实战入门FAISS搜索BERT模型 --知识铺
在这一期中,我们延续上一期 Bert 中文短句相似度计算 Docker CPU镜像,继续使用 huggingface transformer 和 sentence-transformer 类库,并将英语句子生成 bert embedding,然后引入 faiss 类库来建立索引,最后查询最接近的句子。
Docker 镜像获取方式
本期 docker 镜像获取方式为,关注 MyEncyclopedia 公众号后回复 docker-faiss-transformer 即可获取如下完整命令。
1 | docker run -p 8888:8888 myencyclopedia/faiss-demo bash -c 'jupyter notebook --allow-root --port 8888 --NotebookApp.token= --ip 0.0.0.0' |
然后打开浏览器,输入 http://localhost:8888/notebooks/faiss_demo.ipynb
faiss 简介
Faiss 的全称是Facebook AI Similarity Search,是由 Facebook 开发的适用于稠密向量匹配的开源库,作为向量化检索开山鼻祖,Faiss 提供了一套查询海量高维数据集的解决方案,它从两个方面改善了暴力搜索算法存在的问题:降低空间占用和加快检索速度。此外,Faiss 提供了若干种方法实现数据压缩,包括 PCA、Product-Quantization等。
Faiss 主要特性:
- 支持相似度检索和聚类;
- 支持多种索引方式;
- 支持CPU和GPU计算;
- 支持Python和C++调用;
Faiss 使用流程
使用 faiss 分成两部,第一步需要对原始向量建立索引文件,第二步再对索引文件进行向量 search 操作。
在第一次建立索引文件的时候,需要经过 train 和 add 两个过程;后续如果有新的向量需要被添加到索引文件,只需要一个 add 操作来实现增量索引更新,但是如果增量的量级与原始索引差不多的话,整个向量空间就可能发生了一些变化,这个时候就需要重新建立整个索引文件,也就是再用全部的向量来走一遍 train 和 add,至于具体是如何 train 和 add的,就和特定的索引类型有关了。
1. IndexFlatL2和indexFlatIP
对于精确搜索,例如欧式距离 faiss.indexFlatL2 或 内积距离 faiss.indexFlatIP,没有 train 过程,add 完直接可以 search。
1 | import faiss |
2.公司简介
IndexFlatL2 的结果虽然精确,但当数据集比较大的时候,暴力搜索的时间复杂度很高,因此我们一般会使用其他方式的索引来加速。比如 IndexIVFFlat,将数据集在 train 阶段分割为几部分,技术术语为 Voronoi Cells,每个数据向量只能落在一个cell中。Search 时只需要查询query向量落在cell中的数据了,降低了距离计算次数。这个过程本质就是高维 KNN 聚类算法。search 阶段使用倒排索引来。
IndexIVFFlat 需要一个训练的阶段,其与另外一个索引 quantizer 有关,通过 quantizer 来判断属于哪个cell。IndexIVFFlat 在搜索阶段,引入了nlist(cell的数量)与nprob(执行搜索的cell数)参数。增大nprobe可以得到与brute-force更为接近的结果,nprobe就是速度与精度的调节器。
1 | import faiss |
3. IndexIVFPQ
IndexFlatL2 和 IndexIVFFlat都要存储所有的向量数据。对于超大规模数据集来说,可能会不大现实。因此IndexIVFPQ 索引可以用来压缩向量,具体的压缩算法就是 Product-Quantization,注意,由于高维向量被压缩,因此 search 时候返回也是近似的结果。
1 | import faiss |
在本期中,我们仅使用基本的 IndexIVFFlat 和 IndexFlatIP 完成 bert embedding 的索引和搜索,后续会有篇幅来解读 Product-Quantization 的论文原理和代码实践。
ag_news 新闻数据集
ag_news 新闻数据集 3.0 包含了英语新闻标题,training 部分包含 120000条数据, test 部分包含 7600条数据。
ag_news 可以通过 huggingface datasets API 自动下载
1 | def load_dataset(part='test') -> List[str]: |
显示前三条新闻标题为
1 | 120000 |
变压器
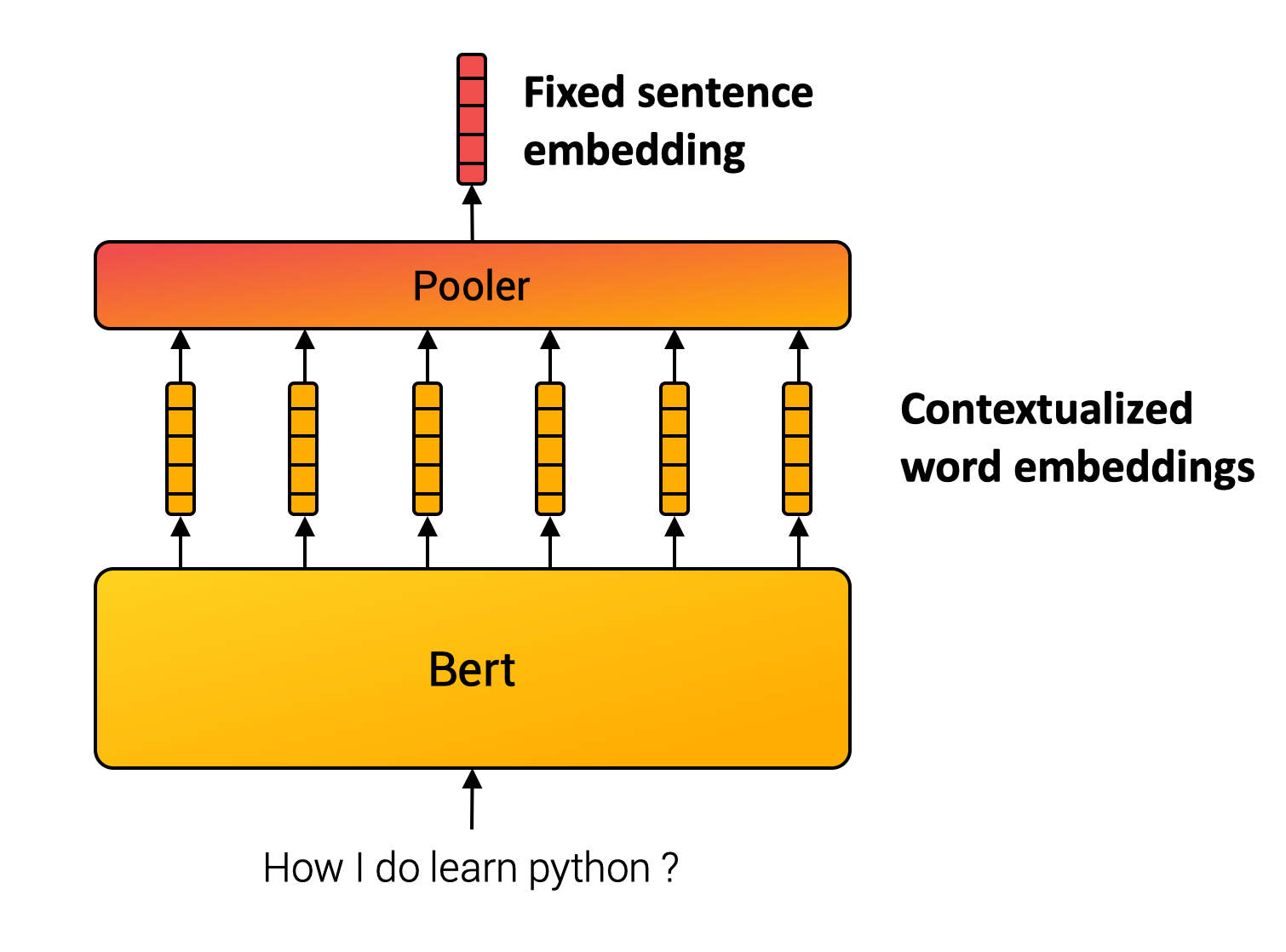
和上一期一样,我们利用sentence-transformer 生成句子级别的embedding。其原理基于 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (https://arxiv.org/abs/1908.10084)这篇论文。基本思想很直接,将句子中的每个词的 bert embedding ,输进入一个池化层(pooling),例如选择最简单的平均池化层,将所有token embedding 的均值作为输出,便得到跟输入句子长度无关的一个定长的 sentence embedding。
结果展示
数据集 train 部分由于包含的样本比较多,需要一段时间生成 bert embedding,大家可以使用 load_dataset(part='test') 来快速体验。下面我们演示一个查询 how to make money 的最接近结果。
1 | index = load_index('news_train.index') |
1 | Profit From That Traffic Ticket Got a traffic ticket? Can't beat 'em? Join 'em by investing in the company that processes those tickets. |
核心代码
所有可运行代码和数据都已经包含在 docker 镜像中了,下面列出核心代码
建立索引
1 | def train_flat(index_name, id_list, embedding_list, num_clusters): |
查询结果
1 | def query(model, index, query_str: str) -> List[int]: |
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E5%AE%9E%E6%88%98%E5%85%A5%E9%97%A8FAISS%E6%90%9C%E7%B4%A2BERT%E6%A8%A1%E5%9E%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


