Java从0到1构建基于ChatGPT+向量数据库的检索增强生成模型RAG-01 --知识铺
Java程序员如何搭建问答知识库
前言本系列教程将指导Java程序员如何利用ChatGPT+向量数据库构建私有的问答知识库,即RAG模型。通过三篇文章,读者将学会创建AI机器人,本系列将详细描述每个步骤,并提供源码链接。
第1篇:RAG模型原理介绍本文不涉及代码,而是从原理上帮助读者理解RAG。
AI大模型的局限性
尽管AI大模型如OpenAI GPT-4-Turbo在逻辑和互动方面表现出色,但在实际应用中存在以下问题:
- 知识更新滞后:大模型的知识库通常不会实时更新,导致无法获取最新信息。2. 缺乏私有知识:企业或个人需要模型理解特定的私有知识,如客服机器人、产品问答等。
解决AI大模型缺陷的策略
为了克服这些限制,我们可以通过以下两种方式将知识传递给AI模型:
- 构造问题:在问题中嵌入私有知识,使AI能够理解并回答。2. 微调训练(Fine-tune):虽然效果更佳,但需要硬件资源和时间,且难以实时更新。 构造问题是一种更灵活且成本较低的方法。例如:
你作为XX领域的专家,请根据以下资料回答用户问题。> > 资料:> - 小米汽车蓝图现世,智能化进程加速。> - 11月15日,小米汽车首款车型获批生产,型号SU7和SU7MAX,由北汽越野车代工,计划2024年上半年上市。> > 用户问题:> - 小米汽车何时上市?
检索与知识构造
在构建问题时,我们需要找到与用户问题相关的资料。传统关键词检索可能不足以处理复杂语义关系。因此,我们需要更先进的检索技术来实现精确匹配。
关键词检索的局限性关键词检索在处理具体关键词时效果显著,但面对包含多个关键词和复杂语义的问题时,其效果有限。
向量数据库的作用向量数据库能够存储和检索向量化的数据,这为实现更高级的检索提供了可能。通过向量数据库,我们可以更有效地找到与问题相关的资料,从而构造出更准确的AI问题。
结语本文为构建问答知识库的第一步,提供了对RAG模型的初步理解。接下来的教程将深入代码实现和具体操作,敬请期待。
传统的关键词检索
我们希望有一个搜索服务,可以针对用户问题的语义,来搜索到私有知识库中语义相近的标题或段落,在这个场景下,向量检索闪亮登场。
三、什么是向量检索
AI大模型训练过程中,对文本的语义关系在计算机底层是数字化处理的,提供普通聊天接口的同时,每一个AI大模型也都提供了一个将文本语义向量化的服务。
向量是一组浮点数,例如[0.1, 0.2, …],在高中数学中我们学习到一个二维向量可以表达在一个直角坐标系中,两个向量之间可以通过欧氏距离来计算向量间距离,也可以通过余弦距离来衡量两个向量相对于原点的方向近似度。
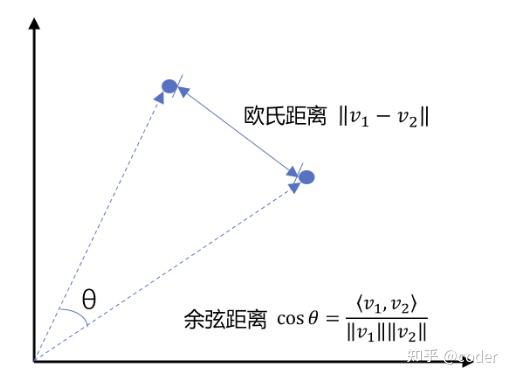
向量相似度的计算
向量检索实际上是将文本分段转换成了一个个向量,通过余弦距离或欧式距离来计算两个向量之间的相似度,向量相似度越高,表示对应的2个文本语义相似度越高。我们可以通过这种方式来获得与用户问题语义最相近的私有知识库的资料,如下图所示:
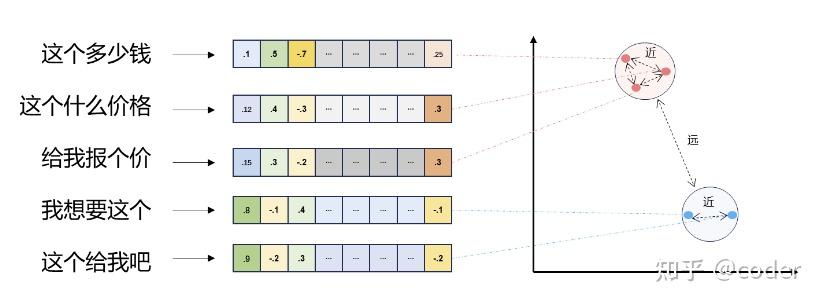
向量检索技术是一种先进的信息检索方式,它与传统的关键词检索方法有着本质的区别。在传统的关键词检索中,系统需要识别并提取用户查询中的关键词,然后根据这些关键词在知识库中进行匹配。这种方法存在一定的局限性,例如对于语义理解的深度和广度有限,以及对关键词的依赖性较强。
向量检索则不同,它通过将文本内容转换为向量形式,利用向量空间模型来表达文本的语义信息。这样一来,即使用户的问题中没有直接出现知识库中的关键词,只要问题与知识库中的文本在语义上存在相关性,系统也能够检索到相关内容。例如,下面的示例展示了向量搜索的工作原理:
- 文本向量化:首先,系统将用户的问题和知识库中的文本都转换为向量。
- 语义匹配:然后,系统通过计算向量之间的相似度来确定语义相关性。
- 结果检索:最后,系统根据相似度的高低,检索出与用户问题最相关的文本。 这种方法的优势在于它能够突破关键词的限制,更全面地理解用户的查询意图,从而提供更为准确和相关的搜索结果。
|
|
四、向量数据库与AI大模型协同工作流程
1. 文档向量化与存储
- 利用文本向量化接口,将原有知识库文档进行向量化处理。- 将向量化后的内容存储于向量数据库中,为后续检索提供基础。
2. 用户问题向量化与检索- 将用户的提问通过文本向量化接口转换成向量形式。- 使用该向量在向量数据库中检索与用户问题相似的资料。
3. 问题组装与资料整合- 将用户的问题与检索到的相似资料进行整合,形成一个新的问题集合。
4. AI大模型的回答生成- AI大模型根据私有化的知识资料库,对新组装的问题集合进行分析。- 根据分析结果,生成回答,以满足用户的问题需求。
注意事项- 确保向量化接口的准确性,以提高检索的准确性和效率。- 私有化知识库的维护与更新,确保AI大模型能够访问到最新的资料。- 对AI大模型的回答进行质量控制,确保回答的准确性和相关性。
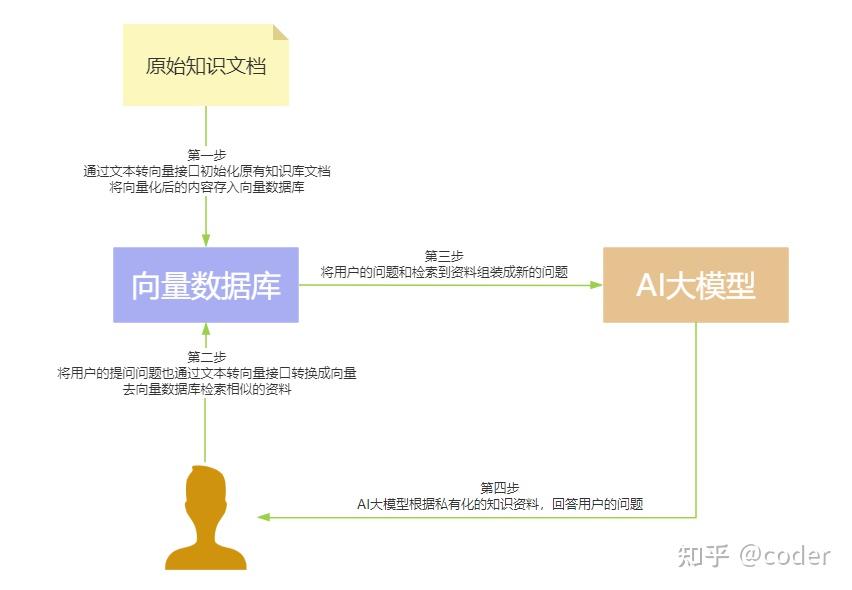
向量数据库与AI大模型的结合使用指南
一、概述
向量数据库与AI大模型的结合使用,可以极大地提升数据处理和智能分析的能力。本文将详细介绍这一执行过程,并通过视频链接,帮助读者更直观地理解。
二、开发前的准备工作
在开始实际开发之前,需要完成以下准备工作:
- 获取OpenAI Key:首先需要有一个OpenAI的Key,这是调用其API的凭证。 2. 确保网络环境稳定:需要一个可以稳定访问的网络环境,例如使用魔法网络或代理服务器。
- 申请阿里云向量检索服务:前往阿里云申请向量检索服务,并获取相应的Key,目前该服务处于公测阶段,可以免费使用。
- 开通灵积模型服务:在阿里云开通灵积模型服务,用于将文本转换为向量,这一过程速度快且免费。注意,这里并没有使用OpenAI的GPT模型进行文本向量化。
- 配置本地Java开发环境:确保本地计算机上安装有Java开发环境,以便进行后续的开发工作。
三、实操教学预告
完成上述准备工作后,我们将进入实操教学阶段。下一篇文章将详细介绍具体的开发步骤和方法。
四、资源链接
- 视频教程链接:点击查看视频教程- 项目仓库地址:lifei1102/MyGPT
五、注意事项
- 目前知乎小程序不支持点击链接跳转,需要在App或网页端查看视频教程和源码。
- 请确保在App或网页端操作,以获得最佳体验。 以上就是向量数据库与AI大模型结合使用的准备工作和预告信息。希望能够帮助到对此感兴趣的开发者和研究者。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/Java%E4%BB%8E0%E5%88%B01%E6%9E%84%E5%BB%BA%E5%9F%BA%E4%BA%8EChatGPT+%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%E6%A8%A1%E5%9E%8BRAG-01--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


