Milvus 向量数据库介绍及使用_java 如何使用向量数据库 milvus--知识铺
一、Milvus 介绍及安装
Milvus 于 2019 年创建,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的大量嵌入向量。它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
作为专门为处理输入向量查询而设计的数据库,它能够对万亿规模的向量进行索引。与现有的关系数据库主要处理遵循预定义模式的结构化数据不同,Milvus 是自下而上设计的,旨在处理从非结构化数据转换而来的嵌入向量。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
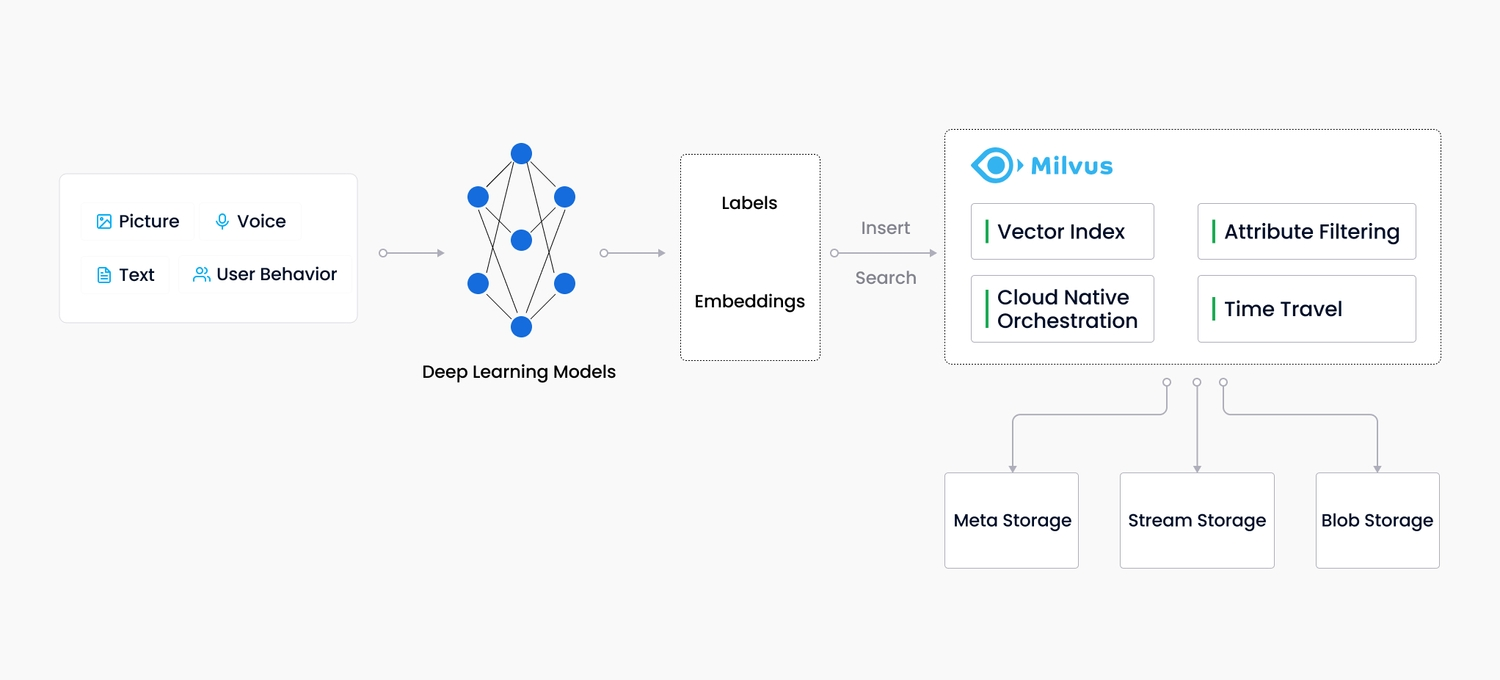
在 Milvus 中相关术语:
-
Collection: 包含一组
Entity,可以理解为关系型数据库中的表。 -
Entity: 包含一组
Field,可以理解为关系型数据库中的行。 -
Field:可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。可以理解为关系型数据库中的字段。
-
Partition:分区,针对
Collection数据分区存储多个部分,每个分区又可以包含多个段。 -
Segment:分段,一个
Partition可以包含多个Segment。一个Segment可以包含多个Entity。在搜索时,会搜索每个Segment合并后返回结果。 -
Sharding:分片,将数据分散到不同节点上,充分利用集群的并行计算能力进行写入,默认情况下,单个
Collection包含 2 个分片。 -
Index:索引,可以提高数据搜索的速度。但一个向量字段仅支持一种索引类型。
更多介绍可以参考官方文档:
官网地址:https://milvus.io/
Milvus Docker 单机部署
单机版 Milvus 主要包括三个组件:
- Milvus:负责提供系统的核心功能。
- etcd :元数据引擎,用于管理
Milvus内部组件的元数据访问和存储,例如:proxy、index node等。 - MinIO :存储引擎,负责维护
Milvus的数据持久化。
需要提前安装好 Docker、Docker-compose 环境。
下载 docker-compose.yml 文件:
|
|
启动 Milvus
|
|
查看启动服务:
|
|

安装可视化工具
|
|
|
|
启动
|
|
浏览器访问可视化页面:
http://ip:3000
二、Python Api 使用
Milvus 与 Python Api 版本对应如下:
| Milvus 版本 | 推荐的 PyMilvus 版本 |
|---|---|
| 1.0.* | 1.0.1 |
| 1.1.* | 1.1.2 |
| 2.0.x | 2.0.2 |
| 2.1.x | 2.1.3 |
| 2.2.x | 2.2.3 |
| 2.3.0 | 2.3.7 |
| 2.4.0-rc.1 | 2.4.0 |
这里安装 2.3.7 版本依赖,推荐 Python 版本 3.8 以上:
|
|
连接 Milvus :
|
|
如果有用户名密码,可以使用:
|
|
1. 创建 Collection
|
|
或者自定义设置字段:
|
|
其中向量索引方式有如下选择:
| 索引 | 说明 |
|---|---|
| FLAT | 准确率高, 适合数据量小,暴力求解相似。 |
| IVF-FLAT | 量化操作, 准确率和速度的平衡 |
| IVF | inverted file 先对空间的点进行聚类,查询时先比较聚类中心距离,再找到最近的N个点。 |
| IVF-SQ8 | 量化操作,disk cpu GPU 友好 |
| SQ8 | 对向量做标量量化,浮点数表示转为int型表示,4字节->1字节。 |
| IVF-PQ | 快速,但是准确率降低,把向量切分成m段,对每段进行聚类 |
| HNSW | 基于图的索引,高效搜索场景,构建多层的NSW。 |
| ANNOY | 基于树的索引,高召回率 |
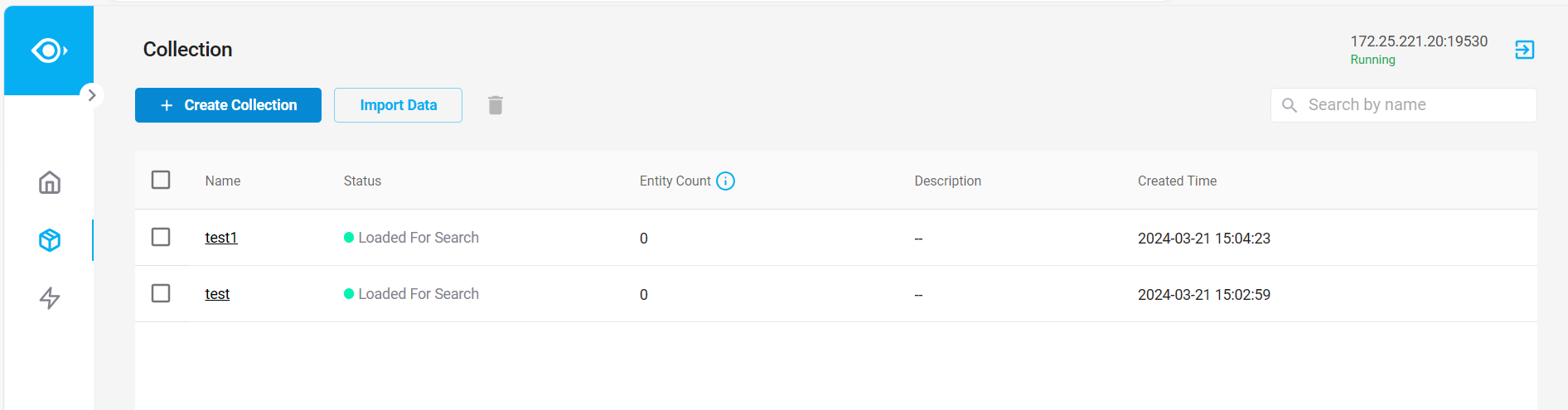
执行后可在可视化工具中看到创建的 Collection :
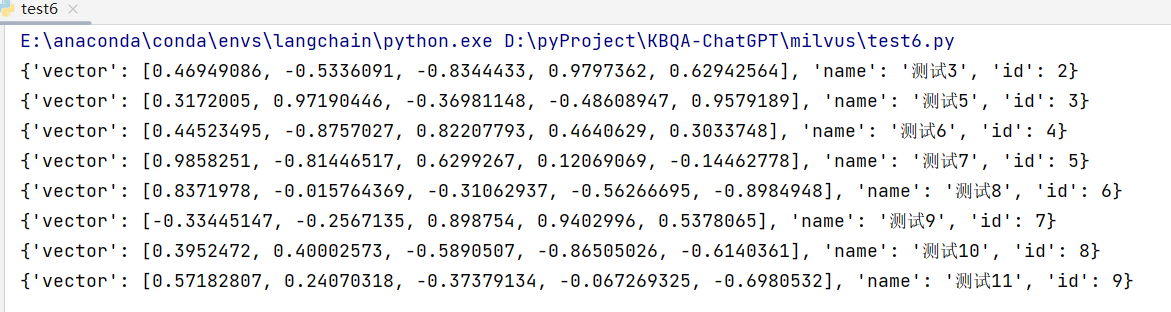
2. insert 写入数据:
|
|

3. search 向量相似查询数据
3.1 向量相似检索
|
|
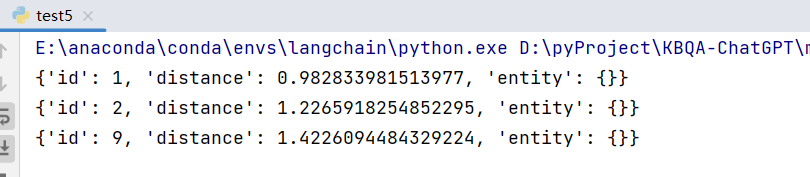
3.2 向量相似检索 + 过滤
过滤和 SQL 用法类似,通过 filter 字段控制:
|
|

3.3 向量相似检索 + 模糊查询过滤
模糊查询和 SQL 用法一直,使用 like 。
|
|
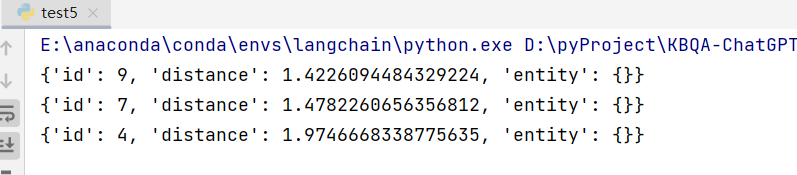
3.4 向量相似检索 + 指定输出字段
通过 output_fields 控制输出字段。
|
|

3.5 向量相似检索 + 分页
通过增加 offset + limit 的方式实现:
|
|

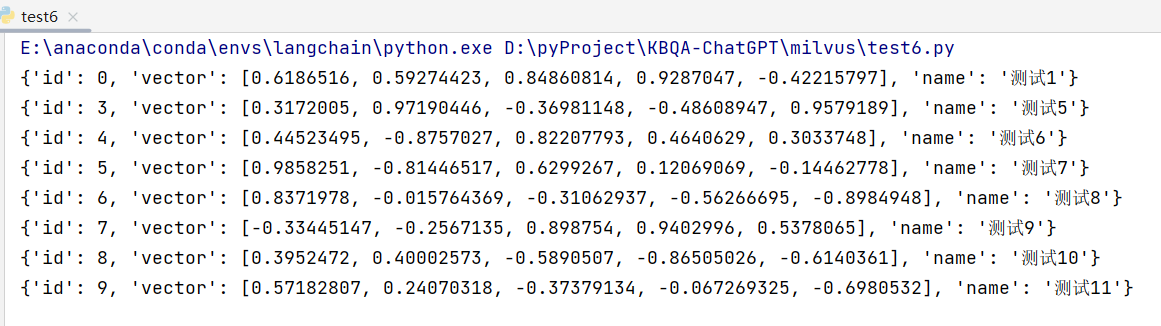
4. query 普通查询数据
query 用法和 search 类似,只是不用传递 data 向量了:
|
|
5. upsert 插入或更新数据
|
|
再次查询:
|
|

6. delete 删除数据
|
|
查询数据:
|
|
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Milvus-%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E4%BB%8B%E7%BB%8D%E5%8F%8A%E4%BD%BF%E7%94%A8_java-%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93-milvus--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


