向量检索技术详解及应用案例 --知识铺
向量检索技术是一种高效的搜索方法,广泛应用于多个领域。以下是对这项技术的详细解析以及其应用场景的梳理。
向量检索技术概述向量检索技术允许我们在向量空间中快速找到与查询向量最相似的向量。这项技术通常基于度量方式,如欧式距离,实现相似向量的搜索。在实际应用中,非结构化数据如文本、图像和视频首先被转化为向量形式,然后通过向量检索技术进行处理。
技术实现
- 数据嵌入:将非结构化数据转化为向量形式。
- 相似性度量:使用特定的度量方法(如欧式距离)来比较向量间的相似度。
应用领域
- 人脸识别:通过分析人脸特征的向量表示来识别个体。
- 推荐系统:根据用户行为或偏好的向量表示推荐相关内容。
- 图片搜索:通过比较图像特征的向量来搜索相似图片。
- 视频指纹:利用视频中提取的向量进行内容的快速检索。
- 语音处理:将语音信号转化为向量,进行语音识别或其他处理。
- 自然语言处理:文本数据向量化后,进行语义分析或信息检索。
- 文件搜索:基于文件内容的向量表示进行快速搜索。
开源工具介绍在向量检索领域,有几个开源工具非常受欢迎,它们提供了强大的索引和搜索功能。
Faiss由 Meta(原 Facebook)开源的 Faiss 是一个用于高效相似性搜索的库,支持多种索引结构和度量方式。
MilvusMilvus 是一个开源的向量数据库,以其高性能和易用性著称,适用于处理大规模向量数据。
其他工具
- Proxima
- Vearch
- Jina 这些工具各有特点,但共同提供了强大的向量检索能力。
索引方式在 Faiss 中,有几种常用的索引方式,包括:
IndexFlatL2
- 基于欧氏距离的精确检索。
- 适用于小规模数据集。
IndexIVFFlat
- 使用倒排索引加速搜索。
- 适用于大规模数据集。
IndexIVFPQ
- 利用乘积量化技术进行有损压缩,以空间换时间。
结论向量检索技术在现代 AI 应用中扮演着重要角色,开源工具如 Faiss 和 Milvus 提供了强大的支持。随着技术的发展,我们可以预见向量检索将在更多领域展现其潜力。
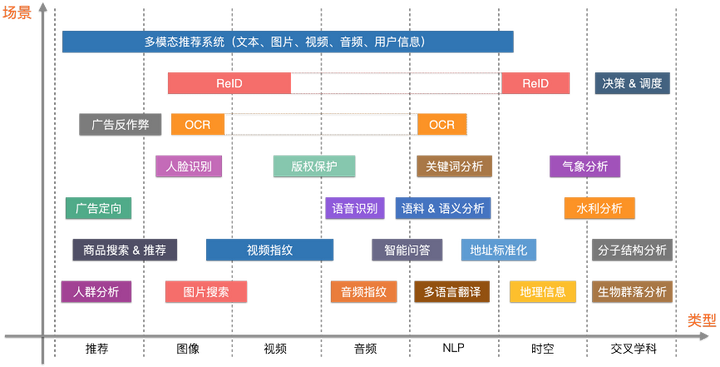
向量数据库概述
向量检索任务在许多现代应用中扮演着重要角色,例如推荐系统、图像搜索和自然语言处理等。然而,传统的关系型数据库(如MySQL、PostgreSQL)并不适用于这类任务,因为它们缺乏处理高维向量数据的优化。以下是向量数据库与传统数据库的主要区别和优势。
向量检索的特性
- 高维度数据:向量检索处理的通常是具有数百到数千个维度的高维数据。
- 相似性度量:基于相似性度量(如欧氏距离、余弦相似度)进行向量检索。
- 近似最近邻搜索(ANN):在大规模数据集上使用近似算法提高检索效率。
普通数据库的限制
- 索引结构:传统数据库的索引结构不适合高维向量数据。
- 查询优化:查询优化器主要针对SQL查询优化,对向量检索优化有限。
- 扩展性:分布式存储和计算能力支持不足。
向量数据库的优势
- 高效的索引结构:支持HNSW、IVF、PQ等索引结构,优化高维向量检索。
- 优化的相似性计算:针对高维向量计算进行优化。
- 扩展性和分布式支持:支持分布式存储和计算,处理大规模数据。
索引类型
以下是一些常见的索引类型及其特点: | 索引类型 | 原理 | 特点 | 适用场景 | 优点 | 缺点 || –
- | –
- | –
- | –
- | –
- | –
- || FLAT | 线性扫描 | 精确度高,速度慢 | 小规模数据集 | 精度高 | 大数据集速度慢 || IVF | 簇划分 | 加速查询,平衡速度和精度 | 中大规模数据集 | 速度快,精度平衡 | 精度稍低 || PQ | 子空间划分和量化 | 存储效率高,查询快 | 大规模数据集 | 存储和查询效率高 | 量化精度损失 || HNSW | 多层图结构 | 高查询效率和精度 | 高效查询的大规模数据集 | 查询速度快,高精度 | 结构复杂,内存消耗大 || LSH | 哈希映射 | 适用于高维数据 | 高维数据查询 | 查询速度快 | 精度较低 || ANNOY | 随机投影树 | 平衡速度和精度 | 大规模数据集 | 速度和精度平衡 | 构建时间长 || IVF-PQ | 簇划分和量化 | 优化存储和查询效率 | 需要效率优化的场景 | 存储和查询效率优化 | 构建维护复杂 || ScaNN | 结合量化和排序 | 大规模数据集表现出色 | 大规模数据集 | 大规模数据集表现好 | 算法复杂度高 |
相似度指标
- Euclidean distance (L2):常用于计算机视觉。
- Inner product (IP):常用于自然语言处理。
- Hamming、Jaccard、Tanimoto:常用于分子相似性搜索。
- Superstructure、Substructure:用于分子结构搜索。
主流向量数据库对比
以下是一些主流向量数据库的对比: | 数据库 | 发布者 | 时间 | 功能 | 优点 | 缺点 || –
- | –
- | –
- | –
- | –
- | –
- || Milvus | Zilliz | 2019 | 多模态检索,分布式架构 | 高性能,多模态支持 | 部分功能依赖商业 || FAISS | Facebook AI Research | 2017 | 多种索引类型,GPU加速 | 高性能,灵活性强 | 持久化和分布式支持弱 || Annoy | Spotify | 2014 | 随机投影树,磁盘持久化 | 简单易用 | 写操作不高效 || NMSLIB | 非官方开源项目 | 2013 | 多种近似算法 | 性能优秀 | 文档和社区支持少 || Weaviate | SeMI Technologies | 2019 | 分布式搜索,知识图谱 | 上下文感知搜索 | 社区生态新 || Pinecone | Pinecone.io | 2020 | 商业化托管服务 | 全托管服务 | 使用成本高 || Qdrant | Qdrant | 2021 | 高性能搜索,实时更新 | 高性能,实时更新 | 社区生态发展中 |
Milvus 向量数据库
Milvus 是一个高性能分布式向量数据库,由Zilliz开发并开源,最初由阿里巴巴孵化。它支持多模态向量检索,具有多种索引类型和分布式架构。
功能
- 多模态向量检索
- 多种索引类型
- 分布式架构
- 数据持久化
- 高级查询
- 图形化界面
- API 支持
架构
Milvus 的架构包括:
- Coordinator:集群管理
- Proxy:请求处理
- Data Node:数据存储
- Query Node:查询处理
- Index Node:索引管理
- Meta Store:元数据存储
社区和使用情况
Milvus 社区活跃,广泛应用于多模态检索和推荐系统等领域。GitHub上Star数超过14k,Fork数超过2k。
官方文档
官方文档提供了详细的部署和使用指南,包括如何在Amazon EKS上部署Milvus。
官方文档
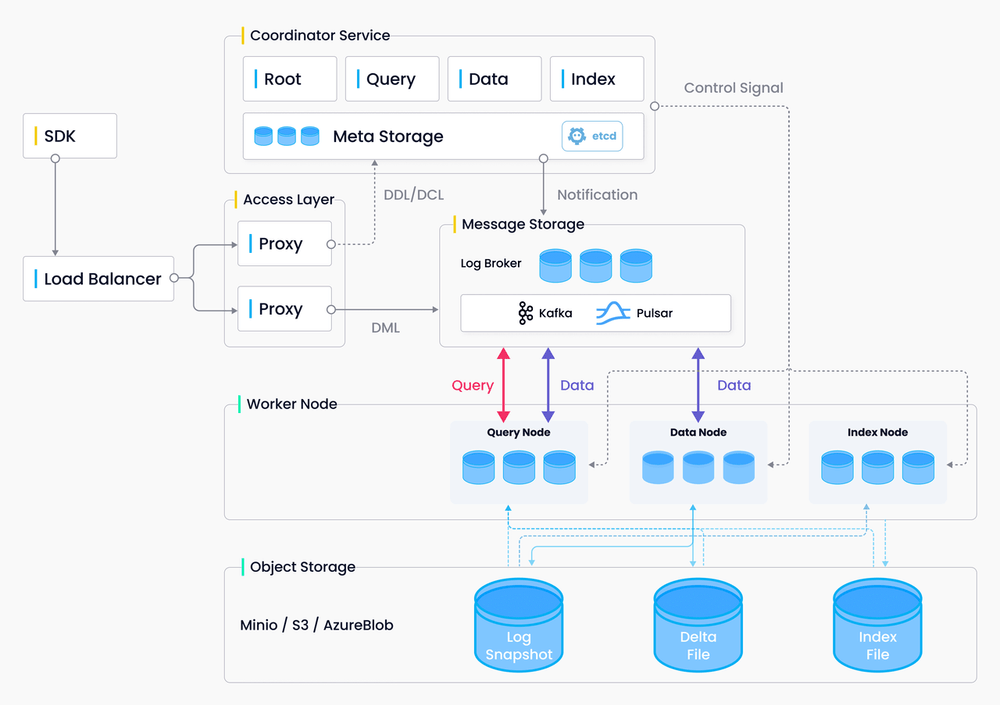
节点角色与设计原则
Milvus 2.0 的设计原则和数据流程是构建其高性能向量数据库的基础。以下是对Milvus中节点角色和设计原则的概述。
节点角色
- Query Node:负责处理数据查询请求。
- Data Node:负责数据的写入操作以及数据的持久化存储。
- Index Node:主要负责索引的构建和查询加速。
设计原则Milvus 2.0 的设计遵循以下原则:
- 日志作为数据:系统中所有的数据变更都通过日志序列化记录。
- 表与日志的二元性:表是有界数据,日志是无界数据,日志可以转换为表。
- 日志持久性:通过发布-订阅(pub/sub)系统解决日志的存储和持久化问题。
数据流程数据在Milvus中的流动遵循以下流程:
- 日志(Logs):记录数据变更。
- 日志快照(Log Snapshot):将多个日志聚合成小文件。
- 段(Segment):由日志快照组合形成,用于负载均衡。
第三方依赖Milvus 集群依赖以下第三方服务:
- MinIO:用于对象存储。
- etcd:用于存储元数据和提供服务注册与健康检查。
- Pulsar:作为日志代理,提供日志发布和订阅服务。
Storage层组成Storage层由以下三个部分组成:
- Meta Store:存储元数据快照。
- Log Broker:支持数据流式存储和异步查询执行。
- Object Storage:存储日志快照文件、索引文件和查询处理结果。
数据处理过程数据在Milvus中的处理过程包括以下几个步骤:
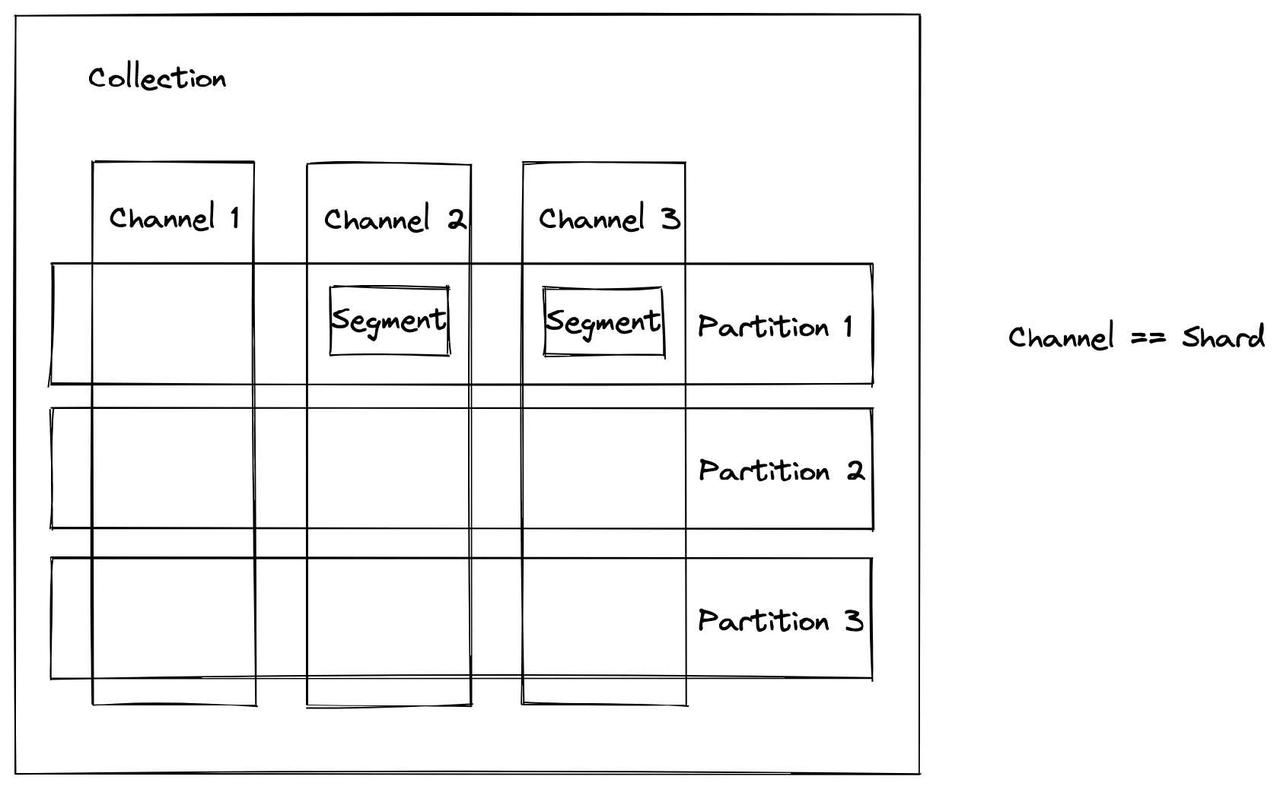
- 数据写入:为每个集合(Collection)设置分片数量,数据根据主键哈希值写入相应分片。
- 自动触发Data Flush:当段达到默认大小(512MB)时,自动触发数据刷新到磁盘。
- 段的三种状态:
- Growing Segment:允许插入数据。
- Sealed Segment:关闭不再接受数据。
- Flushed Segment:已被写入磁盘。
加载数据到内存(实时查询)查询节点通过以下方式加载数据以支持实时查询:
- 从日志代理加载流数据。
- 从对象存储加载历史数据。 查询节点需要管理历史数据和增量数据,历史数据存储在封闭段,增量数据存储在开放段。系统通过负载均衡和查询节点故障转移来确保查询效率和可靠性。
参考链接
- Milvus 架构概述
- Milvus 数据模型
- Milvus 实时查询
以上内容提供了Milvus 2.0的节点角色、设计原则、数据流程、第三方依赖、Storage层组成以及数据处理过程的详细介绍。
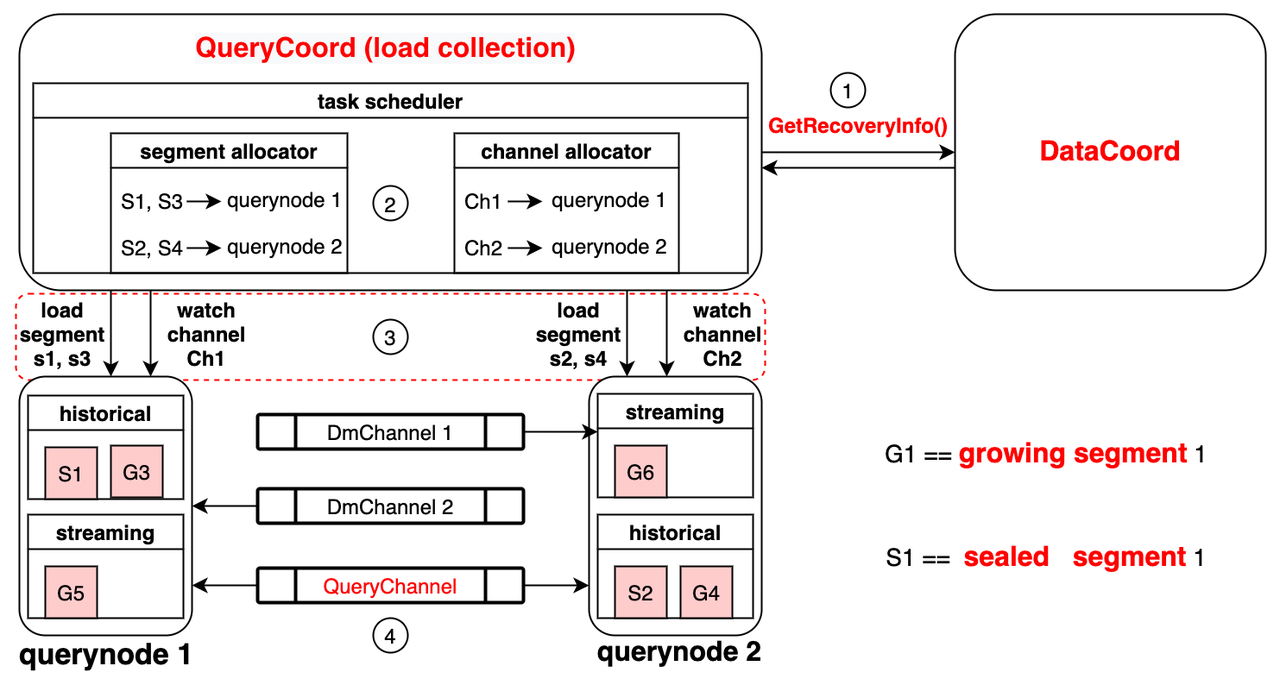
索引建立与查询过程
索引建立索引节点在处理数据索引化时,遵循以下步骤:
- 加载数据:从对象存储中的段(segment)加载日志快照(log snapshots)到内存。
- 反序列化:将加载的数据和元数据反序列化,以便于建立索引。
- 建立索引:根据反序列化后的数据和元数据构建索引。
- 序列化索引:索引构建完成后,将索引序列化。
- 写回存储:将序列化的索引写回对象存储。
向量检索的挑战由于向量的高维度特性,传统的基于树的索引方法不再适用。现代技术采用聚类(cluster-based)或基于图(graph-based)的索引方法,以提高检索效率。
查询过程Milvus中的集合被划分为多个段(segment),查询节点在执行查询时遵循以下步骤:
- 加载索引:根据查询协调器(query coord)的指令,按需加载或释放段的索引。
- 执行搜索:在本地段中执行搜索操作。
查询节点的职责每个查询节点负责以下两项任务:
- 根据查询协调器的指令加载或释放段。
- 在本地段中进行搜索。
段的类型查询节点处理两种类型的段:
- 增长段(growing segments):用于增量数据,订阅vchannel以接收最近的更新。
- 封闭段(sealed segments):用于历史数据。
索引技术的发展随着技术的发展,传统的树状索引已逐渐被聚类或图基索引所取代,以适应高维向量的检索需求。
Milvus 与 FAISS 概览
Milvus 简介Milvus 是一款开源的向量数据库,专为大规模特征向量检索设计。它支持多种数据类型,包括图像、文本和视频等,能够满足推荐系统、图像搜索等应用场景的需求。
核心概念
- Collection: 类似于关系型数据库中的表,存储具有相同结构的数据。
- Index: 用于加速检索的索引,Milvus 提供多种索引类型,如 FLAT、IVF 等。
- Schema: 定义集合中字段的数据类型和属性。
特点
- 高性能: 针对大规模数据和高并发场景进行优化。
- 多模态支持: 支持多种数据类型的向量检索。
- 易用性: 提供多语言 SDK 和 RESTful API。
- 分布式架构: 支持横向扩展。
应用场景Milvus 适用于需要高效向量搜索的应用,例如电商平台的多模态商品搜索。
FAISS 简介FAISS 是由 Facebook AI Research 开发的库,用于高效相似性搜索和聚类分析。
功能
- 支持多种索引类型,包括 Flat、IVF 等。
- 高效的内存和计算资源使用。
- GPU 加速支持。
架构FAISS 包含 Index、Vector Storage 和 Distance Computation 等核心组件。
优缺点
- 优点: 高性能,特别是在 GPU 环境下;灵活性好,支持多种索引类型。
- 缺点: 数据持久化和分布式支持较弱,学习曲线较陡。
应用场景FAISS 适用于大规模基因相似性分析等场景。
Elasticsearch 与 Milvus 和 FAISS 对比Elasticsearch 是一个强大的分布式搜索和分析引擎,但在向量检索方面,Milvus 和 FAISS 提供了更专业的解决方案。
性能对比
- Milvus 和 FAISS 在高维向量检索性能上优于 Elasticsearch。
数据持久化和分布式支持
- Milvus 和 Elasticsearch 都提供数据持久化和分布式支持,而 FAISS 主要设计用于内存内检索。
多模态支持
- Milvus 专为多模态向量检索设计,而 Elasticsearch 通过扩展支持向量检索。
易用性和生态系统
- Elasticsearch 拥有丰富的生态系统和工具,Milvus 和 FAISS 需要一定的配置和使用经验。
数据规模和适用场景在选择使用 Elasticsearch、Milvus 或 FAISS 时,需要考虑数据规模、向量维度和检索需求。
判断数据规模的标准
- 向量维度、向量数量、检索延迟和并发请求量。
具体规模建议
- 小规模数据集可能适合使用 Elasticsearch。
- 中等规模数据集可能需要优化 Elasticsearch 配置。
- 大规模数据集可能更适合使用 Milvus 或 FAISS。
问答传统数据库与向量数据库的区别在于传统数据库侧重 IO 操作,而向量数据库需要大量计算资源。
实践### FAISS 安装参考 INSTALL-FAISS。
使用根据具体需求选择合适的索引类型和配置。
|
|
API Reference
FAISS(Facebook AI Similarity Search)是一个由Facebook AI Research(FAIR)团队开发的高效相似性搜索和聚类库。它提供了多种算法来搜索任意大小的向量集合,包括那些可能不适合在RAM中存储的大型集合。FAISS是用C++编写的,并为Python提供了完整的包装器,部分算法也在GPU上实现。以下是FAISS的一些重要资源链接:
-
FAISS索引类型 此外,有一个示例教程可以参考:
Milvus
Milvus是一个开源的向量数据库,适用于各种规模的AI应用,从在Jupyter笔记本中运行演示聊天机器人到构建为数十亿用户提供服务的网络规模搜索。以下是Milvus的一些核心概念和资源链接:
-
Milvus GitHub示例 在Milvus中,
Collection和Index是两个关键概念,它们分别负责数据存储和检索优化: -
Collection:用于存储向量及其相关元数据。可以将其视为传统SQL数据库中的表。
-
Index:基于Collection中的向量数据构建,用于加速检索操作。
示例应用
- 创建Collection:
创建一个Collection是Milvus中数据存储的第一步。以下是创建Collection的基本步骤:
在上述设置中,Collection的名称为
1 2 3 4 5 6 7 8from pymilvus import MilvusClient client = MilvusClient("milvus_demo.db") if client.has_collection(collection_name="demo_collection"): client.drop_collection(collection_name="demo_collection") client.create_collection( collection_name="demo_collection", dimension=768, # 假设我们使用的向量有768维 )demo_collection,向量字段的维度设置为768。Collection的创建是进行数据插入和检索的前提。
|
|
- 创建 Index:
|
|
通过理解 collection 和 index 的概念及其功能,可以更好地在 Milvus 中组织和优化向量数据的存储和检索。
查看 collection
|
|
加载到内存 collection
Milvus 中的所有搜索和查询操作都是在内存中执行的。因此在执行搜索或查询之前需要将集合加载到内存。
这个加载过程发生在Milvus服务所在的服务器上,而不是客户端。
|
|
在搜索或查询之后从内存中释放集合以减少内存使用量。
|
|
数据写入和更新 collection
|
|
Milvus 数据刷新机制
Milvus 是一个开源的向量数据库,它支持高效的向量搜索功能。在数据写入过程中,Milvus 采用了增量日志的方式来确保数据的持久化存储。以下是 Milvus 数据刷新的详细步骤和注意事项:
数据写入流程
- 数据插入:当数据被插入到 Milvus 时,Milvus 首先将其加载到消息队列中,并返回操作成功的响应。
- 数据持久化:数据节点随后将消息队列中的数据以增量日志的形式写入到持久化存储中。
flush() 方法
- 作用:
flush()方法用于强制数据节点立即将消息队列中的所有数据写入到持久化存储。 - 触发条件:如果需要在插入数据后立即进行搜索,可以在数据插入后调用
flush()方法。 - 自动触发:Milvus 会在适当的时候自动触发
flush()操作,大多数情况下无需手动调用。
数据全量更新方案
- 场景:当需要全量更新一个 Collection 的数据时。
- 推荐方案:新建一个表,导入数据,然后使用 Alias 切换到新的表。
注意事项
- 使用
flush()方法时,应根据实际需求判断是否需要手动调用。 - 对于全量更新数据,推荐使用新建表加导入数据的方案,以保证数据的一致性和完整性。
MilvusHelperMilvusHelper 是一个辅助工具,用于帮助用户更好地管理和操作 Milvus 数据库。它提供了一些实用的功能,如数据导入、导出、搜索等,以简化用户的操作流程。
|
|
Milvus Lite 与 Milvus 是两款面向不同使用场景的向量检索系统。以下是它们的主要区别和适用场景:
- 架构差异:
- Milvus:采用分布式架构,适合大规模数据和高并发请求,具备高可用性和扩展性。
- Milvus Lite:轻量级单节点部署,面向开发、测试和小规模应用。
- 资源需求:
- Milvus:需要较多的计算和存储资源,以及集群环境和专业运维。
- Milvus Lite:资源占用少,适合单机运行,适合资源有限的环境。
- 性能与扩展性:
- Milvus:性能强大,可处理大规模数据和高并发,支持水平扩展。
- Milvus Lite:性能和扩展性有限,适合小规模数据和低并发。
- 运维复杂度:
- Milvus:运维管理复杂,涉及节点管理、负载均衡和故障恢复。
- Milvus Lite:运维简单,适合个人或小团队。 适用场景:
- Milvus:适用于大型生产环境,如搜索引擎、大数据分析、推荐系统等,需要处理大量数据和复杂查询。
- Milvus Lite:适用于开发测试、小规模应用或资源受限环境,适合个人开发者、小团队、初创企业。
关于 Milvus 的问题,
collection.num_entities应返回逻辑上的总实体数,包括已删除但未物理移除的实体。compaction操作会合并数据段并移除标记为删除的数据。目前存在一个问题,即删除操作未被正确计算,具体详情见 GitHub Issue #17193。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E5%90%91%E9%87%8F%E6%A3%80%E7%B4%A2%E6%8A%80%E6%9C%AF%E8%AF%A6%E8%A7%A3%E5%8F%8A%E5%BA%94%E7%94%A8%E6%A1%88%E4%BE%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


