Milvus 向量数据库入门知识 --知识铺
Milvus 简介与使用指南
1. Milvus 是什么?
Milvus 是一个由深度学习社区于2019年创建的向量数据库。它主要用于存储、索引和管理由深度神经网络和其他机器学习模型生成的大量嵌入向量。Milvus 专为处理输入向量的查询而设计,能够高效地索引高达万亿级别的向量。与传统的关系数据库不同,Milvus 专注于处理非结构化数据转换而来的嵌入向量。
2. Milvus 的安装方法Milvus 的安装过程相对简单,通常包括以下几个步骤:
- 确保系统满足 Milvus 的运行要求。
- 从 Milvus 官网下载相应版本的安装包。
- 根据官方文档的指导,完成安装和配置。
3. 使用 Python 运行 Milvus使用 Python 与 Milvus 交互,首先需要安装 Milvus 的 Python SDK。以下是使用 Python 运行 Milvus 的基本步骤:
- 安装 Milvus Python SDK。
- 连接到 Milvus 服务器。
- 进行数据的插入、查询等操作。
4. 非结构化数据与嵌入向量随着互联网的发展,非结构化数据变得越来越普遍,例如电子邮件、论文、物联网传感器数据等。Milvus 将这些非结构化数据转换成向量,并通过计算向量之间的相似度来分析它们之间的相关性。如果两个嵌入向量相似度高,表明原始数据源也具有较高的相似性。
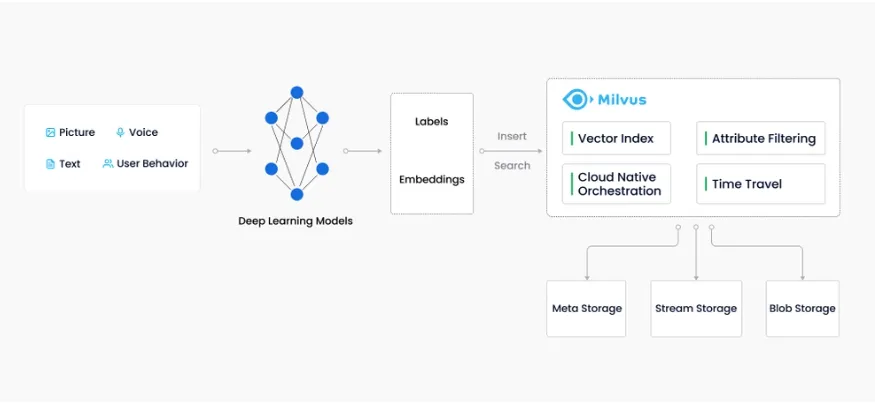
非结构化数据与Milvus概述
主要概念
非结构化数据非结构化数据包括图像、视频、音频和自然语言等,它们不遵循预定义的模型或组织方式。这类数据占据了全球数据的约80%,可通过人工智能(AI)和机器学习(ML)模型转换成向量。
嵌入向量嵌入向量是将非结构化数据的特征抽象化,例如电子邮件、物联网传感器数据、Instagram照片、蛋白质结构等。数学上,它们是浮点数或二进制数的数组。现代嵌入技术用于将非结构化数据转换为嵌入向量。
向量相似性搜索向量相似性搜索是将一个向量与数据库进行比较,以找到与查询向量最相似的向量的过程。近似最近邻(ANN)搜索算法用于加速搜索过程。如果两个嵌入向量非常相似,意味着原始数据源也很相似。
为什么选择Milvus?
Milvus在以下方面表现出优势:
- 高性能处理大规模数据集的向量搜索。
- 开发者友好的社区,提供多语言支持和工具链。
- 云可扩展性和高可靠性,即使在中断事件中。
- 通过结合标量过滤与向量相似性搜索,实现混合搜索。
支持的索引和度量标准
索引类型Milvus支持多种向量索引类型,主要使用近似最近邻搜索(ANNS):
- FLAT:适用于小型、百万级数据集的精确搜索。
- IVF_FLAT:基于量化的索引,平衡准确性和查询速度。
- IVF_SQ8:基于量化的索引,显著减少资源消耗。
- IVF_PQ:基于量化的索引,追求高查询速度。
- HNSW:基于图的索引,高搜索效率。
相似性度量Milvus使用相似性度量来测量向量之间的相似性,选择合适的度量可以提高分类和聚类性能:
- 欧几里得距离(L2):常用于计算机视觉。
- 内积(IP):常用于自然语言处理。
- 汉明距离(Hamming):常用于自然语言处理。
- 杰卡德距离(Jaccard):用于分子最近邻搜索。
应用程序示例
Milvus可以为多种应用程序添加最近邻搜索功能,例如:
- 图像相似搜索
- 视频相似搜索
- 音频相似搜索
- 推荐系统
- 问答系统
- DNA序列分类
- 文本搜索引擎
Milvus安装方法
Milvus支持多种安装方法,包括基于Docker Compose的安装。以下是安装步骤:
- 安装Docker。2. 安装Docker Compose。3. 安装Milvus。
Docker安装步骤
详细的安装指南请访问Milvus官方文档。
<pre data-block="true" data-editor="faj32" data-offset-key="fq19f-0-0"><p>sudo apt install -y docker.io # 安装Docker Engine</p></pre>
apt install直接安装docker, 使用 -y 参数来避免确认,实现自动化操作
<pre data-block="true" data-editor="faj32" data-offset-key="3ba6v-0-0"><p>sudo service docker start # 启动docker 服务
sudo usermod -aG docker ${USER} # 当前用户加入docker组</p></pre>
Docker 服务启动与用户权限配置指南
启动 Docker 服务
首先,我们需要启动 Docker 的后台服务。这可以通过执行以下命令来完成:
|
|
用户权限配置
接下来,为了安全地操作 Docker,我们需要将当前用户加入 Docker 用户组。这可以通过以下命令实现:
|
|
请注意,替换 当前用户名 为实际的用户名。执行此命令后,建议退出系统并重新登录,以确保用户组的变更生效。
验证 Docker 安装
为了验证 Docker 是否安装成功,我们可以使用以下命令来获取 Docker 客户端和服务器的版本信息:
|
|
这将输出 Docker 客户端和服务器各自的版本信息,帮助我们确认 Docker 的安装状态。
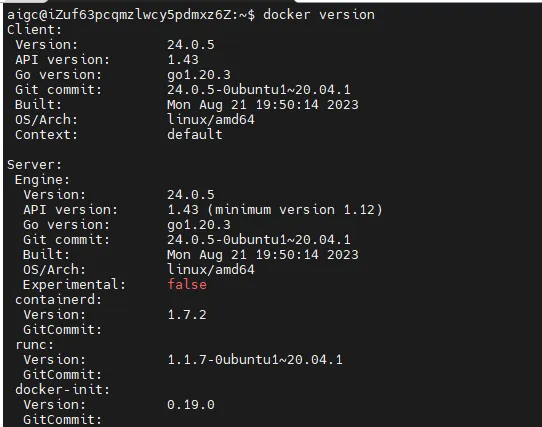
docker info 会显示当前 Docker 系统相关的信息,例如 CPU、内存、容器数量、镜像数量、容器运行时、存储文件系统等等.
Docker-Compose安装
按顺序运行以下命令
<pre data-block="true" data-editor="faj32" data-offset-key="90k8p-0-0"><p>sudo curl -SL https://github.com/docker/compose/releases/download/v2.23.3/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose</p></pre><pre data-block="true" data-editor="faj32" data-offset-key="24n4f-0-0"><p>sudo chmod +x /usr/local/bin/docker-compose</p></pre><pre data-block="true" data-editor="faj32" data-offset-key="evr0d-0-0"><p>sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose</p></pre>
安装完成之后,来看一下它的版本号,命令是 docker-compose version,用法和 docker version 是一样的:

Milvus安装
下载YAML文件
下载milvus-standalone-docker-compose.yml文件,并改名成docker-compose.yml
<pre data-block="true" data-editor="faj32" data-offset-key="b6knk-0-0"><p>wget https://github.com/milvus-io/milvus/releases/download/v2.3.4/milvus-standalone-docker-compose.yml -O docker-compose.yml</p></pre>
启动Milvus
在与 docker-compose. yml 文件相同的目录中,运行以下命令启动 Milvus:
<pre data-block="true" data-editor="faj32" data-offset-key="a3g78-0-0"><p>sudo docker-compose up -d</p></pre>

检查容器是否已经启动并运行。
sudo docker-compose ps

连接Milvus
验证 Milvus 服务器正在监听哪个本地端口。将容器名称替换为您自己的。
<pre data-block="true" data-editor="faj32" data-offset-key="vjts-0-0"><p>docker port milvus-standalone 19530/tcp</p></pre>

可以使用此命令返回的本地 IP 地址和端口号连接到 Milvus。
停止Milvus服务
<pre data-block="true" data-editor="faj32" data-offset-key="i7n7-0-0"><p>sudo docker-compose down</p></pre>

停止Milvus后,删除数据
<pre data-block="true" data-editor="faj32" data-offset-key="98kva-0-0"><p>sudo rm -rf volumes</p></pre>
如何使用Python运行Milvus?
准备工作:
-
Milvus: 上一步已经安装好
-
Python3:Linux默认已经安装好
-
PyMilvus:运行pip install pymilvus安装
下载示例代码
<pre data-block="true" data-editor="faj32" data-offset-key="a4486-0-0"><p>wget https://raw.githubusercontent.com/milvus-io/pymilvus/master/examples/hello_milvus.py</p></pre>

示例代码解释
导入 PyMilvus 包
<pre data-block="true" data-editor="faj32" data-offset-key="b6hpi-0-0"><p>from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)</p></pre>
连接服务
<pre data-block="true" data-editor="faj32" data-offset-key="58uml-0-0"><p>connections.connect("default", host="localhost", port="19530")</p></pre>
创建一个集合
<pre data-block="true" data-editor="faj32" data-offset-key="fe16s-0-0"><p>fields = [
FieldSchema(name="pk", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=8)
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
hello_milvus = Collection("hello_milvus", schema)
</p></pre>
在集合中插入向量
<pre data-block="true" data-editor="faj32" data-offset-key="1bp7o-0-0"><p>import random
entities = [
[i for i in range(3000)], # field pk
[float(random.randrange(-20, -10)) for _ in range(3000)], # field random
[[random.random() for _ in range(8)] for _ in range(3000)], # field embeddings
]
insert_result = hello_milvus.insert(entities)
hello_milvus.flush()
</p></pre>
在实体上生成索引
<pre data-block="true" data-editor="faj32" data-offset-key="9ikem-0-0"><p>index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
hello_milvus.create_index("embeddings", index)
</p></pre>
将集合加载到内存并执行向量相似性搜索
<pre data-block="true" data-editor="faj32" data-offset-key="88i95-0-0"><p>hello_milvus.load()
vectors_to_search = entities[-1][-2:]
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10},
}
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, output_fields=["random"])</p></pre>
执行向量查询
<pre data-block="true" data-editor="faj32" data-offset-key="u9k2-0-0"><p>result = hello_milvus.query(expr="random > -14", output_fields=["random", "embeddings"])</p></pre>
执行混合搜索
<pre data-block="true" data-editor="faj32" data-offset-key="f3fkh-0-0"><p>result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > -12", output_fields=["random"])</p></pre>
按照实体的主键删除实体
<pre data-block="true" data-editor="faj32" data-offset-key="3hd0h-0-0"><p>expr = f"pk in [{entities[0][0]}, {entities[0][1]}]" hello_milvus.delete(expr)</p></pre>
删除集合
<pre data-block="true" data-editor="faj32" data-offset-key="4ekiq-0-0"><p>utility.drop_collection("hello_milvus")</p></pre>
运行示例代码
<pre data-block="true" data-editor="faj32" data-offset-key="d5lfm-0-0"><p>python3 hello_milvus.py</p></pre>
返回的结果和查询延迟如下所示:
<pre data-block="true" data-editor="faj32" data-offset-key="ev7po-0-0"><p>=== start connecting to Milvus ===
Does collection hello_milvus exist in Milvus: False
=== Create collection `hello_milvus` ===
=== Start inserting entities ===
Number of entities in Milvus: 3000
=== Start Creating index IVF_FLAT ===
=== Start loading ===
=== Start searching based on vector similarity ===
hit: (distance: 0.0, id: 2998), random field: -11.0
hit: (distance: 0.11455299705266953, id: 1581), random field: -18.0
hit: (distance: 0.1232629269361496, id: 2647), random field: -13.0
hit: (distance: 0.0, id: 2999), random field: -11.0
hit: (distance: 0.10560893267393112, id: 2430), random field: -18.0
hit: (distance: 0.13938161730766296, id: 377), random field: -14.0
search latency = 0.2796s
=== Start querying with `random > -14` ===
query result:
-{'pk': 9, 'random': -13.0, 'embeddings': [0.298433, 0.931987, 0.949756, 0.598713, 0.290125, 0.094323, 0.064444, 0.306993]}
search latency = 0.2970s
=== Start hybrid searching with `random > -12` ===
hit: (distance: 0.0, id: 2998), random field: -11.0
hit: (distance: 0.15773043036460876, id: 472), random field: -11.0
hit: (distance: 0.3273330628871918, id: 2146), random field: -11.0
hit: (distance: 0.0, id: 2999), random field: -11.0
hit: (distance: 0.15844076871871948, id: 2218), random field: -11.0
hit: (distance: 0.1622171700000763, id: 1403), random field: -11.0
search latency = 0.3028s
=== Start deleting with expr `pk in [0, 1]` ===
query before delete by expr=`pk in [0, 1]` -> result:
-{'pk': 0, 'random': -18.0, 'embeddings': [0.142279, 0.414248, 0.378628, 0.971863, 0.535941, 0.107011, 0.207052, 0.98182]}
-{'pk': 1, 'random': -15.0, 'embeddings': [0.57512, 0.358512, 0.439131, 0.862369, 0.083284, 0.294493, 0.004961, 0.180082]}
query after delete by expr=`pk in [0, 1]` -> result: []
=== Drop collection `hello_milvus` ===</p></pre>
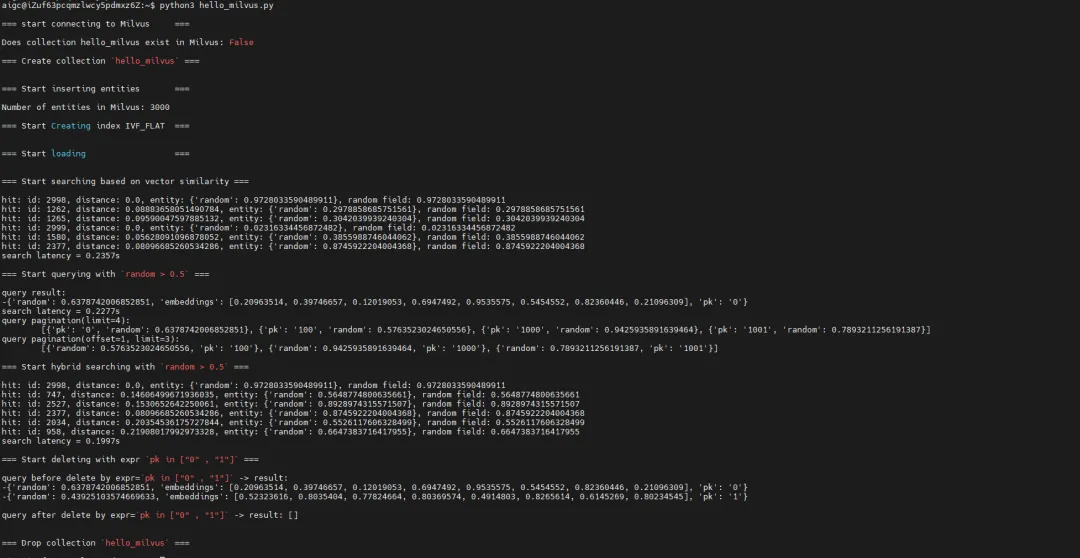
我们已经成功地安装了Milvus,并完成了首个向量相似性搜索任务。以下是对整个流程的梳理和总结:
安装MilvusMilvus是一款开源的向量数据库,它支持多种相似性搜索和数据分析功能。安装Milvus是实现向量搜索的第一步。
执行向量相似性搜索在安装完成后,我们进行了向量相似性搜索的实践。这一过程涉及到将查询向量与数据库中的向量集合进行比较,以找出最相似的结果。
相关阅读材料为了更深入地了解向量数据库和AI大模型项目,以下是一些推荐阅读材料:
-
文章详细介绍了Pinecone向量数据库的使用方法,包括如何创建索引、进行数据检索等。
-
该文章是AI大模型项目实战系列的开端,介绍了如何从零开始搭建一个基于LLM的对话机器人Tbot。
-
在v0.2版本中,Tbot通过结合个人知识库,提升了对话的质量和深度。
结构化内容以上内容以Markdown格式呈现,确保了条理性和结构性,便于读者理解和跟进。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Milvus-%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E5%85%A5%E9%97%A8%E7%9F%A5%E8%AF%86--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


