使用检索增强生成(RAG)系统提升搜索:技术和最佳实践 --知识铺
大型语言模型(LLMs)的兴起彻底重塑了搜索与信息检索领域。
RAG系统的概念与发展
RAG(Retrieval-Augmented Generation)系统是由刘易斯在2020年提出的一种新型信息检索技术。这种系统结合了大型语言模型的强大能力与传统的文档检索技术,旨在提高搜索结果的相关性和准确性。
传统方法的局限性
虽然基于关键词的搜索以及像BM25这样的算法在过去的搜索场景中发挥了重要作用,但它们往往受限于对查询意图的理解不足以及无法有效处理自然语言的复杂性。这导致搜索结果可能不够准确或相关。
LLMs带来的变化
大型语言模型的引入显著提升了RAG系统的效能。LLMs不仅能够更好地理解用户查询的真实意图,还能从海量数据中检索出最相关的信息片段。通过这种方式,它们可以生成更加精准的回答。
RAG系统的工作原理
RAG系统的核心机制包括以下几个步骤:
-
信息检索:首先,系统会使用传统的信息检索技术从数据库中找到与查询相关的文档。
-
内容理解:接着,利用LLMs的强大理解能力,系统会对检索到的信息进行深度分析。
-
答案生成:最后,系统根据对文档内容的理解生成高质量的回答。
结论
随着研究的不断深入和技术的进步,RAG系统正变得越来越成熟。它们不仅提高了搜索效率,还极大增强了用户体验。未来,我们可以期待看到更多创新性的方法被应用于这一领域,进一步提升RAG系统的性能。
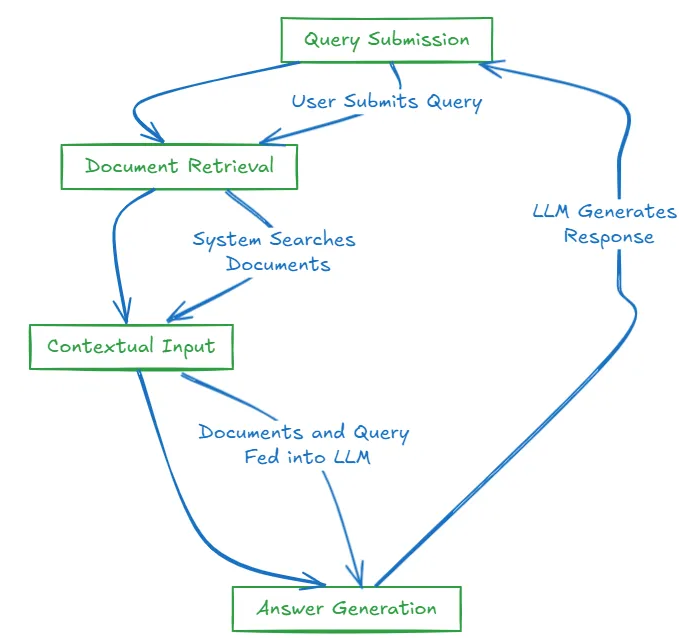
查询处理流程与局限性的解决方法
查询处理通常遵循以下步骤:
- 查询提交
- 用户提交他们的问题或查询。
- 文档检索
- 系统搜索并检索可能包含问题答案的相关文档。
- 上下文整合
- 这些文档与原始查询一起被送入大型语言模型(LLM)进行处理。
- 答案生成
- LLM基于提供的上下文生成响应。
解决局限性
这种方法有助于克服在静态或有限数据集上训练的LLMs的一些局限性,比如对于新颖查询给出错误答案,或者生成不准确的信息甚至出现"幻觉"现象。
早期发展阶段及面临的挑战
在早期研究中,人们尝试通过向LLMs添加额外的文档来增强其检索能力。然而,这种方法存在成本高昂的问题,并且随着新信息的出现,模型需要持续不断地重新训练。
关键技术改进
鉴于上述挑战,研究重点转向了优化检索过程本身。通过改善文档检索机制,可以更有效地利用现有知识,减少对频繁模型更新的需求。
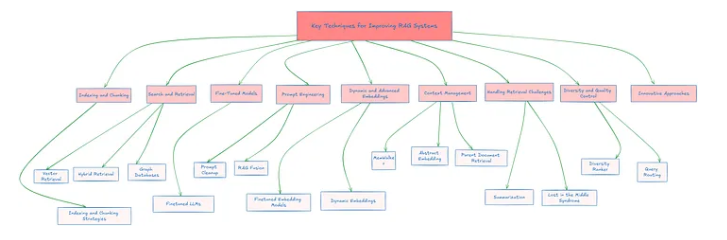
索引和组块
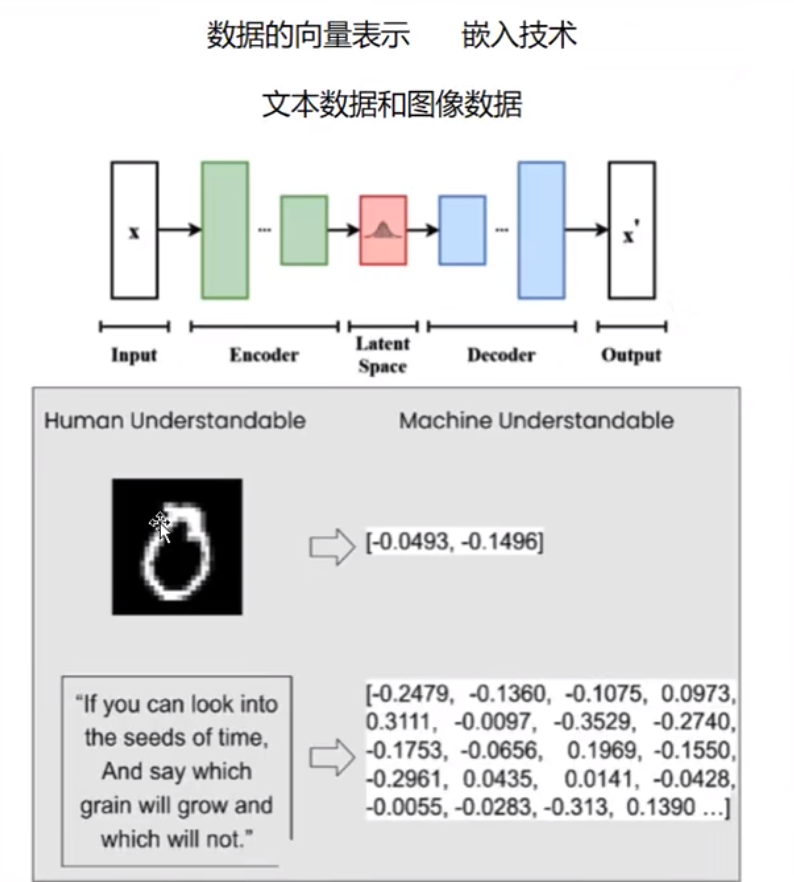
- 索引涉及将数据转换为适合LLM消费的格式。文档被分成可管理的片段–如句子或段落–并转换为矢量表示。
- 有效的分块策略各不相同,包括统一的块大小,按文档节分块,或两者兼而有之。优化块大小有助于平衡检索精度和存储成本。
搜索和检索
- 矢量检索:将文本和文档转换为矢量。系统检索向量与查询向量相似的文档。
- 混合检索:将矢量搜索与传统的基于关键字的方法和语义搜索相结合,可以提高检索的准确性。
- 图形数据库:对于某些人来说,图形数据库用于识别相关性并更有效地检索相关文档。
微调模型
- Finetuned LLMs:使用特定领域知识定制LLMs可以提高他们生成相关答案的能力。例如,以医疗保健为重点的LLM在医疗环境中表现更好。
提示工程
- 提示提示:使用较小的模型或提示摘要技术简化和细化提示可以增强模型性能。
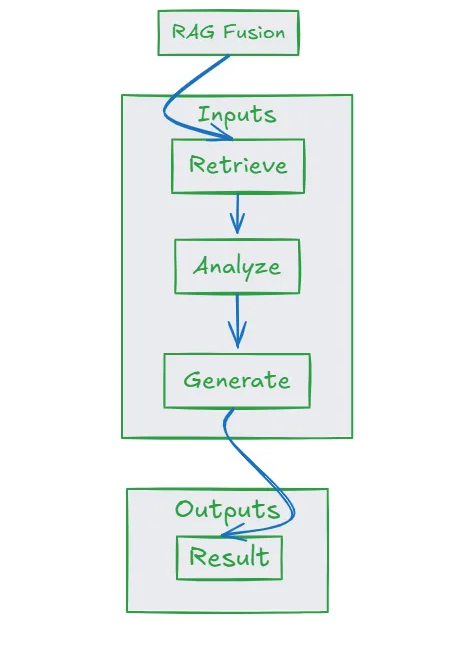
- RAG Fusion:这种技术涉及从初始查询生成多个提示,每个提示突出显示查询的不同视角或方面。这些不同的提示丰富了上下文,提供了更全面的理解,从而得到更好的答案。
动态和高级嵌入
-
微调嵌入模型:通过使用在特定领域数据上进行过训练的嵌入模型来提升搜索效率。
-
动态嵌入:利用BERT等预训练模型生成上下文相关的词向量表示,使得每个单词的嵌入能够根据其周围的词语进行调整。
上下文管理
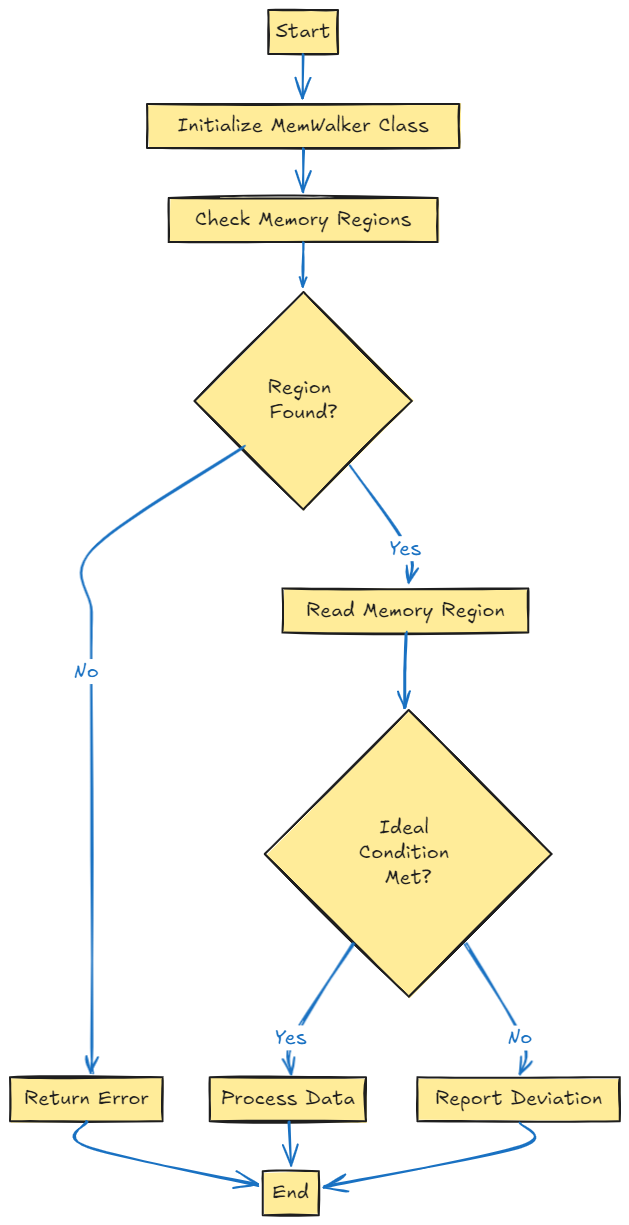
- MemWalker:这是一种用于跟踪和维护对话历史的技术,有助于更好地理解上下文,从而提供更准确和连贯的响应。
组织上下文为摘要树的方法
-
摘要树构建:采用一种方法将上下文信息组织成为摘要树结构,便于LLM(大型语言模型)能够有效地遍历并选取关键信息。
-
摘要嵌入:通过创建文档摘要并将其矢量化来简化检索过程,提升信息处理效率。
-
父文档检索:当检索到特定的子文档时,同时考虑其所属的父文档以提供更全面的上下文背景。
处理检索挑战
-
文档摘要:对检索到的文档内容进行精炼摘要,旨在减少处理成本并降低出现幻觉的风险。
-
解决"迷失在中间"综合症:针对这一问题提出有效策略,确保在处理大量信息时仍能保持准确性和连贯性。
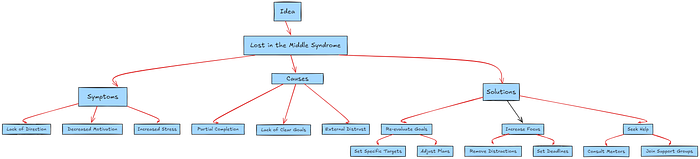
- 为了缓解大型语言模型(LLM)在处理大型上下文时倾向于关注开始和结束部分的问题,我们可以采取一些策略来重新组织数据。
多样性和质量控制
-
多样性排名:通过评估文档内容的多样性来进行排序,确保能够提供平衡且全面的回答。
-
查询路由:依据查询涉及的数据类型和格式将其导向最适合的数据库,从而提升检索效率。
创新方法
- 假设文档检索:基于上下文信息生成假设性的文档,并检索与之相似的向量数据,以此扩大搜索范围。
- Retrieve-then-Read vs. Retrieve-then-Generate-and-Read:选择先检索后阅读的方式,或是结合生成后再阅读的方法来构建更加清晰的上下文环境;通过调整模型权重来优化检索和生成答案的过程。
向量相似度搜索
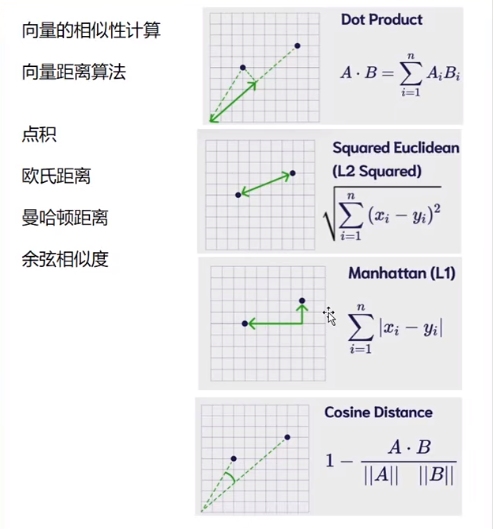
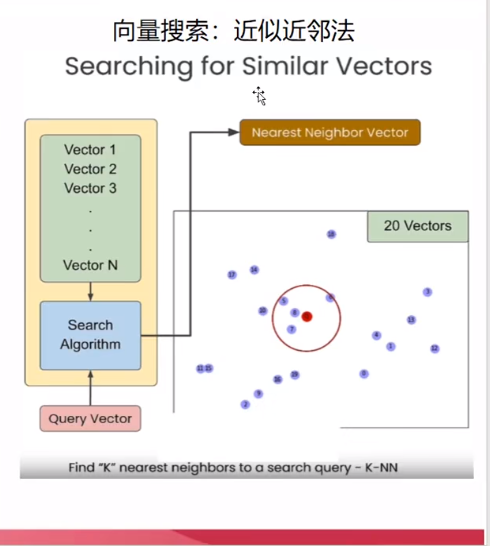
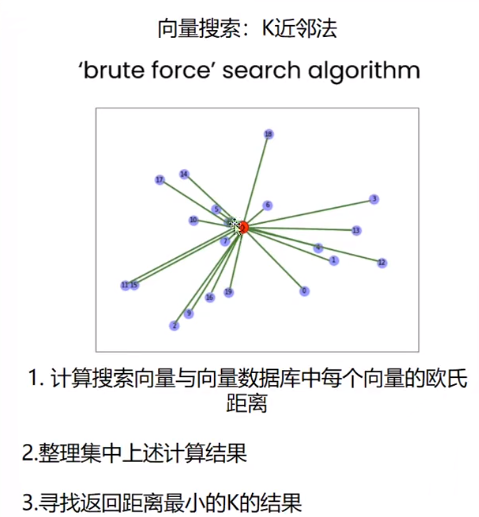

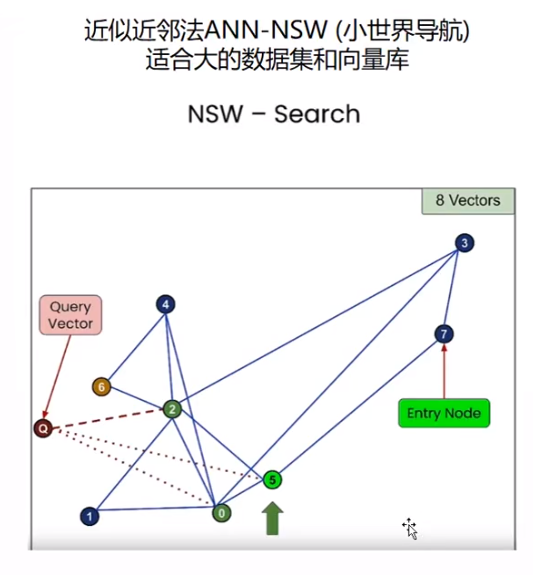
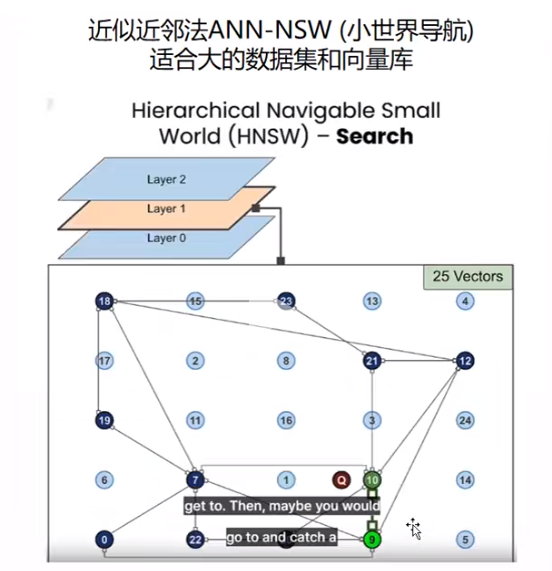
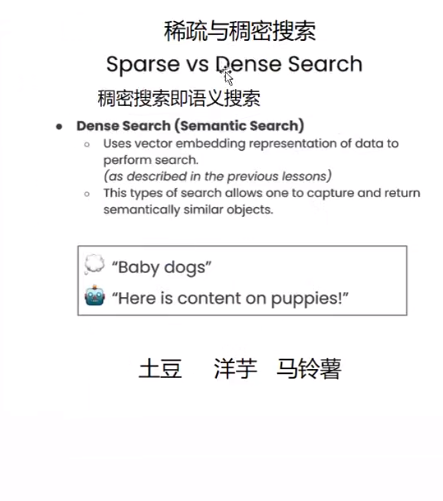
结论
RAG系统(Retrieval-Augmented Generation System)的发展前景充满无限可能,这些创新技术旨在改进搜索和检索流程。随着该领域的不断进步,采用上述最佳实践和技术融合,可以显著提升RAG系统的性能及答案的相关性。研究人员和行业专家应当持续关注这些进展,以便有效利用最新的方法和技术,确保其搜索和生成能力始终保持领先水平。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240801/%E4%BD%BF%E7%94%A8%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90RAG%E7%B3%BB%E7%BB%9F%E6%8F%90%E5%8D%87%E6%90%9C%E7%B4%A2%E6%8A%80%E6%9C%AF%E5%92%8C%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


