PDF文档向量化详细过程 --知识铺
读取文件
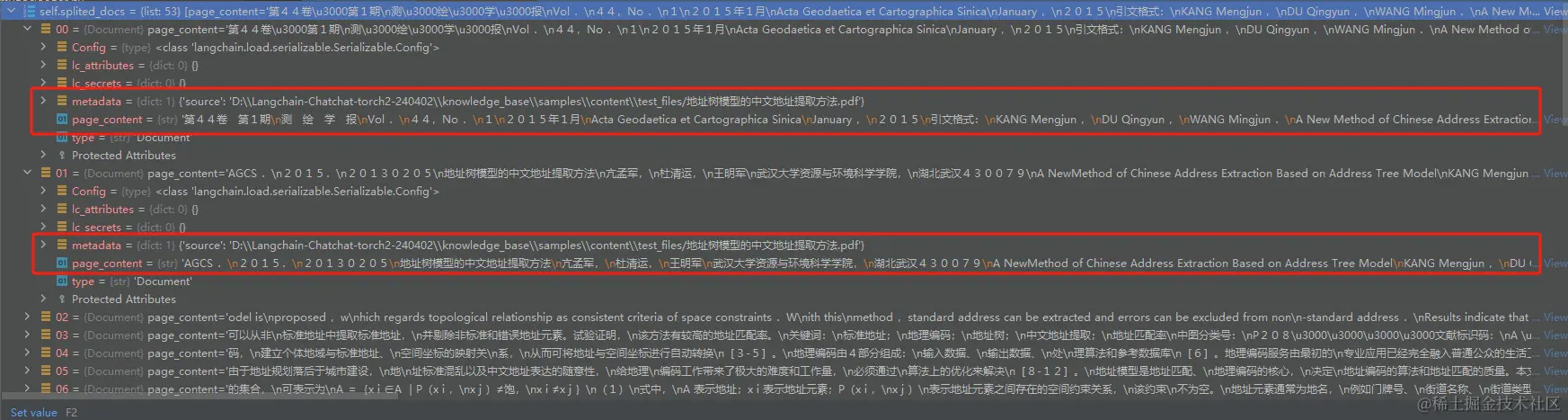
使用的 pdf 文档是一个 地址树模型的中文地址提取方法.pdf 文档,内容截图如下:

参数说明
基本的文档处理参数如下:
chunk_overlap = 50
chunk_size = 250
embed_model = 'm3e-large'
vs_type = 'fassi'
zh_title_enhance = False
在进行文本处理时,合理设置参数对于确保信息完整性和处理效率至关重要。以下是对几个关键参数的详细解释:
-
文本块重叠量 (
chunk_overlap): 此参数设置为50,意味着在分割文本时,每个块与相邻块之间会有50个字符的重叠部分。这有助于确保在文本块的边界处不会遗漏任何重要信息。 -
文本块大小 (
chunk_size): 每个文本块的大小设定为250个字符。通过将长文本分割成这样的小块,可以更高效地进行文本分析和处理。 -
文本嵌入模型 (
embed_model): 这里使用的是m3e-large模型,它负责将文本转换为向量形式,以便更好地表示和分析文本数据。 -
向量数据库类型 (
vs_type): 指定使用的向量数据库为fassi,这关系到文本向量的存储和检索方式。 -
中文标题增强 (
zh_title_enhance): 此布尔参数控制是否对中文标题进行增强处理。设置为False表示不进行任何增强。 此外,针对PDF文件的处理,可以使用自定义的RapidOCRPDFLoader类作为加载器。以下是使用此加载器的日志打印示例:[日志信息]
RapidOCRPDFLoader used for D:\Langchain-Chatchat-torch2-240402\knowledge_base\samples\content\test_files/DRL.pdf
在处理PDF文档转换为文本的任务中,核心逻辑集中在pdf2text函数。以下是详细的步骤和逻辑结构:
- PDF文档打开:使用
fitz库打开PDF文件,doc = fitz.open(filepath),获取整个文档的页面列表。 - 页面遍历:遍历
doc列表,对每一页page进行操作。 - 文本识别:若页面
page包含文本,使用OCR技术识别并获取文本内容,将其添加到响应字符串resp中。 - 图片处理:如果页面包含图片,执行可能的旋转和OCR识别,提取图片中的文本,并将结果添加到
resp。 - 文本整合:完成所有页面的处理后,将
resp中的文本整合,形成一个长字符串。 - 文本切分:由于长字符串不易于向量化处理,使用
partition_text函数,根据内置算法将长文本切分成较短的字符串列表。 通过以上步骤,我们能够将PDF文档中的所有文字信息提取并整理成一个易于处理的文本列表。
class RapidOCRPDFLoader(UnstructuredFileLoader):
def _get_elements(self) -> List:
def rotate_img(img, angle):
'''
img --image
angle --rotation angle
return--rotated img
'''
h, w = img.shape[:2]
rotate_center = (w/2, h/2)
#获取旋转矩阵
# 参数1为旋转中心点;
# 参数2为旋转角度,正值-逆时针旋转;负值-顺时针旋转
# 参数3为各向同性的比例因子,1.0原图,2.0变成原来的2倍,0.5变成原来的0.5倍
M = cv2.getRotationMatrix2D(rotate_center, angle, 1.0)
#计算图像新边界
new_w = int(h * np.abs(M[0, 1]) + w * np.abs(M[0, 0]))
new_h = int(h * np.abs(M[0, 0]) + w * np.abs(M[0, 1]))
#调整旋转矩阵以考虑平移
M[0, 2] += (new_w - w) / 2
M[1, 2] += (new_h - h) / 2
rotated_img = cv2.warpAffine(img, M, (new_w, new_h))
return rotated_img
def pdf2text(filepath):
import fitz # pyMuPDF里面的fitz包,不要与pip install fitz混淆
import numpy as np
ocr = get_ocr()
doc = fitz.open(filepath)
resp = ""
b_unit = tqdm.tqdm(total=doc.page_count, desc="RapidOCRPDFLoader context page index: 0")
for i, page in enumerate(doc):
b_unit.set_description("RapidOCRPDFLoader context page index: {}".format(i))
b_unit.refresh()
text = page.get_text("")
resp += text + "\n"
img_list = page.get_image_info(xrefs=True)
for img in img_list:
if xref := img.get("xref"):
bbox = img["bbox"]
# 检查图片尺寸是否超过设定的阈值
if ((bbox[2] - bbox[0]) / (page.rect.width) < PDF_OCR_THRESHOLD[0]
or (bbox[3] - bbox[1]) / (page.rect.height) < PDF_OCR_THRESHOLD[1]):
continue
pix = fitz.Pixmap(doc, xref)
samples = pix.samples
if int(page.rotation)!=0: #如果Page有旋转角度,则旋转图片
img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.height, pix.width, -1)
tmp_img = Image.fromarray(img_array);
ori_img = cv2.cvtColor(np.array(tmp_img),cv2.COLOR_RGB2BGR)
rot_img = rotate_img(img=ori_img, angle=360-page.rotation)
img_array = cv2.cvtColor(rot_img, cv2.COLOR_RGB2BGR)
else:
img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.height, pix.width, -1)
result, _ = ocr(img_array)
if result:
ocr_result = [line[1] for line in result]
resp += "\n".join(ocr_result)
# 更新进度
b_unit.update(1)
return resp
text = pdf2text(self.file_path)
from unstructured.partition.text import partition_text
return partition_text(text=text, **self.unstructured_kwargs)
在处理文本数据时,我们首先需要对其进行封装,以便于后续的向量化处理。封装后的文本数据将被组织成多个Document对象,这些对象将有助于我们进行高效的数据管理和索引。每个Document对象包含两个主要部分:‘pagecontent’和’metadata’。‘pagecontent’部分存储了文本的具体内容,而’metadata’部分则存储了与文本内容相关的元数据,例如文件的存储位置等信息。
通过这种方式,我们能够确保文本数据的结构化和有序化,为后续的数据分析和处理打下坚实的基础。
构建向量库流程
1. 选择向量模型在文本处理和信息检索领域,选择合适的向量模型至关重要。本文以 m3e-large 模型为例,该模型能够将文本内容转化为向量形式,为后续的检索和问答提供基础。
2. 选择向量数据库向量数据库的选择同样关键,本文选用的 fassi 是一个高效的向量数据库,它能够存储和管理大量的向量数据,支持快速检索。
3. 文本向量化将处理好的文本内容通过 m3e-large 模型进行向量化处理,生成对应的向量表示。
4. 存入向量数据库将生成的向量数据存入 fassi 数据库中,确保数据的组织和索引,便于后续的检索和使用。
5. 结合大模型进行问答和检索利用存储在 fassi 中的向量数据,结合大型语言模型,可以进行高效的文档问答和检索操作。
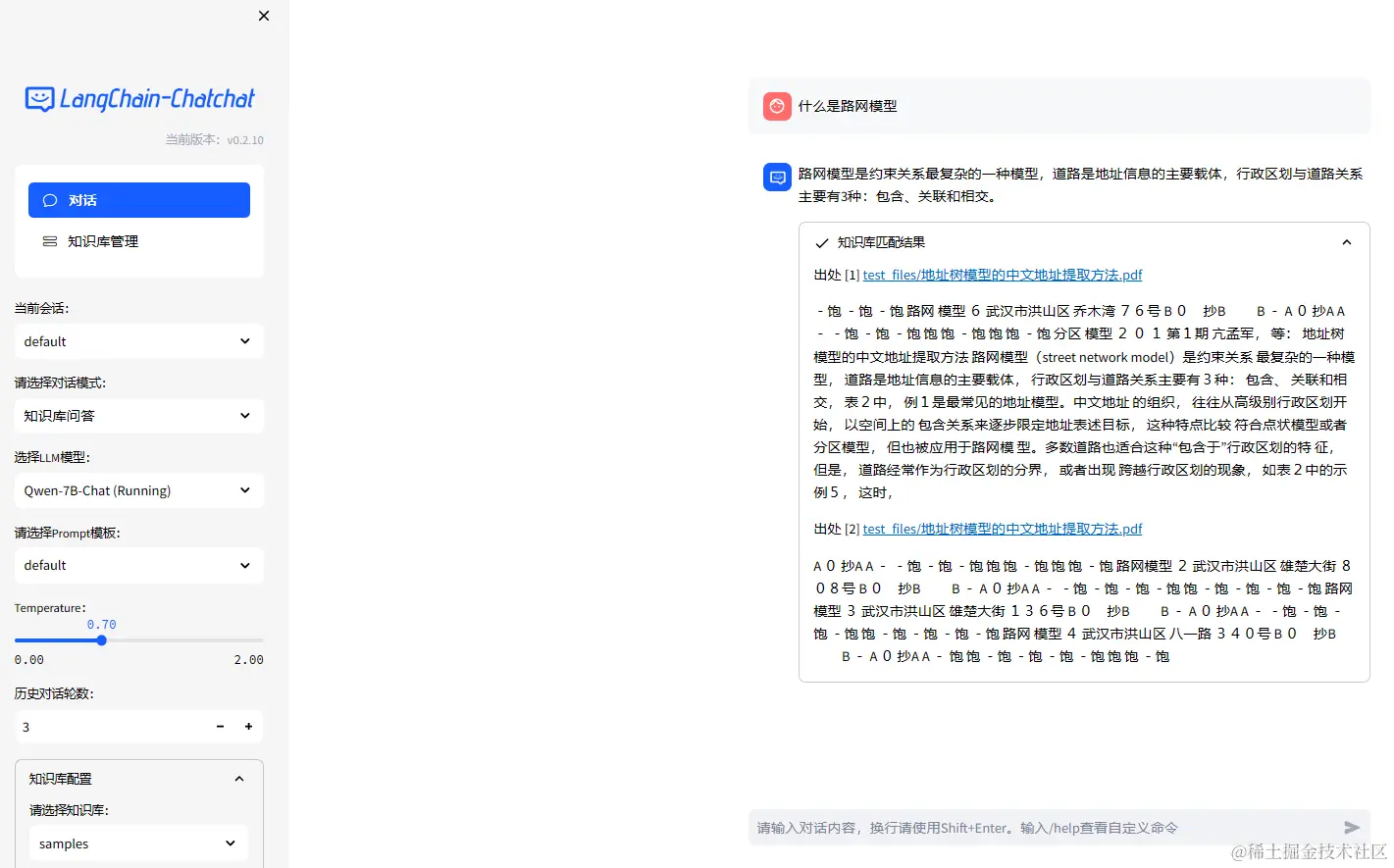
问答示例以下是使用本文档进行问答的一个示例过程:
-
问题: 如何选择合适的向量模型?
-
回答: 选择合适的向量模型需要考虑模型的精度、效率以及适用场景。
m3e-large是一个性能优秀的选择,适用于多种文本处理任务。 -
问题: 向量数据库的作用是什么?
-
回答: 向量数据库用于存储和管理向量化后的文本数据,支持高效的数据检索和分析,
fassi是一个表现出色的向量数据库。 -
问题: 文本向量化的步骤有哪些?
-
回答: 文本向量化主要包括文本预处理、模型转换和向量生成三个步骤,
m3e-large模型能够高效完成这一过程。 -
问题: 如何利用向量数据进行检索?
-
回答: 利用
fassi数据库中的向量数据,结合语言模型,可以实现快速准确的文档检索和问答功能。
结论通过上述步骤,可以构建一个高效的文本向量库,为文档的问答和检索提供强大的支持。
如何学习大模型
作为一名经验丰富的互联网从业者,我决定将我积累的AI知识分享给所有对人工智能感兴趣的朋友。能否掌握这些知识,取决于你的学习决心和能力。我已经整理并免费分享了一系列重要的AI大模型学习资料,包括思维导图、书籍、视频教程以及实战案例。
一、大模型学习路线图
掌握大型人工智能模型,例如GPT-3、BERT或其他先进神经网络,需要一个系统化的学习计划和持续的实践。下面是一份详细的学习路线图,它将帮助你快速构建知识框架,形成自己的学习体系。 L1级别:AI大模型时代的入门
-
基础概念:了解AI大模型的基本概念和原理。
-
工具准备:熟悉必要的编程语言和开发工具。
-
入门教程:通过在线教程和书籍,学习基础的机器学习知识。
-
实践操作:通过简单的项目实践,加深对AI大模型的理解。 L2级别:深入理解与应用
-
模型研究:深入研究不同AI大模型的架构和功能。
-
技术深化:学习更高级的技术,如自然语言处理、图像识别等。
-
项目实战:参与更复杂的项目,将理论知识应用于实践。 L3级别:专业技能与创新
-
领域专精:选择一个AI领域进行深入研究和实践。
-
创新探索:尝试开发新的模型或改进现有模型。
-
社区贡献:参与开源项目,与社区分享你的知识和经验。 L4级别:领导与影响
-
团队领导:领导团队进行AI项目的研发。
-
行业影响:通过发表文章、演讲等方式,对行业产生影响。
-
持续学习:跟踪最新的AI技术发展,不断更新自己的知识库。 通过上述学习路线,你可以逐步建立起自己的AI大模型知识体系,并在实践中不断提升自己的专业技能。
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

在职场发展中,专业技能的掌握程度往往决定了个人能胜任的岗位类型和层次。对于AI大模型的学习,一般而言,达到第四个级别,即L4级别,便能够满足市场上大多数岗位的需求。然而,要达到行业的顶尖水平,即所谓的’天花板’级别,对算法的理解和实战经验的要求则更为严格和苛刻。对于大多数人来说,掌握到L4级别是一个合理的目标。
AI大模型学习路线的高清版资料,可以通过扫描下方的CSDN官方认证二维码免费获取,我们保证资料的获取过程是100%免费的。

640份AI大模型报告合集概览
介绍这套报告合集汇集了640份关于人工智能大模型的深度研究报告,覆盖了理论研究、技术实现和行业应用等多维度内容。它旨在为不同背景的读者提供全面而深入的视角。 目标读者无论是在科研领域深耕的学者、在工程界实践的技术专家,还是对人工智能抱有浓厚兴趣的普通爱好者,都能在这套报告中找到所需的信息和灵感。 报告内容
- 理论研究:探讨AI大模型的数学基础、算法原理及其理论发展。
- 技术实现:介绍AI大模型的构建过程、关键技术和实现方法。
- 行业应用:分析AI大模型在不同行业中的应用案例和潜在价值。 价值与启示这套报告合集不仅是知识的宝库,更是启发思考和创新的源泉。它能够帮助读者更好地理解AI大模型的现在与未来,激发新的研究思路和技术探索。 获取方式如需获取这套640份AI大模型报告合集,请按照指定渠道进行申请或购买,以获得完整资料。 注意事项
- 请确保在合法和合规的前提下使用这些报告。
- 尊重知识产权,合理引用报告内容。
结语AI大模型正以其强大的能力改变世界,这套报告合集将助您一臂之力,深入了解并把握这一变革的脉搏。

人工智能大模型经典PDF籍推荐
在人工智能领域,大模型以其卓越的语言处理能力,正迅速成为研究和应用的焦点。以下是一些精选的PDF籍,它们是深入了解和学习AI大模型的宝贵资源。
1. GPT-3模型GPT-3是目前最知名的大型语言模型之一,以其生成文本的多样性和准确性而闻名。学习GPT-3的机制和应用,对于理解现代AI语言模型至关重要。
2. BERT模型BERT模型通过其双向编码器的特性,为自然语言处理领域带来了革命性的变化。了解BERT的工作原理,有助于掌握当前NLP技术的核心。
3. XLNet模型XLNet作为BERT的后继者,通过其创新的排列语言模型,进一步推动了语言理解的边界。探索XLNet,可以让我们洞悉AI在语言理解方面的最新进展。
4. 大模型的应用大模型不仅在理论研究中占据重要地位,它们在实际应用中也展现出巨大的潜力。从文本生成到机器翻译,大模型正在不断拓展人工智能的应用领域。
5. 学习资源为了更好地学习这些大模型,以下是一些推荐的PDF籍,它们涵盖了从基础理论到高级应用的各个方面:
- 基础理论: 了解大模型的工作原理和背后的数学基础。
- 高级应用: 探索如何将大模型应用于复杂的实际问题中。
- 案例研究: 通过实际案例,学习如何有效利用大模型解决具体问题。
通过阅读这些PDF籍,你将能够更全面地理解AI大模型,并掌握如何将它们应用于实际问题中。
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/PDF%E6%96%87%E6%A1%A3%E5%90%91%E9%87%8F%E5%8C%96%E8%AF%A6%E7%BB%86%E8%BF%87%E7%A8%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


