Milvus作为OpenAI嵌入式向量数据库的探讨 --知识铺
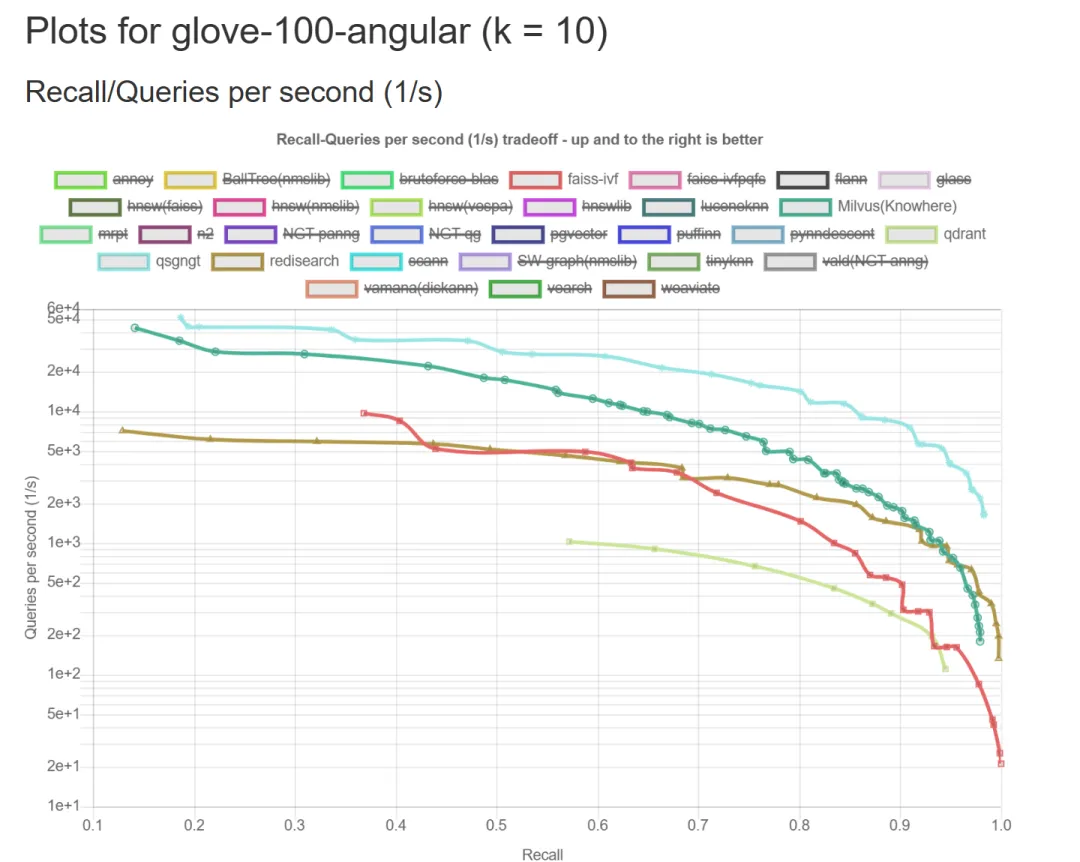
目前向量数据库的种类很多,也有很多性能对比的报告,可以参考这一份:https://ann-benchmarks.com/glove-100-angular_10_angular.html
电影描述生成与搜索示例
简介本文旨在展示如何使用OpenAI生成电影描述的嵌入式数据,并在Milvus中利用这些数据进行相关电影的搜索。我们的目标是通过过滤技术,结合元数据搜索,来优化搜索结果。
数据集来源本示例所用的数据集来源于HuggingFace,包含超过8000个电影条目。
准备工作在开始之前,我们需要下载以下库以支持我们的操作:
- PyMilvus: 用于与Milvus服务器进行通信。
- Datasets: 用于下载所需的数据集。
- Tqdm: 用于展示数据加载的进度条。
步骤概述
- 环境准备: 安装并配置上述库。
- 数据下载: 使用Datasets库下载HuggingFace提供的电影数据集。
- 数据预处理: 对下载的数据进行必要的清洗和格式化。
- 生成嵌入数据: 使用OpenAI技术生成电影描述的嵌入式数据。
- Milvus数据索引: 将生成的嵌入数据上传至Milvus,并建立索引。
- 搜索与过滤: 利用Milvus的搜索功能,结合元数据过滤,查找相关电影。
注意事项
- 确保Milvus服务器已正确配置并可访问。
- 在使用OpenAI进行嵌入数据生成时,注意API的使用限制和费用。
结语通过本示例,你将了解到如何结合使用OpenAI和Milvus进行电影描述的生成和搜索,以及如何通过过滤技术来提高搜索的准确性和效率。
! pip install openai pymilvus datasets tqdm
查看docker-compose.yaml:
version: '3.5'
! docker compose up -d
Milvus 配置全局变量指南
在使用 Milvus 进行向量搜索之前,需要设置一些全局变量以确保系统配置正确。以下是需要配置的变量列表:
-
HOST: Milvus 主机地址,用于连接到 Milvus 服务。
-
PORT: Milvus 端口号,用于指定服务的网络端口。
-
collection_name: 指定 Milvus 中的集合名称,集合是存储数据的容器。
-
DIMENSION: 嵌入向量的维度,影响搜索精度和性能。
-
ENGINE: 选择要使用的嵌入模型,用于生成和处理向量。
-
openai.api_key: 您的 OpenAI 账户密钥,用于访问 OpenAI 提供的 API 服务。
-
INDEX_PARAM: 设置用于集合的索引参数,优化搜索效率。
-
QUERY_PARAM: 定义使用的搜索参数,包括搜索范围和精度。
-
BATCH_SIZE: 指定一次嵌入和插入操作中处理的文本数量。 请确保按照上述指南设置您的 Milvus 环境变量,以实现高效的向量搜索和管理。
import openai
在Python代码中,我们定义了三个关键变量:INDEX_PARAM, QUERY_PARAM, 和 BATCH_SIZE,它们各自承担着特定的功能。
- INDEX_PARAM: 这个变量是一个字典,用于设置创建索引的参数。索引是一种优化数据检索的数据结构。这里使用的HNSW算法是高维空间中进行近似最近邻搜索的有效方法。HNSW算法中,参数’M’代表每个节点的邻居数量,而’efConstruction’是构建索引时搜索候选集的大小。这些参数对索引的构建速度和准确性有直接影响。此外,索引采用L2距离,也就是欧几里得距离,作为度量标准。
- QUERY_PARAM: 这个变量同样是字典类型,它存储了查询索引时的参数。查询操作同样以L2距离作为度量标准,确保与索引阶段的一致性。参数’ef’决定了查询时搜索候选集的大小,影响查询的速度和准确性。
- BATCH_SIZE: 这是一个整数,表示每次处理或查询时涉及的数据点数量。使用批处理可以提高操作的效率,但同时也需要更多的内存和计算资源。 这些变量可能是构建基于向量的搜索引擎或推荐系统的一部分,它们可以根据用户输入或偏好,快速定位到最相关或最相似的内容或产品。
HOST = 'localhost'
from pymilvus import connections, utility, FieldSchema, Collection, CollectionSchema, DataType
# Remove collection if it already exists
在Python编程中,集合(Collection)是一种用于存储和管理多个数据点的数据结构。本文将介绍如何使用Milvus,一个开源的向量搜索引擎,来高效地处理高维向量数据,例如文本或图像的嵌入。以下是实现这一功能的步骤:
- 定义数据点属性:创建一个名为
fields的列表,包含数据点的属性和类型。属性包括:
id:数据点的唯一标识符,为自动生成的整数。title:数据点的标题,字符串类型,最大长度64000字符。type:数据点的类型,字符串类型,最大长度64000字符。release_year:数据点的发布年份,整数类型。rating:数据点的评级,字符串类型,最大长度64000字符。description:数据点的描述,字符串类型,最大长度64000字符。embedding:数据点的嵌入向量,浮点数向量类型,维度由DIMENSION变量指定。
-
创建集合模式:定义一个名为
schema的对象,作为集合的模式,描述集合的结构和属性。它使用fields列表作为参数。 -
初始化集合对象:创建一个名为
collection的集合对象,用于存储和管理数据点。它使用COLLECTION_NAME变量作为集合的名称,并以schema对象作为其模式。 此代码片段可能是构建基于向量的搜索引擎或推荐系统的一部分,能够根据用户输入或偏好快速找到最相关或最相似的内容或产品。有关Milvus和向量搜索的更多信息,请参阅相关文章。
# Create collection which includes the id, title, and embedding.
# Create the index on the collection and load it.
Milvus 数据集抓取与存储流程
概述
Milvus 是一个开源的向量数据库,用于存储和搜索大量的向量数据。在本教程中,我们将使用 Milvus 来管理和搜索关于电影的数据集。
步骤一:数据集选择
我们选择了 Hugging Face Datasets 中的 netflix-shows 数据集作为我们的源数据。该数据集包含了 8000 多部电影的详细信息,包括元数据。
步骤二:数据抓取使用适当的工具或脚本从 Hugging Face Datasets 下载并加载 netflix-shows 数据集。
步骤三:数据预处理对数据集中的每条电影描述进行嵌入处理,以便将文本转换为向量形式。
步骤四:数据存储将处理后的向量数据以及电影的标题、类型、发行年份和评分等信息存储到 Milvus 数据库中。
注意事项
- 确保 Milvus 服务已经启动并运行。
- 嵌入向量的质量将直接影响搜索结果的准确性。
结语通过上述步骤,我们可以有效地将电影数据集嵌入到 Milvus 中,并利用其强大的搜索功能来探索和分析数据。
import datasets
插入数据
现在我们已经在机器上获得了数据,可以开始嵌入数据并将其插入 Milvus。嵌入函数接收文本,并以列表格式返回嵌入结果。
onverts the texts to embeddings
下一步是实际插入。我们遍历所有条目,并创建批次,一旦达到设定的批次大小,就插入这些批次。循环结束后,如果存在最后一个批次,我们将插入该批次。
from tqdm import tqdm
查询数据库
将数据安全地插入 Milvus 后,我们就可以执行查询了。该查询接收一个元组,其中包括要搜索的电影描述和要使用的过滤器。有关过滤器的更多信息,https://milvus.io/docs/boolean.md。搜索首先会打印出描述和过滤器表达式。然后,我们会为每个结果打印得分、片名、类型、发行年份、评分和结果电影的描述。
import textwrap
查询结果:

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Milvus%E4%BD%9C%E4%B8%BAOpenAI%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E6%8E%A2%E8%AE%A8--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


