Zilliz:超越Milvus的知识铺 --知识铺
向量数据库的崛起与Milvus的优势
在人工智能和大模型技术迅猛发展的今天,向量数据库应运而生,成为处理高维数据的关键技术。以下是对向量数据库核心观点的梳理和Milvus的详细介绍。
一、向量数据库的市场前景
-
头部公有云厂商的商用计划 今明两年,头部公有云厂商将正式商用自己的向量数据库产品。
-
市场需求的持续增长 随着技术的发展,向量数据库的需求将持续增长,竞争也将随之加剧。但市场足够大,足以让所有参与者分享到一杯羹。
-
Milvus的市场地位 尽管云厂商可能会吸引一部分Milvus的客户,但Milvus凭借其知名度和成熟度,仍将保持领先地位。
二、为什么需要向量数据库
高维向量数据支持大模型处理的数据通常是高维的,如图像、文本和语音等。这些数据需要转换为高维向量,以便在模型中进行计算和表示。向量数据库针对这类数据进行了优化,提供了更高效的存储和检索功能。
相似性搜索能力向量数据库通过计算向量之间的距离,如欧氏距离或余弦相似度,实现快速的相似性搜索,这是传统数据库难以实现的。
高效的索引结构向量数据库采用特殊的索引结构,如k-d树、球体k树等,以实现快速的相似性搜索,提高查询性能。
模型微调和迁移学习能力向量数据库支持大模型进行更高效的模型微调和迁移学习,通过存储训练数据和知识库,加快模型更新和知识迁移。
存储优化向量数据库采用高效的数据结构和压缩算法,降低存储空间需求,提高存储效率。
三、Milvus的介绍
Milvus是由Zilliz公司开发的一款开源向量数据库,专为存储、索引和管理由深度学习和其他机器学习模型生成的海量向量设计。Milvus自2019年开源以来,已经获得了全球1000多家企业用户的信任。
Milvus的开源历程Milvus最初由Zilliz公司孵化,并作为项目贡献给LF AI & Data基金会。2021年6月,Milvus正式毕业,成为向量数据库领域的领导者。
Milvus 2.0的特点Milvus 2.0是一款云原生向量数据库,采用存储与计算分离的架构设计,所有组件均为无状态组件,增强了系统的弹性和灵活性。系统分为四个层面,但具体层面未在原文中详述。
结语
向量数据库以其在高维数据处理、相似性搜索、模型微调和存储优化方面的优势,成为大模型技术发展中不可或缺的一部分。Milvus作为这一领域的佼佼者,将继续引领向量数据库的创新和发展。

系统架构概览
接入层(Access Layer)接入层是系统的门面,由一系列无状态的代理(proxy)组成。它对外提供用户连接的端点(endpoint),并负责验证客户端的请求,同时合并并返回结果。
协调服务(Coordinator Service)协调服务是系统的中枢,其任务是分配任务给执行节点。它包含四种不同的角色:
- root coord:负责总体任务分配和协调。
- data coord:处理与数据相关的任务分配。
- query coord:负责查询相关的任务。
- index coord:处理索引相关的任务。
执行节点(Worker Node)执行节点是系统的执行力量,负责完成由协调服务下发的指令以及代理(proxy)发起的数据操作语言(DML)命令。执行节点分为三种角色:
- data node:处理数据存储和检索任务。
- query node:执行查询操作。
- index node:负责索引构建和维护。
存储服务(Storage)存储服务是系统的基础架构,负责 Milvus 数据的持久化存储。它由三个主要部分组成:
- 元数据存储(meta store):存储系统的元数据。
- 消息存储(log broker):负责消息的传递和记录。
- 对象存储(object storage):存储实际的数据对象。
Zilliz CloudZilliz Cloud 是由 Milvus 原厂精心打造的全托管 SaaS 及 PaaS 向量数据库服务。它提供了深度优化和即用的 Milvus 体验,使用户能够轻松构建并部署十亿级规模的向量数据库和向量搜索服务。Zilliz Cloud 由全球顶尖的向量数据库团队提供专业的运维、优化和综合支持服务。
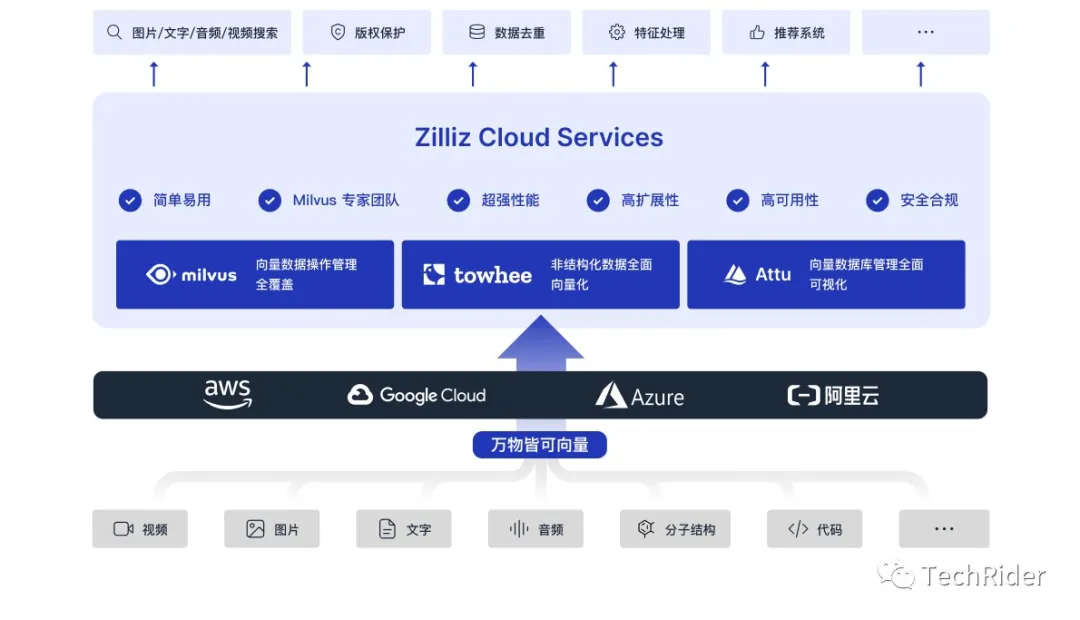
Zilliz Cloud在全球拥有7个公有云合作伙伴,其中NVIDIA在其官方大会上的提及帮助Zilliz Cloud正式出圈。

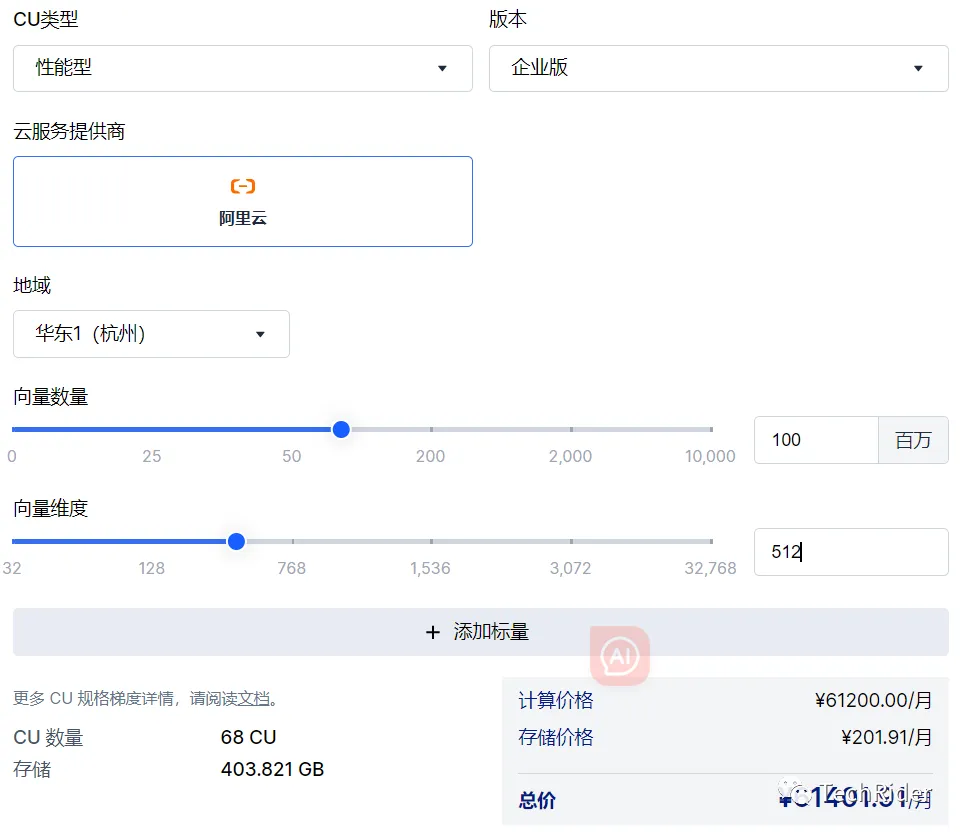
在国内,Zilliz Cloud已经上架阿里云,定价逻辑是按照向量数据和向量维度进行收费。
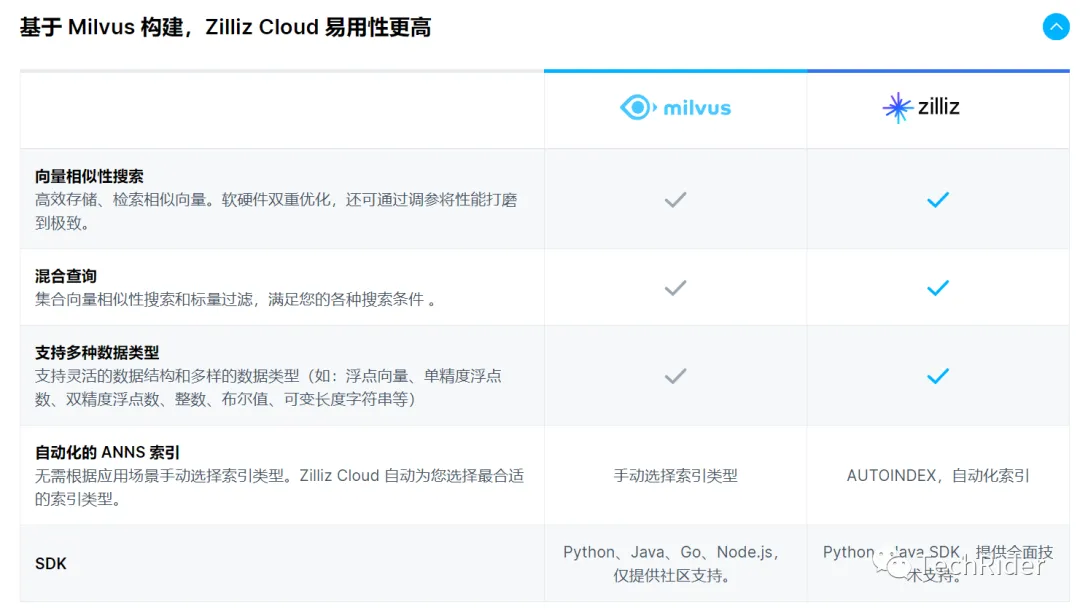
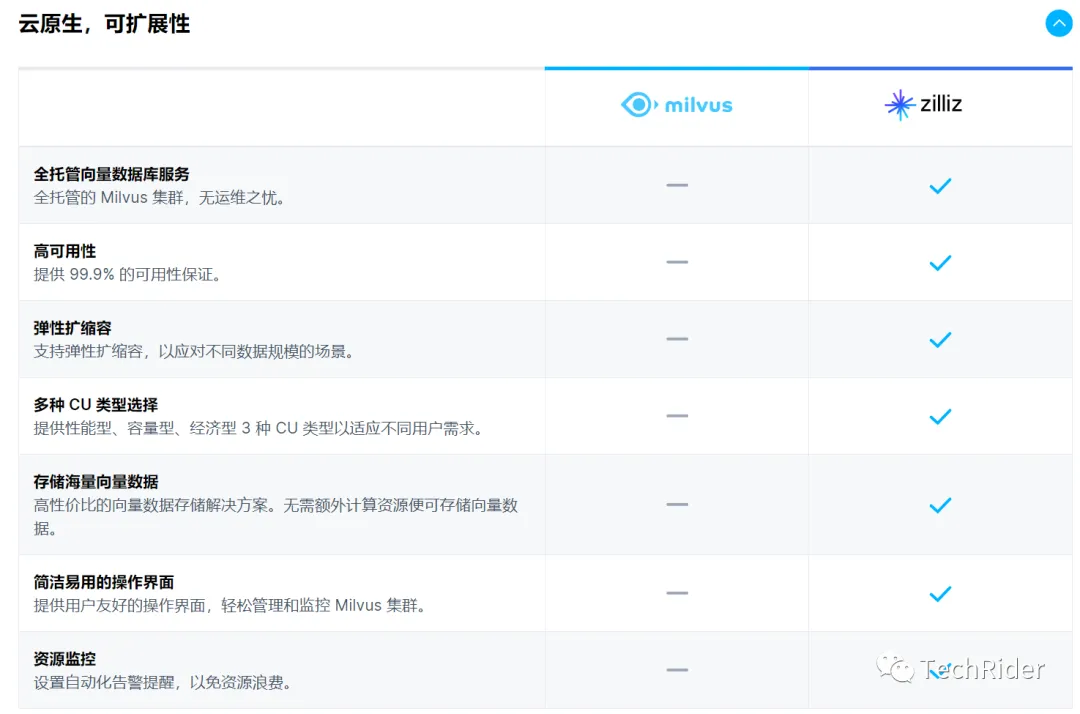
差异
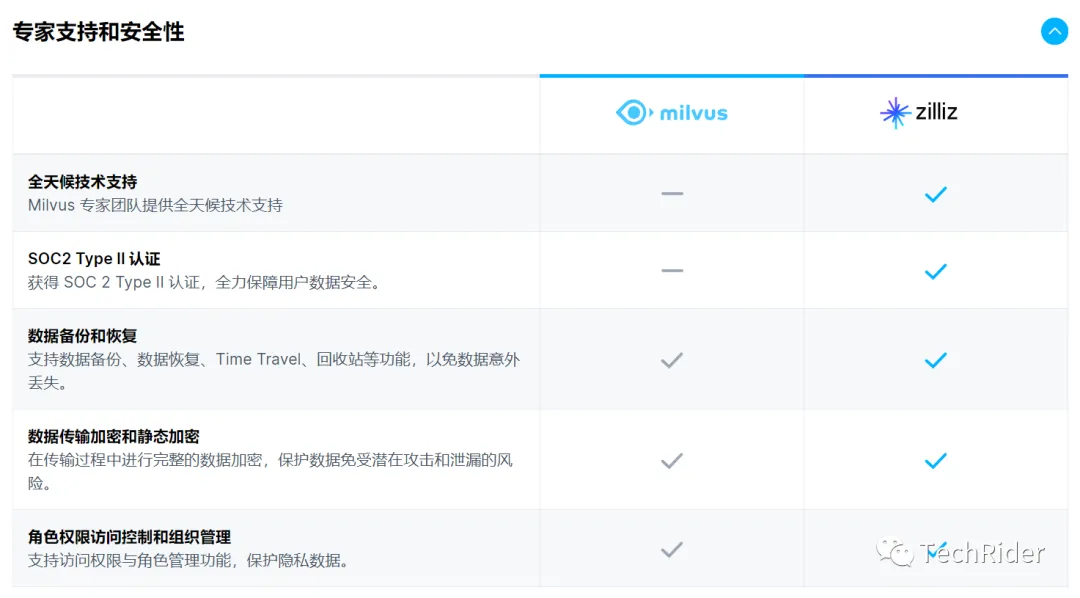
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Zilliz%E8%B6%85%E8%B6%8AMilvus%E7%9A%84%E7%9F%A5%E8%AF%86%E9%93%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


