1
|
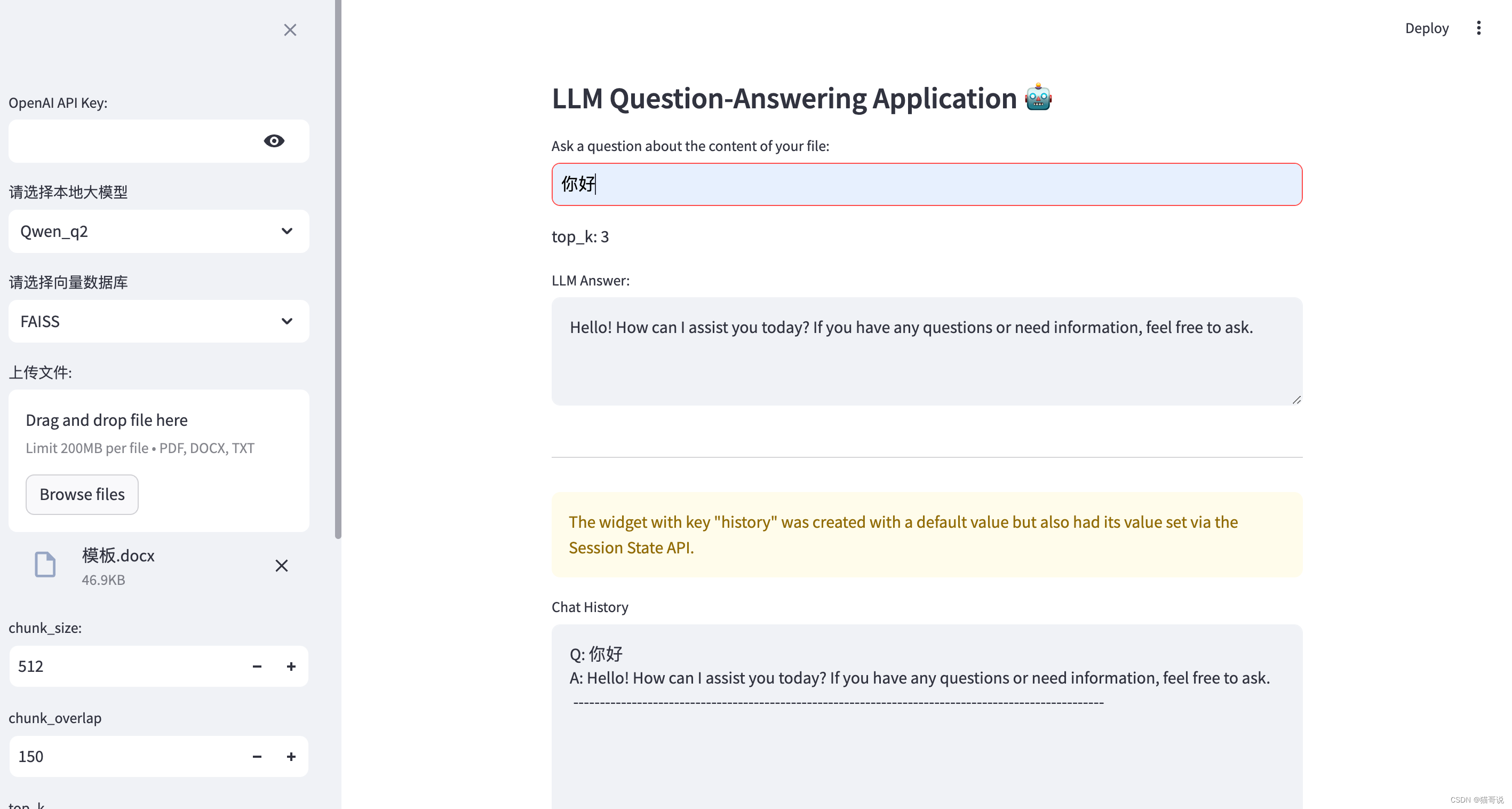
import sys import streamlit as st import os from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI import tiktoken from dotenv import load_dotenv, find_dotenv from langchain_core.prompts import PromptTemplate BASE_DIR = os.path.dirname(__file__) PRJ_DIR = os.path.abspath(os.path.join(BASE_DIR, "..")) sys.path.append(PRJ_DIR) from streamlit_demo.custom_llm import QwenLLM from streamlit_demo.embedding_oper import create_embeddings_faiss, create_embeddings_chroma, load_embeddings_faiss from streamlit_demo.prepare_data import load_document, chunk_data _ = load_dotenv(find_dotenv(), override=True) vector_db_path = os.path.join(BASE_DIR, "vector_db") print(f"vector_db_path: {vector_db_path}") DEFAULT_TEMPLATE = """ 你是一个聪明的超级智能助手,请用专业且富有逻辑顺序的句子回复,并以中文形式且markdown形式输出。 检索到的信息: {context} 问题: {question} """ def ask_and_get_answer_from_local(model_name, vector_db, prompt, top_k=5): """ 从本地加载大模型 :param model_name: 模型名称 :param vector_db: :param prompt: :param top_k: :return: """ docs_and_scores = vector_db.similarity_search_with_score(prompt, k=top_k) print("docs_and_scores: ", docs_and_scores) # knowledge = [doc.page_content for doc in docs_and_scores] # print("检索到的知识:", knowledge) if model_name == "Qwen_q2": llm = QwenLLM(model_name=model_name, temperature=0.4) prompt_template = PromptTemplate(input_variables=["context", "question"], template=DEFAULT_TEMPLATE) retriever = vector_db.as_retriever(search_type='similarity', search_kwargs={'k': top_k}) chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, chain_type_kwargs={"prompt": prompt_template}, return_source_documents=True) answer = chain({"query": prompt, "top_k": top_k}) print(f"answers: {answer}") # answer = chain.run(prompt) # answer = answer['choices'][0]['message']['content'] answer = answer['result'] return answer def ask_and_get_answer(vector_store, q, k=3): llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=1) retriever = vector_store.as_retriever(search_type='similarity', search_kwargs={'k': k}) chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever) answer = chain.run(q) return answer # calculate embedding cost using tiktoken def calculate_embedding_cost(texts): enc = tiktoken.encoding_for_model('text-embedding-ada-002') total_tokens = sum([len(enc.encode(page.page_content)) for page in texts]) # print(f'Total Tokens: {total_tokens}') # print(f'Embedding Cost in USD: {total_tokens / 1000 * 0.0004:.6f}') return total_tokens, total_tokens / 1000 * 0.0004 # clear the chat history from streamlit session state def clear_history(): if 'history' in st.session_state: del st.session_state['history'] if __name__ == "__main__": # st.image('img.png') st.subheader('LLM Question-Answering Application 🤖') with st.sidebar: # text_input for the OpenAI API key (alternative to python-dotenv and .env) api_key = st.text_input('OpenAI API Key:', type='password') if api_key: os.environ['OPENAI_API_KEY'] = api_key llm = st.selectbox( label="请选择本地大模型", options=('Qwen_q2', 'Qwen_q6') ) # 向量数据库 embedding = st.selectbox( "请选择向量数据库", ('FAISS', 'Chroma') ) # file uploader widget uploaded_file = st.file_uploader('上传文件:', type=['pdf', 'docx', 'txt']) # chunk size number widget chunk_size = st.number_input('chunk_size:', min_value=100, max_value=2048, value=512, on_change=clear_history) # chunk overlap chunk_overlap = st.number_input(label="chunk_overlap", min_value=0, max_value=1024, value=150, on_change=clear_history) # k number input widget k = st.number_input('top_k', min_value=1, max_value=20, value=3, on_change=clear_history) # add data button widget add_data = st.button('添加数据', on_click=clear_history) # 输出方式 output_type = st.selectbox("选择输出方式", ('普通输出', '流式输出')) if uploaded_file and add_data: # if the user browsed a file with st.spinner('Reading, chunking and embedding file ...'): # writing the file from RAM to the current directory on disk bytes_data = uploaded_file.read() file_name = os.path.join('./', uploaded_file.name) with open(file_name, 'wb') as f: f.write(bytes_data) data = load_document(file_name) chunks = chunk_data(data, chunk_size=chunk_size, chunk_overlap=chunk_overlap) st.write(f'Chunk size: {chunk_size}, chunk_overlap: {len(chunks)} Chunks: {len(chunks)}') tokens, embedding_cost = calculate_embedding_cost(chunks) st.write(f'Embedding cost: ${embedding_cost:.4f}') # creating the embeddings and returning the Chroma vector store # 指定选择向量库和embedding类型,还可改进 if embedding == "FAISS": vector_store = create_embeddings_faiss(vector_db_path=vector_db_path, embedding_name="bge", chunks=chunks) elif embedding == "Chroma": vector_store = create_embeddings_chroma(chunks) # saving the vector store in the streamlit session state (to be persistent between reruns) st.session_state.vs = vector_store st.success('File uploaded, chunked and embedded successfully.') # 初始化history if "messages" not in st.session_state: st.session_state.messages = [] # 展示对话 for msg in st.session_state.messages: with st.chat_message(msg['role']): st.markdown(msg["content"]) # React to user input if prompt := st.chat_input("Say something"): # Display user message in chat message container with st.chat_message("user"): st.markdown(prompt) # Add user message to chat history st.session_state.messages.append({"role": "user", "content": prompt}) # load local vector db if 'vs' not in st.session_state: # st.warning(body='正在努力加载模型中...', icon="⚠️") vector_store = load_embeddings_faiss(vector_db_path, "bge") st.session_state.vs = vector_store st.toast('Load vector store db success!', icon='😍') # 普通方式输出 if prompt is not None: vector_store = st.session_state.vs # if vector_store is None: # st.warning(body='正在努力加载模型中,稍后再试', icon="⚠️") if output_type == "普通输出" and vector_store is not None: response = "" if llm == "GPT": response = ask_and_get_answer(vector_store, prompt, k) elif llm == "Qwen_q2": response = ask_and_get_answer_from_local(model_name="Qwen_q2", vector_db=vector_store, prompt=prompt, top_k=k) # Display assistant response in chat message container with st.chat_message("assistant"): st.markdown(response) # Add assistant response to chat history st.session_state.messages.append({"role": "assistant", "content": response}) else: # 流式输出 # stream_res = get_llm_model_with_stream(prompt=prompt, model="Qwen_q2") # with st.chat_message("assistant"): # content = st.write_stream(stream_res) # print("流式输出:", content) # st.session_state.messages.append({"role": "assistant", "content": content}) print("流式输出") # run the app: streamlit run ./chat_doc.py
|