Milvus 实战问答系统构建 --知识铺
Milvus 向量数据库
上一篇文章介绍了Milvus向量数据库安装部署,这次我们来介绍一下Milvus的应用实例。

Milvus是一款强大的向量搜索引擎,它通过相似性搜索的特性,可以广泛应用于多个领域。以下是Milvus的一些主要应用场景:
-
图像相似性搜索:在庞大的图像数据库中,快速检索出与查询图像最为相似的图片。
-
视频相似度搜索:将视频的关键帧转化为向量,通过Milvus实现对数十亿视频的实时搜索与推荐。
-
音频相似度搜索:快速检索海量音频数据中的相似声音,包括语音、音乐和音效。
-
推荐系统:根据用户的行为和需求,智能推荐信息或产品。
-
问答系统:构建交互式的数字问答助手,自动回答用户的问题。
-
DNA序列分类:通过比较DNA序列的相似性,迅速准确地进行基因分类。
-
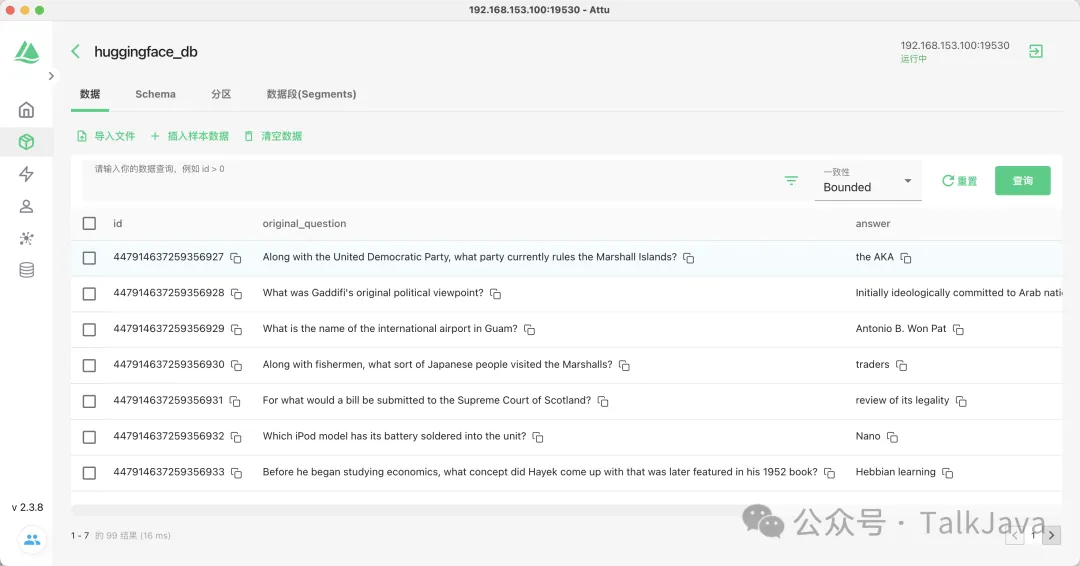
文本搜索引擎:通过关键字与文本数据库的匹配,帮助用户找到所需的信息。 特别地,Milvus与Hugging Face的结合,为问答系统(Question-Answering)提供了一种新的解决方案。Hugging Face是一个开源的NLP平台,拥有大量的预训练模型和数据集。本次结合使用的模型是Bert-base-uncased,它是一个广泛使用的预训练模型,适用于多种NLP任务。 模型链接:Bert-Base-Uncased 请注意,模型链接中的’MASK’是一个占位符,用于模型的填充任务。
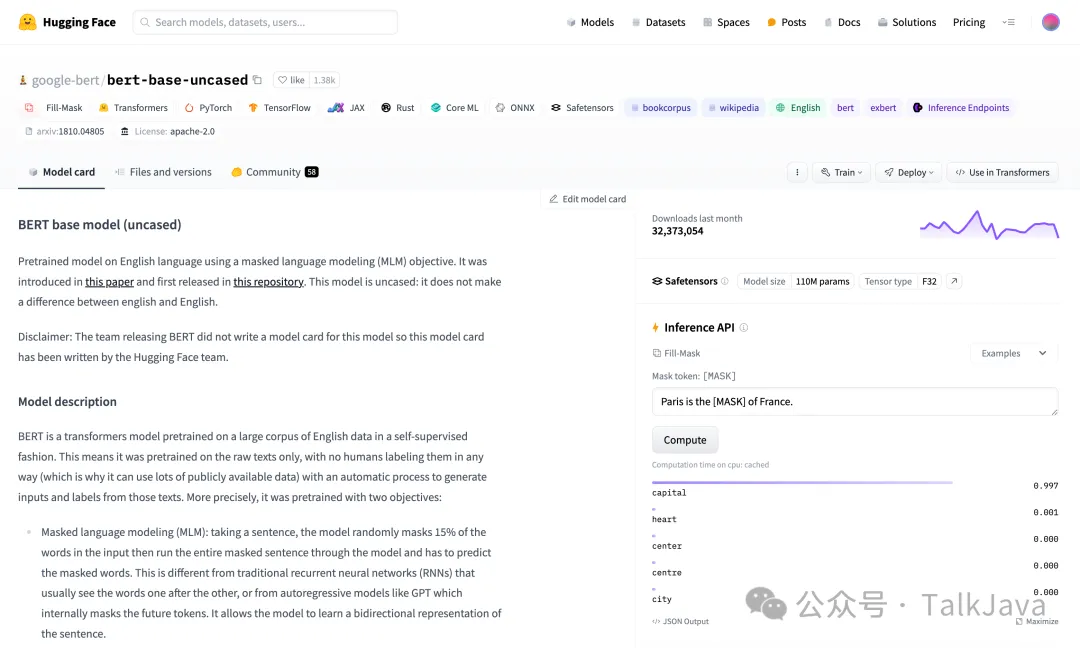
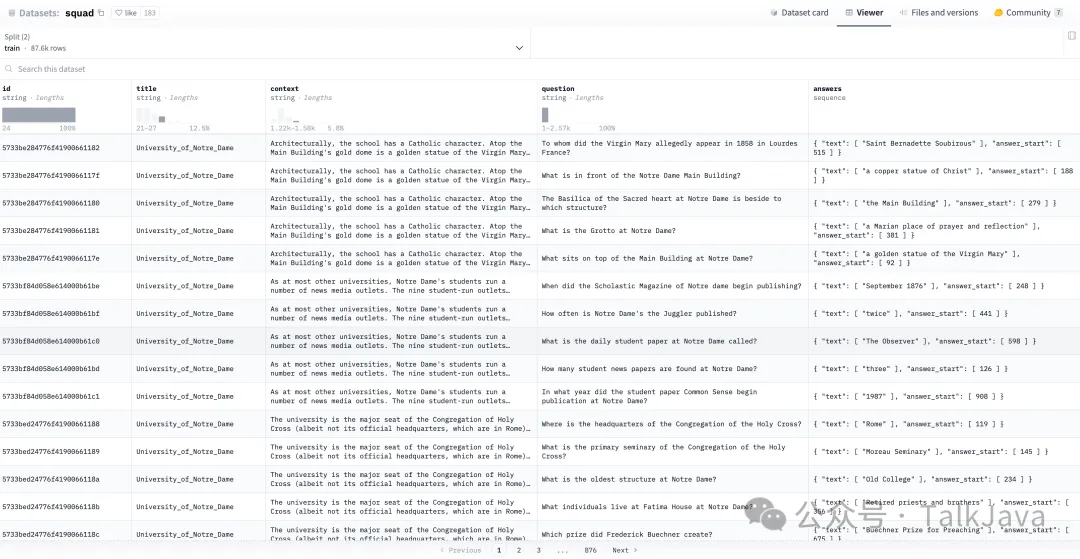
数据集:
https://huggingface.co/datasets/squad
0. 准备工作
环境准备,下载依赖:
pip install transformers datasets pymilvus torch
1. 创建收藏夹
首先本地需要启动Milvus:

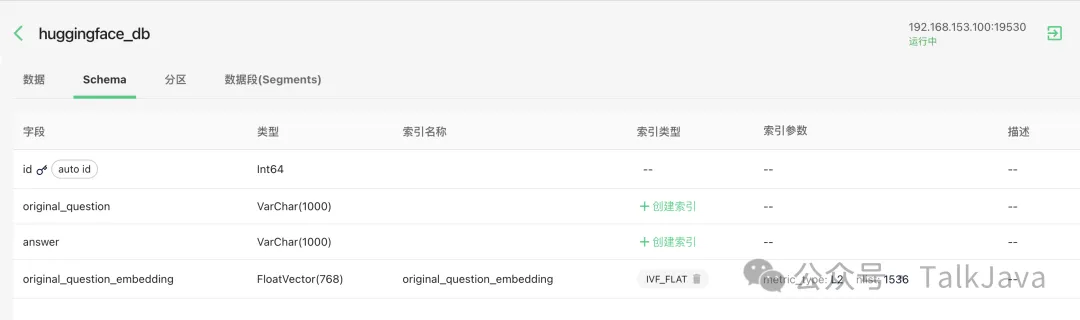
在Milvus创建Collection,并创建index:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1536}
}
collection.create_index(field_name="original_question_embedding", index_params=index_params)
print("Create index done.")
2. 插入数据
我们创建了Collection之后,就要开始插入数据了。
-
1. 将Dataset的数据进行分词处理
-
2. 将数据转化为向量
-
3. 将问题、问题的向量以及问题的答案插入到Milvus
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
data_dataset = load_dataset(DATASET, split='all')
data_dataset = data_dataset.train_test_split(test_size=INSERT_RATIO, seed=42)['test']
data_dataset = data_dataset.map(lambda val: {'answer': val['answers']['text'][0]}, remove_columns=['answers'])
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens = True, truncation = True, padding = "max_length", return_attention_mask = True, return_tensors = "pt")
batch['input_ids'] = results['input_ids']
batch['token_type_ids'] = results['token_type_ids']
batch['attention_mask'] = results['attention_mask']
return batch
data_dataset = data_dataset.map(tokenize_question, batch_size=TOKENIZATION_BATCH_SIZE, batched=True)
data_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True)
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
return batch
data_dataset = data_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
collection.load()
def insert_function(batch):
insertable = [
batch['question'],
[x[:995] + '...' if len(x) > 999 else x for x in batch['answer']],
batch['question_embedding'].tolist()
]
collection.insert(insertable)
data_dataset.map(insert_function, batched=True, batch_size=64)
collection.flush()
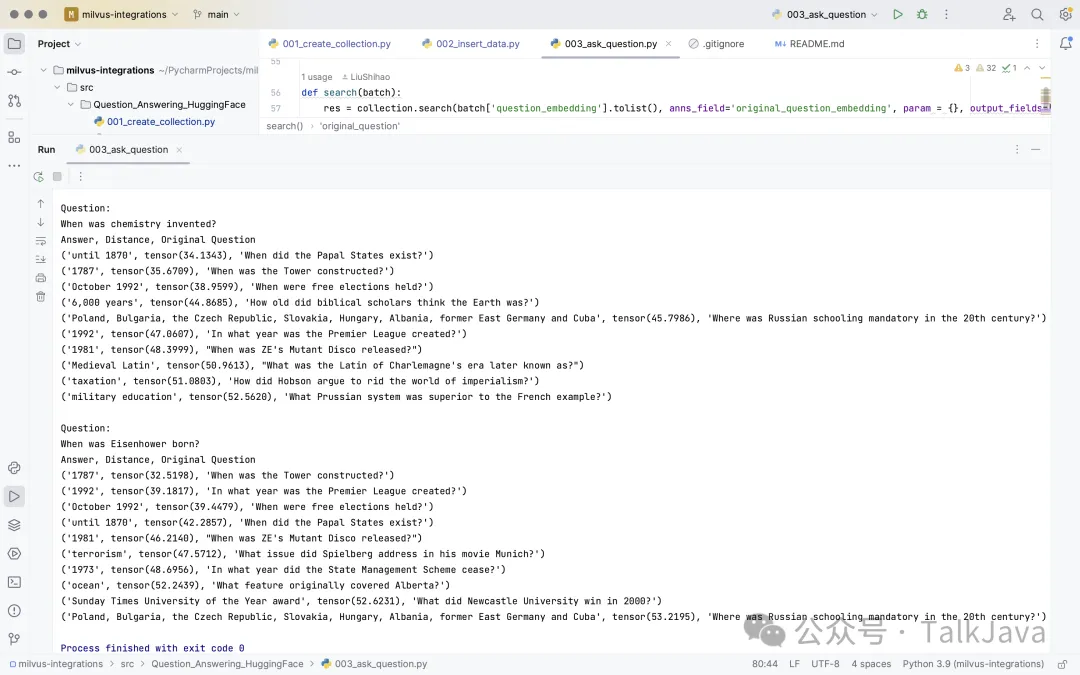
3. 提出问题
所有的数据插入到Milvus向量数据库后,就可以提出问题并查看相似度最高的答案。
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
collection.load()
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens = True, truncation = True, padding = "max_length", return_attention_mask = True, return_tensors = "pt")
batch['input_ids'] = results['input_ids']
batch['token_type_ids'] = results['token_type_ids']
batch['attention_mask'] = results['attention_mask']
return batch
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
return batch
questions = {'question':['When was chemistry invented?', 'When was Eisenhower born?']}
question_dataset = Dataset.from_dict(questions)
question_dataset = question_dataset.map(tokenize_question, batched = True, batch_size=TOKENIZATION_BATCH_SIZE)
question_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True)
question_dataset = question_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)
def search(batch):
res = collection.search(batch['question_embedding'].tolist(), anns_field='original_question_embedding', param = {}, output_fields=['answer', 'original_question'], limit = LIMIT)
overall_id = []
overall_distance = []
overall_answer = []
overall_original_question = []
for hits in res:
ids = []
distance = []
answer = []
original_question = []
for hit in hits:
ids.append(hit.id)
distance.append(hit.distance)
answer.append(hit.entity.get('answer'))
original_question.append(hit.entity.get('original_question'))
overall_id.append(ids)
overall_distance.append(distance)
overall_answer.append(answer)
overall_original_question.append(original_question)
return {
'id': overall_id,
'distance': overall_distance,
'answer': overall_answer,
'original_question': overall_original_question
}
question_dataset = question_dataset.map(search, batched=True, batch_size = 1)
for x in question_dataset:
print()
print('Question:')
print(x['question'])
print('Answer, Distance, Original Question')
for x in zip(x['answer'], x['distance'], x['original_question']):
print(x)
Question:
问答系统实现与模型整合
本文档介绍了如何实现一个简单的问答系统,并探讨了与不同AI模型的整合方法。以下是整合步骤和相关资源的详细介绍。
问答系统的实现
问答系统的核心是理解用户的问题并给出准确的回答。这通常涉及到自然语言处理技术。
与Huggingface模型的整合Huggingface提供了多种预训练模型,可以用于问答系统,以增强对语言的理解能力。
与OpenAI接口的整合除了Huggingface,还可以通过OpenAI的API接口实现更高级的功能,如图像和音频搜索。
功能拓展
问答系统不仅可以回答文本问题,还可以通过整合其他模型来实现图像和音频的搜索功能。
图像搜索利用图像识别技术,系统可以识别图像内容并根据内容回答问题。
音频搜索音频搜索功能允许系统处理语音输入,并根据语音内容提供答案。
项目代码
项目的代码已经上传至GitHub,欢迎访问以下链接查看和使用: GitHub项目链接
社区交流
如果您在使用过程中遇到任何问题,或者有宝贵的经验想要分享,欢迎在评论区进行交流。您的反馈对我们至关重要。
支持与鼓励
如果您觉得本文档对您有所帮助,请不要吝啬您的点赞、评论和分享。您的支持是我们继续创作的最大动力。
注意:以上内容为根据原始信息重新编写,并使用Markdown格式进行排版。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Milvus-%E5%AE%9E%E6%88%98%E9%97%AE%E7%AD%94%E7%B3%BB%E7%BB%9F%E6%9E%84%E5%BB%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


