Milvus 实战:BERT 与 Milvus 构建文本搜索引擎 --知识铺
谷歌BERT模型及其在NLP领域的影响
BERT模型由谷歌开发,自推出以来,在自然语言处理(NLP)领域产生了深远影响。它是一个先进的语言表示模型,具备广泛的应用潜力。
项目概述本文项目旨在结合Milvus和BERT模型,构建一个高效的文本搜索引擎。通过BERT模型将文本数据转换为向量,利用Milvus的向量相似度搜索能力,实现快速的相似文本检索。
关键技术
MilvusMilvus是一个开源的向量相似度搜索引擎,基于Faiss、NMSLIB、Annoy等向量索引库构建。它具有以下特点:
- 功能强大:集成多种向量索引库,提供统一的API接口。
- 稳定可靠:经过实践检验,确保搜索的稳定性和可靠性。
- 易于使用:简化用户操作,降低技术门槛。
- 扩展性:支持集群分片,适应大规模数据和查询需求。
- 动态扩容:支持读写分离和水平扩展,适应数据增长。 Milvus的这些特性使其成为构建文本搜索引擎的理想选择,特别是在需要处理大规模数据和复杂查询的场景中。
BERT模型BERT模型通过深度学习技术,能够理解语言的上下文信息,生成高质量的文本向量表示。这些向量可以作为Milvus搜索的输入,以实现文本的相似性匹配。
结合应用将BERT模型与Milvus结合,可以创建一个强大的文本搜索引擎。BERT负责将文本转换为向量,而Milvus则利用这些向量进行高效的相似度搜索。这种结合利用了BERT在语言理解方面的优势和Milvus在向量搜索方面的高效性,为用户提供了一个快速、准确的文本检索解决方案。
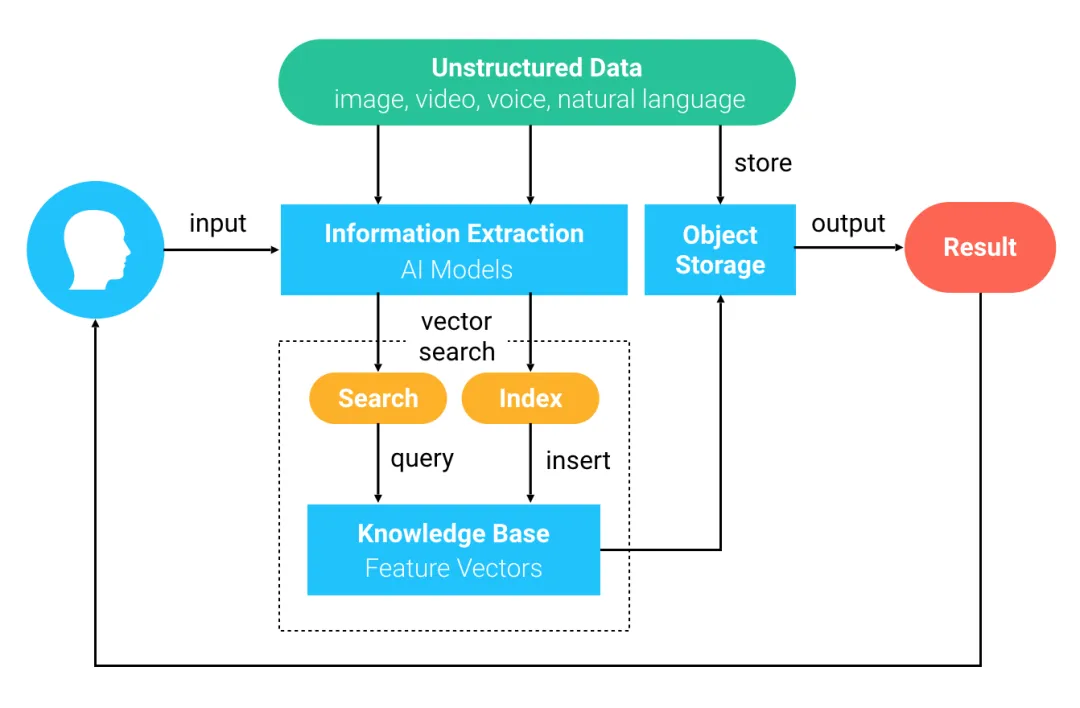
BERT 模型概述
BERT,即双向编码表征模型(Bidirectional Encoder Representations from Transformers),是由 Google 发布的一种先进的语言表达模型。它在自然语言处理领域具有显著的优势,主要体现在以下两个方面:
简化网络结构BERT 模型采用了基于注意力机制的全连接网络,取代了传统的卷积神经网络(CNN)和循环神经网络(RNN)。这种设计不仅缩短了模型的训练时间,还显著提高了模型的性能。
全面捕捉上下文BERT 是首个能够真正理解上下文语义信息的预训练语言模型。它利用了 Transformer 框架,该框架能够深入捕捉语句中的双向关系,从而实现对语义信息的全面理解。
模型特点
- 注意力机制:BERT 通过注意力机制,使得模型能够关注输入序列中的不同部分,以更好地理解语言的上下文。
- Transformer 框架:作为 BERT 的核心算法框架,Transformer 允许模型在处理语言时考虑整个序列的信息,而不仅仅是局部信息。
应用场景BERT 模型因其强大的语言理解能力,被广泛应用于各种自然语言处理任务,包括但不限于文本分类、情感分析、问答系统等。
结论BERT 模型的推出,为自然语言处理领域带来了革命性的进步,其双向上下文理解能力和简化的网络结构,使其成为当前最前沿的语言模型之一。
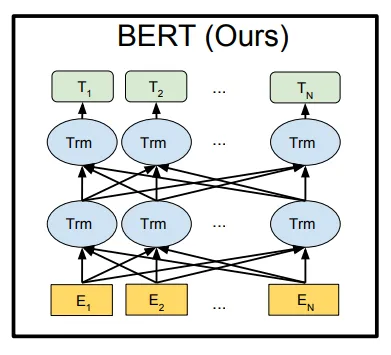
Google 提供了一些预先训练的模型,其中最基本的两个模型是BERT-base 模型和 BERT-large 模型。具体参数如下表所示:
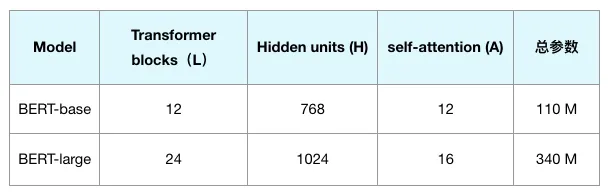
BERT模型选择与参数对比
BERT模型分为两种规模:基础版(BERT-base)和增强版(BERT-large)。在参数总量和网络层数上,BERT-large模型具有更多的参数,同时占用更多的计算机内存。基于资源和性能的考量,本项目选择了BERT-base模型来执行文本数据的向量转换。在BERT模型中,层数(Transformer块数)用L表示,隐藏尺寸用H表示,自注意力头数用A表示。
数据来源
本项目所使用的新闻数据集由两部分组成:标题集和文本集,它们是一一对应的关系。这些数据存放在data目录下,且数据已经过预处理。数据集来源于和鲸社区提供的中文新闻数据集,包含近14万条数据。
系统架构
文本搜索引擎项目采用了Milvus作为其整体架构。具体的架构图示在文中未提供,但可以推断其设计用于优化搜索引擎的性能和效率。
请注意,以上内容是根据用户提供的原始信息重新编写的,以确保条理性和结构性,同时遵循了Markdown格式的要求。
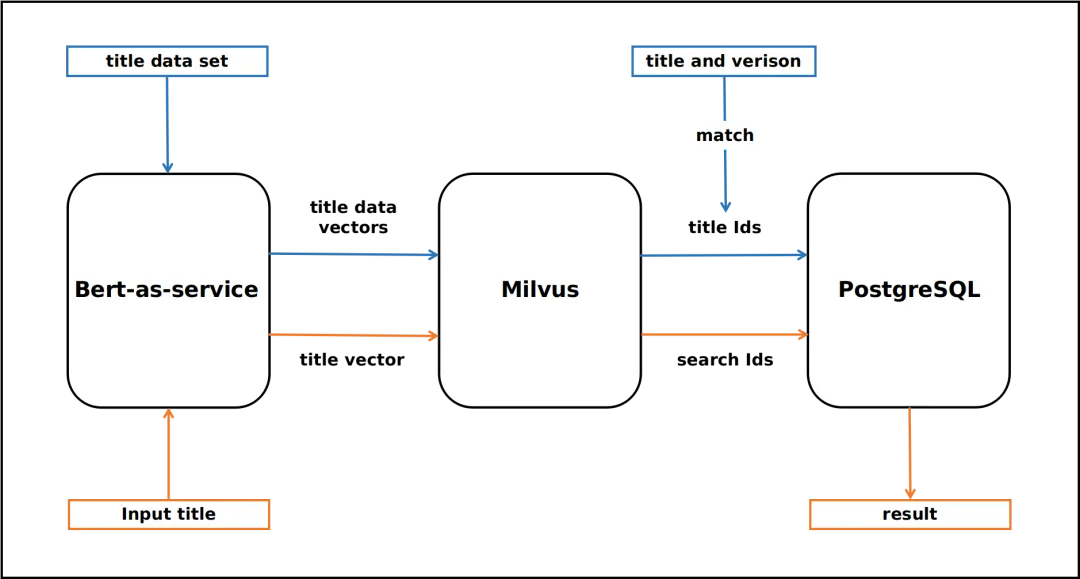
文本搜索引擎的构建与实现
概述本文介绍了使用开源的bert-as-service结合Milvus和PostgreSQL构建文本搜索引擎的过程。通过BERT模型将新闻标题转化为特征向量,并利用Milvus进行相似度检索,最终在PostgreSQL中存储和检索新闻标题及其文本。
步骤一:数据导入
- BERT模型应用:采用bert-as-service将新闻标题转换为728维的特征向量。
- Milvus库使用:将转换后的特征向量导入Milvus库,并建立索引。
步骤二:数据存储与索引
- Milvus索引建立:为特征向量分配ID,并建立索引以优化检索效率。
- PostgreSQL存储:将ID、新闻标题和文本存储于PostgreSQL数据库中,确保数据的持久化和可查询性。
步骤三:用户查询
- 用户输入:用户输入新闻标题,系统使用BERT模型转换为特征向量。
- Milvus检索:Milvus根据特征向量进行相似度检索,找到相似新闻标题的ID。
- PostgreSQL查询:根据检索到的ID,在PostgreSQL中查询对应的新闻标题和文本。
后续界面展示展示新闻文本搜索的实例,用户可以直观地看到搜索引擎的工作效果。
实现关键步骤以下是构建文本搜索引擎的关键步骤,具体操作可以参考GitHub项目。
安装Milvus
- 选择CPU或GPU版本,GPU版本提供更优的查询性能。
- 参考Milvus文档进行安装。
安装PostgreSQL
- PostgreSQL是一个功能强大的开源关系数据库系统。
- 以其高可靠性、稳定性和数据一致性而著称。
- 参考PostgreSQL官网进行安装。
安装bert-as-service
- bert-as-service用于将标题集转换为特征向量。
- 为Milvus的相似度检索提供数据基础。
- 参考bert-as-service的Github存储库了解安装细节。
注意事项
- 确保根据项目需求选择合适的软件版本和安装方法。
- 考虑到性能和稳定性,推荐使用GPU版本的Milvus。
结语通过上述步骤,可以构建一个高效、可靠的文本搜索引擎,为用户提供快速准确的新闻检索服务。
<section>#下载模型$ wget https://storage.googleapis.com/BERT_models/2018_11_03/chinese_L-12_H-768_A-12.zip#启动服务$ BERT-serving-start -model_dir chinese_L-12_H-768_A-12/ -num_worker=12 -max_seq_len=40</section>
4. 数据导入
在项目中的 Milvus-bert-server 文件的 main.py 文本数据导入脚本。用户只需要修改脚本中的标题集路径和文本集路径,即可运行脚本进行文本数据导入。
<section>python main.py --collection test11 --title data/title.txt --version data/version.txt --load</section>
5. 启动查询服务
在项目中启动查询服务,然后在浏览器中进行文本搜索,得到最终的文本搜索结果。
python app.py
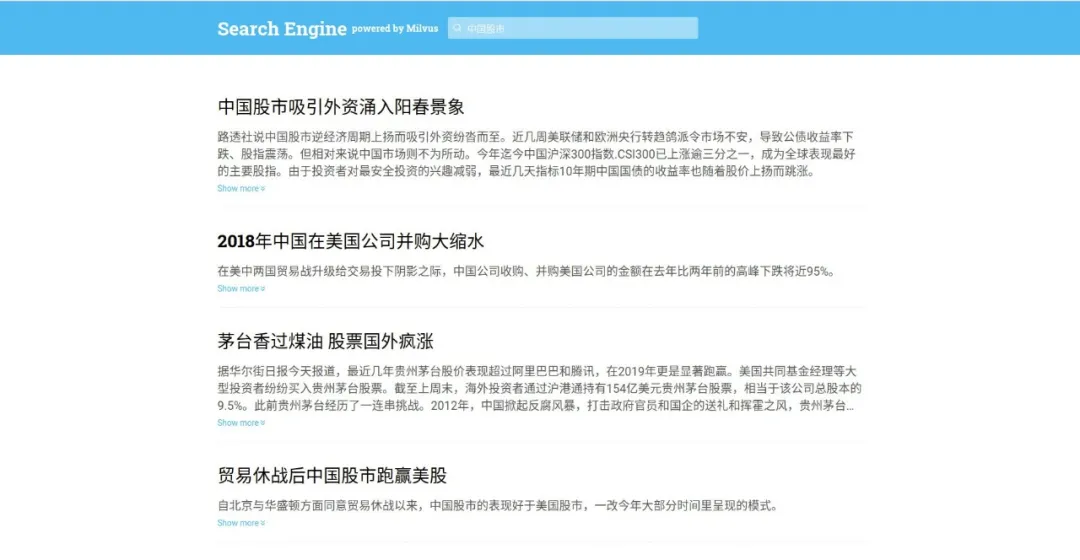
| 界面展示
打开 http://127.0.0.1:3001/search,下面是一个文本搜索的例子。首先进入搜索页面,输入“中国股市”,点击 Search 进行搜索。

可以得到与“中国股市”相关的新闻文本。比如图中所示的文本“中国股市吸引外资……”等。
深度学习与非结构化数据处理
随着人工智能技术的飞速发展,深度学习模型在处理非结构化数据方面展现出了巨大的潜力。这些数据包括图片、文本、视频和语音等多种形式。本文项目通过BERT模型将这些数据转化为特征向量,并利用Milvus进行向量计算,实现了对非结构化数据的高效分析与检索。
应用场景:文本搜索引擎
本文重点介绍了利用Milvus搭建的文本搜索引擎,这仅仅是Milvus在非结构化数据处理领域的一个应用实例。Milvus作为一个向量相似度检索引擎,能够与多种深度学习平台兼容,并且具备毫秒级响应时间处理十亿级向量的能力。
邀请与探索
我们鼓励用户导入自己的数据,构建个性化的文本搜索引擎。Milvus的灵活性和高效性使其成为探索AI应用的有力工具。此外,我们还提供了其他应用场景的参考,以帮助用户更深入地了解Milvus的应用潜力。
参考资料
有关Milvus的更多应用场景,请参阅Milvus 应用场景。
结语
Milvus作为一个强大的向量检索工具,为非结构化数据的处理和分析提供了新的可能性。我们期待与您一起探索AI技术的无限可能。
<section>
</section><p>参考资料:
</p>
<ol><li><p>和鲸社区的中文新闻数据集:https://www.kesci.com/home/dataset/5d8878638499bc002c1148f7/files</p></li><li><p>GitHub 项目:https://github.com/milvus-io/bootcamp/blob/0.10.0/solutions/Textsys/README.md</p></li><li><p>bert-as-service:https://github.com/hanxiao/BERT-as-service</p></li><li><p>Milvus 应用场景:https://milvus.io/cn/scenarios/</p></li></ol>
| 欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码
milvus.io | 官网
milvusio.slack.com | Slack 社区
zhihu.com/org/zilliz-11/columns | 知乎
zilliz.blog.csdn.net | CSDN 博客
space.bilibili.com/478166626 | Bilibili

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Milvus-%E5%AE%9E%E6%88%98BERT-%E4%B8%8E-Milvus-%E6%9E%84%E5%BB%BA%E6%96%87%E6%9C%AC%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


