Java程序员的问答知识库搭建教程(第二篇)
本文是系列教程的第二篇,旨在指导Java程序员如何结合ChatGPT和向量数据库,快速构建一个私有的问答知识库。这个知识库基于检索增强生成模型RAG,让读者能够通过本教程,一步步实现自己的AI机器人。
前言本系列教程分为三篇文章,本文将重点介绍环境准备和向量数据库的交互设置。在开始之前,请确保你已经拥有OpenAI GPT的账号。如果没有,可以搜索相关教程进行注册。
一、向量检索服务的开通向量检索服务是构建知识库的关键部分。你可以选择使用开源的向量数据库如Milvus或Faiss,或者选择云服务提供商的向量检索服务。为了简化流程,本文推荐使用阿里云的向量检索服务,目前该服务处于公测阶段,申请后即可免费使用。
创建API-KEY- 操作步骤:进入产品控制台,找到API-KEY管理,创建新的API-KEY。- 重要性:复制并保存你的API-KEY,因为在后续的代码调用中,它将被频繁使用。
结语通过本篇教程,你应该已经了解了如何开通并配置向量检索服务。下一步,我们将深入探讨如何与向量数据库进行交互,以及如何整合到你的Java项目中。请继续关注本系列的后续文章,获取更多实用信息。
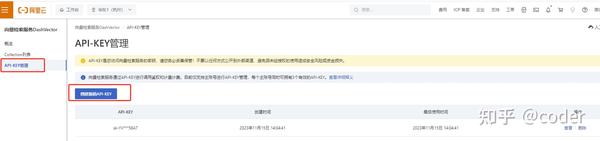
向量检索服务API-KEY创建指南
概述
向量检索服务是用于高效地进行向量数据匹配和搜索的系统。创建API-KEY是使用此服务的第一步。
创建API-KEY步骤
- 登录向量检索服务平台。2. 进入API-KEY管理页面。3. 点击创建API-KEY按钮,输入必要的信息。4. 系统将生成一个唯一的API-KEY。
创建Collection步骤1. 在向量检索服务平台,找到Collection列表。2. 点击创建新Collection的选项。3. 填写Collection的相关信息,包括: - Collection名称:根据自身业务需求命名。 - 向量维度:必须填写1536,以匹配灵积模型服务生成的向量。
注意事项- 请确保Collection名称与业务需求相符。- 向量维度的填写至关重要,错误将影响后续向量匹配的准确性。
截图示例由于无法提供实际截图,以下为示例说明:- Collection名称:aaaaaaa- 向量维度:1536
后续步骤创建Collection后,您可以进行向量数据的上传和管理,以实现高效的向量检索。
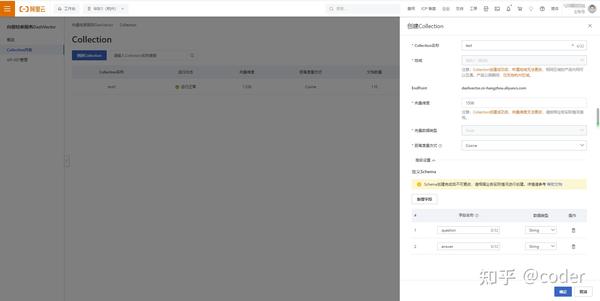
向量数据库创建Collection
二、灵积模型服务开通
OpenAI GPT的接口都是收费的,文本转向量这部分用不同大模型的接口实测没有特别明显的差异,灵积模型还支持批量文本转向量,所以这里依然采用阿里云的云服务,依然免费,放心白嫖。
阿里云灵积模型服务产品地址:模型服务灵积 DashScope
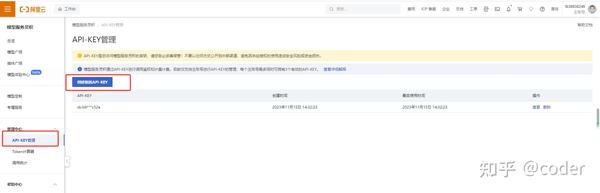
同样的,开通后进入产品控制台,在API-KEY管理中创建新的API-KEY,复制保存后面代码调用中需要使用
三、SpringBoot项目初始化构建
- 使用IDEA创建一个新的SpringBoot项目,注意依赖管理选择Maven,JDK和Java版本选择1.8
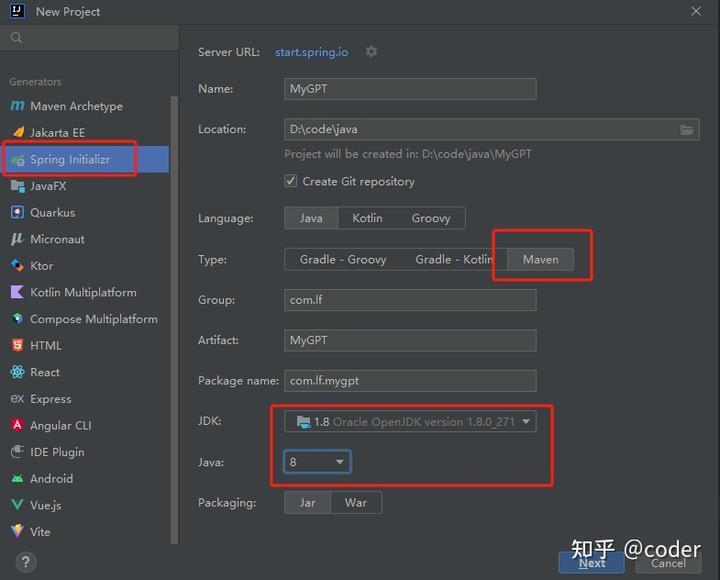
2. 依赖选择中由于我们后面要提供可访问接口供前端或浏览器调用,勾选上Spring Web即可,然后右下方Create创建项目
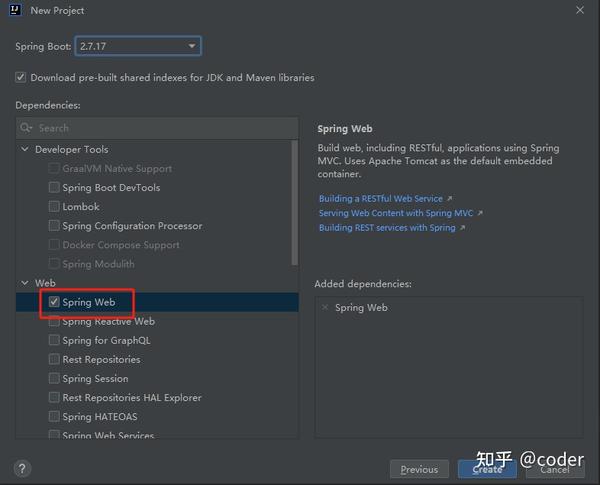
3. 校正生成后项目的SpringBoot版本,添加相关依赖,这里SpringBoot我采用的是本地项目使用的2.4.7
1
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.4.7</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.lf</groupId> <artifactId>MyGPT</artifactId> <version>0.0.1-SNAPSHOT</version> <name>MyGPT</name> <description>MyGPT</description> <properties> <java.version>1.8</java.version> </properties>
|
4、添加其他相关依赖
1
|
<!-- GPT-Java 的调用优化 --> <dependency> <groupId>com.unfbx</groupId> <artifactId>chatgpt-java</artifactId> <version>1.1.2-beta0</version> </dependency> <!-- 阿里云向量检索服务 --> <dependency> <groupId>com.aliyun</groupId> <artifactId>dashvector-java-sdk</artifactId> <version>1.0.6</version> </dependency> <!-- fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.75</version> </dependency> <!-- gson --> <dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version> </dependency>
|
配置Spring Boot项目配置文件
在Spring Boot项目中,我们可以通过两种主要的配置文件格式来管理应用的配置:application.properties 和 application.yml。以下是一些基本步骤和注意事项:
1. 选择配置文件格式如果你更习惯于使用YAML格式的配置文件,可以创建一个 application.yml 文件。默认情况下,Spring Boot生成的是 application.properties 文件。
2. 配置端口号在配置文件中,你可以自由设置端口号,只要确保它不与本机上的其他端口冲突即可。例如:propertiesserver.port=8080
3. 设置API密钥配置文件中可能需要包含API密钥(api-key),这是调用外部服务时必需的。请务必填写你自己的实际API密钥。示例中的API密钥已经被修改,直接使用是效的。
properties# 示例:application.propertiesapi.key=aaaaaaa
注意事项- 请根据实际需要修改配置文件中的API密钥。- 配置文件中的端口号应避免与本机其他服务冲突。
配置文件示例以下是使用 application.yml 格式的一个简单示例:```yamlserver: port: 8081
api: key:
请根据你的项目需求和个人喜好选择合适的配置文件格式,并正确填写所有必要的配置项。
```yaml
# 声明浏览器访问的端口号 server: port: 10010 # 阿里云向量检索服务的 api-key dash-vector-key: sk-YVfCClQoB2ZvVxrVd8oTbfKq7juhyDD78AEE9837C11EE8F6B421BE73B58A7 # 阿里云灵积模型服务的 api-key dash-scope-key: sk-b924aff9f2364b6f865fdea48aedc52e # OpenAI GPT调用的 api-key openai-key: sk-xbegjiZKHPDjrCp11tROT3BaceFJabE7KGgFSshfOILSYvaU
四、构建 Question 实体结构
1
|
package com.lf.mygpt.domain; import lombok.Getter; import lombok.Setter; import lombok.ToString; import java.util.List; @Getter @Setter @ToString public class Question { // 每一条Question的 Id private Long questionId; // 问题 private String question; // 答案 private String answer; // 向量结构 private List<Double> vector; }
|
接入阿里云灵积模型服务指南
概述灵积模型服务是阿里云提供的一项服务,主要用于将知识库内容和用户提问问题转化为向量形式,以便于进行更高效的文本处理和分析。
服务方式灵积模型服务支持两种调用方式:- SDK调用:通过集成SDK进行调用,但可能存在依赖冲突问题。- HTTP调用:推荐使用的方式,通过HTTP请求进行调用,避免了依赖冲突。
推荐方案由于SDK中的OkHttp依赖可能与ChatPT使用的第三方依赖冲突,因此推荐使用HTTP调用方式。
操作步骤1. 确定使用HTTP调用方式。2. 根据灵积模型服务的API文档,编写HTTP请求代码。3. 发送请求并接收响应,获取文本的向量化结果。
注意事项- 确保网络环境稳定,以保证HTTP请求的顺利进行。- 对API文档进行充分理解,以避免在调用过程中出现错误。
结语通过接入阿里云灵积模型服务,可以有效地提升知识库管理和用户交互的智能化水平。
1
|
// 灵积大模型的 key @Value("${dash-scope-key}") private String DASH_SCOPE_KEY; // 灵积大模型 Embedding 的请求 Url private static final String TextEmbeddingUrl = "https://dashscope.aliyuncs.com/api/v1/services/embeddings/text-embedding/text-embedding"; /** * 利用灵积大模型进行文本向量化 * @param textList 待转换的文本列表 * @param textType 带转换的文本类型,分为 doucment 和 query,分别对应知识库文档和用户问题,阿里云文档表示对于query他们有特殊处理,使得检索效果更好 * @return 返回文本列表对应生成的向量列表 */ public List<EmbeddingItem> textEmbedding(List<String> textList, String textType) { List<EmbeddingItem> embeddingResult = new LinkedList<>(); // 构造请求体 JSONObject body = new JSONObject(); body.put("model", "text-embedding-v1"); JSONObject texts = new JSONObject(); JSONObject parameter = new JSONObject(); parameter.put("text_type", textType); body.put("parameters", parameter); texts.put("texts", textList); body.put("input", texts); // 发送请求 RestTemplate template = new RestTemplate(); HttpEntity<String> entity = new HttpEntity<String>(body.toJSONString(), getTextEmbeddingHttpHeaders()); ResponseEntity<JSONObject> response = template.exchange(TextEmbeddingUrl, HttpMethod.POST, entity, JSONObject.class); // 处理请求返回结果 JSONArray jsonArray = response.getBody().getJSONObject("output").getJSONArray("embeddings"); jsonArray.forEach( embedding -> { EmbeddingItem embeddingJson = JSONObject.parseObject(JSON.toJSONString(embedding), EmbeddingItem.class); embeddingResult.add(embeddingJson); } ); return embeddingResult; } /** * 构造灵积大模型的请求头,请求头中需要使用 DASH_SCOPE_KEY 进行鉴权 * @return 对应的请求投 */ private HttpHeaders getTextEmbeddingHttpHeaders() { HttpHeaders httpHeaders = new HttpHeaders(); httpHeaders.add("Authorization", "Bearer " + DASH_SCOPE_KEY); httpHeaders.add("Content-Type", "application/json"); return httpHeaders; }
|
六、接入阿里云向量检索服务
向量检索服务实现使用阿里云提供的Java SDK
向量检索这里主要实现两个功能:
- 对向量化的私有知识存入向量库中
1
|
/** * 初始化问题列表到向量数据库中 * @param questionList 问题列表 */ public void initQuestionToDashVector(List<Question> questionList) { // 阿里云文本转向量最大支持每次转25条文本,这里需要对问题列表进行分批处理 int batchSize = 25; int totalSize = questionList.size(); // 总数据量 for (int i = 0; i < totalSize; i += batchSize) { int endIndex = Math.min(i + batchSize, totalSize); // 获取当前批次的文本数据 List<Question> batchQuestion = questionList.subList(i, endIndex); List<String> batchTexts = batchQuestion.stream().map(Question::getQuestion).collect(Collectors.toList()); System.out.println(" == 处理的问题列表 =="); System.out.println(batchTexts); // 执行文本向量化操作,调用上一步构造好的 textEmbedding 方法 List<EmbeddingItem> embeddingResultItemList = textEmbedding(batchTexts, "document"); // 构建向量数据库插入的请求体结构 DashVectorCollection collection = vectorClient.get(COLLECTION_NAME); List<Doc> docList = new LinkedList<>(); for(int j=0; j<batchQuestion.size(); j++){ Question question = batchQuestion.get(j); Vector vector = Vector.builder() .value(embeddingResultItemList.get(j).getEmbedding().stream().map(Double::floatValue).collect(Collectors.toList())) .build(); Doc doc = Doc.builder() .vector(vector) .id(question.getQuestionId().toString()) .field("question", question.getQuestion()) .field("answer", question.getAnswer()) .build(); docList.add(doc); } // 执行新增更新数据的请求 UpsertDocRequest upsertDocRequest = UpsertDocRequest.builder() .docs(docList).build(); Response<Void> response = collection.upsert(upsertDocRequest); System.out.println(response); } }
|
2. 用户提供的问题转向量后搜索向量数据库,得到相关的语料
1
|
/** * 根据问题进行向量查询 * @param question 用户的问题文本 * @return 相关的初始问题知识列表 */ public List<Question> searchQuestion(String question) { // 执行用户问题向量化操作,调用上一步构造好的 textEmbedding 方法 List<EmbeddingItem> embeddingResultItemList = textEmbedding(Collections.singletonList(question), "query"); // 获取到我们创建好的Collection DashVectorCollection collection = vectorClient.get(COLLECTION_NAME); Vector vector = Vector.builder().value(embeddingResultItemList.get(0).getEmbedding().stream().map(Double::floatValue).collect(Collectors.toList())).build(); QueryDocRequest queryDocRequest = QueryDocRequest.builder() .vector(vector) .topk(5) .build(); Response<List<Doc>> response = collection.query(queryDocRequest); System.out.println(" == 向量查询结果 == "); System.out.println(response); // 将查询到的结果转换为之前构造的 Question 的格式返回给前端 List<Question> result = new LinkedList<>(); for (Doc doc : response.getOutput()) { Question question1 = new Question(); question1.setQuestionId(Long.valueOf(doc.getId())); question1.setQuestion(doc.getFields().get("question").toString()); question1.setAnswer(doc.getFields().get("answer").toString()); result.add(question1); } return result; }
|
七、构造controller接口方便浏览器调用
1
|
/** * 初始化问题向量 * @param questionList questionList 问题列表 */ @PostMapping("/init-vector") public void initQuestionToDashVector(@RequestBody List<Question> questionList) { dashVectorService.initQuestionToDashVector(questionList); } /** * 根据问题进行向量查询 * @param question 用户的问题文本 * @return 相关的初始问题知识列表 */ @PostMapping("/search") public List<Question> search(@RequestBody Question question) { return dashVectorService.searchQuestion(question.getQuestion()); }
|
八、实际调用测试
在完成了程序与向量检索相关的所有开发工作后,接下来我们将通过Postman进行接口测试。本节将详细介绍测试流程。
1. 初始化私有知识库测试
为了测试初始化私有知识库的功能,我们需要准备一些问答知识。以下是一些示例知识,您可以使用这些示例,也可以根据自己的需求创建新的知识内容。
示例问答知识
- Q: 如何进行接口测试?
A: 接口测试是确保软件组件按预期工作的一种测试方法。通常使用工具如Postman来模拟客户端请求,验证服务器响应。
- Q: 什么是Markdown?
A: Markdown是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML(或者HTML)。
测试步骤
- 打开Postman应用程序。
- 创建一个新的请求,并设置请求方法,例如GET或POST。
- 输入服务器的URL地址。
- 根据API文档设置请求头和请求体。
- 发送请求并观察响应结果。
注意事项
- 确保API文档与实际接口保持一致。
- 检查响应数据是否符合预期格式。
- 测试不同场景下的接口表现,包括正常情况和异常情况。
通过上述步骤,您可以对私有知识库的初始化功能进行全面测试,确保其稳定性和可靠性。
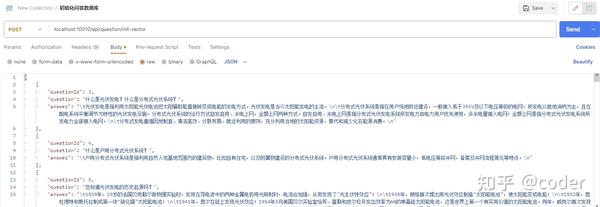
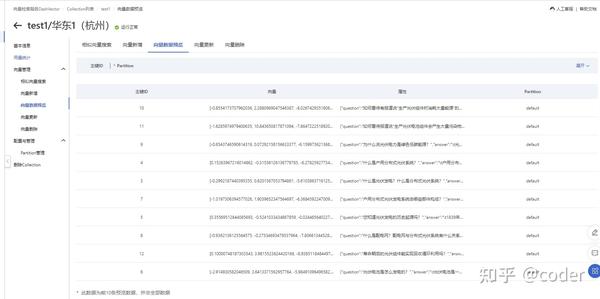
初始化完成后,我们可以在阿里云的向量检索服务控制台看到新增的数据
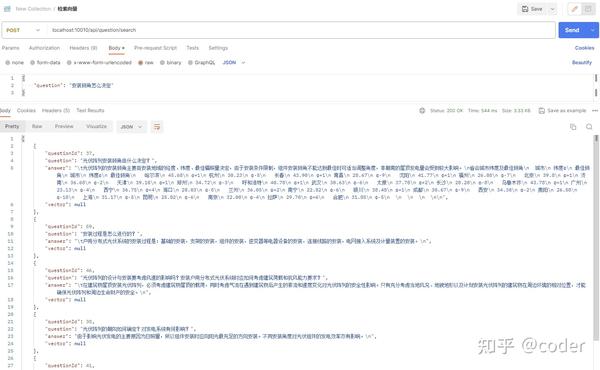
2. 使用用户问题检索知识库
在本系列的前两篇文章中,我们已经详细介绍了如何对接向量检索服务。现在,我们将进入下一阶段,即与ChatGPT的对接,并完成整个业务流程的整合。以下是对前文的概括以及接下来步骤的预告。
前文回顾- 上一篇文章:我们探讨了向量检索服务的对接过程。点击这里回顾上一篇内容。
下一步预告- 下一篇文章:我们将开始对接ChatGPT,并实现业务流程的整合。点击这里查看下一篇文章。
项目仓库- 仓库地址:lifei1102/MyGPT。这是项目的GitHub仓库,你可以在这里找到源代码和更多信息。
注意事项- 目前,知乎小程序尚不支持点击链接直接跳转。如果你希望查看后续内容或获取源码,请在App或网页浏览器中打开上述链接。
请继续关注本系列,我们将逐步深入,为你展示如何将先进的技术应用到实际项目中。


