BAAIbge-m3 高频镜知识介绍 --知识铺
有关更多详细信息,请参阅我们的 github 存储库: https://github.com/FlagOpen/FlagEmbedding
在这个项目中,我们引入了BGE-M3,它以其多功能性、多语言性和多粒度性而著称。
- 多功能:可以同时执行嵌入模型的三种常见检索功能:密集检索、多向量检索和稀疏检索。
- 多语言:可支持100多种工作语言。
- 多粒度:它能够处理不同粒度的输入,从短句子到最多 8192 个标记的长文档。
RAG 中检索管道的一些建议
我们建议使用以下管道:混合检索+重新排序。
-
混合检索结合了多种方法的优点,具有更高的准确率和更强的泛化能力。 一个经典的例子:同时使用嵌入检索和 BM25 算法。
现在,您可以尝试使用BGE-M3,它同时支持嵌入和稀疏检索。 这允许您在生成密集嵌入时获得令牌权重(类似于 BM25),而无需任何额外成本。 使用混合检索可以参考Vespa和Milvus 。 -
作为跨编码器模型,重排序器表现出比双编码器嵌入模型更高的准确性。检索后利用重排序模型(例如bge-reranker 、 bge-reranker-v2 )可以进一步过滤所选文本。
消息:
-
2024年7月1日:我们更新了BGE-M3的MIRACL评估结果。要重现新结果,您可以参考: bge-m3_miracl_2cr 。我们还更新了 arXiv 上的论文。
细节
之前的测试结果较低是因为我们错误地从搜索结果中删除了与查询具有相同 id 的段落。
纠正这个错误后,BGE-M3在MIRACL上的整体性能高于之前的结果,但实验结论保持不变。其他结果不受此错误影响。要重现之前较低的结果,您需要在使用pyserini.search.faiss或pyserini.search.lucene搜索段落时添加--remove-query参数。 -
2024/3/20:**感谢 Milvus 团队!**现在您可以在 Milvus 中使用 bge-m3 的混合检索: pymilvus/examples /hello_hybrid_sparse_dense.py 。
-
2024/3/8:感谢@Yannael的实验结果。在该基准测试中,BGE-M3 在英语和其他语言上均取得了顶级性能,超越了 OpenAI 等模型。
-
2024/2/1:**感谢 Vespa 提供的优秀工具。**跟随这款笔记本,您可以轻松使用BGE-M3的多种模式
规格
-
模型
-
数据
常问问题
1. 不同检索方式介绍
- 密集检索:将文本映射到单个嵌入中,例如DPR 、 BGE-v1.5
- 稀疏检索(词汇匹配):大小等于词汇量的向量,大多数位置设置为零,仅计算文本中存在的标记的权重。例如,BM25、 unicoil和spade
- 多向量检索:使用多个向量来表示文本,例如ColBERT 。
2.如何在其他项目中使用BGE-M3?
对于嵌入检索,您可以采用与 BGE 相同的方法的 BGE-M3 模型。唯一的区别是 BGE-M3 模型不再需要向查询添加指令。
3.如何对bge-M3模型进行微调?
您可以按照本例中的常见内容来微调密集嵌入。
如果你想微调m3的所有嵌入函数(dense、sparse和colbert),可以参考unified_fine-tuning示例
用法
安装:
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
或者:
pip install -U FlagEmbedding
生成文本嵌入
- 密集嵌入
|
|
您还可以使用句子转换器和拥抱脸转换器来生成密集嵌入。详细信息请参阅baai_general_embedding 。
- 稀疏嵌入(词汇权重)
|
|
- 多向量 (ColBERT)
|
|
计算文本对的分数
输入文本对列表,即可得到不同方法计算出的分数。
|
|
评估
来自开源社区的基准
[注意:请根据上面内容,做到下面操作
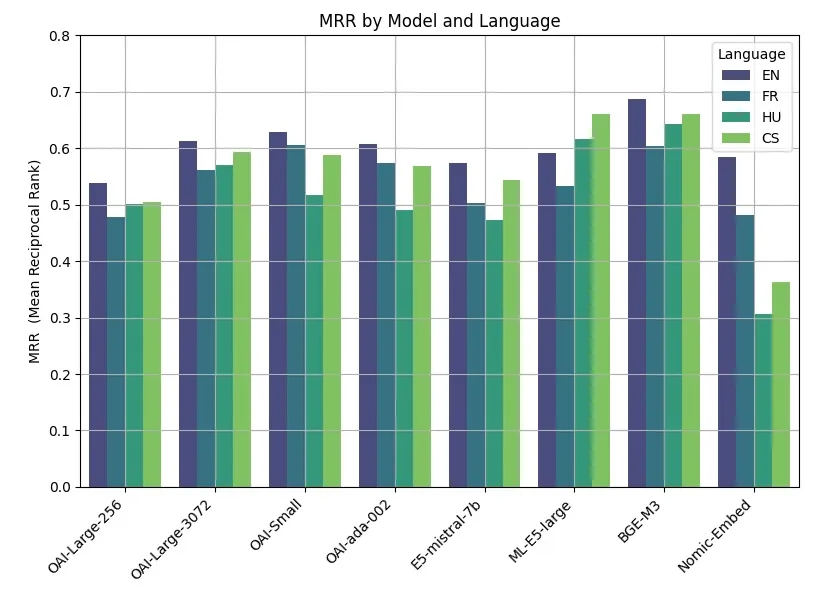
BGE-M3 模型基准测试表现
BGE-M3 模型在最近的基准测试中取得了最佳成绩,超越了 OpenAI(OAI)的相关模型。以下是我们的成果概述:
多语言支持(Miracl 数据集)
我们的模型在多语言环境下表现出色,特别是在 Miracl 数据集上。这表明 BGE-M3 在处理不同语言的文本时具有很高的准确性和可靠性。
参考资源
-
文章:OpenAI vs. Open Source Multilingual Embedding Models 提供了关于 BGE-M3 模型与 OpenAI 模型的对比分析。
-
Github Repo:Multilingual Embeddings 是一个开源的多语言嵌入模型仓库,其中包含了 BGE-M3 模型的详细信息和代码。
我们的成果
-
多语言支持:BGE-M3 模型在 Miracl 数据集上的表现证明了其在多语言处理方面的强大能力。 以上信息提供了 BGE-M3 模型在基准测试中的优异表现和多语言处理能力的概述。
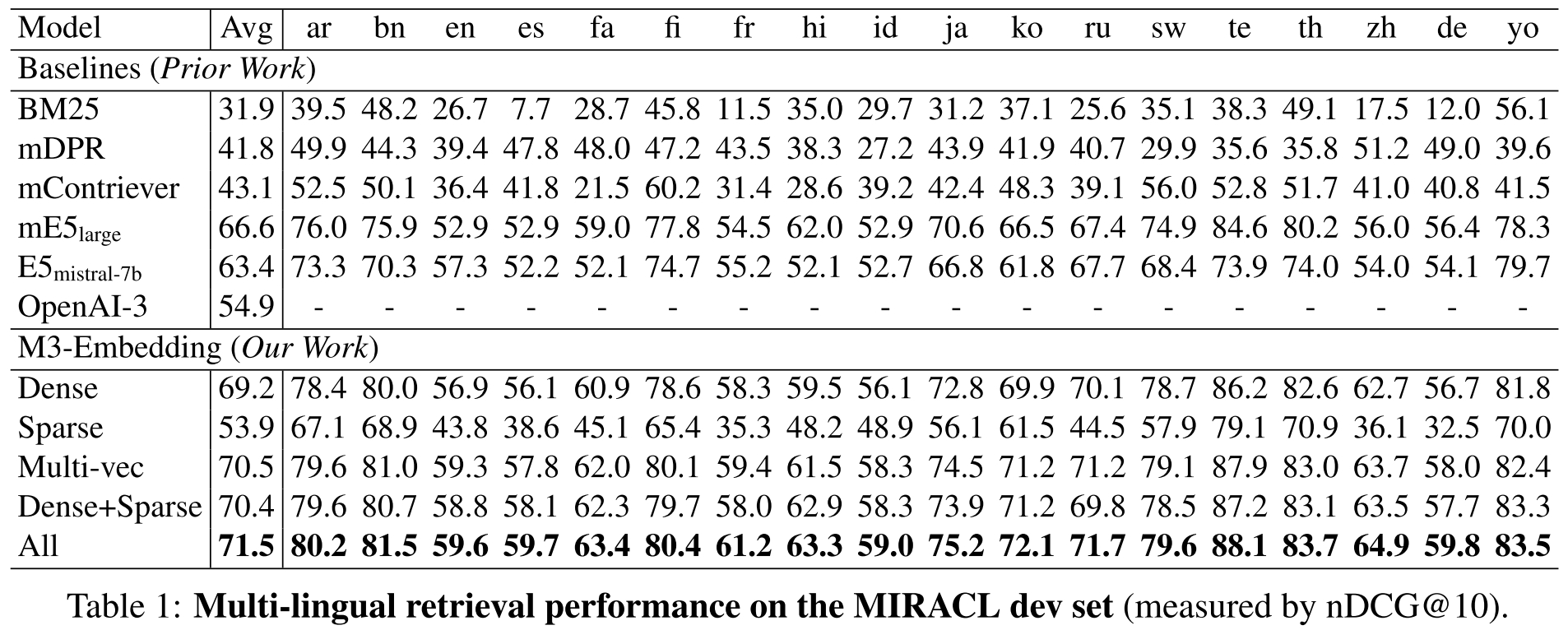
](https://hf-mirror.com/BAAI/bge-m3/blob/main/imgs/miracl.jpg) -
跨语言(MKQA 数据集)
{kind=link}

-
长文档检索
- MLDR:
[
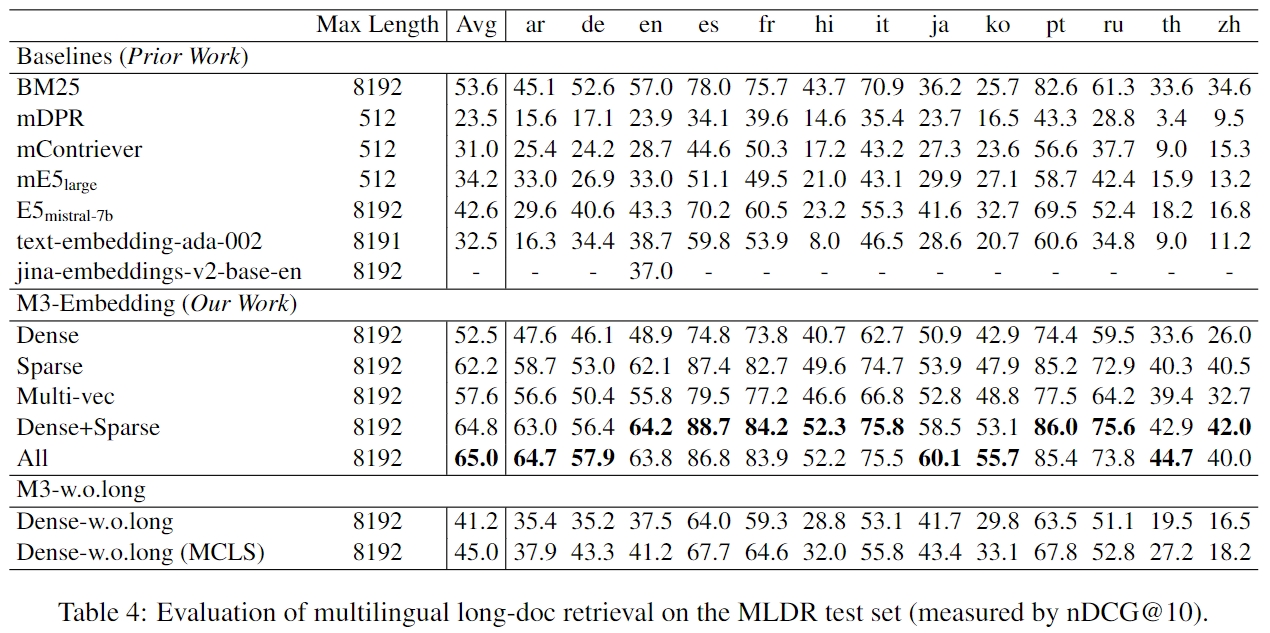
aaaaaaa 我们构建了一个名为 MLDR 的文档检索数据集,该数据集覆盖了13种语言,并且包含了测试集、验证集以及训练集。MLDR 数据集的创建旨在通过使用其训练集来提升模型在长文档检索上的能力。 为了确保评估的公正性,在对比实验中我们选择将经过 MLDR 训练集微调后的模型与Dense wolong(即未采用长文档数据集进行微调的基线模型)进行比较。 此外,我们计划将此多语言长文本检索数据集开源,以填补目前在这方面开放资源的空缺。我们相信这将为开源社区提供宝贵的数据支持,促进更多高质量文档检索模型的发展。
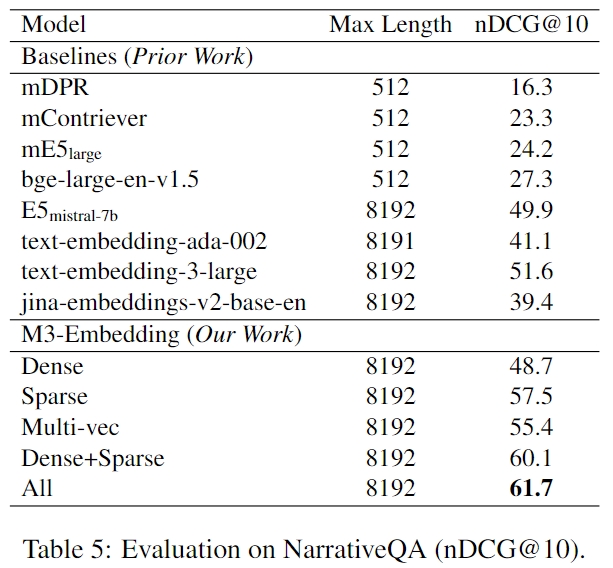
我们利用Pyserini来实现BM25,并且可以通过该脚本重现测试结果。我们使用两种不同的分词器测试 BM25:一种使用 Lucene Analyzer,另一种使用与 M3 相同的分词器(即 xlm-roberta 的分词器)。结果表明 BM25 仍然是一个有竞争力的基线,特别是在长文档检索方面。
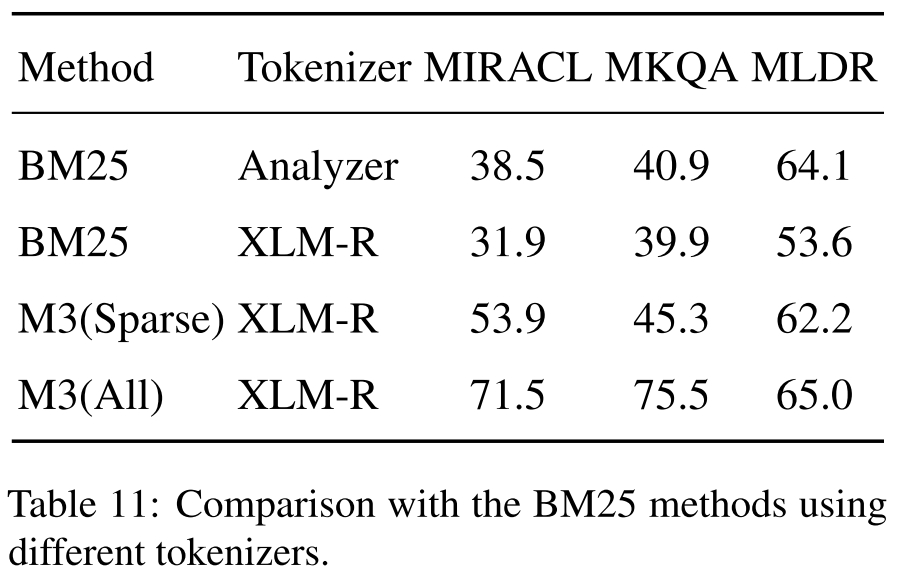
本研究介绍了一种基于自知识蒸馏和高效批处理技术的训练方法,旨在提高长文本微调时的效率。该方法通过组合不同检索模式的多个输出作为奖励信号,以增强单一模式的性能,特别适用于稀疏检索和多向量(colbert)检索。此外,还提出了一种无需微调即可提高长文本性能的简单方法MCLS,对于资源有限的用户来说非常有用。更多详细信息请参阅我们的报告。
- MLDR:
@misc{bge-m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/BAAIbge-m3-%E9%AB%98%E9%A2%91%E9%95%9C%E7%9F%A5%E8%AF%86%E4%BB%8B%E7%BB%8D--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com
See Also
- LightRAG:高效构建和优化大型语言模型应用的 PyTorch 框架.md --知识铺
- 介绍txtai,一体化嵌入式数据库由大卫Mezzetti NeuML介质 --- Introducing txtai, the all-in-one embeddings database by David Mezzetti NeuML Medium.md--知识铺
- Milvus×Dify半小时轻松构建RAG系统_Milvus_Zilliz.md--知识铺
- GPU服务器本地搭建Dify+xinference实现大模型应用_dify xinference.md --知识铺
- Centos7安装Glibc 2.32版本(超详细)_centos glibc -- 知识铺 --知识铺