Milvus 向量数据库进阶系列丨构建 RAG 多租户多用户系统 (上) --知识铺
专栏/
Milvus 向量数据库进阶系列丨构建 RAG 多租户/多用户系统 (上)
2024年08月05日 18:35214浏览 · 1点赞 · 0评论
[

Milvus向量数据库进阶系列
在与社区成员的交流过程中,我们了解到大家最为关切的是如何针对具体的实战场景选择合适的向量数据库解决方案或功能组合。因此,在"Milvus向量数据库进阶"这一系列文章中,我们将着重解答这些问题,例如:“在AI应用开发的不同阶段应如何进行向量数据库的选型”,以及"如何正确地构建RAG多租户系统"等。尽管这个系列被命名为"进阶",但其内容同样适合初级用户。
上期回顾
Milvus是一款成熟的开源向量数据库,它提供了三种不同的部署形态:Milvus Lite、Standalone和Distributed,以满足从原型设计到大规模生产环境的不同需求。在上一篇文章中,我们深入探讨了这三种部署形态的特点、适用场景以及如何根据项目的不同阶段和数据规模来选择最适合的Milvus部署方式。此外,还对比分析了其他开源向量数据库,包括Qdrant、Weaviate和Chroma等,介绍了它们的特点及适用范围。
构建RAG多租户系统
1. 什么是RAG(Retrieval-Augmented Generation)
2. 多租户系统的挑战与机遇
-
挑战:
-
数据隔离与安全性
-
资源分配与优化
-
管理与监控
-
机遇:
-
提高资源利用率
-
降低运营成本
-
增强用户体验
3. 如何利用Milvus构建RAG多租户系统
-
设计原则:
-
明确租户间的逻辑与物理隔离策略
-
确保数据安全性和隐私保护
-
实现资源的动态分配
-
实现步骤:
-
配置合适的Milvus部署形态
-
设计数据访问控制机制
-
实施性能监控与优化 通过本系列文章,我们希望能够帮助开发者们在向量数据库的应用过程中避免常见的陷阱,并提供实用的指导和建议。

用户数据组织与权限控制
用户数据组织与权限控制是构建RAG(Retrieval-Augmented Generation)多租户或多用户系统的核心要素。在向量数据库中合理地组织用户数据,并确保适当的数据访问权限对于实现高效、安全的服务至关重要。
数据组织层次
面向生产的向量数据库系统通常会提供多层次的数据组织能力。以Milvus为例,数据组织可以分为三个层级:
- Database(数据库)
- 这是最顶层的数据组织单位,可以用来区分不同的业务场景或租户。
- Collection(集合)
- Collection位于Database之下,用于存储特定类型的数据集。
- Partition Key/Partition(分区键/分区)
- Partition Key/Partition用于进一步细分数据,便于管理和查询。
组织示例
假设我们需要为一家企业客户建立一个大型知识库,我们可以按照以下方式组织数据:
-
Database: 为每个企业客户创建一个独立的Database,比如
CompanyA_DB和CompanyB_DB。 -
Collection: 在每个Database中,可以根据数据的用途或类别来创建多个Collection。例如,在
CompanyA_DB中,可以创建Product_Info_Coll和FAQs_Coll等Collection。 -
Partition Key/Partition: 对于每个Collection,还可以根据时间、地理位置或其他标准进行分区。例如,在
Product_Info_Coll中,可以按季度或产品线创建分区。
权限控制
-
租户隔离: 每个租户的数据被严格隔离在各自的Database中,保证数据安全性。
-
细粒度访问控制: 利用Role-Based Access Control (RBAC)等机制,对不同角色的用户授予不同的访问权限。
-
审计与监控: 实施审计和监控措施,记录数据访问行为,以便追踪和审查。 通过上述方式,不仅可以有效地组织和管理用户数据,还能确保数据的安全性和隐私性。
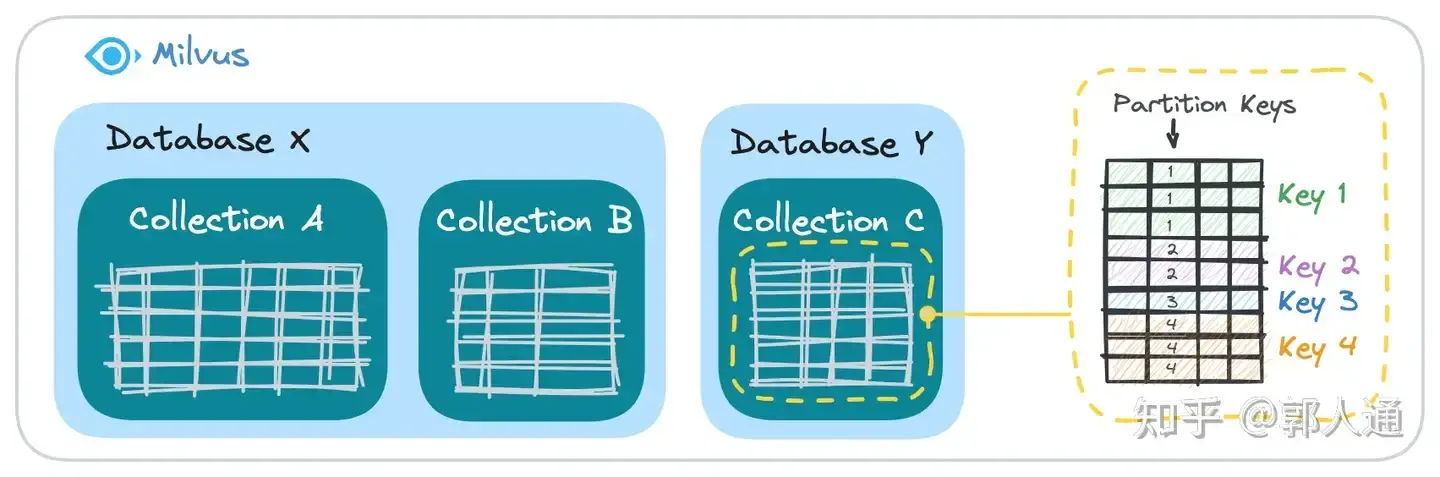
数据组织结构概述
Milvus 采用多层次的数据组织结构来管理数据,包括 Database、Collection 与 Partition Key。这一设计不仅确保了高效的数据存储和检索,还提供了灵活的权限控制。
Database
-
概念:类似于传统关系型数据库中的
Database,它代表了一个逻辑上的数据库单元。 -
作用:提供数据隔离和高级别的组织框架。
Collection
-
概念:位于
Database内部,相当于传统意义上的Table。 -
作用:用于存储具体的数据集合。
Partition Key
-
概念:用于对
Collection内的数据进行逻辑分组。 -
作用:具有相同
Partition Key的数据会被划分到相同的逻辑组内,便于按特定粒度进行数据查询。
权限控制
Milvus 支持基于角色的访问控制(RBAC),允许系统管理员为每个用户设定数据访问范围及权限级别。
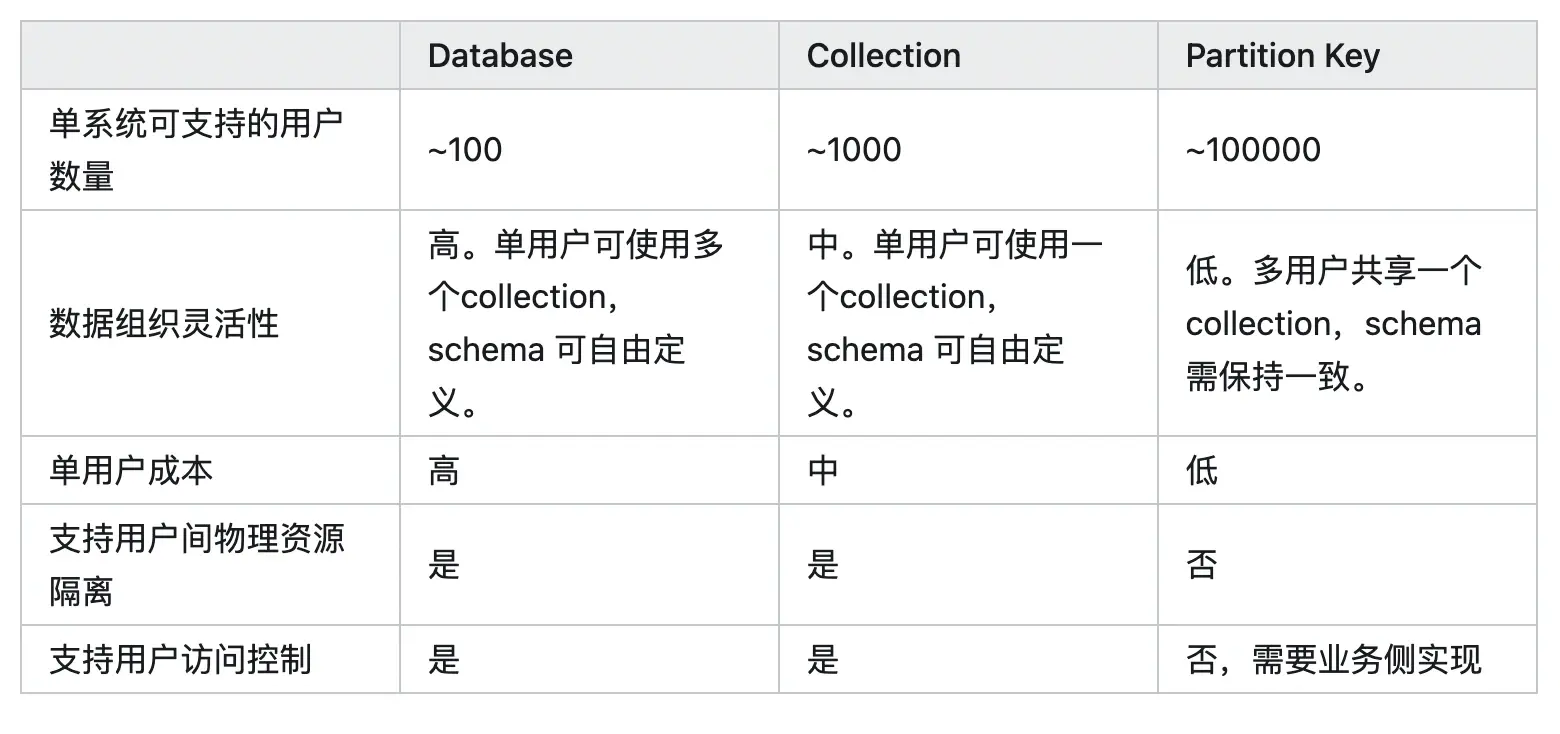
数据组织粒度与灵活性
-
高粒度(Database):为每个用户分配单独的
Database可以提供高度的数据组织灵活性,适用于有特殊需求的场景。但这种方式可能会增加单个用户的成本,并限制系统能够支持的用户数量。 -
低粒度(Partition Key):为每个用户分配一个
Partition Key可以极大提高系统的用户支持能力,并降低单个用户的成本。然而,这要求所有用户的数据 schema 必须保持一致,减少了数据组织的灵活性。 | 组织粒度 | 优点 | 缺点 | | – -
| –
-
| –
-
| | Database | 高度灵活性,适应广泛业务需求 | 单用户成本较高,支持用户数较少 | | Partition Key | 极高的用户支持能力,单用户成本低 | 数据组织需要固定,schema 必须一致 | aaaaaaa
To B大型知识系统的多租户设计
在To B的大型知识系统中,通常涉及较少但规模较大的租户,例如企业内部的不同业务团队或部门。当这些团队或部门各自运营着独立的知识库服务时,数据库中台团队会将每一个业务单元视为一个独立的租户。
数据库层面的设计
-
Database分配:中台团队基于业务复杂度为每个租户分配一个或多个Database,以实现不同业务之间的数据隔离。
-
灵活性赋予租户:给予租户高度自由度来管理其Collection层级,包括数据模型定义、Collection创建的数量以及对不同Collection上用户访问权限的控制等。
-
支持差异化使用:这样的多租户设计能够有效支持各个业务团队根据自身需求对向量数据库进行差异化的利用。 通过上述策略,To B大型知识系统的多租户设计能够在确保数据安全和隔离的同时,提供足够的灵活性以适应各种复杂的业务场景。
逻辑层到物理层的映射
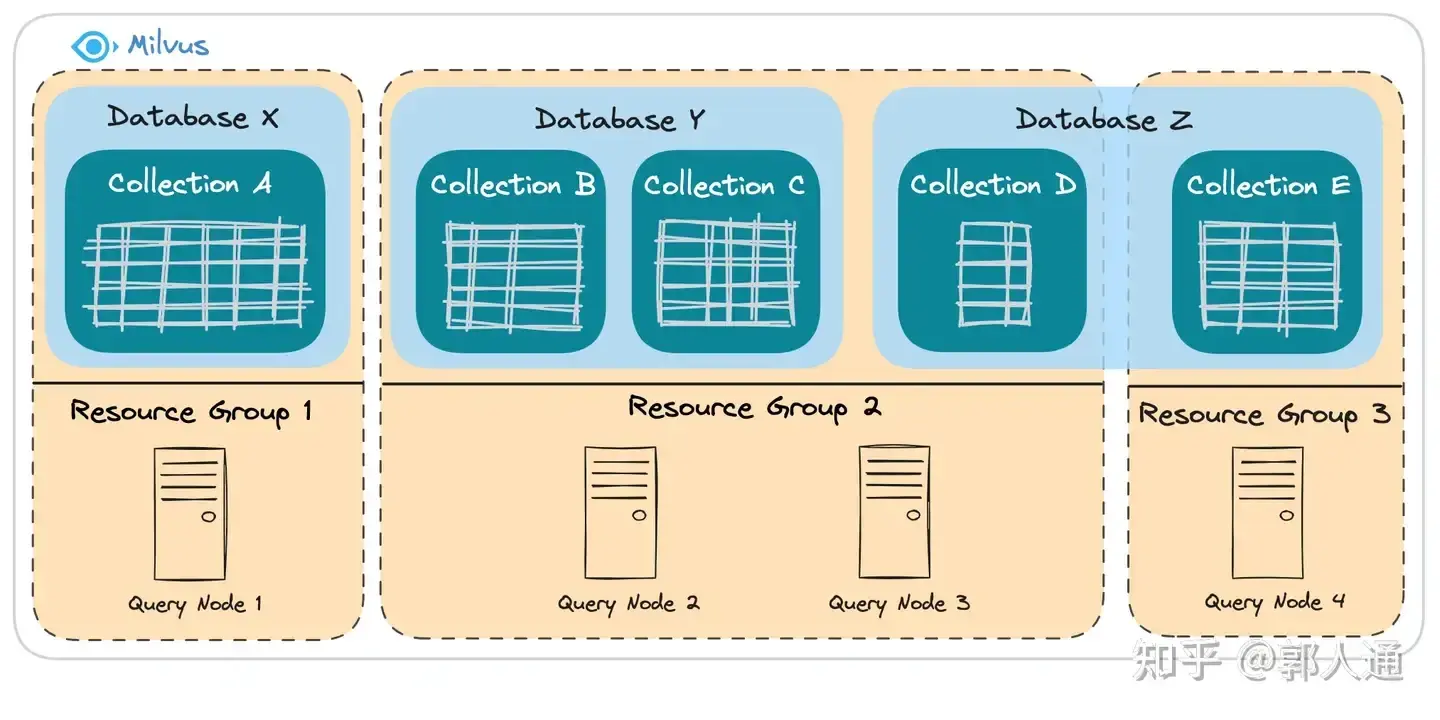
很多时候,为了保障核心业务的服务质量,除了需要在Database粒度上实现逻辑隔离之外,还需要关注物理隔离。Milvus支持从逻辑层的Database和Collection到物理层资源的映射。如下图所示,从下到上可以分为三层概念:Query Node、Resource Group和Database。
在Milvus系统内部,Query Node是支撑查询任务的关键组件,并且每一个Query Node部署在一个物理节点上,例如一台物理机或一个Pod。一个或多个Query Node可以组成一个Resource Group,而每个Resource Group是承载逻辑到物理映射的基本单元:可以将一个或多个Database或Collection映射到一个Resource Group。
例子说明
-
假设有三个逻辑上的
Database:X、Y和Z。假设Database X所支撑的知识库非常关键,因此我们希望它不受其他Database的负载干扰。所以,将X单独分配到了一个Resource Group。 -
同样地,
Collection E也单独分配了一个Resource Group。这里存在两种不同的模式:一种是对整个Database进行物理隔离;另一种则是将某个Database中的特定Collection单独拿出来进行物理隔离。 -
对于
Database Y和Z中的所有其他Collection,我们让它们共享Resource Group 2的物理资源。
用户层设计
通常情况下,企业级知识库的用户都是以只读的方式进行服务访问。此外,我们往往还会关心这些用户产生的问答数据,或者希望建立数据与用户的关联。比如,在一个医院的智能咨询服务台场景中,患者的咨询通常是一些即时问题,例如"今天专家还有没有临时号"、“采血在几楼"等。 从医院的角度来看,希望能够不断提升问答质量,因此需要对这些咨询问答对进行记录。需要注意的是,这些问答对并不会直接更新RAG系统的知识库,而是会被写入另一个专门记录问答的数据库(这个数据库不一定需要是向量数据库)。该数据库背后通常需要一到多名知识库维护人员,他们通过对实际问答数据的分析来持续迭代优化知识库。
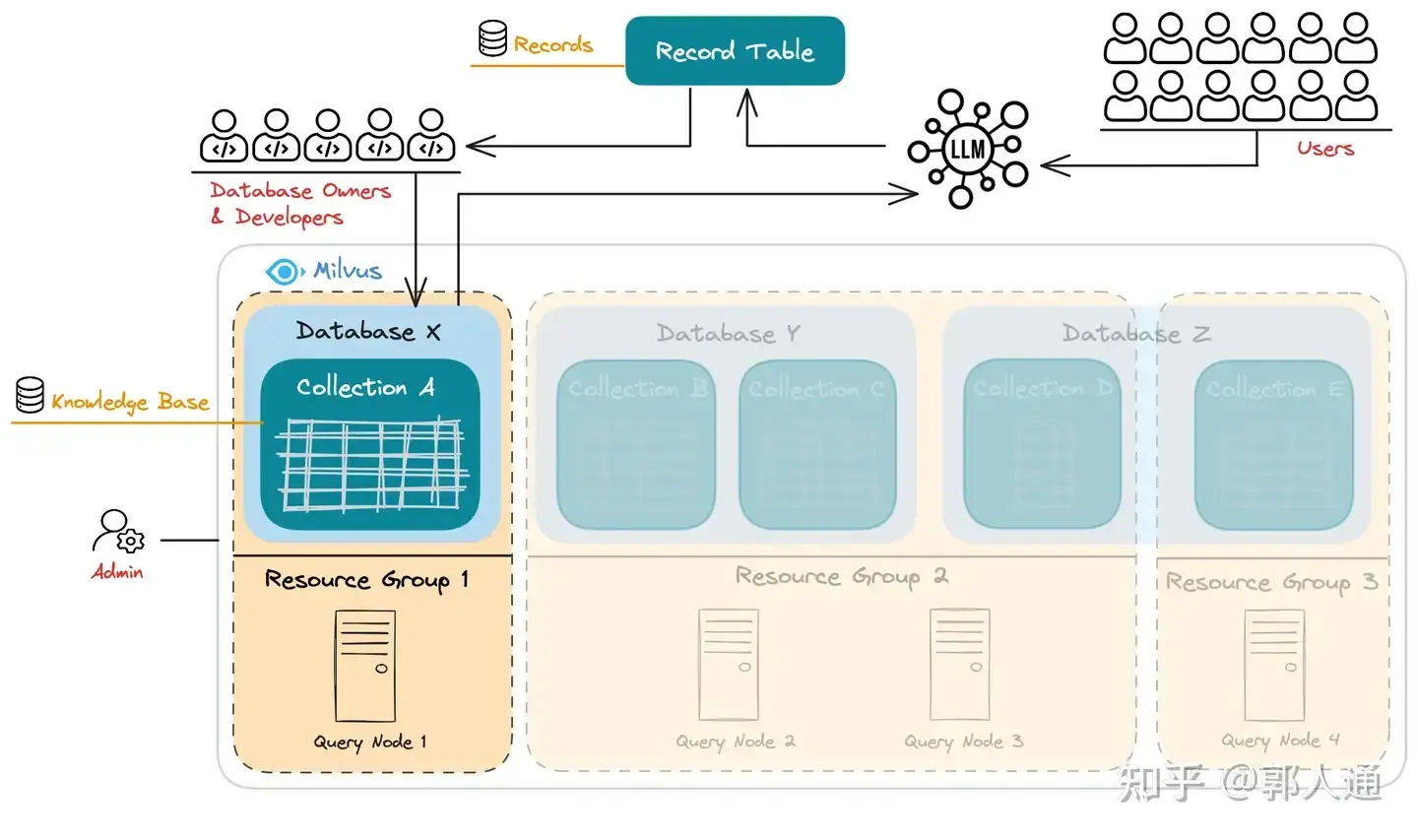
企业知识库组成结构
在这个企业知识库架构中,我们把各个组成部分整合成为一个整体,具体如下:
-
系统管理员:负责整个系统的维护工作,包括系统资源的管理与分配,例如为不同的租户分配数据库(Database),确定数据库到资源组(Resource Group)的映射关系,以及资源组的扩展等。
-
租户(Database Owner & Developers):根据具体的业务需求构建知识库,并基于用户的问答数据来不断优化和迭代知识库。
-
用户:以只读方式通过大型语言模型(LLM)间接访问知识库,用户的访问数据会被收集并存入问答记录库,用于后续分析。 值得注意的是,在这个架构设计中,向量数据库系统仅支持多租户模式,而没有针对单个租户内部的多用户进行设计。也就是说,虽然实际业务场景中可能存在多个用户,但这些多用户的概念并未被向量数据库所识别。因此,如果需要根据每位用户的历史咨询记录提供更为精确的回答,是否需要在向量数据库中为每位用户维护一个私有的问答上下文,就成了一个问题点。 对于即时咨询这种随机性较高的场景,核心影响因素在于知识库的质量,而不是用户的历史上下文。但是,对于那些高度依赖上下文的场景,向量数据库系统则需要具备用户层面的感知能力,并能够为每个用户维护一个上下文记忆。
下期预告
在接下来的内容中,我们将探讨如何设计一个能支持多用户上下文记忆的向量数据库系统,这与面向消费者(To C)的应用场景非常相似。敬请期待。
作者介绍
aaaaaaa

郭人通,Zilliz 合伙人和产品总监,CCF 分布式计算与系统专委会执行委员。专注于开发面向 AI 的高效并可扩展的数据分析系统。郭人通拥有华中科技大学计算机软件与理论博士学位。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/Milvus-%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E8%BF%9B%E9%98%B6%E7%B3%BB%E5%88%97%E4%B8%A8%E6%9E%84%E5%BB%BA-RAG-%E5%A4%9A%E7%A7%9F%E6%88%B7%E5%A4%9A%E7%94%A8%E6%88%B7%E7%B3%BB%E7%BB%9F-%E4%B8%8A--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


