LLMs外挂知识库_llm 外挂知识库 --知识铺
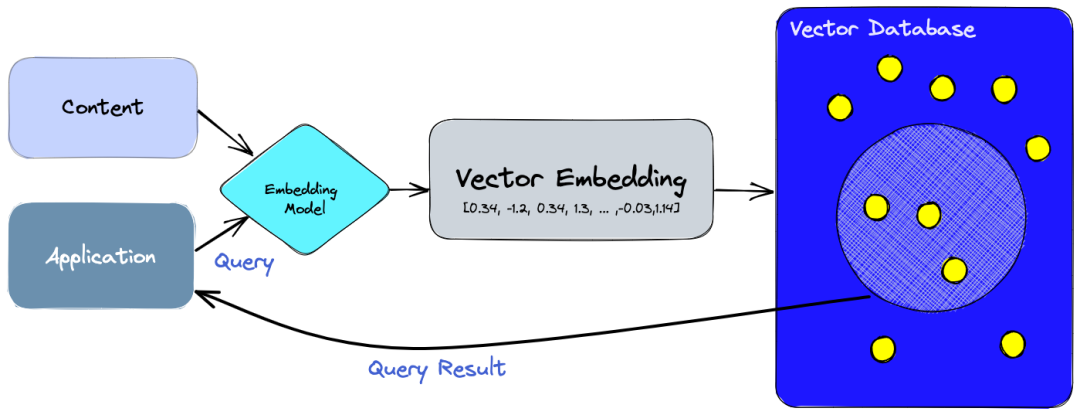
矢量数据库为管理高维数据提供了专门的解决方案,这对人工智能的上下文决策至关重要。但它们究竟是如何做到的呢?

在当今的数据驱动世界中,信息呈现出多样化的形式。这些信息可以是非结构化的,比如文本文档、图片和音频文件;也可能是结构化的,例如应用程序日志、电子表格和图表。为了有效地存储和检索这些多样的数据形式,矢量数据库应运而生。
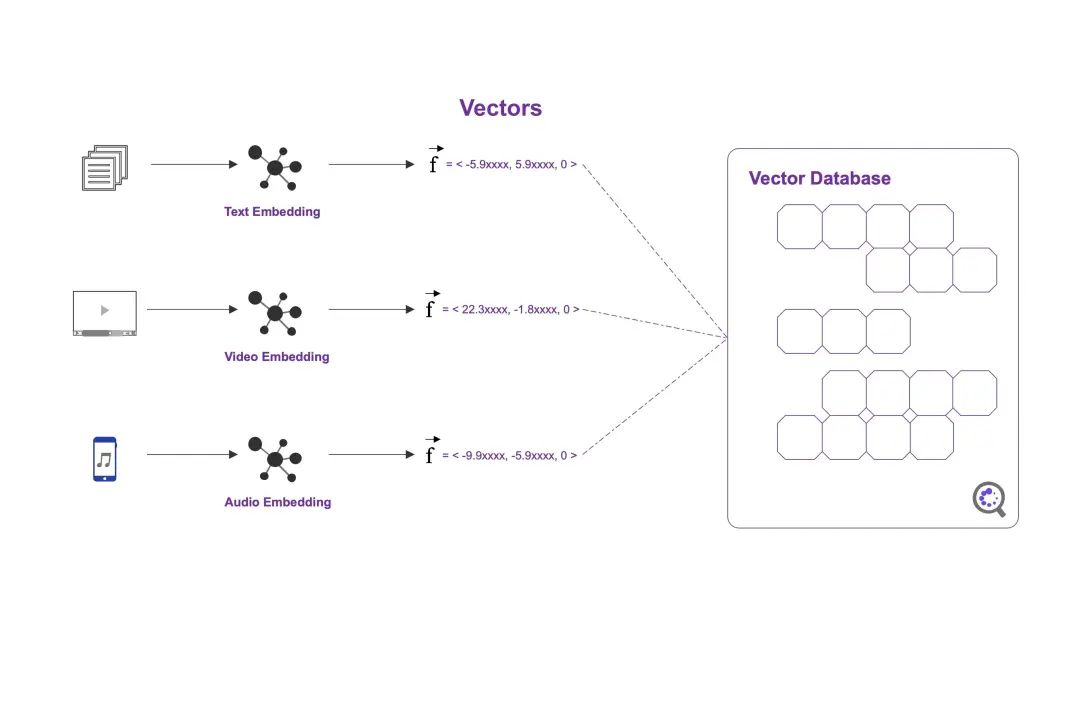
矢量数据库通过将非结构化数据转换为高维向量来实现这一点,这些向量可以被高效地存储和检索。具体来说,可以使用文本嵌入算法对文本文档进行处理,将其转化为向量形式。类似地,视频、图像和音频数据可以通过多模态表征算法转换为密集向量。一旦这些数据被转换为向量形式,就可以被存储到矢量数据库中(例如Pinecone等)。当需要查询时,矢量数据库利用相似性度量算法快速找到与查询最匹配的结果。
这种处理方式使得用户能够在海量数据中快速定位到相关信息,无论是文本还是多媒体数据,都能通过一种统一的方式进行管理和检索。
**

要创建并使用一个矢量数据库,例如Pinecone,并确保它与您的应用无缝集成,请按照以下步骤操作:
-
安装与配置:
-
首先安装Pinecone服务。对于初学者来说,可以利用私人账户免费试用。
-
在设置过程中,需要指定嵌入向量的维度。因为OpenAI的嵌入模型输出的向量维度为1536,所以应将数据库的维度设置为1536以保证兼容性。
-
选择检索指标:
-
为了进行有效的数据检索,需要选择一个合适的相似度指标。在本例中,我们采用余弦相似度作为向量间的相似度计算方式。
-
余弦相似度能够计算两个向量之间的夹角余弦值,以此来评估它们之间的相似程度。
-
当检索数据时,系统会根据余弦相似度输出最接近的Top-K个结果。 通过以上步骤,您可以有效地创建和管理一个用于存储和检索嵌入向量的矢量数据库。
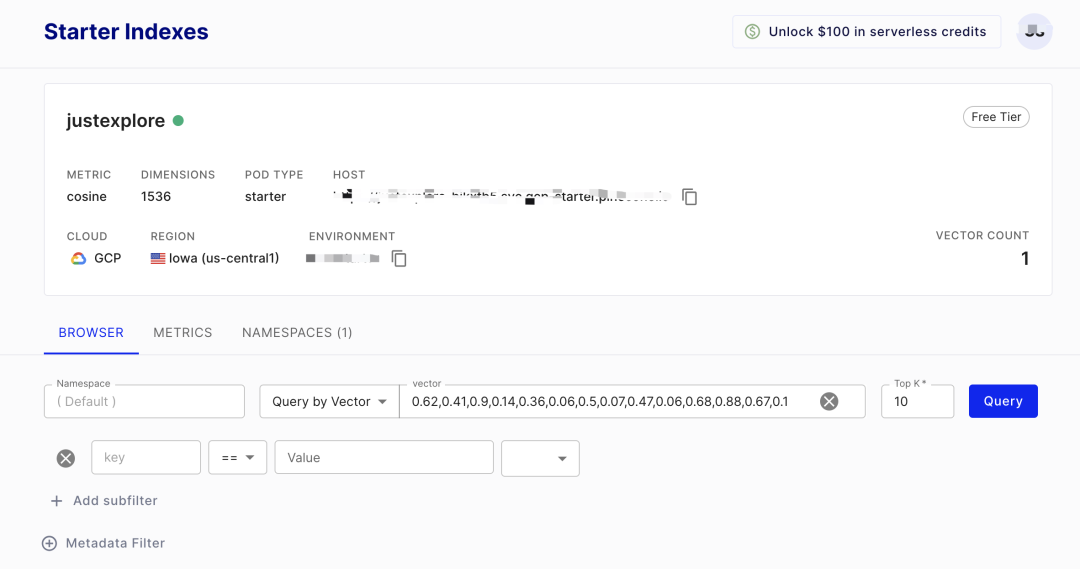
可以通过API方式进行数据库“增删改查”操作。通过Pinecone的API方式插入数据的代码如下:

矢量数据存入到数据库后的效果如下:
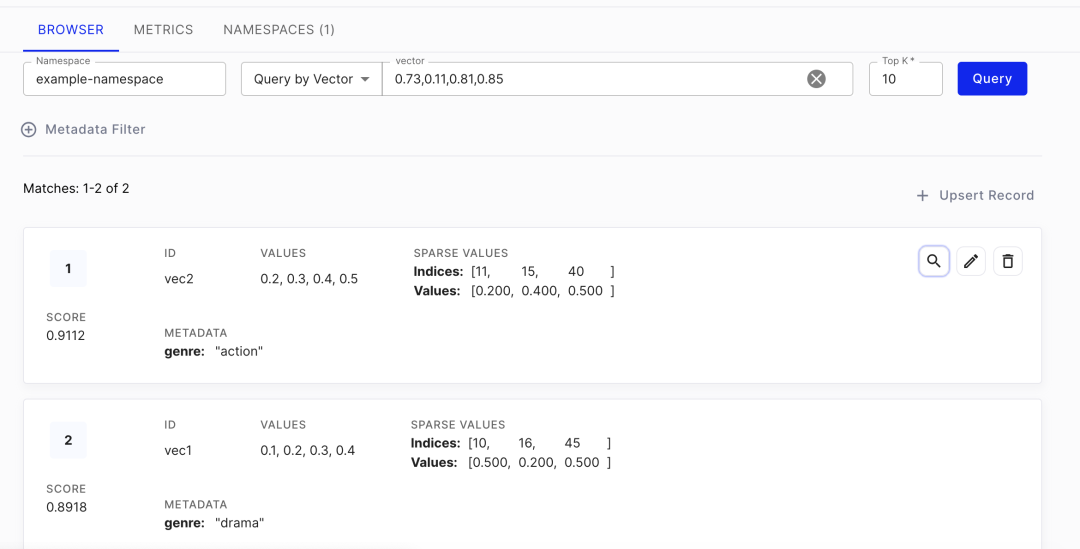
矢量数据库构建完成以后,每个数据点都会表征成一个有方向的向量值(Vector Representation)。当有检索诉求时,可通过相似度算法进行计算,从矢量数据库中输出最相似的向量返回即可。
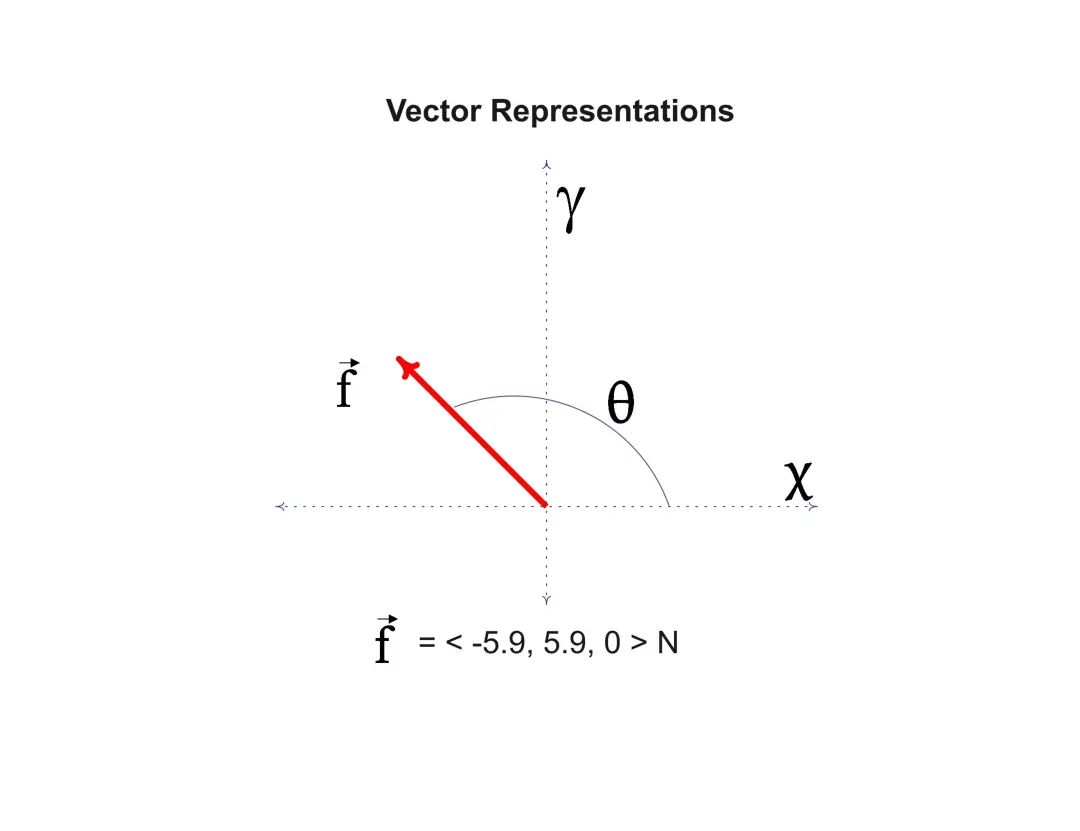

矢量数据库与ChatGPT结合:构建外挂知识库
外挂知识库的核心价值在于提供更加专业和可控的信息。 这些信息能够为用户提供比ChatGPT原始输出更为精确和专业的指导,确保用户体验得到显著提升。
典型应用场景
-
智能客服
-
背景: 当面对客户关于“缺货”等具体问题的投诉时,简单地使用ChatGPT生成的回答可能会让客户感到不满,因为这类回复往往倾向于提供一般性的解决方案而非直接解决问题。
-
挑战: 客户在寻求帮助时希望能够立即获得明确的解答或行动方案,而不是被引导去探索可能的解决方案。
-
解决方案: 通过整合矢量数据库与ChatGPT,可以在特定领域积累专业知识,并针对具体问题提供定制化的回答。例如,在客户投诉缺货时,系统可以迅速检索相关知识库,给出确切的库存状态、预计补货时间或替代产品建议,从而有效解决客户问题。 aaaaaaa这样的方式不仅能够提高问题解决效率,还能增强客户满意度,确保服务的专业性和可靠性。
外挂知识库与ChatGPT的集成应用
-
深度理解与检测
-
利用ChatGPT处理用户上传的图片和文本,进行深度理解。
-
检测内容的真实性,并分析用户申诉的原因。
-
专业解决方案提供
-
基于图文理解的结果,在外挂知识库中检索匹配的话术。
-
直接为用户提供专业的解决方案。 aaaaaaa通过这种集成方式,不仅能够快速准确地理解用户需求,还能高效地给出应对策略,提升用户体验。
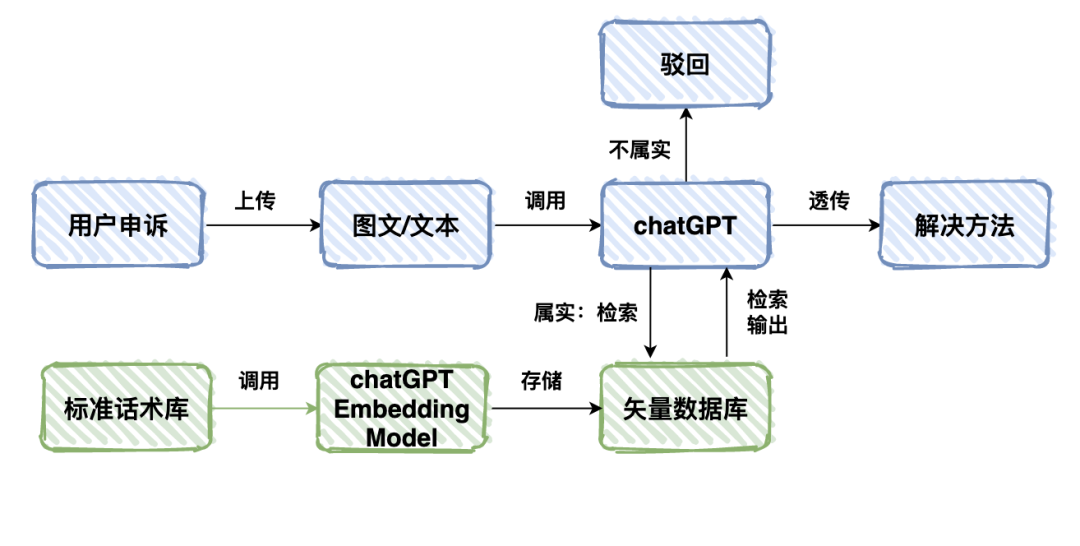
整体代码如下:
import openai
import pinecone
# your openai app key and vector database app key
openai.api_key = "your openai appkey"
pinecone.init(api_key="your pinecone appkey",
environment="your environment")
# prompt
prompt="我买的东西丢了,我没收到货"
# initial your vector database
active_indexes = pinecone.list_indexes()
index = pinecone.Index(active_indexes[0])
print("****************** Initialized:Done ******************")
# your knowledge
file = open('data/knowledge.txt', 'r')
content = file.read()
file.close()
print("****************** Knowledge acquired:Done ******************")
# knowledge to embedding vector
data_embedding_res = openai.Embedding.create(
model="text-embedding-ada-002",
input=content
)
print("****************** knowledge embedding vector:Done ******************")
# knowledge embedding to vector database
upsertRes = index.upsert([
("q1", data_embedding_res['data'][0]['embedding'], { "data": content })
])
print("****************** update knowledge embedding to vector database:Done ******************")
# prompt embedding vector
promt_embedding_res = openai.Embedding.create(
model="text-embedding-ada-002",
input=prompt
)
print("****************** prompt embedding vector:Done ******************")
# retrieve knowledge by prompt embedding and return the retrieval result
prompt_res = index.query(
promt_embedding_res['data'][0]['embedding'],
top_k=5, include_metadata=True
)
print("****************** retrieval:Done ******************")
# reconstruct prompts
contexts = [item['metadata']['data'] for item in prompt_res['matches']]
# chatGPT
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens = 200,
messages=[
{"role": "user", "content": prompt}
]
)
print("****************** User prompt: {} ******************".format(prompt))
print("****************** chatGPT only: {} ******************".format(completion.choices[0].message.content))
print("****************** chatGPT with vector database: {} ******************".format(contexts[0]))
可以看到,相较于chatGPT输出结果,外挂知识库不仅可以正确理解用户意图,同时能够从知识库中抽取专业的解决方案:“是我们物流的失误导致您没有收到货,我们会给你2倍的赔偿,给您带来的不便请谅解!”
**

**

AI-agent与矢量数据库的应用
AI-agent的工作原理在于将复杂问题拆解并执行,最后整合各部分的结果得出答案。在这个过程中,矢量数据库扮演着关键角色,它负责外挂知识的存储与检索,可以高效地处理多模态数据,并为用户提供更专业、更垂直的知识信息。
学习大模型AI的方法
随着新技术的发展,那些能快速掌握AI技术的人将在职场上占据优势。这与历史上计算机、互联网以及移动互联网初期的情况相似。 在我超过十年的一线互联网工作经验中,我有幸指导了许多后来者,并帮助他们取得了进步。我认为有许多宝贵的经验和知识值得分享。尽管工作繁忙,我还是希望能够为大家提供一些帮助,解答大家在学习人工智能过程中的疑问。 鉴于目前知识传播渠道有限,许多互联网行业的朋友们难以获取到正确且有效的学习资源。因此,我决定分享一系列重要的AI大模型学习资料,包括但不限于:
-
AI大模型入门学习思维导图
-
精品AI大模型学习书籍手册
-
视频教程
-
实战学习录播视频 这些资源都将免费提供给大家,希望能够帮助更多人提升自己在人工智能领域的技能。
aaaaaaa
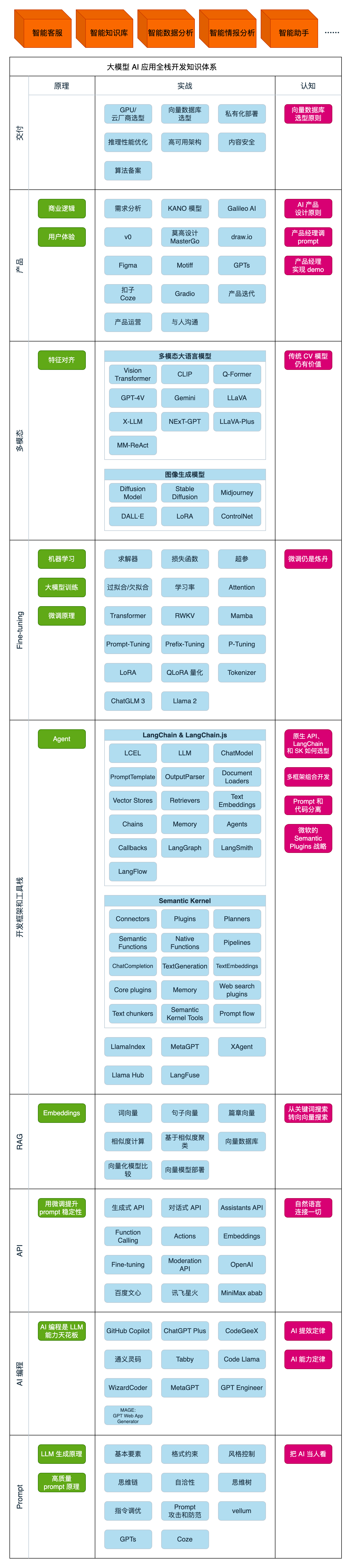
大模型 AI 四阶段学习计划
第一阶段(10天): 初阶应用
目标:掌握大模型 AI 的基础知识与实践技能。
-
大模型 AI 的能力与应用场景
-
大模型 AI 的智能来源
-
高效使用 AI 的策略与技巧
-
业务场景中的大模型应用架构设计
-
技术架构的搭建与优化
-
代码示例:为 GPT-3.5 添加定制知识
-
提示工程的核心价值与原则
-
构建有效的 Prompt 结构
-
指令调优的方法论
-
思维链与思维树的概念及应用
-
Prompt 安全性问题与防范措施
第二阶段(30天): 高阶应用
目标:深入学习大模型 AI 的高级应用,包括构建私有知识库和对话机器人。
-
RAG(Retrieval-Augmented Generation)的重要性
-
实现简单的 ChatPDF 应用
-
检索技术的基本原理
-
向量表示(Embeddings)的定义与作用
-
向量数据库及其在 RAG 中的应用
-
RAG 系统的构建与优化
-
混合检索与 RAG-Fusion 的概念
-
向量模型的本地部署方法
第三阶段(30天): 模型训练
目标:掌握模型训练的核心技能,能够独立训练和微调大模型。
-
模型与模型训练的基础概念
-
求解器与损失函数的作用
-
小实验:从零开始创建并训练一个简单的神经网络
-
训练、预训练、微调和轻量化微调的区别
-
Transformer 架构概述
-
轻量化微调的实际操作
-
实验数据集的设计与构建
第四阶段(20天): 商业闭环
目标:了解大模型的商业部署,寻找适合自己的创业或项目机会。
-
硬件设备的选择与配置
-
全球大模型的性能、吞吐量与成本分析
-
国内大模型服务的使用指南
-
OpenAI 代理服务的搭建
-
Stable Diffusion 在阿里云 PAI 上的部署热身
-
大模型在本地环境的运行
-
大模型的私有化部署方案
-
使用 vLLM 进行大模型部署
-
阿里云上开源大模型的私有部署案例
-
开源 LLM 项目的部署流程
-
内容安全策略与实施
-
互联网信息服务算法的备案要求 学习是一个持续的过程,坚持就是胜利。即使只完成了大部分内容,你也已经踏上了成为大模型 AI 专家的道路。
学习资料获取
这份完整版的学习资料已上传至 CSDN,需要的朋友可以通过微信扫描下方的 CSDN 官方认证二维码免费领取。保证100%免费。

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/LLMs%E5%A4%96%E6%8C%82%E7%9F%A5%E8%AF%86%E5%BA%93_llm-%E5%A4%96%E6%8C%82%E7%9F%A5%E8%AF%86%E5%BA%93--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


