LLMs将向量数据库与LLMs集成:实用指南 --知识铺
探索如何利用向量数据库提升大型语言模型,为精准、具有上下文意识的人工智能解决方案。
文章目录
- 向量数据库简要概述
- LLMs兴起之前的向量数据库
- 向量数据库与传统数据库的比较
- 提升向量数据库性能
-
- 索引策略
- 优化的额外考虑因素
- 用向量数据库丰富LLMs的上下文
- 使用Falcon-7B和ChromaDB构建闭合问答机器人
- 环境设置
- 构建“知识库”
- 生成基本答案
- 生成具有上下文意识的答案
- 总结
欢迎来到我们的实用指南,在这里我们将深入探讨大型语言模型(LLMs)及其与向量数据库的协同作用。LLMs在科技领域产生了深远影响,推动了应用开发的创新。然而,当单独使用时,它们的全部潜力往往无法得到充分发挥。这就是向量数据库发挥作用的地方,它们增强了LLMs的能力,使其不仅产生任何回应,而是产生正确的回应。
通常,LLMs会在各种数据上进行训练,这使它们具有广泛的理解能力,但可能导致特定知识领域存在空白。有时,它们甚至可能输出与目标无关或带有偏见的信息 —— 这是从庞大、未经过滤的网络学习的副产品。为了解决这一问题,我们引入了向量数据库的概念。这些数据库以一种称为“向量嵌入”的独特格式存储数据,使LLMs能够更具上下文和准确性地理解和利用信息。
本指南介绍了如何使用向量数据库构建LLM并改进LLM对这种流的使用。我们将探讨如何结合这两者可以使LLMs更加准确和有用,特别是对于特定主题。
接下来,我们将简要概述向量数据库,解释向量嵌入的概念及其在增强人工智能和机器学习应用中的作用。我们将向您展示这些数据库与传统数据库的区别,以及它们为AI驱动任务提供更好支持的原因,特别是在处理文本、图像和复杂模式等非结构化数据时。
此外,我们将探讨这项技术在构建闭环问答机器人中的实际应用。这款机器人由Falcon-7B和ChromaDB提供支持,展示了当LLMs与正确的工具和技术结合时的有效性。
通过本指南,您将更清楚地了解如何利用LLMs和向量数据库的力量创建不仅创新而且具有上下文意识和可靠性的应用程序。无论您是人工智能爱好者还是经验丰富的开发人员,本指南都旨在帮助您轻松自信地探索这个令人兴奋的领域。
向量数据库简要概述
在深入了解向量数据库是什么之前,理解向量嵌入的概念至关重要。向量嵌入在机器学习中至关重要,用于将原始数据转换为人工智能系统可以理解的数值格式。这涉及将数据(如文本或图像)转换为一系列数字,称为向量,在高维空间中。高维数据指的是具有许多属性或特征的数据,每个特征代表不同的维度。这些维度有助于捕捉数据的微妙特征。
创建向量嵌入的过程始于输入数据,这可以是句子中的单词或图像中的像素等任何内容。大型语言模型和其他人工智能算法分析这些数据并识别其关键特征。例如,在文本数据中,这可能涉及理解单词的含义以及它们在句子中的上下文。嵌入模型然后将这些特征转换为数值形式,为每个数据片段创建一个向量。向量中的每个数字代表数据的特定特征,这些数字共同体现了原始输入的本质,以便机器可以处理。
这些向量是高维的,因为它们包含许多数字,每个数字对应数据的不同特征。这种高维度使得向量能够捕捉复杂、详细的信息,使它们成为人工智能模型的强大工具。模型使用这些嵌入来识别数据中的模式、关系和潜在结构。
向量数据库旨在提供针对向量嵌入独特性质的优化存储和查询能力。它们擅长提供高效的搜索能力、高性能、可扩展性和数据检索,通过比较和识别数据点之间的相似性来实现。
这些复杂、高维信息的数值表示使向量数据库与主要存储文本和数字等格式的传统系统有所不同。它们的主要优势在于管理和查询诸如图像、视频和文本等数据类型,特别是在这些数据被转换为机器学习和人工智能应用所需的向量格式时。
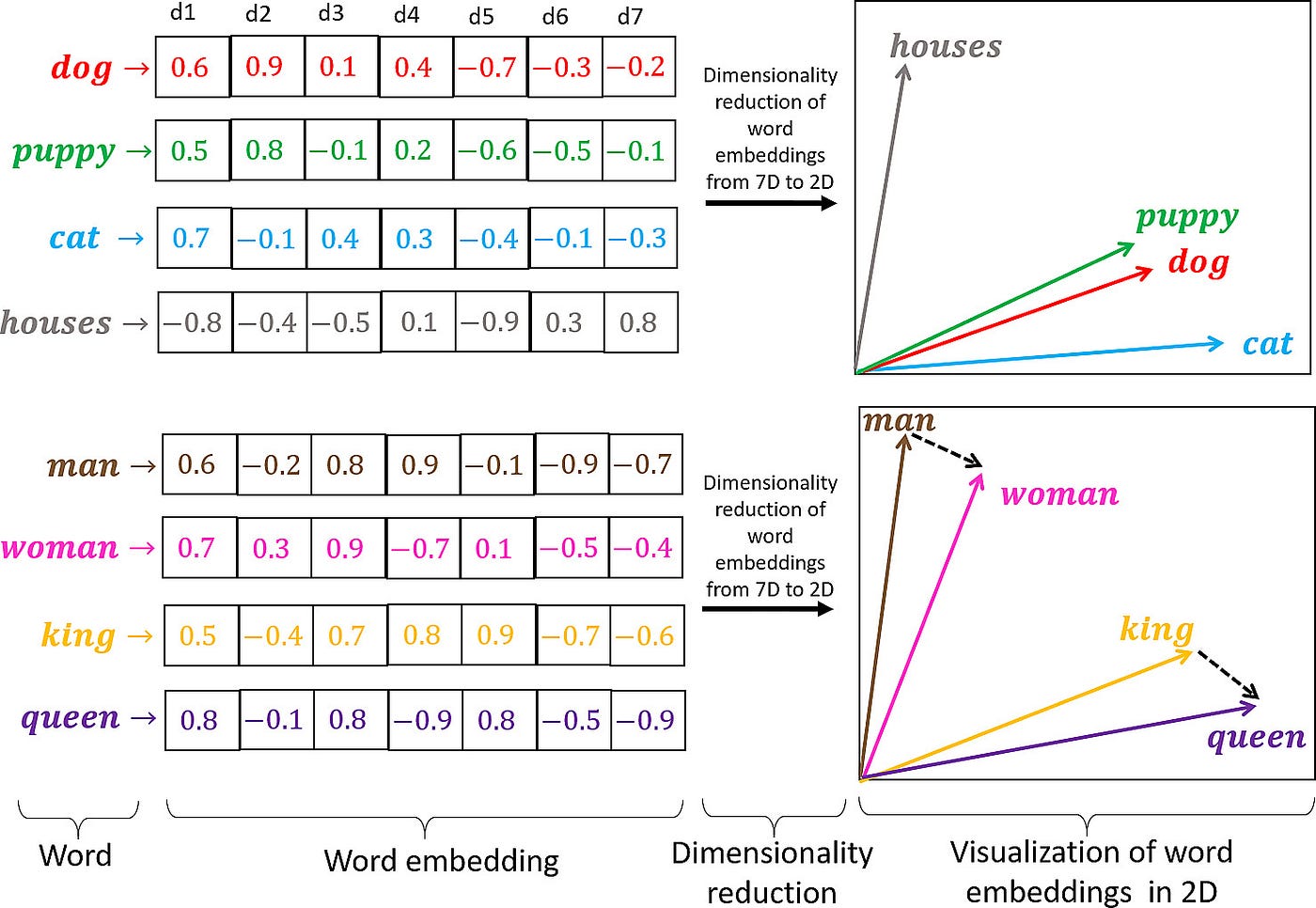
在下图中,我们展示了将文本转换为单词向量的过程。这一步在自然语言处理中至关重要,使我们能够量化和分析语言关系。例如,“小狗”的向量表示在向量空间中会更接近“狗”而不是“房子”,反映了它们的语义接近性。这种方法也适用于类比关系。在“男人”和“女人”之间的向量距离和方向可以类比于“国王”和“皇后”之间的关系。这说明了单词向量不仅代表单词,还允许在多维向量空间中对它们的语义关系进行有意义的比较。
向量数据库的关键用例与优化
关键用例
相似性搜索
-
电子商务:通过图像相似性搜索,帮助用户找到视觉上类似的产品。
-
音乐流媒体服务:推荐具有相似音频特征的歌曲。
-
医疗影像:检索与特定病症相关的医学图像以辅助诊断。 推荐系统
-
流媒体平台:根据观看历史个性化推荐内容。
-
在线零售商:基于用户行为推荐商品。
-
新闻聚合器:依据阅读偏好推送个性化新闻。 基于内容的检索
-
数字资产管理:根据视觉或音频特征搜索媒体资产。
-
法律与合规:在文档中查找相关信息。
-
学术研究:发现语境相似的研究文献。 增强LLMs的上下文理解
-
文本嵌入:通过存储文本嵌入,帮助LLMs更好地理解语义内容。
-
信息检索:执行细致的信息检索任务。
-
对话上下文:维持对话流程的连贯性。
-
内容生成:生成与上下文相关的内容。
与传统数据库的比较
传统数据库
-
优势:管理结构化数据、保证数据完整性和精确匹配。
-
局限:难以处理非结构化数据的语义细节。 向量数据库
-
优势:处理非结构化数据、支持相似性搜索和上下文理解。
-
应用场景:特别适合LLMs和其他AI应用。
提升性能的策略
量化(Quantization)
-
作用:通过映射向量到有限的参考点来压缩数据。
-
适用场景:适合大规模数据集,可以容忍一定精度损失的应用。 分层可导航小世界图(HNSW)
-
作用:构建分层图以加速搜索过程。
-
适用场景:适合需要快速响应的应用。 倒排文件索引(IVF)
-
作用:将向量空间划分为簇,减少搜索范围。
-
适用场景:适合处理高维数据,相对静态的数据集。
优化的额外考虑因素
-
降维(Dimensionality Reduction):使用PCA或自动编码器减少数据复杂性。
-
并行处理(Parallel Processing):在多核CPU或GPU上并行处理查询。
-
动态索引(Dynamic Indexing):支持数据更新的同时保持索引高效。
用向量数据库丰富LLMs的上下文
定向训练
-
优点:提升模型在特定领域的专业知识。
-
局限:高昂的成本和技术要求。 通过向量数据库增加上下文
-
优点:无需重新训练即可提供专业信息。
-
应用场景:适用于缺乏训练资源的组织和个人。 aaaaaaa这些策略和方法,向量数据库不仅增强了LLMs的能力,还提升了其他AI应用的性能和实用性。
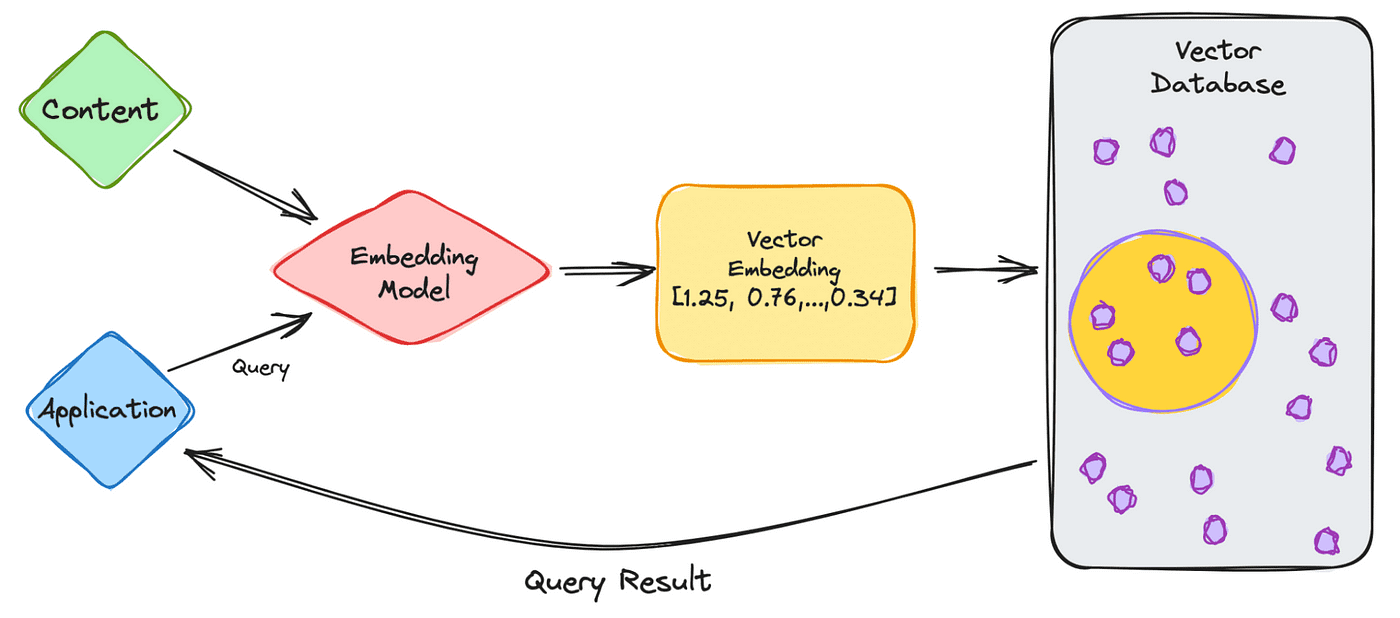
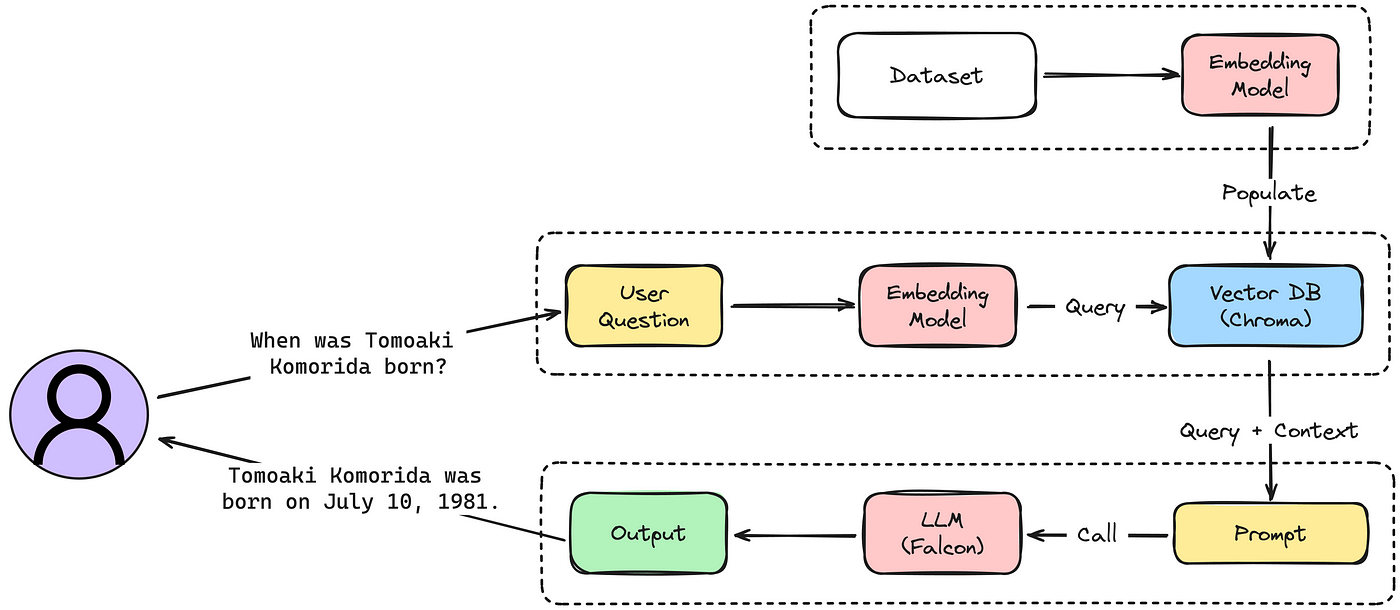
在本节中,我们将详细介绍如何利用向量数据库来构建一个基于大型语言模型 (LLM) 的闭合问答机器人。这个机器人设计用于高效地回答与科学相关的提问,并结合了一系列技术组件。以下是构建过程中的关键步骤和技术要点:
- 使用 HuggingFace 的 Databricks-Dolly-15k 数据集
-
这是由 Databricks 提供的一个开源数据集,包含员工生成的遵循指令的记录。它主要用于训练大型语言模型 (LLMs),同时也适用于合成数据生成和数据增强。
-
数据集覆盖了多种提示和响应类型,例如头脑风暴、分类、闭合问答、生成、信息提取、开放问答以及摘要等。
- 使用 Chroma 作为向量存储
- Chroma 是我们的主向量存储系统,扮演着机器人知识库的角色。它能够高效地存储和检索大量的向量数据。
- 使用 Sentence Transformers 进行语义搜索
- 我们使用 Sentence Transformers 库中的 ‘multi-qa-MiniLM-L6-cos-v1’ 模型来生成存储在 Chroma 中的数据嵌入。此模型经过优化,非常适合于语义搜索任务。
- 采用 Falcon 7B Instruct 作为生成模型
-
Falcon 7B Instruct 是一个仅解码器的模型,拥有 70 亿个参数。它由 TII 开发,并在一个庞大的 1,500B 令牌数据集 RefinedWeb 上进行了训练。
-
该模型的更大版本 Falcon 40B 在 Hugging Face 的 Open LLM Leaderboard 上排名首位。
环境设置
为了实现本文中讨论的功能,你需要进行以下软件安装和配置:
-
Databricks-Dolly-15k 数据集: 从 HuggingFace Hub 下载并准备数据集。
-
Chroma: 安装并配置 Chroma 向量数据库。
-
Sentence Transformers: 安装 Sentence Transformers 库,并加载 ‘multi-qa-MiniLM-L6-cos-v1’ 模型。
-
Falcon 7B Instruct: 从 Hugging Face Model Hub 下载并加载模型。
!pip install -qU \
transformers==4.30.2 \
torch==2.0.1+cu118 \
einops==0.6.1 \
accelerate==0.20.3 \
datasets==2.14.5 \
chromadb \
sentence-transformers==2.2.2```
这段代码最初在 Qwak 的 Workspaces 上的 gpu.a10.2xl 实例 上运行。需要注意的是,运行 Falcon-7B-Instruct 模型所需的特定代码可能会因使用的硬件配置而有所不同。
构建“知识库”
首先,我们获取 Databricks-Dolly 数据集,专注于 closed_qa 类别。这些条目通常以对精确信息的需求为特征,对于一般训练的大型语言模型(LLM)来说,由于其特定性,这些条目构成了挑战。
为了从`databricks-dolly-15k`数据集中加载并过滤出特定类别的样本,可以按照以下步骤进行操作:
### 步骤 1: 加载数据集
首先使用`load_dataset`函数从Hugging Face的数据集库中加载名为`databricks-dolly-15k`的数据集,并指定只加载训练集。
```python
from datasets import load_dataset
# 加载数据集的训练部分
train_dataset = load_dataset("databricks/databricks-dolly-15k", split='train')
步骤 2: 过滤数据集
接下来,定义一个过滤条件来选择特定类别的样本。在这个例子中,我们只保留类别为closed_qa的样本。
|
|
步骤 3: 查看结果
最后,可以通过打印第一个样本来检查过滤后的数据集。
|
|
以上步骤确保了你能够有效地从大型数据集中筛选出符合特定条件的样本,这对于机器学习任务中的数据预处理是非常有用的。
典型的数据集条目如下所示:
Tomoaki Komorida出生于1981年7月10日,出生地是日本熊本县。他的足球生涯轨迹如下:
-
高中毕业后:2000年加入J1联赛俱乐部Avispa Fukuoka,并在那里作为中场球员开始职业生涯。
-
职业生涯发展:在Avispa Fukuoka之后,他在多个俱乐部担任过防守型中场和中后卫的角色,包括Oita Trinita、Montedio Yamagata、Vissel Kobe以及Rosso Kumamoto等。
-
海外经历:他曾前往印度尼西亚,在Persela Lamongan队效力。
-
职业生涯尾声:返回日本后加入Giravanz Kitakyushu,并于2012年在此俱乐部结束了自己的职业生涯。 aaaaaaa总结起来,Komorida的职业生涯丰富多变,展现了他在不同位置上的适应能力和对足球的热爱。
接下来,我们专注于为每组指令及其相应上下文生成词嵌入,并将其整合到我们的向量数据库 ChromaDB 中。
[Chroma DB](http://zshipu.com/t/index.html?url=https://docs.trychroma.com/) 是一个开源的向量存储系统,擅长管理向量嵌入。它专为语义搜索引擎等应用而设计,这在自然语言处理和机器学习领域至关重要。Chroma DB 的高效性,特别是作为内存数据库,有助于快速数据访问和操作,这对高速数据处理至关重要。其友好的 Python 设置增强了其在我们项目中的吸引力,简化了其整合到我们的工作流程中。详细文档请参阅:[Chroma DB 文档](http://zshipu.com/t/index.html?url=https://docs.trychroma.com/)。
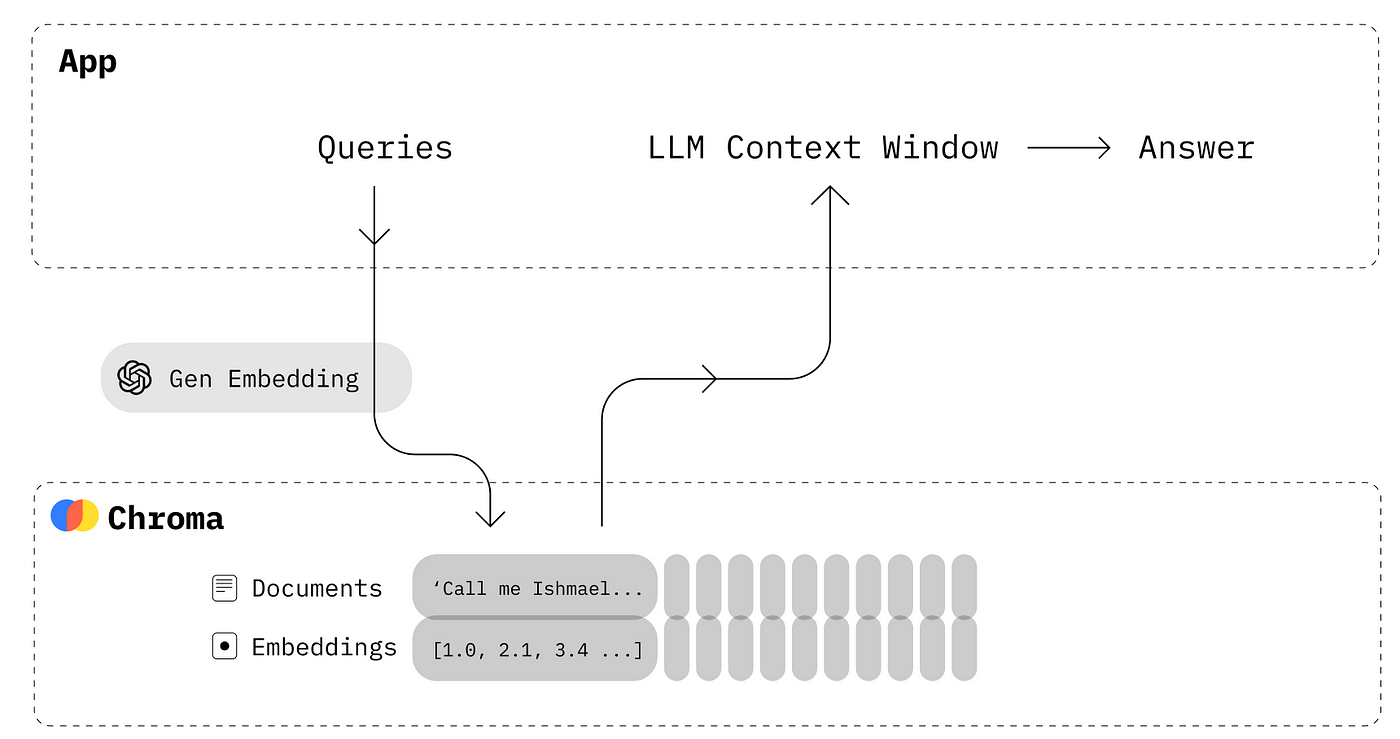
[来源](http://zshipu.com/t/index.html?url=https://docs.trychroma.com/)
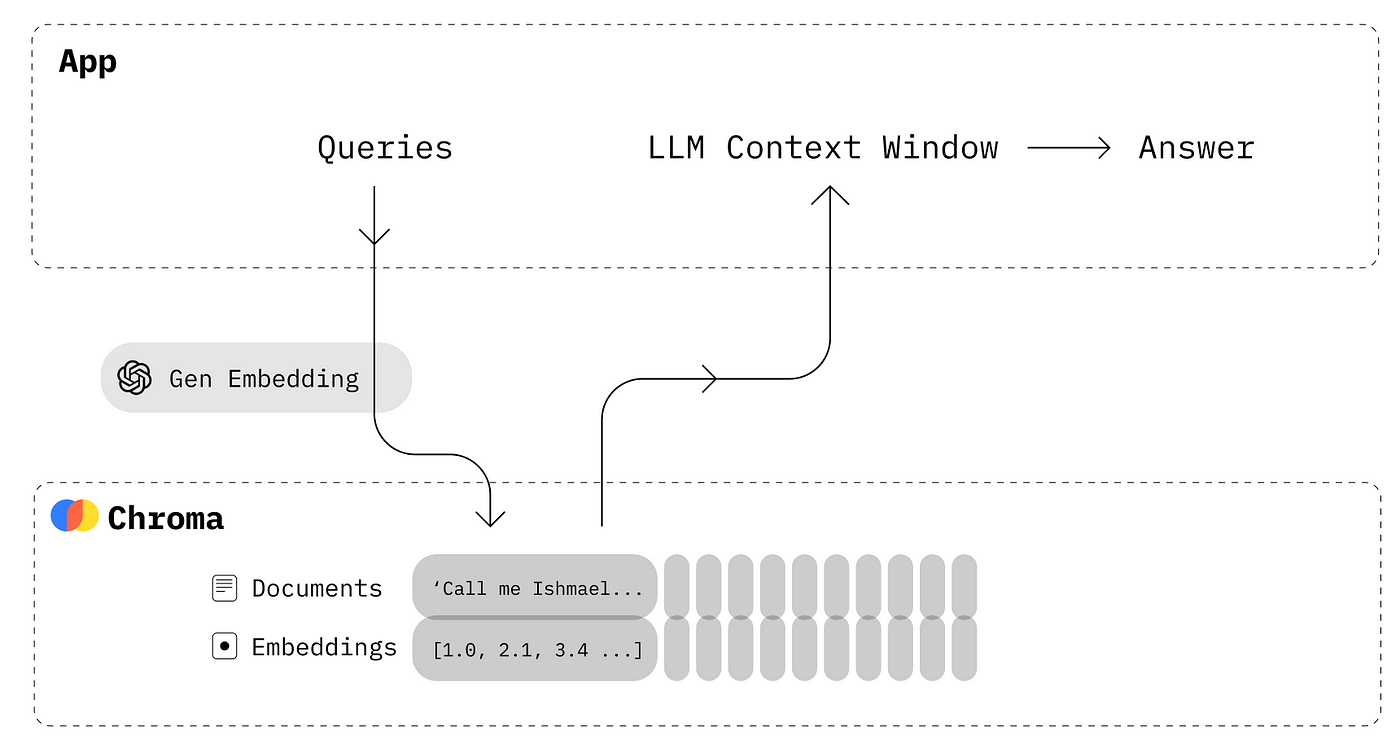
为了为答案生成嵌入,我们使用了专门针对语义搜索用例进行训练的 multi-qa-MiniLM-L6-cos-v1 模型。给定一个问题/搜索查询,该模型能够找到相关的文本段落,这正是我们的目标。
在下面的示例中,我们说明了嵌入是如何存储在 Chroma 的内存集合中的。
为了为答案生成嵌入,我们使用了专门针对语义搜索用例进行训练的 multi-qa-MiniLM-L6-cos-v1 模型。给定一个问题/搜索查询,该模型能够找到相关的文本段落,这正是我们的目标。
在下面的示例中,我们说明了嵌入是如何存储在 Chroma 的内存集合中的。
import chromadb
from sentence_transformers import SentenceTransformer
class VectorStore:
def __init__(self, collection_name):
# 初始化嵌入模型
self.embedding_model = SentenceTransformer('sentence-transformers/multi-qa-MiniLM-L6-cos-v1')
self.chroma_client = chromadb.Client()
self.collection = self.chroma_client.create_collection(name=collection_name)
# 从数据集中填充向量存储的方法
def populate_vectors(self, dataset):
for i, item in enumerate(dataset):
combined_text = f"{item['instruction']}. {item['context']}"
embeddings = self.embedding_model.encode(combined_text).tolist()
self.collection.add(embeddings=[embeddings], documents=[item['context']], ids=[f"id_{i}"])
# 根据查询搜索 ChromaDB 集合中的相关上下文的方法
def search_context(self, query, n_results=1):
query_embeddings = self.embedding_model.encode(query).tolist()
return self.collection.query(query_embeddings=query_embeddings, n_results=n_results)
# 示例用法
if __name__ == "__main__":
# 使用集合名称初始化处理程序
vector_store = VectorStore("knowledge-base")
# 假设 closed_qa_dataset 已定义并可用
vector_store.populate_vectors(closed_qa_dataset)
对于每个数据集条目,我们生成并存储了“指令”和“上下文”字段的组合嵌入,其中上下文充当了我们在 LLM 提示中检索的文档。
接下来,我们将利用 Falcon-7b-instruct LLM 生成对没有额外上下文的封闭信息查询的响应,展示我们丰富知识库的有效性。
生成基本答案
对于我们的生成文本任务,我们将利用来自 Hugging Face 的 falcon-7b-instruct 模型的能力。
Falcon-7B-Instruct 的独特之处在于它在先进功能和可管理大小之间的高效平衡。它专为复杂的文本理解和生成任务而设计,提供了与更大、闭源模型相媲美的性能,但以更简化的方式呈现。这使其成为我们项目的理想选择,我们需要深入的语言理解,而无需更大型模型的额外开销。
如果您计划在本地计算机或远程服务器上运行 Falcon-7B-Instruct 模型,请务必注意硬件要求。如 HuggingFace 文档 所述,该模型需要至少 16GB RAM。然而,为了获得最佳性能和更快的响应时间,强烈建议使用 GPU。
import transformers
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
class Falcon7BInstructModel:
def __init__(self):
# 模型名称
model_name = "tiiuae/falcon-7b-instruct"
self.pipeline, self.tokenizer = self.initialize_model(model_name)
def initialize_model(self, model_name):
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 用于文本生成的管道设置
pipeline = transformers.pipeline(
"text-generation",
model=model_name,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
return pipeline, tokenizer
def generate_answer(self, question, context=None):
# 准备输入提示
prompt = question if context is None else f"{context}\n\n{question}"
# 生成响应
sequences = self.pipeline(
prompt,
max_length=500,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=self.tokenizer.eos_token_id,
)
# 提取并返回生成的文本
return sequences['generated_text']
这段代码示例基于 Hugging Face 的文档构建,非常清晰易懂。
让我们对其主要组件进行解析,以便更好地理解:
- 分词器 是自然语言处理(NLP)模型(如 Falcon-7B-Instruct)中的关键组件。其主要作用是将输入文本转换为模型可以理解的格式。它将文本分解为称为标记的较小单元。这些标记可以是单词、子词或甚至字符,取决于分词器的设计。在 Falcon-7B-Instruct 模型的上下文中,AutoTokenizer.from_pretrained(model) 调用加载了一个专门设计用于与该模型配合工作的分词器,确保文本被分词的方式与模型训练时的方式一致。
- 管道 在 transformers 库中是一个高级实用程序,它抽象了处理数据和从模型获取预测所涉及的许多复杂性。它在内部处理多个步骤,例如对输入文本进行分词、将标记传递给模型,然后将模型的输出处理为人类可读的形式。在此脚本中,管道设置为“text-generation”,这意味着它经过优化,可以接受提示(如用户问题)并生成基于该提示的文本延续。
示例用法:
# 初始化 Falcon 模型类
falcon_model = Falcon7BInstructModel()
user_question = "Tomoaki Komorida 出生于哪一天?"
# 使用 LLM 为用户问题生成答案
answer = falcon_model.generate_answer(user_question)
print(f"结果: {answer}")
正如您可能已经猜到的那样,这是针对给定用户问题的模型输出:
{ answer: “我没有关于 Tomoaki Komorida 出生日期的信息。” }
在没有额外上下文的情况下利用 Falcon-7B-Instruct 会产生负面响应,因为它没有接受过这种“较少知名”信息的训练。这说明了在为非通用问题生成更有针对性和有用的答案时,需要丰富的上下文。
生成具有上下文意识的答案
现在,让我们通过为生成模型提供相关上下文来提升其能力,这些上下文是从我们的向量存储中检索的。
有趣的是,我们在为生成嵌入和从用户问题中提取上下文时都使用了相同的 VectorStore 类:
### 获取上下文并生成答案
1. **从 Vector Store 中获取上下文**
- 使用 `vector_store.search_context(user_question)` 方法从 Vector Store 中搜索与用户问题相关的上下文。
- 上下文信息存储在响应的 `'context'` 键的第一个元素中。
2. **提取上下文文本**
- 将提取到的上下文文本拼接在一起。
3. **使用 Falcon 模型生成答案**
- 结合提取到的上下文文本,利用 `falcon_model.generate_answer(user_question, context=context)` 方法生成更丰富的答案。
#### 示例输出:
```markdown
结果: enriched_answer
田智明,生于1981年7月10日。
### 如何构建和学习大型语言模型应用
在深入探讨中,我们介绍了如何创建基于大型语言模型(LLM)的应用,并且通过自定义数据集来丰富其功能。很明显,这涉及到一系列复杂的步骤,包括模型管理、数据集实验设计、基础设施搭建以及实际应用开发。
#### 构建过程概述
- **理解模型基础**:首先需要对大型语言模型的基本原理有所了解,比如它们是如何训练的、如何进行微调以适应特定任务等。
- **准备数据集**:收集并预处理相关的文本数据,这些数据将用于训练或微调模型。
- **模型选择与微调**:选择合适的预训练模型,并根据具体需求对其进行微调。
- **基础设施搭建**:设置所需的计算资源和环境,确保模型可以高效运行。
- **应用开发**:开发应用程序接口(API),使模型能够服务于实际场景。
#### 学习资源与路径
- **理论学习**:阅读关于大型语言模型的学术论文和技术文档,理解最新的研究进展。
- **实践操作**:通过动手实践,例如参与Kaggle竞赛或者GitHub上的开源项目。
- **社区交流**:加入相关技术论坛和社群,如CSDN等平台,与其他开发者互动交流。
- **视频教程**:观看在线课程和教程,加深对概念的理解并掌握实用技巧。
为了帮助大家更好地学习大型语言模型,这里有一些资源可以参考:
- **白皮书**:涵盖了市场上主流的大模型介绍和技术细节。
- **学习路线图**:提供了一个结构化的学习路径,指导如何从零开始学习到精通。
- **实战视频**:通过一系列录播视频,展示如何将理论知识应用于实际项目中。
希望以上信息能为你的学习之旅提供帮助!
---
**注意**:上述提供的资源和信息仅供参考,建议结合个人实际情况选择最适合自己的学习方式。

**一、AGI大模型系统学习路线**
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。
**二、AI大模型视频教程**
**三、AI大模型各大学习书籍**
**四、AI大模型各大场景实战案例**

### 学习AI大模型的重要性
随着科技的快速发展,AI大模型已经成为一个不可忽视的趋势。深入探索这一领域不仅能为我们打开新的机遇之门,还能带来前所未有的挑战。通过系统地学习AI大模型,我们能够掌握深度学习与神经网络的核心原理,并将这些知识应用于诸如自然语言处理、计算机视觉及语音识别等实际场景中。
#### 职业发展
掌握AI大模型的相关技能对于提升个人的职业竞争力至关重要。它不仅能够帮助我们在竞争激烈的就业市场中脱颖而出,还有助于我们在技术领域内占据领先地位。
#### 个人价值
此外,学习AI大模型还可以为我们自身创造更多的价值。无论是寻找新的工作机会还是开展副业,这些技能都能够为我们提供额外的收入来源,进而提高生活质量。
### 结论
总而言之,鉴于AI大模型带来的广阔前景和个人收益,投入时间和精力去学习这项技术是一个明智的选择。

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/LLMs%E5%B0%86%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%8ELLMs%E9%9B%86%E6%88%90%E5%AE%9E%E7%94%A8%E6%8C%87%E5%8D%97--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


