融合RAG和CoT的高效多步推理任务解决方案 --知识铺
引言
在人工智能领域,多步推理任务是解决复杂问题的关键。本文提出了一种创新的解决方案——RAT,它通过融合RAG(Retrieval-Augmented Generation)和CoT(Chain of Thought)两种技术,有效地整合了不同的思维模式,从而显著提升了推理效率和准确性。RAT方案为人工智能系统的推理和问题解决能力带来了质的飞跃。
1. 背景与挑战在现有的人工智能系统中,多步推理任务往往面临信息整合和逻辑推理的挑战。传统的算法在处理这类问题时,可能会因为信息的碎片化和逻辑链条的不连贯而导致推理效率低下。
2. RAG与CoT技术概述
- RAG技术:通过检索增强生成模型,RAG能够利用外部知识库来丰富生成的内容,提高信息的丰富度和准确性。
- CoT技术:即思维链技术,通过模拟人类的思维过程,CoT能够将问题分解为多个逻辑步骤,逐步推导出最终答案。
3. RAT方案的优势
- 整合不同思维模式:RAT方案能够结合RAG的检索能力和CoT的逻辑推理能力,实现信息的高效整合和逻辑的严密推导。
- 提高推理效率:通过优化算法结构,RAT方案能够更快地完成多步推理过程,缩短问题解决的时间。
- 增强准确性:RAT方案通过多步逻辑推理,减少了推理过程中的错误,提高了答案的准确性。
4. 应用前景RAT方案为人工智能在复杂问题解决领域提供了新的思路和工具,有望在医疗诊断、法律分析、科学研究等多个领域得到广泛应用。
5. 结论本文提出的RAT方案,通过融合RAG和CoT技术,不仅提升了人工智能系统的推理能力,也为未来人工智能的发展开辟了新的方向。
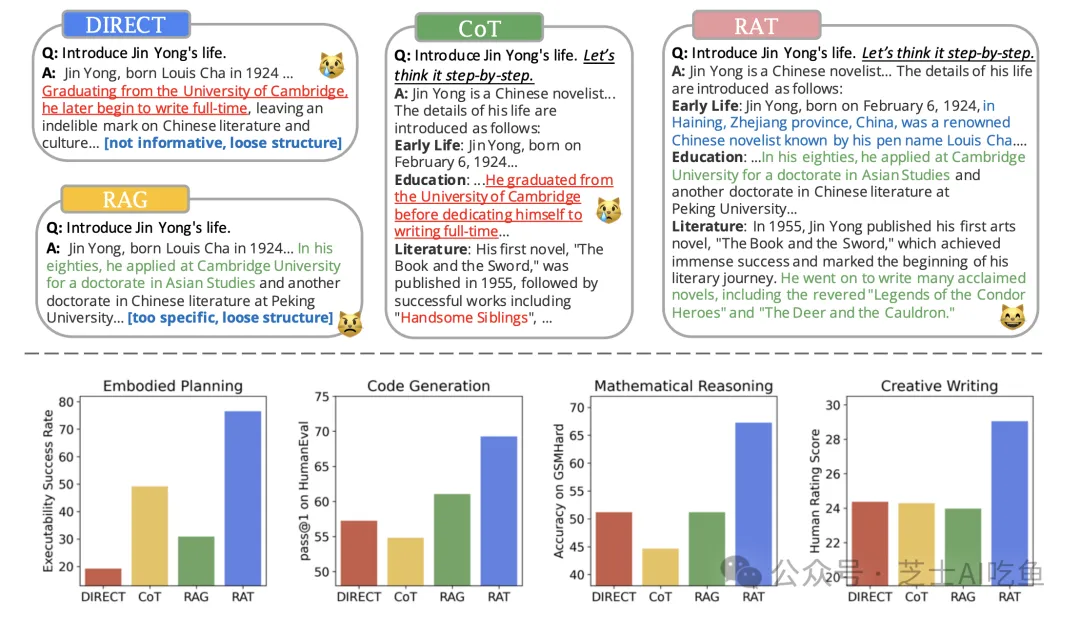
大型语言模型的推理与生成能力提升:检索增强思维(RAT)分析
随着自然语言处理(NLP)领域的快速发展,大型语言模型(LLMs)在多步推理和长期生成任务上的表现日益受到重视。本文旨在分析一种新兴的方法——检索增强思维(Retrieval-Augmented Thoughts,简称RAT),以提高模型的推理和生成能力,减少错误信息的产生。
动机与背景
在多步推理任务中,如代码生成和数学推理,大型语言模型需要依据上下文信息进行准确推理。然而,由于缺乏对真实世界知识的直接访问,模型可能会生成与事实不符的中间推理步骤,导致最终结果的不准确。为此,研究者们提出了结合信息检索技术的方法,以辅助模型进行更准确的推理。
方法详解
3.1 检索增强生成(RAG)与链式思考(CoT)提示
RAG的核心思想
- 检索阶段:从预先构建的知识库中检索与查询最相关的文档。
- 生成阶段:使用检索到的文档作为上下文,辅助模型生成回答或续写文本。
CoT的工作原理
- 分步推理:模型先生成一个中间推理步骤,即一个“思考”。
- 逐步生成:根据当前的思考步骤,继续生成下一个推理步骤,直至得出答案。
3.2 RAT的实现
RAT的工作流程
- 零样本CoT生成:根据任务提示,LLM生成一步步的思考。
- 检索与修正:检索相关信息,并用于修正当前思考步骤。
- 逐步生成与修正:按照CoT的顺序,逐步生成回应,并修正思考步骤。
- 最终回应生成:生成最终的回应,基于修正后的思考步骤。
RAT的优势
- 结合了RAG和CoT的优点,提高了上下文感知和事实准确性。
RAT的挑战
- 依赖外部知识库的质量和相关性。
- 迭代修正每个推理步骤可能增加计算成本。
3.3 算法实现
RAT算法的伪代码如下:
for each step in CoT: retrieve相关信息 based on task提示 and current step; refine current step with retrieved information; generate next step based on refined current step;最终生成回应 based on all refined steps;
通过这种结合,RAT方法在多步推理和长期生成任务中展现出显著的性能提升,为大型语言模型的应用和发展提供了新的可能性。

RAT算法流程解析
RAT算法是一种先进的生成任务处理方法,其流程可以细分为以下几个关键步骤:
步骤0:初始思考生成
- 任务提示接收:首先,接收一个任务提示(Task Prompt)。
- 零样本推理:利用大型语言模型(LLM)进行零样本推理,生成初始的逐步思考(Initial CoTs)。
步骤1-N:迭代修正思考
- 对于每个思考步骤
Ti: - 查询生成:使用当前草稿答案
T*和任务提示生成查询Qi。 - 信息检索:利用查询
Qi从知识库中检索相关信息Ri。 - 思考修正:基于检索到的信息
Ri和草稿答案T*,LLM修正第i步的思考,生成修正后的思考T*i。
步骤N+1:最终回答生成
- 思考步骤串联:将所有修正后的思考步骤串联起来,形成最终的回答。
实验分析
4.1 实验设置实验旨在全面评估RAT方法在不同领域的长期生成任务上的表现,包括:
-
代码生成:HumanEval、HumanEval+、MBPP、MBPP+
-
数学推理:GSM8K、GSM-HARD
-
创造性写作:开放性文本生成任务
-
体现任务规划:Minecraft环境任务 评估指标根据任务类型而定,例如:
-
代码生成:采用pass@k指标,即代码片段成功执行的比率。
-
数学推理:准确性,即问题解决的正确率。
-
体现任务规划:可执行性和可信度,通过自动计算和人类评估。
-
创造性写作:TrueSkill评分系统评估文本质量。 实验还包括了多种基线方法,如直接生成、CoT提示方法、RAG方法等,以及不同规模的LLMs,如GPT-3.5、GPT-4和CodeLLaMA-7b。所有实验均在零样本设置下进行。
4.2 实验结果实验结果将展示RAT方法如何通过结合检索增强生成和链式思考提示来提高LLMs的性能。
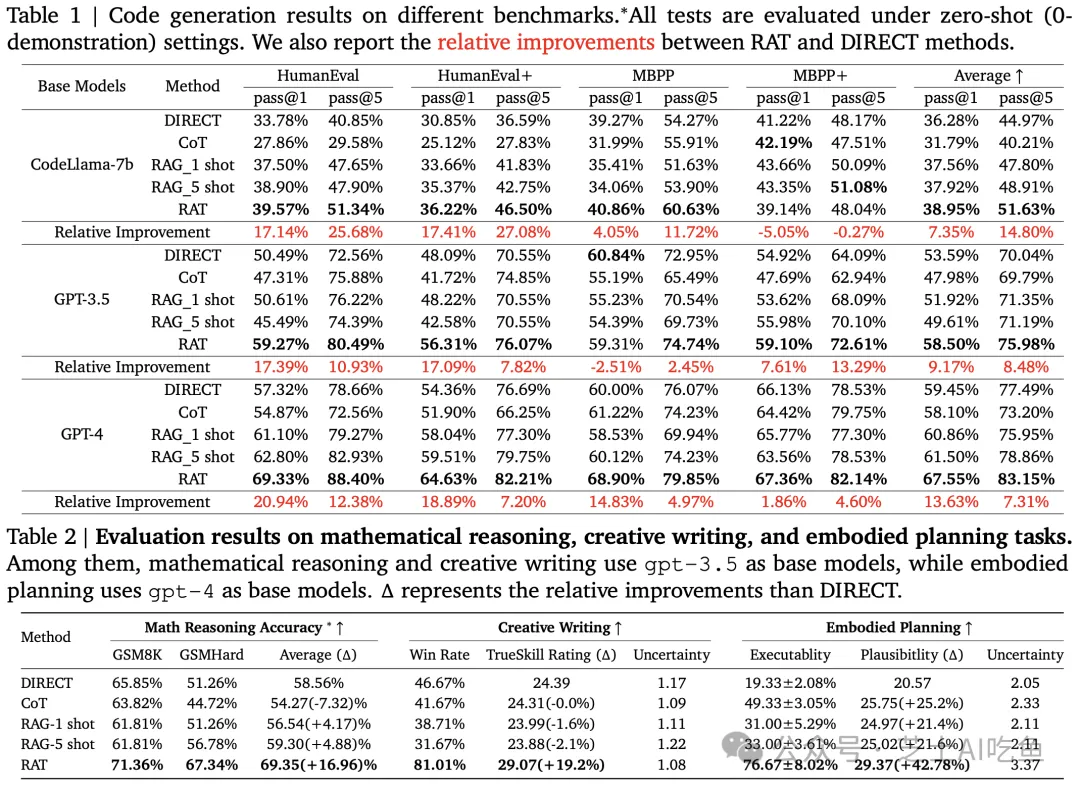
本实验遵循了以下步骤进行系统性的研究与评估:
-
数据预处理:为确保评估过程的公正性,采取了严格的数据清洗措施,避免基准测试结果受到直接解决方案的干扰。
-
检索库构建:针对代码生成与数学推理任务,本研究选用了codeparrot/github-jupyter数据集作为检索基础。对于Minecraft任务规划,则依托于Minecraft Wiki和DigMinecraft网站作为信息来源。
-
模型评估:通过一系列选定的评估指标,对不同方法进行了全面评估,包括RAT方法与其他基线方法。
-
结果分析:对实验结果进行了深入的定量与定性分析,以全面理解RAT在各项任务中的表现。 实验结果揭示了RAT在多个领域的卓越性能:
-
在代码生成任务中,RAT在HumanEval和HumanEval+基准测试中显著提升了准确度。
-
在数学推理任务中,RAT在GSM8K和GSMHard数据集上展现了显著的准确性提高。
-
在Minecraft任务规划中,RAT生成的计划在可执行性和可信度方面优于基线方法。
-
在创造性写作任务中,RAT生成的文本在质量、准确性和创新性方面获得了人类评估者的高度评价。

一、RAT方法概述
RAT(Retrieval-Augmented Thinking)是一种先进的人工智能方法,它在多个基准测试中表现出色,特别是在需要多步推理和上下文感知的场景中。RAT通过结合链式思考(Chain of Thought, CoT)和检索增强生成(Retrieval-Augmented Generation, RAG),提高了大型语言模型(LLMs)的性能,减少了幻觉的发生,并生成了更准确和可靠的输出。
1. 基准测试表现
- HumanEval和HumanEval+: 在代码生成任务上,RAT优于其他方法。
- GSM8K和GSMHard: 在数学推理问题上,RAT同样表现突出。
- Minecraft任务规划: RAT在游戏内任务规划上展现优越性能。
- 创造性写作任务: RAT在创造性写作上也有很好的表现。
2. 性能依赖性
- RAT的性能依赖于基础LLM的CoT和RAG能力。
- 检索到的知识质量对RAT的性能有显著影响。
- 迭代修正过程可能会增加计算成本。
二、RAT的创新点
RAT的主要创新之处在于其结合了CoT提示和RAG方法,通过迭代地修正每一步思考,利用外部知识库辅助模型进行更准确的推理。
- 结合CoT和RAG: RAT创新地将CoT的逐步推理与RAG的信息检索结合起来,形成了一种新的提示策略。
- 迭代修正: RAT通过迭代修正每个思考步骤,提高了修正的精确度和生成回答的质量。
三、不足与展望
尽管RAT在多个任务上展现出了优异的性能,但也存在一些局限性。
- 依赖基础LLM的CoT和RAG能力: 如果基础模型在这些方面的能力较弱,RAT的效果可能会受限。
- 检索知识的质量: 检索到的信息与用户查询的相关性和质量对RAT的效果至关重要。
- 检索成本和效率: 多次迭代检索和修正可能导致较高的计算成本和延迟。
- 显式步骤化的问题解决方式: 可能不适用于所有类型的复杂推理结构。
四、结论
RAT在多种长期生成任务上的有效性得到了验证,包括代码生成、数学推理、创造性写作和体现任务规划等。实验结果表明,RAT在这些任务上相比传统的CoT提示和RAG方法都有显著的性能提升。
- 性能提升: RAT在多个基准测试中一致优于其他方法。
- 减少幻觉: 通过结合CoT和RAG减少了LLM生成错误信息的倾向。
- 上下文感知: RAT生成的回答更加上下文感知,能够更好地利用外部知识库中的信息。
- 计算成本: 尽管性能提升,但计算成本和效率仍是挑战。
- 适应性: RAT展现出良好的适应性和泛化能力,具有广泛的应用潜力。 RAT方法通过其创新的策略在多个任务上取得了显著的性能提升,但仍需进一步研究来解决存在的问题,如提高检索效率、优化模型以适应更复杂的推理结构等。预计RAT及其衍生方法将在提高LLMs的性能方面发挥更大的作用。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E8%9E%8D%E5%90%88RAG%E5%92%8CCoT%E7%9A%84%E9%AB%98%E6%95%88%E5%A4%9A%E6%AD%A5%E6%8E%A8%E7%90%86%E4%BB%BB%E5%8A%A1%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


