RAG全栈技术最新综述 --知识铺
检索增强生成(RAG)概述
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了检索和生成的自然语言处理技术,旨在通过利用外部知识数据库来增强大型语言模型(LLMs)的能力,从而解决幻觉问题和知识更新的挑战。
组成部分
检索器(Retriever)检索器是RAG系统的关键组成部分,负责从外部知识库中检索与输入问题或任务相关的信息。这一过程通常涉及查询构建、信息检索和结果筛选等步骤。
检索融合(Retrieval Fusions)检索融合技术是RAG中将检索到的信息与语言模型结合的过程。这一技术可以采取多种方式,例如,将检索结果作为上下文输入到语言模型中,或者通过特定算法将检索结果与模型生成的内容进行融合。
生成器(Generator)生成器是RAG系统中负责生成最终输出的部分。它可以是一个预训练的语言模型,根据检索到的信息和输入问题生成答案或完成特定任务。
RAG训练策略
RAG的训练策略可以根据是否包含数据存储更新而有所不同:
- 带数据存储更新的RAG:在这种策略中,模型在训练过程中会不断更新其知识库,以保持信息的最新性。
- 不带数据存储更新的RAG:这种策略下,模型使用固定的知识库进行训练和推理,不进行在线更新。
RAG的应用
RAG技术在多种NLP任务和实际场景中展现出了其强大的应用潜力:
- 下游NLP任务:如问答系统、摘要生成、文本补全等。
- 实际NLP场景:包括但不限于客户服务、知识管理、教育辅助等。
教程代码以下是检索融合技术的示例代码,展示了如何将检索到的信息与语言模型的输出进行融合:
python# 示例代码,展示检索融合过程def retrieval_fusion(retrieved_info, model_output): # 融合逻辑 pass
请注意,上述代码仅为示例,实际应用中需要根据具体任务和模型进行调整。
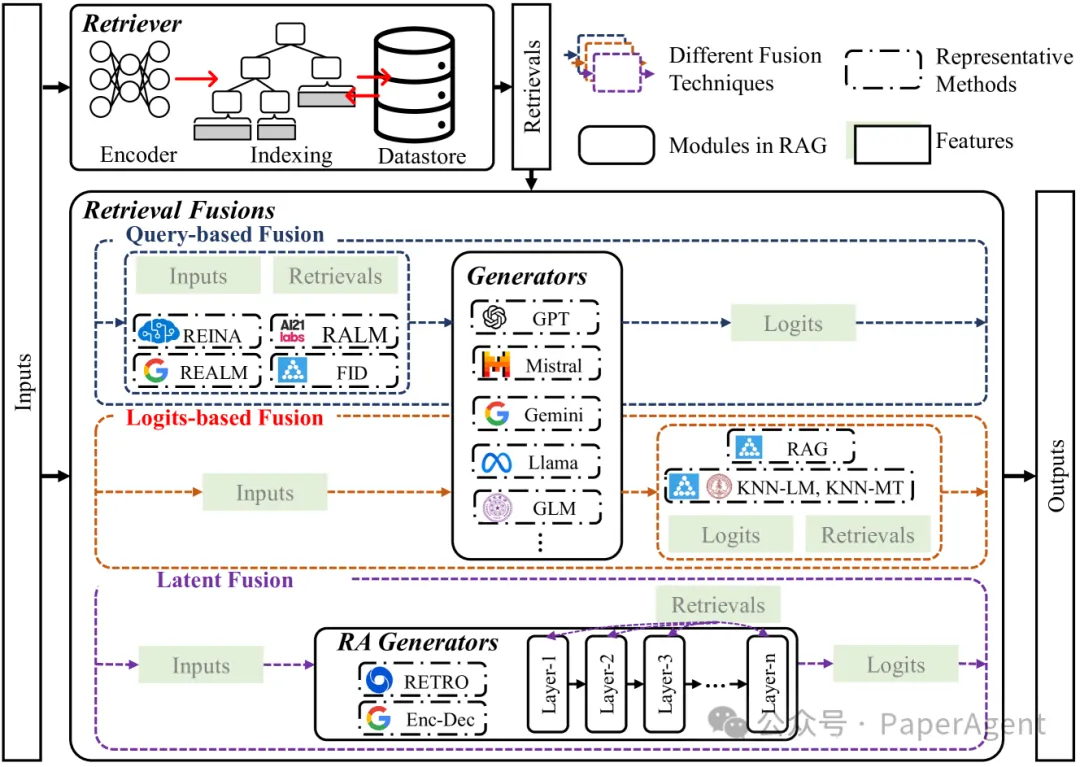
1. 检索器(Retriever)
检索器(Retriever) 是检索增强生成(RAG)中的一个关键组件,其主要作用是从一个外部知识库中检索与输入相关的信息。
使用检索器的两个阶段two-stages
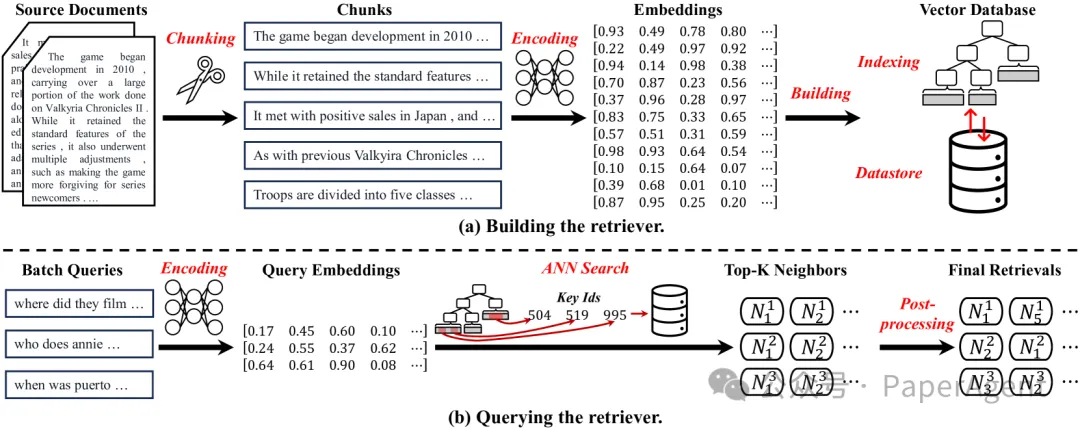
在构建高效的文档检索系统时,我们首先需要对文档进行分块处理,然后对这些块进行编码,并建立索引以支持快速检索。以下是构建阶段的关键步骤:
构建阶段
1. 分块语料库(Chunking Corpus)
- 固定长度分块:通过设定固定的长度参数,顺序地分割文档。
- 基于语义的分块:根据句号或新行等语义标志切割文档。
- 基于内容的分块:依据文档的结构特征,如电子病历的章节或代码的功能块进行分割。
2. 编码块(Encoding Chunks)
- BERT及其变体:使用RoBERTa、DistilBERT、ELECTRA等生成语义嵌入。
- Siamese Encoders:设计用于学习输入相似性的网络,如DPR、SimCSE。
- LLM-based Encoders:利用大型语言模型的表示能力,例如text-embedding-ada-002、bge-embedding。
- 稀疏编码:如词袋模型(BoW)、TF-IDF,通过高维向量表示文本。
- 密集编码:使用深度学习模型生成向量,捕捉语义特征。
3. 索引构建(Building the Index)
- 索引的目的是加速多维查询嵌入的搜索过程,主要关注近似最近邻搜索的效率。
4. 选择相似性度量(Choice of Similarity Metrics)
- 使用余弦相似度、欧几里得相似度等衡量查询与块嵌入的相关性。
5. 降维(Dimension Reduction on Embeddings)
- 主成分分析(PCA):转换数据到新坐标系,保留重要特征。
- 局部敏感哈希(LSH):通过桶映射降低维度,保留相似性。
- 乘积量化(PQ):划分高维空间为更小的量化子空间。
6. 高级ANN索引(Advanced ANN Indexing)
- IVFPQ:结合倒排文件和乘积量化,用于ANN搜索。
- HNSW:使用分层图结构执行ANN搜索。
- 基于树的索引:如KD-Trees等,组织高维向量。
7. 构建数据存储(Building the Datastore with Key-Value Pairs)
- 使用LMDB或RocksDB等数据库存储数据,支持检索和数据持久性。
- 向量数据库如Milvus、FAISS、LlamaIndex等,提供索引和数据存储。
查询阶段
在查询阶段,使用相同的编码器对查询进行编码,并利用预建索引和数据存储进行近似最近邻搜索,以检索相关值。
2. 检索融合(Retrieval Fusions)
- 探讨如何将检索到的知识整合到生成模型中,提高性能。
RAG中融合方法的类别
- 这部分内容需要进一步阐述,以展示如何在检索增强生成(RAG)模型中融合不同的方法。
注意:以上内容是对原始文本的结构化重写,确保了条理性和逻辑性。
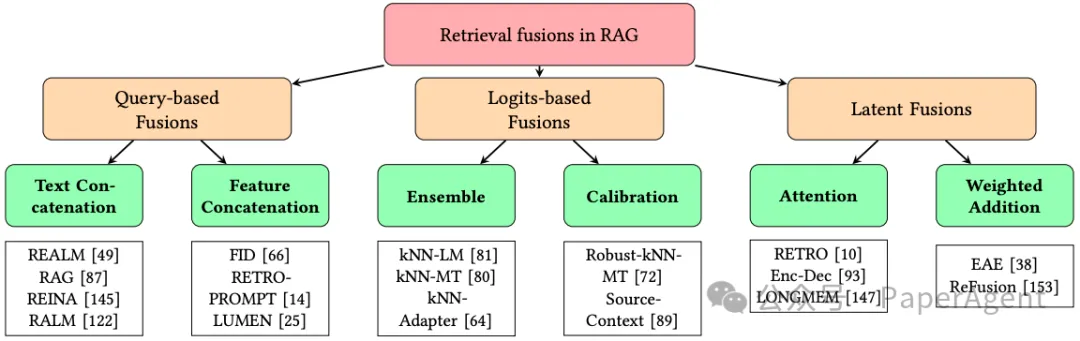
检索增强生成(RAG)技术概述
检索融合类型
基于查询的融合(Query-based Fusion)
- 文本连接:将检索到的文本与查询文本直接连接。
- 特征连接:检索文本编码为特征向量后与查询特征合并。
- FID:特征融合方法,将检索文本编码为稀疏或密集表示。
潜在融合(Latent Fusion)
- 基于注意力的融合:使用交叉注意力机制嵌入检索知识。
- RETRO:引入新交叉注意力模块的检索增强预训练语言模型。
- 加权添加:通过学习权重将检索知识以加权方式添加。
基于对数的融合(Logits-based Fusion)
- 集成融合:结合检索知识对数与模型输出对数。
- kNN-LM 和 kNN-MT:利用最近邻模型对数增强语言模型和机器翻译。
- 校准融合:使用检索知识对数校准模型预测。
生成器(Generator)
生成器类型
- 默认生成器:如GPT系列、Mistral、Gemini等大型语言模型。
- 检索增强生成器:包含融合检索信息模块的预训练/微调生成器。
生成器的功能生成器基于输入和检索结果生成文本。
生成器的架构通常采用或修改基于Transformer的架构,专注于解码器模块。
RAG训练策略
RAG的不同训练策略
- 包括/不包括数据存储更新
注意事项
- 内容需有条理性、结构性。
- 使用Markdown格式。
- 特定字段替换为’aaaaaaa’。
以上内容为检索增强生成(RAG)技术的简要概述,涵盖了融合类型、生成器类型及其特点和功能,以及RAG模型的训练策略。
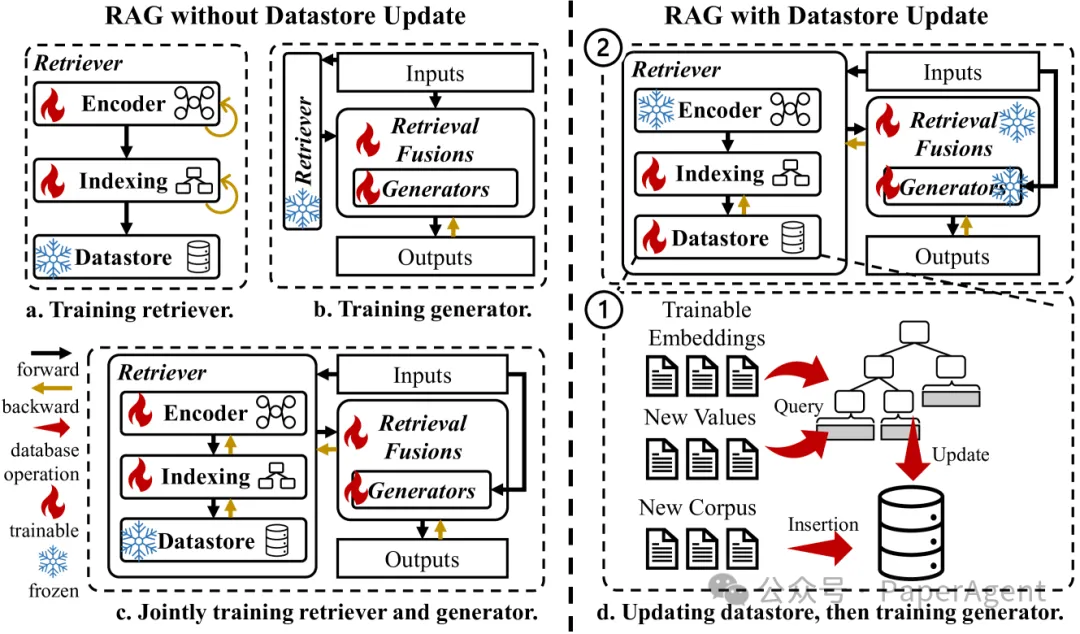
RAG 训练分类与数据存储更新
RAG 训练类型
- 不更新数据存储的RAG训练:此类型训练专注于更新RAG模型中各个模块的可训练参数,而数据存储中的知识保持原样。
- 更新数据存储的RAG训练:首先更新数据存储中的知识,然后对RAG模型中的参数进行更新。
数据存储更新(RAG without Datastore Update)
检索器训练(Training Retriever)
- 训练检索器编码器并重建索引,通常采用密集编码方法。
- 根据训练目标,可能需要更换编码器或使用对比学习来训练现有编码器。
生成器训练(Training Generator)
- 更新生成器的参数或检索融合模块中的参数。
- 采用参数高效的微调技术,例如LoRA,以解决大型语言模型(LLMs)的微调问题。
联合训练检索器和生成器(Jointly Training Retriever and Generator)
- 同时训练检索器和生成器以提升下游任务的性能。
- 确保从输入到输出的正向过程中的可微性,实现端到端优化。
数据存储更新(Datastore Update)
- 涉及两个阶段:先更新知识库,然后训练检索器和生成器。更新知识库有三种情况:用可训练的嵌入更新、用新值更新和用新语料库更新。
- 第一种情况中,值通常是可训练的嵌入,并且与RAG中的参数同时或异步更新。最后两种情况通常指的是用最新信息更新知识库。
- 以问答语料库为例,用新值更新指的是更新现有问题的答案,而用新语料库更新指的是添加新的问答对。更新现有键的值需要先查询现有的键值对,然后执行就地更新。对于新的语料库,数据存储需要先执行插入操作,然后重建或更新新键的索引。更新数据存储后,训练检索器和生成器的过程与没有数据存储更新的RAG相似。
RAG的应用场景
RAG技术在NLP任务中的应用
LLM-based Autonomous Agents
- 利用RAG技术为基于大型语言模型的自主智能体提供更广泛的信息访问能力,增强其决策和问题解决能力。
- 智能体可以使用RAG从自己的外部记忆中检索相关信息,以增强其理解和决策能力。
- 智能体还可以利用工具搜索网络,获取最新信息,这对于需要最新知识的情境非常有用。
框架(Frameworks)
- 介绍了如Langchain和LLaMAindex等框架,它们通过集成复杂的检索机制与生成模型,促进了外部数据在语言生成过程中的整合。
https://arxiv.org/pdf/2407.13193
推荐阅读材料
以下是为您精心挑选的几篇关于RAG(Retrieval-Augmented Generation)技术及其应用的深度文章,这些文章深入浅出地探讨了RAG技术的原理、应用案例以及实现方法。
RAG高效应用指南系列
- RAG高效应用指南:Query理解 深入探讨了Query理解的重要性和实现技术,以及如何在RAG系统中提高Query理解的性能。
- RAG组合拳:AGI应用走向落地的40%(下篇)–附100M文档资料 继上篇之后,本文详细介绍了RAG在实际应用中的优化策略,包括Rerank环节和生成环节的改进,以及如何通过RAGAS评估框架进行系统性能评估。
- 手把手教你构建Agentic RAG:一种基于多文档RAG应用的AI Agent智能体 本文将引导读者一步步构建基于多文档的RAG应用,介绍了Agentic RAG的概念、实现方法以及如何优化以适应更复杂的企业级知识库需求。
关注我们,获取更多AI技术动态和深度解析。
👆👆👆欢迎关注👆👆👆
互动环节
- 分享:将这些有价值的内容分享给需要的朋友。
- 点赞:如果你觉得这些材料对你有帮助,别忘了点赞支持。
- 在看:持续关注,获取更多更新。 你最好看!👇
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/RAG%E5%85%A8%E6%A0%88%E6%8A%80%E6%9C%AF%E6%9C%80%E6%96%B0%E7%BB%BC%E8%BF%B0--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


