RAG开山之作:知识密集型NLP任务新解法 --知识铺
检索增强生成(RAG)综述
1. 简介检索增强生成(RAG)是一种先进的自然语言处理(NLP)技术,它将预训练语言模型与检索机制相结合,以增强模型对知识的访问和操作能力。
2. 核心概念
- 预训练语言模型:利用大量文本数据预训练的模型,能够捕捉语言的复杂特征。
- 检索机制:通过检索与问题相关的信息,为模型提供额外的知识支持。
3. RAG模型的优势
- 知识访问:RAG模型能够有效地访问和利用外部知识源。
- 知识操作:模型能够对检索到的知识进行深入分析和操作。
- 知识更新:与传统模型相比,RAG模型在知识更新方面更为灵活。
4. 应用领域RAG模型在多个知识密集型NLP任务上展现出卓越的性能,包括但不限于问答系统、文本摘要、机器翻译等。
5. 研究意义RAG模型的提出为NLP领域带来了新的启示,推动了知识密集型任务的研究和应用。
6. 结论RAG作为一种创新的NLP技术,通过结合检索和生成,为解决传统模型在知识访问、操作及更新方面的难题提供了有效的解决方案。
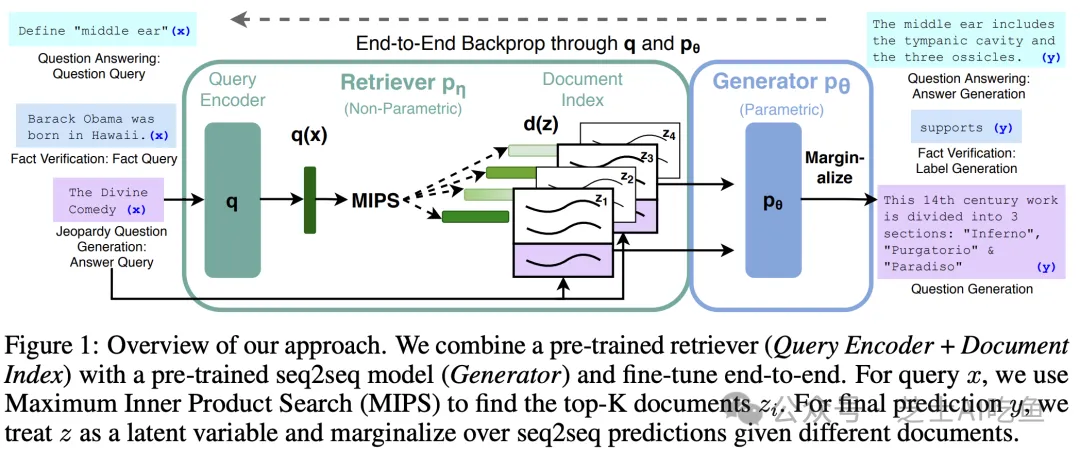
自然语言处理中的检索增强生成方法(RAG)
引言在自然语言处理(NLP)领域,大型预训练语言模型在各种任务中取得了显著成果。然而,这些模型在处理知识密集型任务时,如开放域问答和事实验证,仍面临挑战。尽管能够存储大量知识,但它们在精确操作和检索知识方面能力有限,并且难以提供决策出处和更新知识库。
方法背景与动机传统预训练语言模型,例如BERT和GPT,在许多任务上表现出色,但在需要外部知识的任务中受限。这些模型难以扩展知识库,提供决策洞察,且可能产生“幻觉”。为解决这些问题,提出了结合参数化和非参数化记忆的混合模型。
主要问题
- 知识访问与操作限制:预训练模型在访问和操作知识方面存在局限。
- 缺乏可解释性:模型被视为“黑箱”,难以提供决策过程的清晰解释。
- 知识更新困难:参数化知识库一旦固定,难以修改或扩展。
- 生成内容的幻觉问题:在缺乏外部知识支持时,可能生成与事实不符的内容。
方法详解RAG方法旨在通过结合预训练的参数化记忆和非参数化记忆提升模型性能。
解决方案
- 检索增强的生成模型:结合预训练的seq2seq模型和基于Wikipedia的向量索引。
- 端到端训练:检索器和生成器共同学习利用外部知识源。
- 知识源的动态更新:通过替换文档索引更新知识,无需重新训练。
- 生成内容的准确性提升:利用检索到的文档内容,减少幻觉,提高准确性。
关键步骤
- 预训练的检索器(DPR):使用基于BERTBASE的Dense Passage Retriever生成文档表示。
- 预训练的生成器(BART):使用BART-large进行文本生成。
- 端到端训练:联合训练检索器和生成器,最小化目标序列的负对数似然。
- 解码策略:根据RAG-Sequence和RAG-Token采用不同解码方法。
- 检索增强:使用最大内积搜索找到相关文档,作为生成上下文。
实验分析本文将探讨RAG模型在知识密集型任务上的应用效果,包括其在开放域问答和事实验证中的表现。
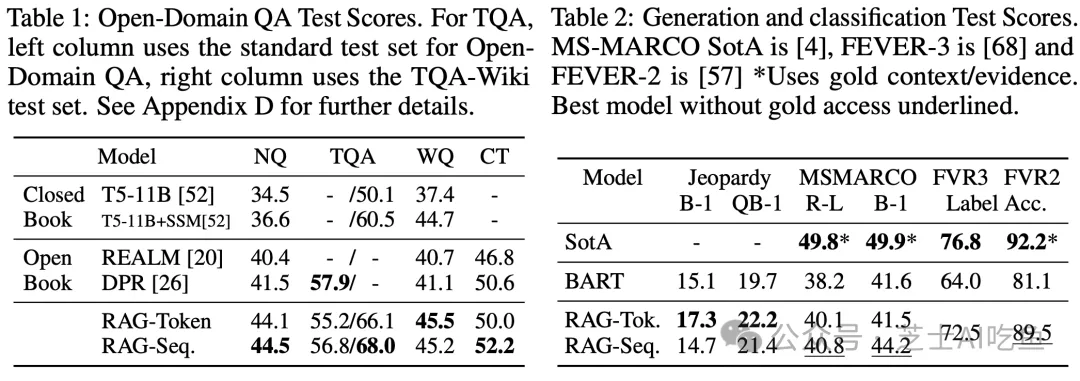
RAG模型在多个知识密集型任务中表现出显著的优势。以下是对RAG模型实验结果的详细分析:
-
性能提升:RAG模型在开放域问答(QA)任务上取得了业界领先的成绩,相较于传统的参数化序列到序列(seq2seq)模型,展现出更卓越的性能。
-
生成内容的改善:在语言生成任务中,RAG模型生成的文本不仅具体、多样,而且具有更强的事实性,超越了基线模型的表现。
-
知识更新的灵活性:RAG模型通过替换索引的方式,能够快速适应世界知识的变化,展现出良好的适应性和灵活性。
-
可解释性的提高:虽然RAG模型的可解释性还有提升空间,但其非参数化记忆的使用已经使得模型的决策过程更加透明,可以通过检查和验证检索到的文档来提高其可解释性。 尽管RAG模型在知识密集型任务中取得了显著进步,但未来研究仍需关注如何进一步提高模型的可解释性以及降低训练成本。

RAG模型评估与分析
概述RAG模型在知识密集型自然语言处理(NLP)任务中显示出显著的性能,特别是在开放域问答(QA)、抽象问答生成、Jeopardy问题生成和事实验证(FEVER)等方面。
创新点RAG模型的创新之处主要体现在以下几个方面:
- 混合内存架构:结合了参数化和非参数化记忆,允许模型利用外部知识源。
- 端到端训练:通过联合训练检索器和生成器,无需额外的检索监督。
- 灵活的检索机制:根据不同的输入动态检索相关信息,增强了模型的适应性和准确性。
- 实时知识更新:非参数化记忆的索引易于替换,以适应知识的变化。
不足与挑战尽管RAG模型取得了显著成果,但仍面临一些挑战:
- 检索崩溃:在某些情况下,检索器可能忽略输入的变化,导致生成器学习忽略检索到的文档。
- 训练成本:训练过程需要大量的计算资源,尽管不需要直接监督检索到的文档。
- 知识源的局限性:模型的性能受限于外部知识源的质量和覆盖范围。
- 解释性:模型的决策过程不够透明,尽管非参数化记忆提供了一定程度的可解释性。
结语RAG模型通过结合参数化和非参数化记忆,为知识密集型NLP任务提供了一种新的解决方案。它在多个任务上的成功表现证明了这种方法的有效性,并为未来的研究指明了方向,尤其是在如何更有效地结合两种记忆方面。尽管存在挑战,RAG模型为NLP领域带来了新的启示和可能性。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/RAG%E5%BC%80%E5%B1%B1%E4%B9%8B%E4%BD%9C%E7%9F%A5%E8%AF%86%E5%AF%86%E9%9B%86%E5%9E%8BNLP%E4%BB%BB%E5%8A%A1%E6%96%B0%E8%A7%A3%E6%B3%95--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


