1
|
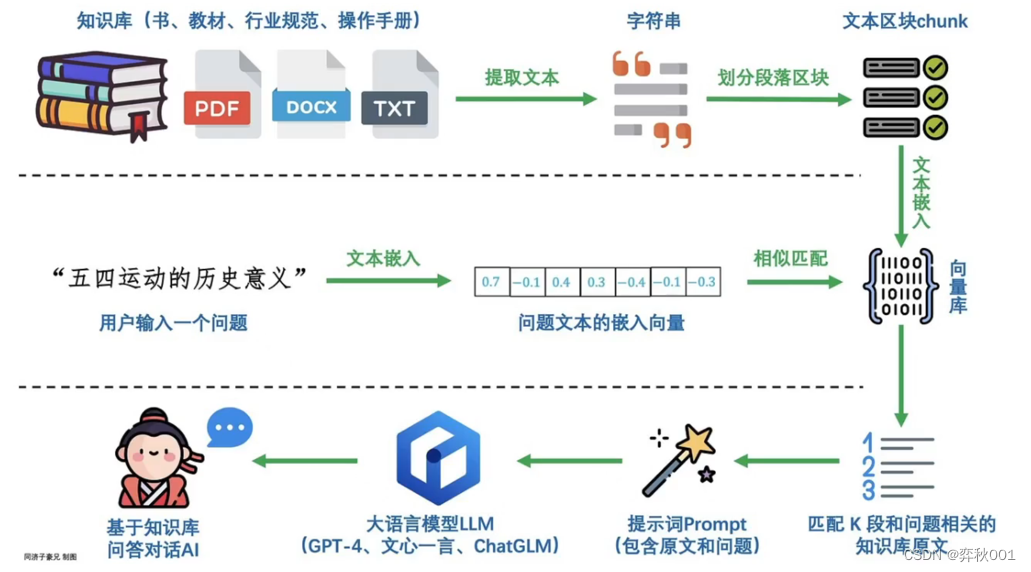
# -*- coding: utf-8 -*- # @Time : 2024/6/13 23:41 # @Author : yblir # @File : qwen2_rag_test.py # explain : # ======================================================= # from openai import OpenAI import jieba, json, pdfplumber # import numpy as np # from sklearn.feature_extraction.text import TfidfVectorizer # from sklearn.preprocessing import normalize from rank_bm25 import BM25Okapi # import requests # 加载重排序模型 import torch from transformers import AutoModelForSequenceClassification, AutoTokenizer, AutoModelForCausalLM from sentence_transformers import SentenceTransformer # client = OpenAI(api_key="sk-13c3a38819f84babb5cd298e001a10cb", base_url="https://api.deepseek.com") device = "cuda" rerank_tokenizer = AutoTokenizer.from_pretrained(r'E:\PyCharm\PreTrainModel\bge-reranker-base') rerank_model = AutoModelForSequenceClassification.from_pretrained(r'E:\PyCharm\PreTrainModel\bge-reranker-base') rerank_model.cuda() model_path = r'E:\PyCharm\PreTrainModel\qwen2-1_5b' # model_path = r'E:\PyCharm\PreTrainModel\qwen_7b_chat' # model_path = r'E:\PyCharm\PreTrainModel\qwen2_7b_instruct_awq_int4' tokenizer = AutoTokenizer.from_pretrained( model_path, # trust_remote_code=True ) model = AutoModelForCausalLM.from_pretrained( pretrained_model_name_or_path=model_path, torch_dtype="auto", device_map="auto", # trust_remote_code=True # attn_implementation="flash_attention_2" ) # 对长文本进行切分 def split_text_fixed_size(text, chunk_size, overlap_size): new_text = [] for i in range(0, len(text), chunk_size): if i == 0: new_text.append(text[0:chunk_size]) else: new_text.append(text[i - overlap_size:i + chunk_size]) # new_text.append(text[i:i + chunk_size]) return new_text def get_rank_index(max_score_page_idxs_, questions_, pdf_content_): pairs = [] for idx in max_score_page_idxs_: pairs.append([questions_[query_idx]["question"], pdf_content_[idx]['content']]) inputs = rerank_tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512) with torch.no_grad(): inputs = {key: inputs[key].cuda() for key in inputs.keys()} scores = rerank_model(**inputs, return_dict=True).logits.view(-1, ).float() max_score = scores.cpu().numpy().argmax() index = max_score_page_idxs_[max_score] return max_score, index def read_data(query_data_path, knowledge_data_path): with open(query_data_path, 'r', encoding='utf-8') as f: questions = json.load(f) pdf = pdfplumber.open(knowledge_data_path) # 标记当前页与其文本知识 pdf_content = [] for page_idx in range(len(pdf.pages)): text = pdf.pages[page_idx].extract_text() new_text = split_text_fixed_size(text, chunk_size=100, overlap_size=5) for chunk_text in new_text: pdf_content.append({ 'page' : 'page_' + str(page_idx + 1), 'content': chunk_text }) return questions, pdf_content def qwen_preprocess(tokenizer_, ziliao, question): """ 最终处理后,msg格式如下,system要改成自己的: [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Tell me who you are."}, {"role": "assistant", "content": "I am a large language model named Qwen..."} ] """ # tokenizer.apply_chat_template() 与model.generate搭配使用 messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": f"帮我结合给定的资料,回答问题。如果问题答案无法从资料中获得," f"输出结合给定的资料,无法回答问题. 如果找到答案, 就输出找到的答案, 资料:{ziliao}, 问题:{question}"}, ] # dd_generation_prompt 参数用于在输入中添加生成提示,该提示指向 <|im_start|>assistant\n text = tokenizer_.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs_ = tokenizer_([text], return_tensors="pt").to(device) input_ids = tokenizer_.encode(text, return_tensors='pt') attention_mask_ = torch.ones(input_ids.shape, dtype=torch.long, device=device) # print(model_inputs) # sys.exit() return model_inputs_, attention_mask_ if __name__ == '__main__': questions, pdf_content = read_data(query_data_path=r"E:\localDatasets\汽车问答系统\questions.json", knowledge_data_path=r'E:\localDatasets\汽车问答系统\初赛训练数据集.pdf') # 文本检索类向量库 pdf_content_words = [jieba.lcut(x['content']) for x in pdf_content] bm25 = BM25Okapi(pdf_content_words) # 语义检索类向量库 sent_model = SentenceTransformer( r'E:\PyCharm\PreTrainModel\stella_base_zh_v3_1792d' # '/mnt/e/PyCharm/PreTrainModel/stella_base_zh_v3_1792d', # '/mnt/e/PyCharm/PreTrainModel/moka_aim3e_small', ) question_sentences = [x['question'] for x in questions] pdf_content_sentences = [x['content'] for x in pdf_content] question_embeddings = sent_model.encode(question_sentences, normalize_embeddings=True) pdf_embeddings = sent_model.encode(pdf_content_sentences, normalize_embeddings=True) for query_idx in range(len(questions)): # 首先进行BM25检索 doc_scores = bm25.get_scores(jieba.lcut(questions[query_idx]["question"])) bm25_score_page_idxs = doc_scores.argsort()[-10:] # 再进行语义检索 score = question_embeddings[query_idx] @ pdf_embeddings.T ste_score_page_idxs = score.argsort()[-10:] # questions[query_idx]['reference'] = 'page_' + str(max_score_page_idx) # questions[query_idx]['reference'] = pdf_content[max_score_page_idxs]['page'] bm25_score, bm25_index = get_rank_index(bm25_score_page_idxs, questions, pdf_content) ste_score, ste_index = get_rank_index(ste_score_page_idxs, questions, pdf_content) max_score_page_idx = 0 if ste_score >= bm25_score: questions[query_idx]['reference'] = 'page_' + str(ste_index + 1) max_score_page_idx = ste_index else: questions[query_idx]['reference'] = 'page_' + str(bm25_index + 1) max_score_page_idx = bm25_index model_inputs, attention_mask = qwen_preprocess( tokenizer, pdf_content[max_score_page_idx]['content'], questions[query_idx]["question"] ) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=128, # 最大输出长度. attention_mask=attention_mask, pad_token_id=tokenizer.eos_token_id ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # print(response) # answer = ask_glm(pdf_content[max_score_page_idx]['content'], questions[query_idx]["question"]) print(f'question: {questions[query_idx]["question"]}, answer: {response}') # data_path = '/media/xk/D6B8A862B8A8433B/GitHub/llama-factory/data/train_clean_eval.json' # with open(data_path, 'r', encoding='utf-8') as f: # data = json.load(f)
|