DDD领域驱动设计在Spring Boot中的落地实践 --知识铺
系列文章目录
前言
在软件开发过程中,我们经常会遇到一些架构设计上的挑战。本文将探讨如何使用领域驱动设计(DDD)来解决这些问题,并介绍在项目Yanx中的实际应用。
传统三层架构的问题
- 面向数据而非面向对象,导致编程过程不够面向对象。- Service层代码冗长,包含大量过程代码,难以维护。- 层与层之间耦合度高,代码修改容易引起连锁反应。- 代码难以反映业务逻辑,随着时间推移,业务逻辑变得难以理解。
DDD的优势- 面向领域建模,代码更贴近业务,易于理解。- 领域逻辑集中,易于维护和扩展。- 技术细节变更对业务逻辑影响小,适合构建插件式架构。- 提高代码可读性和可维护性。
DDD落地方案在Yanx项目中,我们采用了DDD的分层设计,以解决传统三层架构的问题。以下是具体的分层说明:
DDD分层设计1. 战略设计:确定项目的核心领域和支撑领域。2. 战术设计:细化领域模型,包括实体、值对象、聚合等。3. 领域模型:构建反映业务概念的领域模型。4. 应用层:处理应用程序的业务逻辑。5. 基础设施层:提供技术实现,如数据库访问、消息传递等。
通过DDD分层设计,我们能够构建一个更加灵活、可维护的系统,同时保持代码的清晰和业务的紧密联系。
在软件架构设计中,合理分层是保证系统可维护性和扩展性的关键。以下是对系统架构的分层及其调用关系的详细说明:
1. 用户接口层用户接口层主要负责与用户交互,接收用户的输入并返回相应的结果。在本架构中,用户接口层通过 api 包实现,相当于传统的 controller 层,但为了简化命名,我们省略了 controller 后缀。
2. 应用层应用层是业务逻辑的执行者,其核心是命令模式的运用。为了实现读写分离,我们将应用层进一步细分为 command 和 query 两个包。如果业务逻辑较为简单,不采用命令模式,可以将这两个包合并为单一的 service 包。
3. 领域层领域层是业务规则和业务逻辑的核心体现,通过 domain 包实现。本层使用 JPA(Java Persistence API)作为持久化框架,以支持领域驱动设计(DDD)。
4. 基础设施层基础设施层,即 infra 包,用于存放所有公共组件和工具类。如果遵循依赖倒置原则(DIP),则实现类也应该放置于此。
5. 模型层模型层通过 model 包实现,负责定义不同层之间传递的数据模型。经过实践,我们发现将这些模型统一放置于一个包下,不仅便于维护,也方便服务间的调用和对象共享。
分层及调用关系各层之间的关系和模型传递如下:
- 用户通过
api包发起请求。-api包根据请求类型,调用对应的command或query包。-command和query包处理业务逻辑后,与domain包交互,获取或更新领域模型。-domain包通过infra包调用底层服务和数据库操作。- 处理结果通过model包的模型对象在各层间传递,最终返回给用户。 这种分层设计不仅清晰地划分了各层职责,还提高了代码的复用性和系统的可维护性。
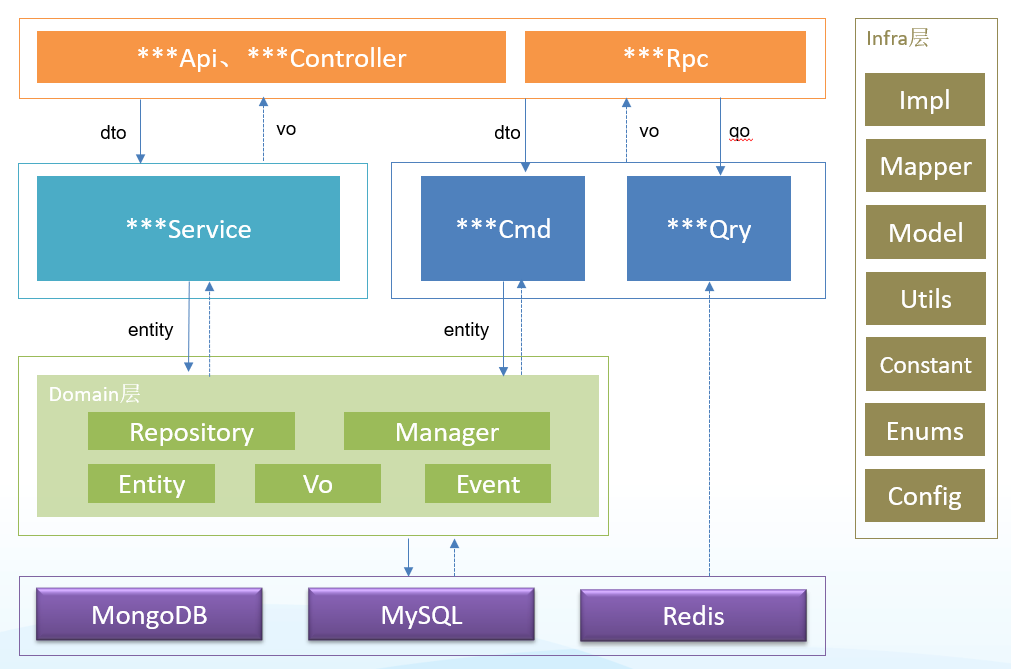
详细说明:
-
api包(controller)
|
|
在设计API接口时,我们采用了以下结构和策略以提高代码的可维护性和可扩展性:
- BaseApi封装:在
BaseApi中,我们封装了queryExecutor和commandExecutor两个命令执行类。通过调用应用层时执行不同的命令,我们避免了使用@Autowired引入不同的服务,从而简化了依赖注入的复杂性。 - 统一结果封装:我们引入了
@ApiResult自定义注解,通过这个注解,我们可以对返回结果进行统一封装,确保了API的响应格式的一致性。 - 自动分页处理:通过
@Pagination自定义注解,我们实现了自动将分页参数存入线程变量的功能。这样,在执行查询操作时,系统会自动获取分页参数,并且在返回结果时,也会包含分页信息,从而简化了分页逻辑的处理。 - 参数与返回对象规范:我们定义了
Qo作为查询参数对象,Dto作为增删改等命令参数对象,而返回对象则使用Vo。特别需要注意的是,Entity对象绝对不能直接暴露到应用层,必须转换为Vo后再进行返回,以保证数据的封装性和安全性。 - 方法简洁性:在
BaseApi层中,每个方法通常只包含一行执行命令的语句,我们尽量避免在这一层面进行复杂的业务逻辑处理,除非遇到特殊情况。 此外,我们还有一个command包,它可能包含具体的命令实现逻辑,但具体内容未在上文提及。
|
|
命令模式实现指南
在软件开发中,命令模式是一种常用的设计模式,它能够将请求或操作封装成对象。以下是实现命令模式的步骤和要点:
- 定义命令接口:创建一个自定义的
Command接口,该接口包含一个泛型返回值。这使得命令模式可以灵活地处理不同类型的返回结果。 - 实现命令类:针对每一个操作,实现一个具体的命令类。这些类将实现
Command接口,并包含业务逻辑。 - 使用构造方法接收参数:通过构造方法和Lombok注解简化属性的注入,使得命令对象的创建更加简洁。
- 单一职责原则:每个命令类只包含一个
execute方法,这符合单一职责原则,即每个类只负责一项任务。 - 领域服务的调用:命令对象通过
executor.getReceiver方法获取到对应的领域服务(例如manager),然后调用其方法执行具体的业务逻辑。 - 数据转换:DTO(数据传输对象)不应该直接在领域层中使用。需要先将DTO转换为Entity,这里推荐使用MapStruct工具来完成这一转换过程。
- 组织者的角色:作为工作的组织者,增删改命令层很薄,主要负责调用领域服务和充血对象的方法,而不包含复杂的业务逻辑。
query包
此部分内容未提供详细信息,但通常指的是与查询相关的类或方法的集合。
|
|
架构设计心得
命令模式与QueryDSL
在设计系统时,我们采用了命令模式和QueryDSL来优化查询效率和代码的可读性。
- 命令模式:通过继承自定义的
QryCommand基类,我们实现了一个通用的命令接口。这个接口封装了分页查询的方法,并且使用了QueryDSL的queryFactory类来增强查询能力。泛型参数允许我们根据需要返回不同的查询结果。 - QueryDSL:由于JPA在处理复杂查询时存在局限性,我们推荐使用QueryDSL。它提供了一种类型安全的方式来构建查询,并且可以很容易地与JPA集成。以下是一个简单的QueryDSL使用示例。
domain包设计
domain包中包含了多个类,主要负责实体(Entity)的管理。
- Entity类:自动生成数据库表,维护数据模型,同时隐藏数据库的复杂性。- 关系注解:灵活使用
@OneToMany、@OneToOne等JPA注解来设计聚合根,但要注意不要过度设计,保持聚合根的简洁性。- 面向对象设计:避免使用贫血模型,确保业务逻辑封装在领域服务(manager)中,而不是散布在Repository类中。- 领域服务:业务逻辑应集中在领域服务中,通过不断的抽象和提取,形成可复用的方法。- 领域事件:适当使用领域事件来处理业务逻辑,JPA支持在Entity中使用@DomainEvents注解来触发事件。
心得体会
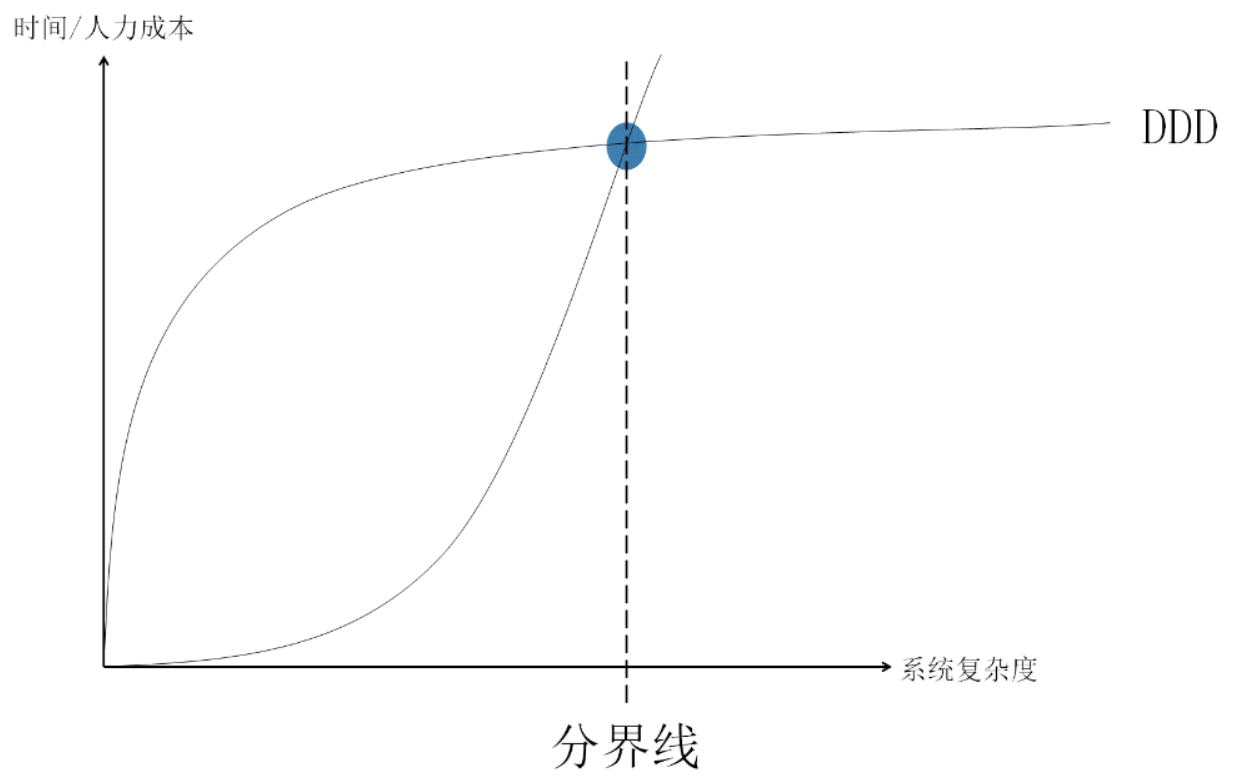
- DDD的适用性:领域驱动设计(DDD)并非万能解决方案。对于简单功能,传统的三层架构可能更加清晰和便捷。- 业务理解:DDD帮助我们更深入地理解业务,使得代码能够更好地反映业务需求。- 代码质量:DDD鼓励编写低耦合、符合单一职责、开闭原则的代码,这使得代码更加优雅和易于维护。- 前期投入:虽然DDD在前期需要更多的代码量和开发投入,如领域划分、实体设计、DTO/VO的创建以及数据转换方法等,但对于中等复杂的系统,这些投入是值得的。以下是一张图来说明这一点:
[图示]
结论
尽管DDD带来了一些挑战,但对于提升代码质量和系统可维护性,它提供了一种有效的架构方法。
领域驱动设计(DDD)概述与SpringBoot实践
领域驱动设计(Domain-Driven Design,简称DDD)是一种软件设计方法,它强调以业务领域为中心进行软件开发。本文将分享我对DDD的理解和实践经验,并通过具体的代码示例,展示如何在SpringBoot框架中应用DDD。
DDD核心概念
DDD包含几个核心概念,如实体(Entity)、值对象(Value Object)、聚合根(Aggregate Root)、领域服务(Domain Service)等。理解这些概念对于实现DDD至关重要。
实体实体是具有唯一标识的领域对象,其生命周期内属性可能发生变化。
值对象值对象是描述领域概念的不可变对象,通常用于描述实体的属性。
聚合根聚合根是一组相关对象的集合,它定义了一组不变规则,确保数据的一致性。
领域服务领域服务是执行领域逻辑的操作,通常与特定的实体或聚合无关。
SpringBoot中应用DDD
SpringBoot是一个流行的Java框架,用于创建独立、生产级的基于Spring框架的应用程序。以下是在SpringBoot中实现DDD的一些步骤:
- 定义领域模型:根据业务需求定义实体、值对象和聚合根。2. 创建领域服务:实现领域逻辑,如业务规则和复杂计算。3. 集成数据访问层:使用Spring Data JPA或其他ORM框架进行数据库操作。4. 应用层设计:设计应用程序的API接口,实现与领域层的交互。
实践示例
项目代码已托管在Gitee平台,项目名为yanx。通过这个示例项目,您可以学习如何将DDD应用于实际开发中。
结语
DDD是一种强大的设计方法,能够帮助开发者更好地理解和建模业务领域。通过本文的介绍和示例代码,希望能够为您提供一个清晰的DDD实践思路。如果您在学习和实践中遇到任何问题,欢迎在下方留言讨论。
注意:以上内容为示例,具体的项目实践和代码实现可能有所不同。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/02-%E6%9E%B6%E6%9E%84%E5%B8%88%E5%BF%85%E5%A4%87-DDD%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1%E4%B9%8B%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5_springboot-ddd--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


