向量数据库结合AI套件与LLM大模型:构建专属知识问答服务实践教程 --知识铺
腾讯云向量数据库(Tencent Cloud VectorDB)构建专属知识库问答服务
背景信息
大型语言模型 (LLM) 是自然语言处理 (NLP) 领域的关键技术,具备强大的 NLP 服务能力。然而,这些模型的训练数据主要覆盖了通用知识和常识,对于特定领域的专业知识处理存在一定的局限性。为了使 LLM 能够理解和利用其训练数据之外的专业知识,可以通过特定的提示来引导模型更好地理解和回答特定领域的复杂问题。本文通过结合腾讯云向量数据库 (VectorDB),构建一个针对特定领域的智能问答系统,以扩展 LLM 的知识范围。
实现思路
- 文档上传与处理
-
使用腾讯云向量数据库的 AI 套件上传知识库文件,并将其拆分成更小的文本片段。
-
对这些文本片段进行向量化处理,以便能够通过向量相似性进行检索。
-
将文本片段及其对应的向量数据存储在腾讯云向量数据库中。
- 问题向量化与检索
-
当用户提出一个问题时,使用腾讯云向量数据库的 Embedding 功能将问题转换为向量形式。
-
在数据库中执行相似性检索,找到与问题最为相似的文本片段。
- 生成答案
-
将用户的问题和检索到的相关文本片段组合起来,形成完整的上下文。
-
将这个上下文送入 LLM 大模型中,以生成最符合上下文的答案。
架构示意图
请注意,架构示意图会在实际文档中展示,此处省略。
aaaaaaa
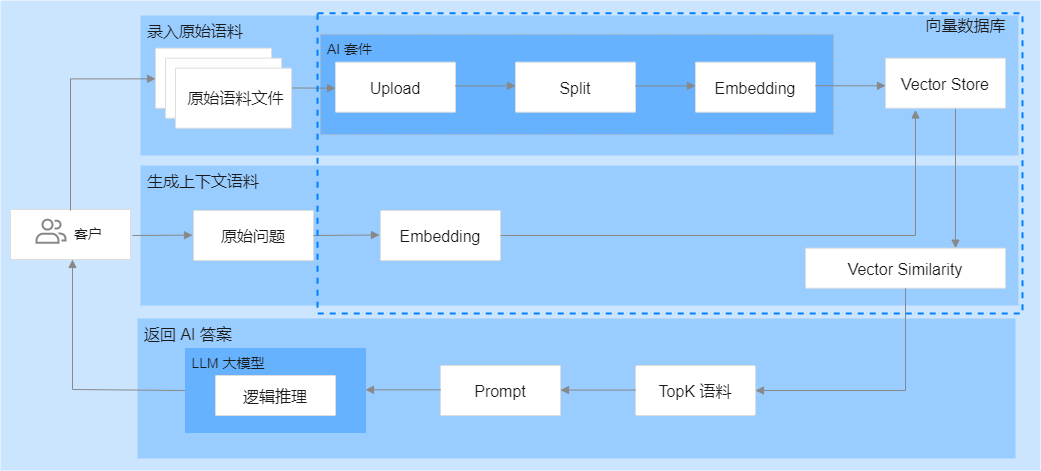
腾讯云向量数据库的AI套件为用户提供了一整套一站式向量检索解决方案,其中包括数据分割与Embedding服务。借助这些服务,用户无需手动编写用于数据拆分和向量化的代码,从而大大减少了在算法工程方面的投入,并显著简化了整个开发流程,降低了业务集成的复杂度。
同时,该解决方案通过利用相似性检索技术,使得上下文语料能够更有效地指导大型语言模型(LLM)生成更加精确的回答,进而提高了回答的质量与准确性。此外,腾讯云向量数据库还采用了灵活的存储策略,可以根据业务需求的变化实时优化和更新知识库,确保系统的稳定运行。
|
|
步骤2:创建客户端对象,连接数据库实例
|
|
步骤3:知识库初始化
声明 knowledgeInit() 函数,初始化知识库。
1. 为腾讯云向量数据库专有知识库创建一个 AI 类数据库 testdb。
2. 在已创建的 AI 类数据库中,创建集合视图 knowledge。
|
|
步骤4:传入问题进行知识内容相似性检索
声明 searchKnowlege() 函数,传入用户 question,返回知识库中与用户 question 最相似的内容。
|
|
步骤5:将用户问题与知识库检索的相似性语料送入大语言模型(LLM),生成问题答案
说明:
-
示例模型:以Baichuan2-Turbo大模型为例。
-
作用:检索所获取的相似性语料将更有效地指引大语言模型(LLM)进行逻辑推理,从而生成更准确的答案。
-
注意点:
-
内容需要有条理性和结构性。
-
使用markdown格式输出。
-
将markdown中的换行符
\n替换成aaaaaa。 -
遵循严格的JSON格式要求。
|
|
步骤6:构建 main() 函数
3. 将检索结果的 Topk 条 knowledges 与 输入的问题 question 进行内容组装。
|
|
在腾讯云向量数据库中,Embedding功能是指将文本数据转换为高维向量表示的过程。这一过程对于理解和处理自然语言至关重要。通过Embedding,可以捕捉到文本中的语义信息,并将其转化为机器可以处理的数值形式。这些高维向量能够有效地衡量文本之间的相似性,从而使得在大规模数据集中搜索和检索特定信息变得可能。Embedding功能是构建知识图谱、实现语义搜索等应用的基础技术之一。通过腾讯云向量数据库的AI套件,用户可以轻松地为自己的数据集创建高质量的Embedding,进而提升基于这些数据的应用和服务的性能和准确性。aaaaaaa当通用的大语言模型(LLM)在预训练阶段缺乏相关数据时,可能会出现幻觉问题,即模型会产生与事实不符的回答。而借助腾讯云向量数据库的知识库对LLM进行知识补充后,可以显著提高其回答问题的准确性。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
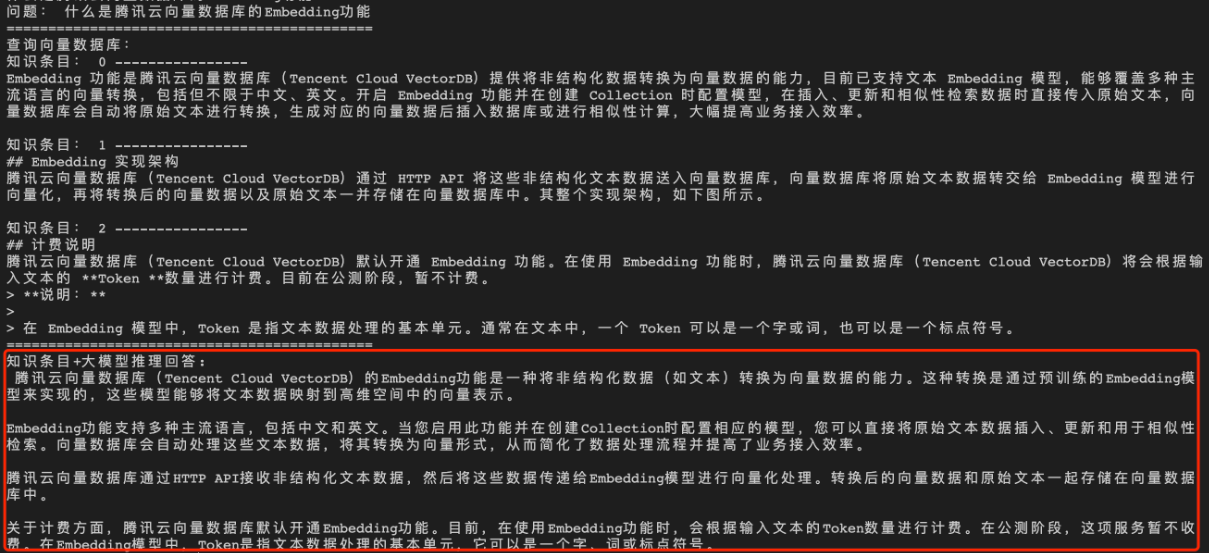
问题2:什么是腾讯云向量数据库中的 AI 套件?
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
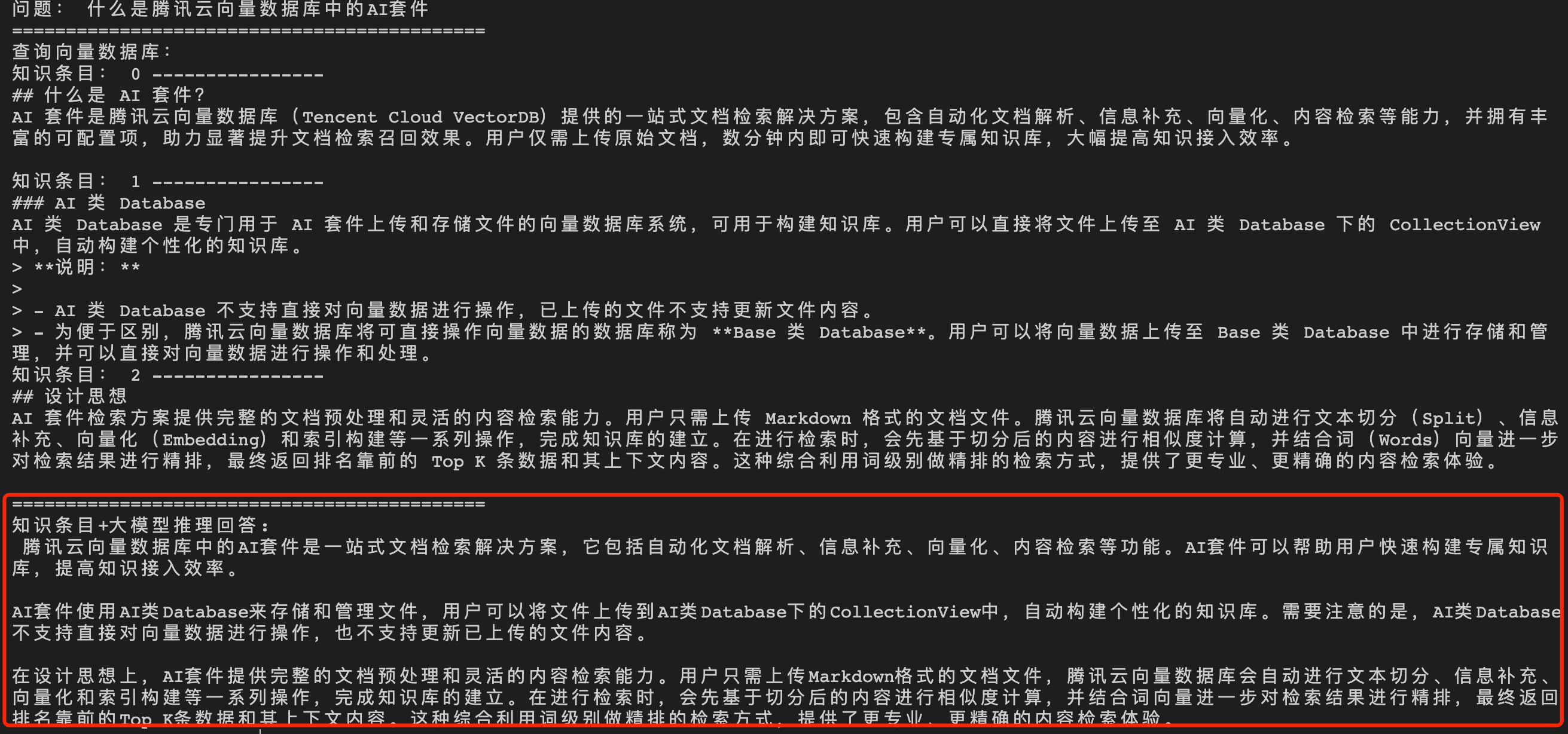
问题3:腾讯云向量数据库支持的最大 QPS
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
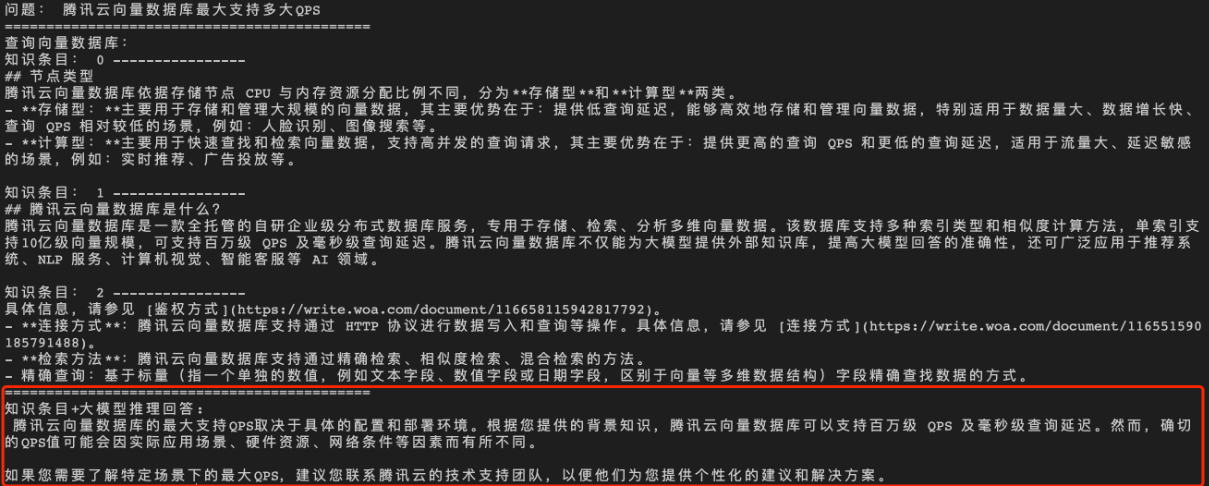
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E7%BB%93%E5%90%88AI%E5%A5%97%E4%BB%B6%E4%B8%8ELLM%E5%A4%A7%E6%A8%A1%E5%9E%8B%E6%9E%84%E5%BB%BA%E4%B8%93%E5%B1%9E%E7%9F%A5%E8%AF%86%E9%97%AE%E7%AD%94%E6%9C%8D%E5%8A%A1%E5%AE%9E%E8%B7%B5%E6%95%99%E7%A8%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


