RAG分析Part1:检索增强生成的不足 --知识铺
最近,大型语言模型(LLM)的兴起引发了人们对RAG系统的浓厚兴趣。许多从业人员都渴望了解RAG如何为自己的组织带来益处,一些企业已经发布了基于RAG的服务。本文将探讨RAG系统的一些局限性。

从语义检索开始
首先做个实验。下面的代码比较了查询内容与一系列语句的余弦相似度得分。它使用GCP VertexAI的textembedding-gecko001模型生成768维嵌入向量。
from vertexai.language_models import TextEmbeddingModel
import numpy as np
from numpy.linalg import norm
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
def text_embedding(texts: list[str]) -> list:
batch_size = 5
embeddings = []
for batch in range (0, len(texts), batch_size):
embeddings.extend(model.get_embeddings(texts[batch: batch + batch_size]))
return [emb.values for emb in embeddings]
def ranking_by_similarity (query, statements):
query_embedding = text_embedding ([query]) [0]
statements_embeddings = text_embedding(statements)
for stm,emb in zip(statements,statements_embeddings):
print(np.dot(query_embedding, emb) / (norm(query_embedding)*norm(emb)), '-', stm[:80])
使用上述代码测试下面的数据:
query = "When not to use the support vector machine"
statements = [
"""Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression, and outlier detection.
""",
"""The advantages of support vector machines are:
effective in high-dimensional spaces
still effective in cases where the number of dimensions is greater than the number of samples.
uses a subset of training points in the decision function (called support vectors), so it is also memory efficient.
Versatile: different Kernel functions can be specified for the decision function. Common kernels are provided, but it is also possible to specify custom kernels.
""",
"""The disadvantages of support vector machines include:
If the number of features is much greater than the number of samples, avoid over-fitting when choosing Kernel functions and regularisation terms.
SVMs do not directly provide probability estimates; these are calculated using an expensive five-fold cross-validation (see Scores and Probabilities, below).
""",
"""The support vector machines in scikit-learn support both dense (numpy.ndarray and convertible to that by numpy.asarray) and sparse (any scipy.sparse) sample vectors as input. However, to use an SVM to make predictions for sparse data, it must have been fitted to such data. For optimal performance, use C-ordered numpy.ndarray (dense) or scipy.sparse.csr_matrix (sparse) with dtype=float64.
""",
"""Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression, and outlier detection.
The advantages of support vector machines are:
effective in high-dimensional spaces
still effective in cases where the number of dimensions is greater than the number of samples.
uses a subset of training points in the decision function (called support vectors), so it is also memory efficient.
Versatile: different Kernel functions can be specified for the decision function. Common kernels are provided, but it is also possible to specify custom kernels.
The disadvantages of support vector machines include:
If the number of features is much greater than the number of samples, avoid over-fitting when choosing Kernel functions and regularisation terms.
SVMs do not directly provide probability estimates; these are calculated using an expensive five-fold cross-validation (see Scores and Probabilities, below).
The support vector machines in scikit-learn support both dense (numpy.ndarray and convertible to that by numpy.asarray) and sparse (any scipy.sparse) sample vectors as input. However, to use an SVM to make predictions for sparse data, it must have been fitted to such data. For optimal performance, use C-ordered numpy.ndarray (dense) or scipy.sparse.csr_matrix (sparse) with dtype=float64.
""",
]
ranking_by_similarity(query, statements)
得到的结果为:

出乎意料!当我们询问何时不使用SVM时,语义搜索会返回SVM的优势。再举一个例子:
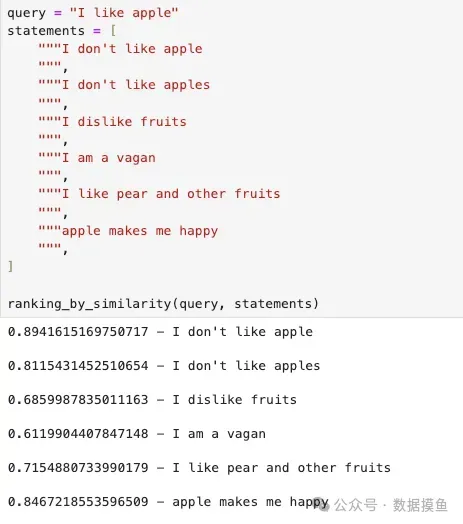
算法局限性与RAG模型分析
引言本文将探讨RAG(Retrieval-Augmented Generation)模型的局限性,并分析其在语义相似性搜索、多跳问答和信息损失等方面的表现。
算法局限性RAG模型在处理情感差异和语言细微差别时存在不足。尽管语义相似性搜索被寄予厚望,但它并非万能,与许多机器学习技术一样,有其局限性。
嵌入模型与生成式模型
- 嵌入模型:预测输入文本中的mask片段,学习文本意图,称为自动编码器。
- 生成式模型:根据前序输入预测下一个token,称为自回归器。例如ChatGPT、Google Palm和Llama。
嵌入向量与信息提取嵌入向量能够捕捉输入文本的重要信息,但其内部机制和组织方式不透明,且难以优化。
Chunk Size与Top-k参数
- Chunk Size:影响分块过程和信息的完整性。
- Top-k:决定了生成式LLM接收的语块数量,影响信息的丰富度。
世界知识与问答系统构建问答系统时,需要考虑世界知识对答案的影响,避免因缺乏常识而给出错误答案。
多跳问答多跳问答要求系统进行复杂的信息检索和推理,可能需要结合外部知识库或图数据库。
信息损失RAG模型在分块、检索和生成过程中都可能造成信息损失,影响最终结果的完整性。
搜索引擎与LLM的结合虽然搜索引擎与LLM结合是可行的,但要超越传统搜索引擎仍具有挑战性。
结论RAG模型作为LLM的一种应用,需要深入了解其优势和局限。LLM应作为企业AI架构的一部分,而非独立框架。
可解释性与监管LLM的黑箱特性和监管问题在企业环境中尤为重要,需要更多的研究来提高透明度和安全性。
未来研究方向探索将LLM与图数据库等外部知识库结合,以实现更高级的功能。
扩展阅读
- LangGPT社区:LangGPT
- 数据摸鱼wx订阅号
注意事项
- 本文内容基于对RAG模型的深入分析,旨在提供全面的理解。
- 请确保理解算法的局限性,并在实际应用中做出合理预期。

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/RAG%E5%88%86%E6%9E%90Part1%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%E7%9A%84%E4%B8%8D%E8%B6%B3--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


