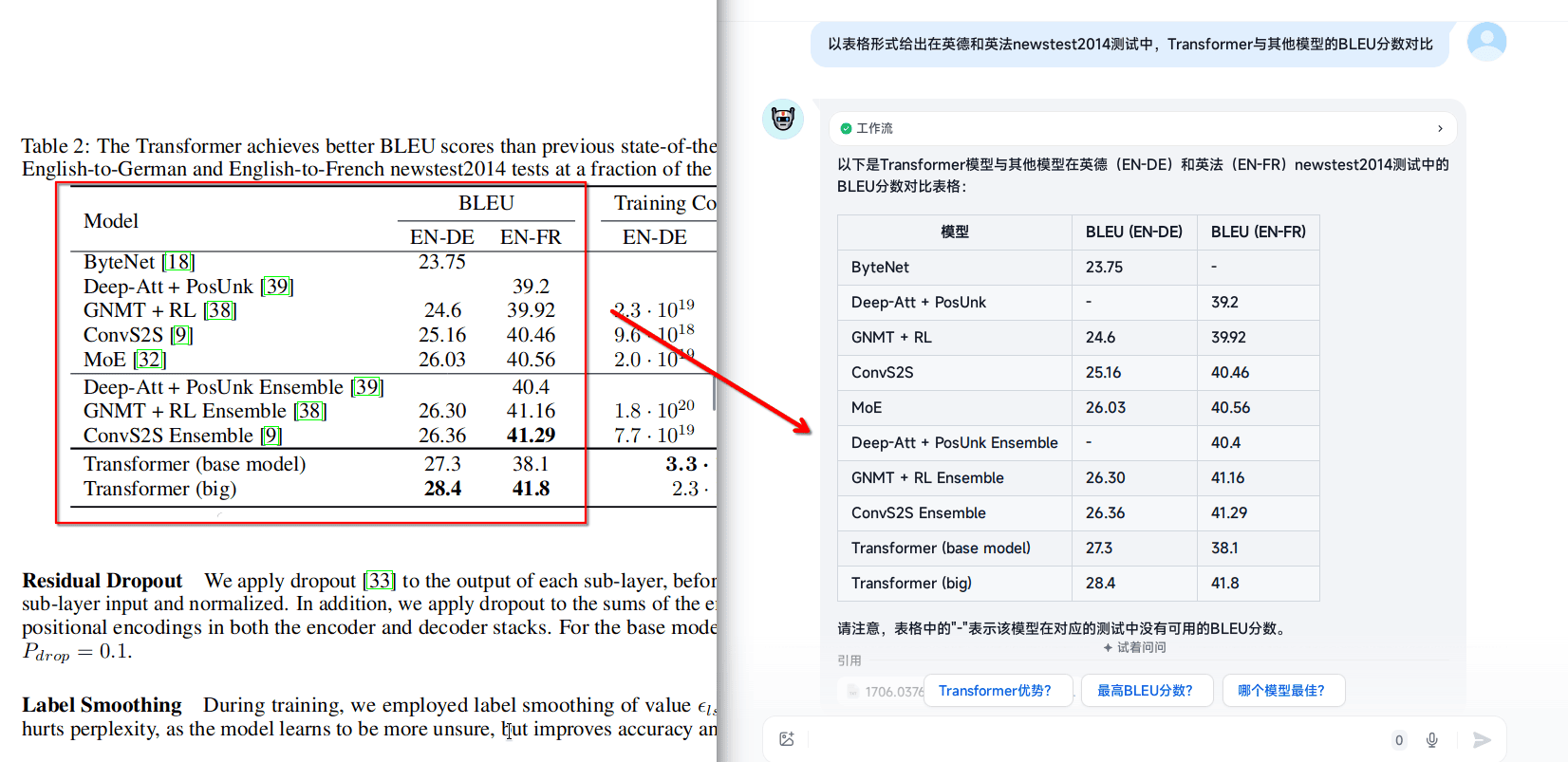
表格和公式召回效果分析
表格和公式召回的实现
表格和公式的召回能力主要得益于Doc2X的格式转换功能。Doc2X在转换过程中能够识别并保留文档中的表格和公式,这对于后续的召回操作至关重要。尽管pdfdeal工具也提供了文件预处理功能,但其对表格和公式召回的贡献相对较小。
Doc2X的作用
Doc2X在文档转换过程中,能够识别并保留文章的结构、公式、表格以及图片。这种保留对于保持文档信息的完整性和可检索性至关重要。
pdfdeal的作用
尽管pdfdeal在文件预处理方面的作用不大,但它提供了一些辅助功能,如文档转换、段落拆分和图片转换为在线URL,这些功能有助于优化文档的检索和展示。
Fastgpt和Dify的效果对比
Fastgpt的Markdown文档处理
Fastgpt对Markdown文档的处理更为精细。在Fastgpt的演示中,可以看到#4章节的内容较多,因此被拆分为几个分块,并且Fastgpt为每个分块添加了章节标题。这种处理方式有助于提高文档的可读性和检索效率。
Dify的Markdown文档处理
与Fastgpt不同,Dify在处理Markdown文档时不会自动添加章节标题,即使上传的是MD格式文档。这可能会影响文档的可读性和检索效率。
结论
表格和公式的召回效果主要依赖于Doc2X的转换能力,而pdfdeal虽然提供了一些辅助功能,但其对召回效果的影响相对较小。Fastgpt和Dify在Markdown文档处理上的差异也会影响最终的召回效果。
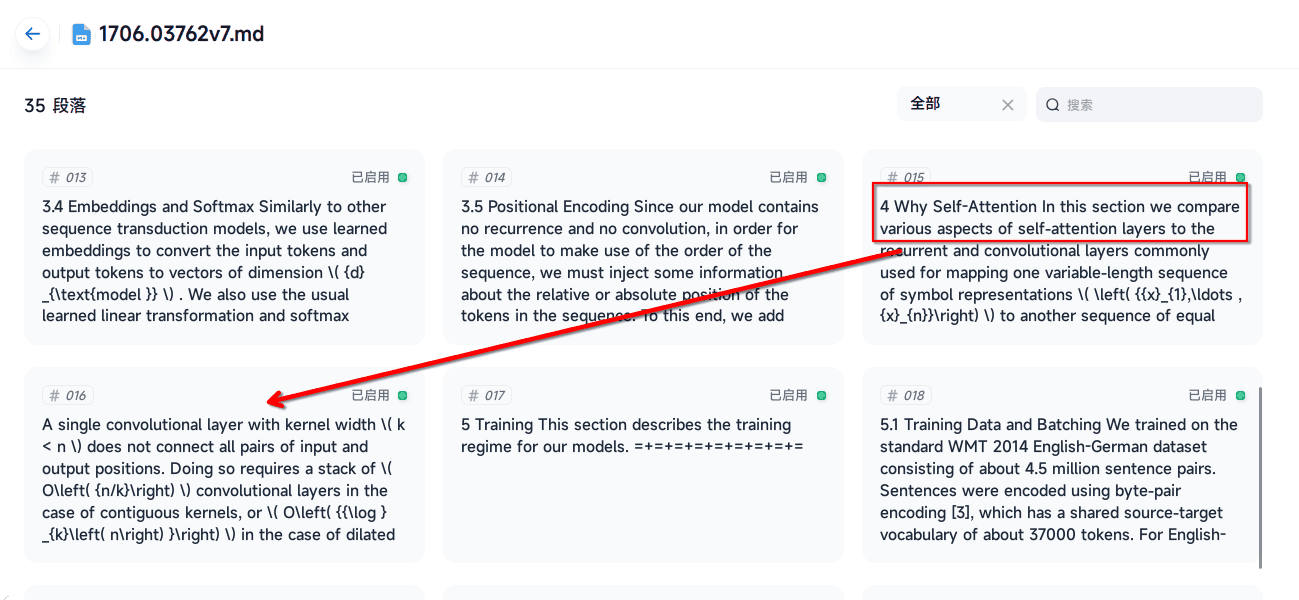
你可以看到Dify并没有分块添加标题
因此理论上拆分段落的一步对于Dify的效果提升是更为显著的,对于Fastgpt可能提升微小或者没有。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/RAG%E9%A2%84%E5%A4%84%E7%90%86%E5%A2%9E%E5%BC%BA%E8%AE%A9FastgptDify%E5%8F%AC%E5%9B%9E%E6%9B%B4%E5%A4%9A%E4%B8%9C%E8%A5%BF-Menghuan1918s-Blog--%E7%9F%A5%E8%AF%86%E9%93%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com