基于Milvus的语义检索系统搭建 --知识铺
语义检索系统构建指南
概述在构建推荐系统中,召回和排序是核心环节。本次讨论的重点是使用Milvus搭建召回系统,并通过语义索引模型抽取向量进行检索,以加速索引过程。
语义搜索系列文章概览
- 无监督预训练语义索引召回:介绍了SimCSE和Diffcse两种方法。 阅读更多
- 基于in-batch Negatives策略的有监督训练语义召回:探索了有监督训练在语义召回中的应用。 阅读更多
- Milvus在召回系统中的应用:本文将详细介绍如何使用Milvus进行向量检索。 阅读更多
- 基于ERNIE-Gram和RocketQA的数据精排序:讨论了使用ERNIE-Gram和RocketQA进行数据精排的方法。 阅读更多
- 学术文献语义检索系统完整版:展示了结合Milvus、ERNIE、SimCSE和IBN的学术文献检索系统构建。 阅读更多
更多文本匹配方案
- 特定领域知识图谱融合方案:提供了文本匹配算法和知识融合的学术界与业界方案。 阅读更多
- Simnet、Diffcse文本匹配算法:介绍了Simnet和Diffcse在文本匹配中的应用。 阅读更多
- ERNIE-Gram单塔模型:探讨了ERNIE-Gram单塔模型在文本匹配中的效果。 阅读更多
- 基于ERNIEKit的文本匹配算法:使用ERNIEKit实现文本匹配的实践。 阅读更多
- 问题匹配鲁棒性评测:讨论了问题匹配的鲁棒性评测方法。 阅读更多
Milvus与向量检索基础
1.1 向量检索概念向量检索是从向量库中根据目标向量找出最近的K个向量的过程。这通常基于欧氏距离或余弦距离来衡量向量间的相似度。
1.2 Milvus简介Milvus是一个开源的向量数据库,专为向量检索设计,支持多种距离度量方式,适用于多种类型数据的检索,如图像、文本和语音等。
1.3 向量检索的应用向量检索技术在推荐系统中扮演重要角色,尤其是在召回阶段,通过快速检索相似向量来筛选候选项目。
结语通过上述内容,我们了解了如何使用Milvus构建召回系统,并结合语义索引模型进行高效的向量检索。在推荐系统的构建过程中,这将是提升召回效率和准确性的关键步骤。
请耐心阅读相关文档,逐步解决搭建过程中遇到的问题,以完成整个推荐系统的构建。

Milvus自2019年诞生以来,专注于为深度学习与机器学习模型生成的嵌入向量提供存储、索引和管理服务。作为一款专业的向量数据库,它能够高效地在万亿规模的数据中进行向量索引查询。Milvus与常规的关系型数据库不同,后者通常处理结构化数据,而Milvus则是针对非结构化数据转换得到的嵌入向量进行设计的。
特点概述
- 创建时间: 2019年
- 核心目标: 管理大量嵌入向量
- 设计初衷: 处理深度神经网络和其他机器学习模型生成的数据
- 功能定位: 存储、索引和管理嵌入向量
- 技术优势: 能够在万亿规模数据上实现高效索引
- 数据类型: 主要处理非结构化数据转换而来的嵌入向量
- 与关系数据库的区别: Milvus专为向量查询设计,而关系数据库处理结构化数据
技术细节
- 向量索引: Milvus能够对输入的向量进行快速索引,支持大规模数据集。
- 查询效率: 针对向量查询进行了优化,确保查询速度。
- 数据规模: 支持万亿级别的数据规模,满足大数据需求。
- 设计哲学: 从底层架构开始,专为处理嵌入向量而设计。
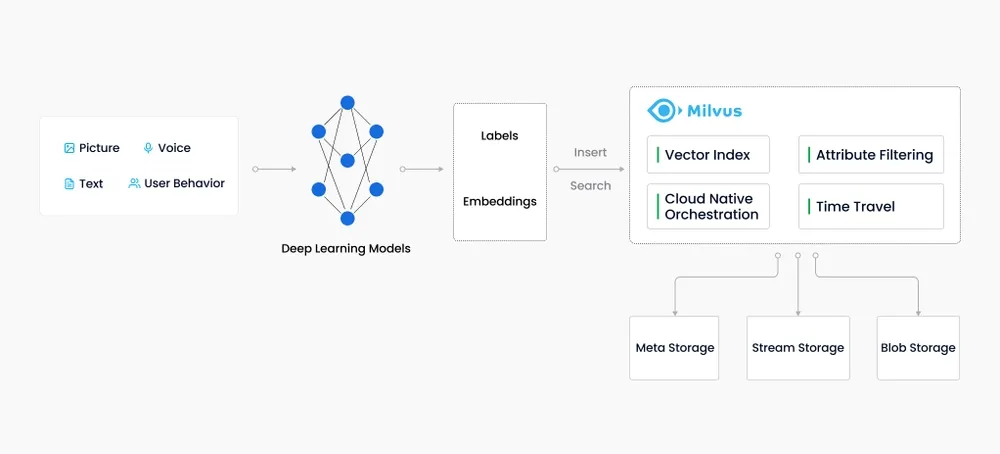
Milvus 向量数据库概述
Milvus 是一款开源的向量数据库,专为处理大规模向量数据而设计。它支持TB级别的向量数据的增删改操作和近实时查询,具备高度灵活性、稳定性和快速查询能力。Milvus 集成了多种向量索引库,如 Faiss、NMSLIB 和 Annoy,提供了数据分区分片、数据持久化、增量数据摄取等高级功能,大幅优化了向量检索的性能。
特点
- 灵活性:支持不同场景下的索引类型选择。
- 稳定性:保证大规模数据处理的可靠性。
- 高速查询:优化算法以实现快速检索。
架构Milvus 采用共享存储架构,实现存储与计算的完全分离,支持计算节点的横向扩展。其架构分为四个层次:
- 接入层:处理客户端请求。
- 协调服务:管理数据流和控制流。
- 执行节点:执行具体的数据处理任务。
- 存储层:负责数据的持久化存储。
应用场景随着互联网的发展,非结构化数据变得日益重要。Milvus 通过嵌入技术将这类数据转换为向量,并进行存储和索引,使得计算机能够分析和处理这些数据。Milvus 能够通过计算向量间的相似度来评估原始数据的相关性。
服务端组件Milvus 服务端由以下两部分组成:
- Milvus Core:负责存储和管理向量及标量数据。
- Meta Store:管理元数据,支持 SQLite 和 MySQL。
架构细节Milvus 服务器采用主从式架构,确保了系统的高可用性和扩展性。
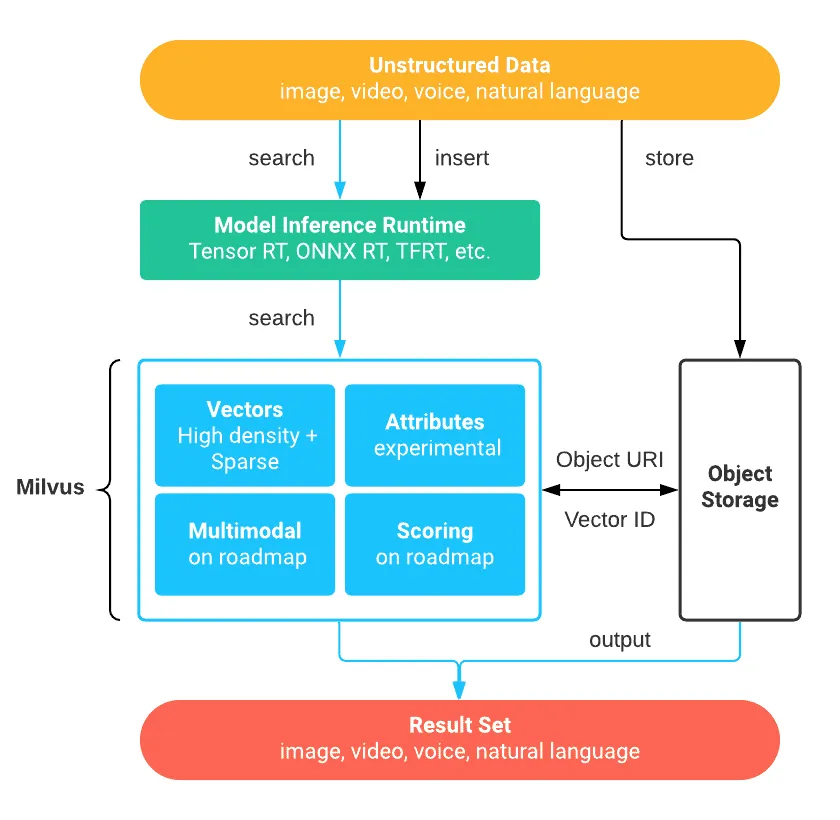
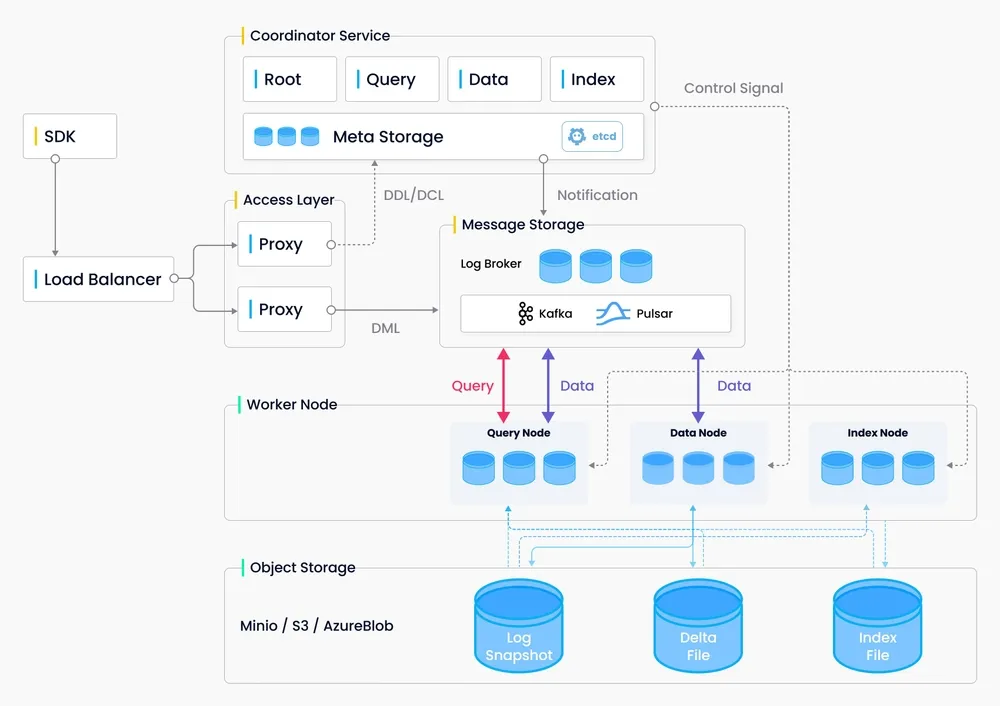
Milvus 向量数据库概述
1. 产品优势Milvus 是一款高性能的向量数据库,具备以下显著优势:
-
全面的相似性指标:支持欧氏距离、内积等多样的向量相似度计算方法。
-
高性能:基于优化的ANNS索引库,如faiss、annoy、hnswlib,适应不同场景需求。
-
动态数据管理:轻松实现数据的插入、删除、搜索和更新。
-
高成本效益:利用并行计算,单机可处理十亿级数据搜索。
-
近实时搜索:保障数据一致性,实现快速搜索。
-
支持多种数据类型和高级搜索:字段支持多类型数据,满足复杂查询。
-
高扩展性和可靠性:易于在分布式环境中部署和扩展。
-
云原生:适配公有云、私有云、混合云等环境。
-
简单易用:提供Python、Java、Go、C++ SDK及RESTful API,简化使用流程。
2. Milvus 应用场景Milvus 可用于构建多种向量相似度检索系统,包括:
-
图片检索系统:实现以图搜图功能。
-
视频检索系统:基于关键帧的向量检索相似视频。
-
音频检索系统:快速检索和匹配音频数据。
-
分子式检索系统:检索化学分子结构的相似性。
-
推荐系统:基于用户行为推荐信息或商品。
-
智能问答机器人:自动答疑。
-
DNA 序列分类系统:快速基因分类。
-
文本搜索引擎:通过关键词搜索文本信息。 更多详细信息,请参阅以下资料:
3. 环境依赖和安装说明
环境依赖安装Milvus前,请确保满足以下依赖条件:
-
Python 版本不低于 3.6.2。
-
PaddlePaddle 版本不低于 2.2。
-
PaddleNLP 版本不低于 2.2。
-
Milvus 版本不低于 2.1.0。
-
PyMilvus 版本不低于 2.1.0。
代码结构
具体的代码结构将根据项目需求进行组织。
|—— scripts |—— feature_extract.sh 提取特征向量的bash脚本 |—— search.sh 插入向量和向量检索bash脚本 ├── base_model.py # 语义索引模型基类 ├── config.py # milvus配置文件 ├── data.py # 数据处理函数 ├── milvus_ann_search.py # 向量插入和检索的脚本 ├── inference.py # 动态图模型向量抽取脚本 ├── feature_extract.py # 批量抽取向量脚本 ├── milvus_util.py # milvus的工具类 └── README.md
4. 数据准备
数据集的样例如下,有两种,第一种是 title+keywords 进行拼接;第二种是一句话。
|
|
数据集下载
|
|
|
|
|
|
|
|
|
|
5. 向量检索系统构建
5.1 基于Milvus的向量检索系统搭建
在数据准备阶段完成后,接下来我们将构建一个基于Milvus的语义检索引擎。Milvus是一个开源工具,专门用于处理大规模高维向量的相似性搜索。本案例中,我们使用的是Milvus的2.1版本,推荐采用官方提供的Docker安装方式,这种方法简单且高效。
5.1.1 Milvus系统搭建
首先,我们需要搭建Milvus系统。根据Milvus官方提供的安装教程,我们可以通过以下步骤进行安装:
- 确保系统满足硬件和软件的安装要求。2. 下载
milvus-standalone-docker-compose.yml文件,并重命名为docker-compose.yml:shell $ wget https://github.com/milvus-io/milvus/releases/download/v2.1.4/milvus-standalone-docker-compose.yml -O docker-compose.yml3. 在包含docker-compose.yml文件的目录下,使用Docker Compose启动Milvus服务:shell $ sudo docker-compose up -d4. 检查容器是否成功启动:shell $ sudo docker-compose ps5. 如果需要停止Milvus服务,可以使用以下命令:shell sudo docker-compose down6. 如果需要删除Milvus的数据,可以执行:shell sudo rm -rf volumes
5.1.2 生成embedding向量
Milvus系统搭建完成后,我们需要生成embedding向量。本案例中,每个样本将生成一个256维的向量。向量的生成是在配备32GB V100 GPU的机器上完成的。以下是生成向量的基本步骤:
- 准备数据集:确保你拥有需要检索的样本数据。2. 使用适当的机器学习模型对样本数据进行处理,以生成embedding向量。3. 向量化处理:将样本数据转换为256维的向量形式。 生成的向量将用于后续的插入和检索操作。
5.1.3 向量插入与检索
- 插入向量:将生成的embedding向量插入到Milvus中,以便进行管理和检索。
- 检索向量:利用Milvus的相似性搜索功能,根据查询向量快速检索出相似的向量。 通过上述步骤,你可以构建一个高效的向量检索系统,实现对大规模数据集的快速语义检索。
|
|
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils. warnings.warn("Setuptools is replacing distutils.") [1m[35m--- Running analysis [ir_graph_build_pass][0m I0713 16:49:07.969594 6532 executor.cc:187] Old Executor is Running. [1m[35m--- Running analysis [ir_analysis_pass][0m [32m--- Running IR pass [map_op_to_another_pass][0m [32m--- Running IR pass [identity_scale_op_clean_pass][0m [32m--- Running IR pass [is_test_pass][0m [32m--- Running IR pass [simplify_with_basic_ops_pass][0m [32m--- Running IR pass [delete_quant_dequant_linear_op_pass][0m [32m--- Running IR pass [delete_weight_dequant_linear_op_pass][0m [32m--- Running IR pass [constant_folding_pass][0m [32m--- Running IR pass [silu_fuse_pass][0m [32m--- Running IR pass [conv_bn_fuse_pass][0m [32m--- Running IR pass [conv_eltwiseadd_bn_fuse_pass][0m [32m--- Running IR pass [embedding_eltwise_layernorm_fuse_pass][0m [32m--- Running IR pass [multihead_matmul_fuse_pass_v2][0m I0713 16:49:08.685951 6532 fuse_pass_base.cc:59] --- detected 12 subgraphs [32m--- Running IR pass [vit_attention_fuse_pass][0m [32m--- Running IR pass [fused_multi_transformer_encoder_pass][0m [32m--- Running IR pass [fused_multi_transformer_decoder_pass][0m [32m--- Running IR pass [fused_multi_transformer_encoder_fuse_qkv_pass][0m [32m--- Running IR pass [fused_multi_transformer_decoder_fuse_qkv_pass][0m [32m--- Running IR pass [multi_devices_fused_multi_transformer_encoder_pass][0m [32m--- Running IR pass [multi_devices_fused_multi_transformer_encoder_fuse_qkv_pass][0m [32m--- Running IR pass [multi_devices_fused_multi_transformer_decoder_fuse_qkv_pass][0m [32m--- Running IR pass [fuse_multi_transformer_layer_pass][0m [32m--- Running IR pass [gpu_cpu_squeeze2_matmul_fuse_pass][0m [32m--- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass][0m [32m--- Running IR pass [gpu_cpu_flatten2_matmul_fuse_pass][0m [32m--- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass][0m I0713 16:49:09.470413 6532 fuse_pass_base.cc:59] --- detected 38 subgraphs [32m--- Running IR pass [gpu_cpu_map_matmul_v2_to_matmul_pass][0m [32m--- Running IR pass [matmul_scale_fuse_pass][0m [32m--- Running IR pass [multihead_matmul_fuse_pass_v3][0m [32m--- Running IR pass [gpu_cpu_map_matmul_to_mul_pass][0m [32m--- Running IR pass [fc_fuse_pass][0m I0713 16:49:09.519965 6532 fuse_pass_base.cc:59] --- detected 38 subgraphs [32m--- Running IR pass [fc_elementwise_layernorm_fuse_pass][0m I0713 16:49:09.542423 6532 fuse_pass_base.cc:59] --- detected 24 subgraphs [32m--- Running IR pass [conv_elementwise_add_act_fuse_pass][0m [32m--- Running IR pass [conv_elementwise_add2_act_fuse_pass][0m [32m--- Running IR pass [conv_elementwise_add_fuse_pass][0m [32m--- Running IR pass [transpose_flatten_concat_fuse_pass][0m [32m--- Running IR pass [conv2d_fusion_layout_transfer_pass][0m [32m--- Running IR pass [transfer_layout_elim_pass][0m [32m--- Running IR pass [auto_mixed_precision_pass][0m [32m--- Running IR pass [inplace_op_var_pass][0m I0713 16:49:09.547497 6532 fuse_pass_base.cc:59] --- detected 1 subgraphs [1m[35m--- Running analysis [save_optimized_model_pass][0m W0713 16:49:09.548242 6532 save_optimized_model_pass.cc:28] save_optim_cache_model is turned off, skip save_optimized_model_pass [1m[35m--- Running analysis [ir_params_sync_among_devices_pass][0m I0713 16:49:09.548257 6532 ir_params_sync_among_devices_pass.cc:51] Sync params from CPU to GPU [1m[35m--- Running analysis [adjust_cudnn_workspace_size_pass][0m [1m[35m--- Running analysis [inference_op_replace_pass][0m [1m[35m--- Running analysis [ir_graph_to_program_pass][0m I0713 16:49:09.937587 6532 analysis_predictor.cc:1660] ======= optimize end ======= I0713 16:49:09.937990 6532 naive_executor.cc:164] --- skip [feed], feed -> token_type_ids I0713 16:49:09.938001 6532 naive_executor.cc:164] --- skip [feed], feed -> input_ids I0713 16:49:09.938807 6532 naive_executor.cc:164] --- skip [elementwise_div_1], fetch -> fetch [32m[2023-07-13 16:49:09,939] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'rocketqa-zh-base-query-encoder'.[0m [32m[2023-07-13 16:49:09,939] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_base_zh_vocab.txt and saved to /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder[0m [32m[2023-07-13 16:49:10,063] [ INFO][0m - Downloading ernie_3.0_base_zh_vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_base_zh_vocab.txt[0m 100%|████████████████████████████████████████| 182k/182k [00:00<00:00, 3.51MB/s] [32m[2023-07-13 16:49:10,249] [ INFO][0m - tokenizer config file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/tokenizer_config.json[0m [32m[2023-07-13 16:49:10,249] [ INFO][0m - Special tokens file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/special_tokens_map.json[0m 0%| | 0/10000000 [00:00<?, ?it/s]W0713 16:49:20.130687 6532 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.6 W0713 16:49:20.137218 6532 gpu_resources.cc:149] device: 0, cuDNN Version: 8.4. 100%|███████████████████████████| 10000000/10000000 [1:27:15<00:00, 1910.02it/s]
执行过程部分展示:
|
|
语义检索系统构建指南
1. 导出静态图模型
在使用Paddle Inference进行模型推理时,首先需要将模型导出为静态图。以下是导出模型的参考步骤:
- 访问提供的项目链接语义检索系统以获取更多详细信息。
- 根据项目指导,使用Paddle Inference导出自己的静态图模型。
2. 模型推理时间对比
以下是不同硬件配置下,对1000万条数据进行模型推理的时间对比: | 数据量 | 显卡型号及容量 | 推理时间 || —–
- | ————-
- | ————-
- || 1000万条 | V100 32GB | 3小时41分钟 || 1000万条 | A100 40GB | 1小时27分钟 |
3. 向量生成与存储
完成模型推理后,会生成一个名为corpus_embedding.npy的文件,该文件包含了数据的向量表示。
4. Milvus库配置与数据插入
4.1 修改配置
为了将生成的向量数据插入到Milvus库,需要先修改配置文件config.py:
- 修改Milvus服务器的IP地址和端口号。本项目使用的端口是8530,而Milvus默认端口是19530。请根据实际部署情况调整。
4.2 插入向量数据
- 根据修改后的配置,将
corpus_embedding.npy中的向量数据插入到Milvus库中。
注意事项
- 确保在插入数据前,Milvus服务已经启动并且配置正确。
- 在进行数据插入时,注意检查数据的一致性和完整性。 以上步骤为构建语义检索系统的基础流程,具体操作可能根据实际项目需求有所调整。
|
|
Milvus 向量插入常见问题及解决方案
在将向量数据插入Milvus库的过程中,可能会遇到一些常见问题。以下是问题汇总以及相应的解决方案:
问题汇总
-
Milvus连接问题:在使用AI studio时,可能会遇到无法连接到Milvus服务器的问题。具体表现为
pymilvus.exceptions.MilvusException异常,错误码为2,提示Fail connecting to server。查看详情 -
程序卡死问题:在执行
milvus_ann_search.py脚本时,可能会遇到程序卡死的情况。这通常发生在尝试插入向量数据时。查看详情 -
匹配精度问题:在使用Milvus进行匹配时,如果只匹配到一个字,召回率可能异常地高(如0.6)。这可能需要调整匹配策略,避免仅匹配单个字的情况。查看详情
解决方案
-
解决连接问题:如果在使用AI studio时遇到连接问题,可以尝试在本地环境运行,因为AI studio可能无法访问外网。
-
解决程序卡死问题:针对程序卡死,需要关注两个方面:
-
确保
--batch_size参数设置得当,不宜过大,建议小于64MB,以避免数据传输错误。 -
检查词嵌入的字符长度,确保不超过1000个字符,以避免潜在的匹配问题。 请注意,这些解决方案可能需要根据具体情况进行调整。
- RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1027) of 7940th string exceeds max length (1000))>, <Time:{'RPC start': '2023-07-21 17RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1092) of 734th string exceeds max length (1000))>, <Time:{'RPC start': '2023-07-21 17:44:15.949226', 'RPC error': '2023-07-21 17:44:16.494690'}> - Milvus insert error: <MilvusException: (code=1, message=the length (1092) of 734th string exceeds max length (1000))>RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1074) of 121th string exceeds max length (1000))>, <Time:{'RPC start': '2023-07-21 17:45:46.076491', 'RPC error': '2023-07-21 17:45:46.115044'}>Milvus insert error: <MilvusException: (code=1, message=the length (1074) of 121th string exceeds max length (1000))>
```
3. 针对第三个问题:Milvus只起到加速的效果,这个跟模型相关,并且关键字匹配不推荐使用语义检索,如果是句子级别的匹配,使用语义检索更合适;推荐进行双路召回【语义+关键字】
- 进入重点如何启动milvus向量库以及涉及到docker使用等,我把遇到问题总结成一份文档,遇到问题请参考下文:
- [一文带你入门向量数据库milvus:含docker安装、milvus安装使用、attu 可视化,完整指南启动 Milvus 进行了向量相似度搜索](http://zshipu.com/t/index.html?url=https://blog.csdn.net/sinat_39620217/article/details/131847096)
其中:docker-compose.yml文件也放在项目根目录了。
```python
# !python milvus_ann_search.py --data_path /home/aistudio/literature_search_data/milvus/milvus_data.csv \ # --embedding_path corpus_embedding.npy \ # --batch_size 1000 \ # --insert
参数含义说明
以下是对参数的详细说明,帮助用户更好地理解每个参数的作用:
-
data_path: 指向存储数据的文件路径。 -
embedding_path: 指向存储数据向量的文件路径。 -
index: 用于指定检索向量时使用的索引。 -
insert: 布尔值,指示是否执行向量的插入操作。 -
search: 布尔值,指示是否执行向量的检索操作。 -
batch_size: 指定每次插入操作中包含的向量数量。
性能数据对比
以下是不同显卡在处理相同数据量时的性能对比数据,以供参考: | 数据量 | 显卡型号 | 处理时间 || –
- | –
- | –
- || 1000万条 | V100 32GB | 23分钟 || 1000万条 | A100 40GB | 数据缺失 |
插入过程进程
插入向量的过程是数据处理的关键步骤之一。以下是插入过程的详细描述:
-
初始化: 准备数据和向量文件,确保路径正确无误。
-
配置参数: 设置
batch_size等参数,以优化插入效率。 -
执行插入: 根据
insert参数的值,决定是否执行插入操作。 -
监控进度: 在插入过程中,实时监控进度,确保操作顺利进行。
-
完成插入: 完成所有向量的插入后,进行必要的数据同步和验证。 注意:插入过程中可能会涉及到大量的数据操作,因此请确保硬件资源充足,以避免性能瓶颈。
|
|
另外,Milvus提供了可视化的管理界面,可以很方便的查看数据,安装地址为Attu.
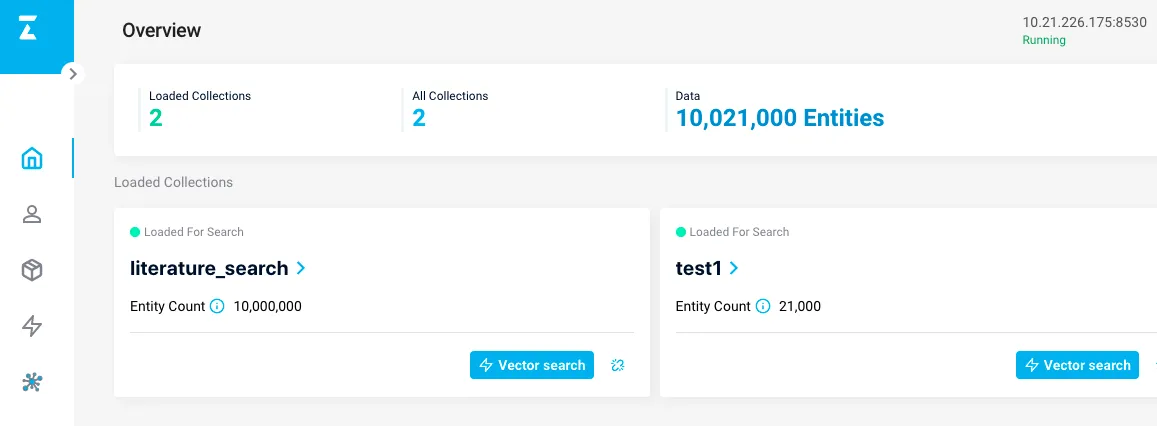
|
|
运行以后的结果的输出为:
|
|
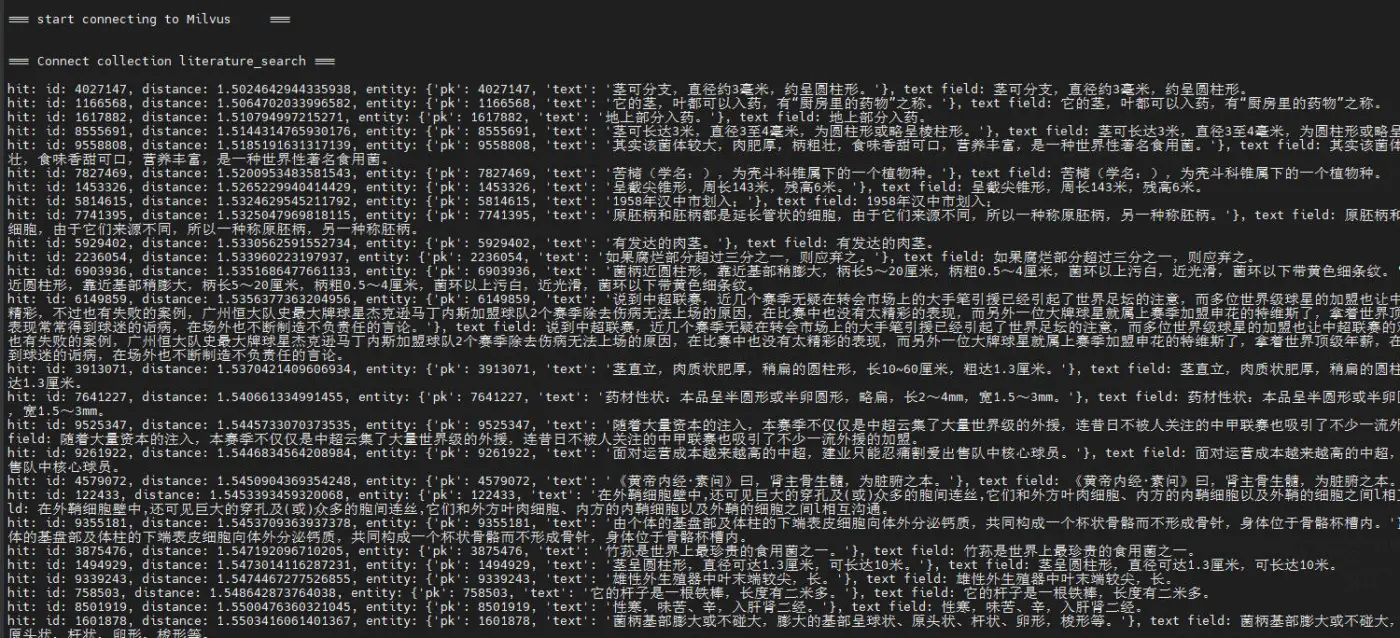
返回的是向量的距离,向量的id,以及对应的文本。
也可以一键执行上述的过程:
sh scripts/search.sh
5.2 文本检索
首先修改代码的模型路径和样本:
|
|
|
|
|
|
|
|
|
|
|
|
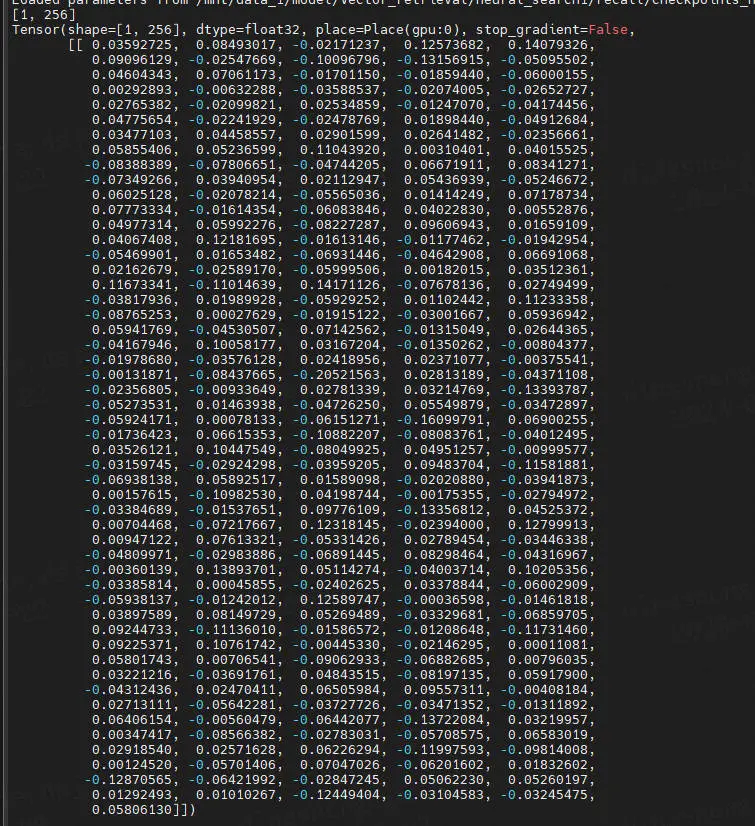
运行的输出为,分别是抽取的向量和召回的结果:
[1, 256] Tensor(shape=[1, 256], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[ 0.07830613, -0.14036864, 0.03433795, -0.14967985, -0.03386058, 0.06630671, 0.01357946, 0.03531205, 0.02411086, 0.02000865, 0.05724005, -0.08119474, 0.06286906, 0.06509133, 0.07193415, .... hit: (distance: 0.40141725540161133, id: 2742485), text field: 完善国有企业技术创新投入机制的探讨--基于经济责任审计实践国有企业,技术创新,投 入机制 hit: (distance: 0.40258315205574036, id: 1472893), text field: 企业技术创新与组织冗余--基于国有企业与非国有企业的情境研究 hit: (distance: 0.4121206998825073, id: 51831), text field: 企业创新影响对外直接投资决策—基于中国制造业上市公司的研究企业创新;对外直接投资; 制造业;上市公司 hit: (distance: 0.42234909534454346, id: 8682312), text field: 政治关联对企业创新绩效的影响——国有企业与民营企业的对比政治关联,创新绩效,国有 企业,民营企业,双重差分 hit: (distance: 0.46187296509742737, id: 9324797), text field: 财务杠杆、股权激励与企业创新——基于中国A股制造业经验数据制造业;上市公司;股权激 励;财务杠杆;企业创新 ....
Milvus 常见问题与系统配置指南
6. FAQ 常见问题解答
6.1 语义向量检索问题在 Milvus 中,即使文本完全相同,由于浮点数舍入误差,计算出的距离也不会为 0。Milvus 使用欧氏距离或内积来衡量向量相似性。实际应用中,可以通过设置阈值来判断向量是否相似。更多索引创建详情,请参考Milvus官方文档。
7. Milvus 更多信息### 7.1 API 参考文档
- Python SDK: Pymilvus GitHub 使用手册。
- Java SDK: [milvus-sdk-java] 待提供链接和使用手册。
- Go SDK: [milvus-sdk-go] 待提供链接和使用手册。
- RESTful SDK: [milvus-sdk-restful] 项目源码及使用手册。
- C++ SDK: [milvus-sdk-c++] 项目源码及使用手册。
7.2 Milvus 系统配置
7.3 Milvus 技术细节
- 数据管理系列:涵盖数据管理策略、数据文件清理、元数据管理等。
- 新功能:如分区表、Mishards 架构介绍。
- 查询任务调度原理。
7.4 Milvus 常见问题
- 性能优化问题、产品问题、部署运维问题、故障诊断等。
7.5 Milvus 相关工具
- Milvus Enterprise Manager: 服务端图形化交互与管理工具。
- Milvus Sizing Tool: 硬件配置估算工具。
- MilvusDM: 数据迁移工具。
7.6 应用示例
- 图像视频检索、智能问答机器人、音频数据处理、化学分子式相似性分析、推荐系统等。
7.7 在线项目体验提供在线服务体验,如以图搜图、智能问答机器人、音频分析等。
7.8 用户案例
- 相似视频检索、拍照购物实现、病毒 APK 检测、钓鱼网站检测、基于语义向量的召回、音乐推荐平台应用等。 更多用户案例和 Milvus 相关内容,请关注 汀丶人工智能。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E5%9F%BA%E4%BA%8EMilvus%E7%9A%84%E8%AF%AD%E4%B9%89%E6%A3%80%E7%B4%A2%E7%B3%BB%E7%BB%9F%E6%90%AD%E5%BB%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


