领域驱动设计及其模型概念解析 --知识铺
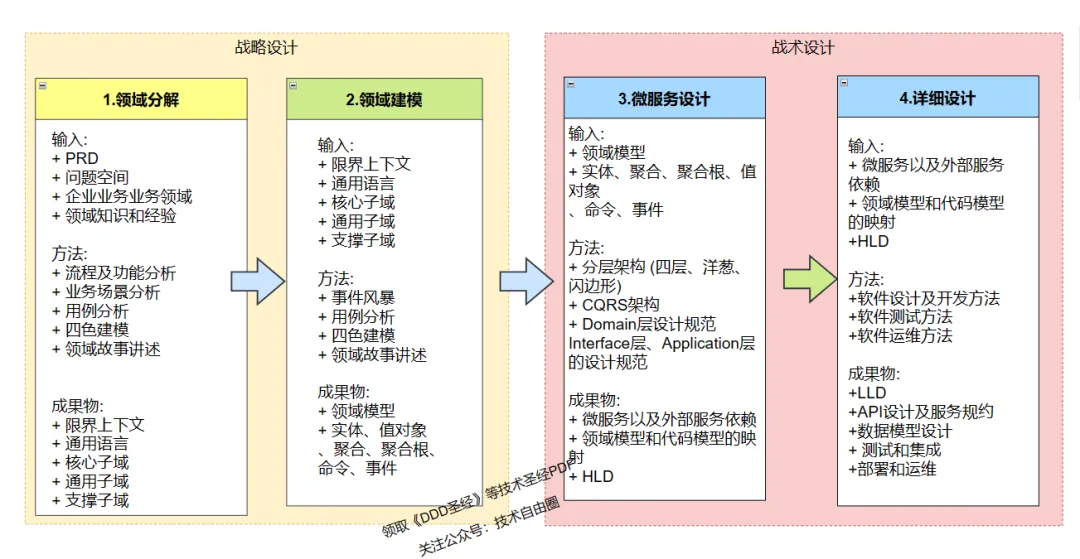
领域驱动设计(DDD)概述
领域驱动设计(Domain-Driven Design,简称DDD)是一种软件设计方法,由Eric Evans在2004年提出。它旨在帮助开发者更好地理解业务领域,并通过软件设计来解决业务问题。以下是对DDD的详细介绍和相关问题的解答。
一、DDD的基本概念
1. DDD的定义
DDD是一种设计和架构方法,它强调以业务域为中心,通过创建丰富的领域模型来反映业务专家的语言和思维。
2. DDD的价值
- 清晰的业务理解:帮助开发者深入理解业务需求。
- 高效的沟通:促进开发者与业务专家之间的沟通。
- 灵活的架构:支持快速响应业务变化。
3. DDD的核心概念
- 领域(Domain):业务的特定领域。
- 子域(Subdomain):领域中的一个具体部分。
- 限界上下文(Bounded Context):明确领域模型的边界。
- 核心域与通用子域:区分领域中的关键部分和一般部分。
二、DDD的关键组件
- 领域模型(Domain Model):反映业务概念和业务逻辑的模型。
- 实体(Entities):具有唯一标识和生命周期的对象。
- 值对象(Value Objects):描述领域中的具体值,没有唯一标识。
- 聚合(Aggregate):一组相关对象的集合,由聚合根管理。
- 聚合根(Aggregate Root):聚合中的主要对象,作为外部交互的入口。
- 服务(Services):执行领域逻辑的操作。
- 仓储(Repository):提供领域聚合的持久化和检索。
三、DDD与微服务
DDD与微服务架构设计紧密相关,DDD可以帮助开发者在微服务中更好地划分服务边界,实现服务的自治和解耦。
四、DDD落地实践
- 外部接口调用:通常放在应用服务层,以保持领域层的纯净。
- DDD架构落地:通过不断的迭代和重构,逐步将DDD理念融入到项目开发中。
- 领域层设计:专注于业务逻辑,避免技术细节的干扰。
五、DDD相关问题解答
- DDD的外部接口调用:应放在应用服务层,以保持领域模型的独立性和清晰性。
- 聚合与数据库表的关系:聚合通常对应数据库中的一组相关表,聚合根作为数据操作的主要入口。
- DDD与微服务拆分:微服务的拆分应基于限界上下文,确保服务的内聚性和独立性。
六、结论
DDD是一种强大的设计方法,它可以帮助开发者构建高质量的软件系统。通过深入理解业务领域,创建丰富的领域模型,DDD能够提升软件的可维护性和可扩展性。
七、参考文献
- Eric Evans. Domain-Driven Design – Tackling Complexity in the Heart of Software
DDD为我们提供的是架构设计的方法论,既面向技术也面向业务,从业务的角度,自顶向下来把握设计方案。
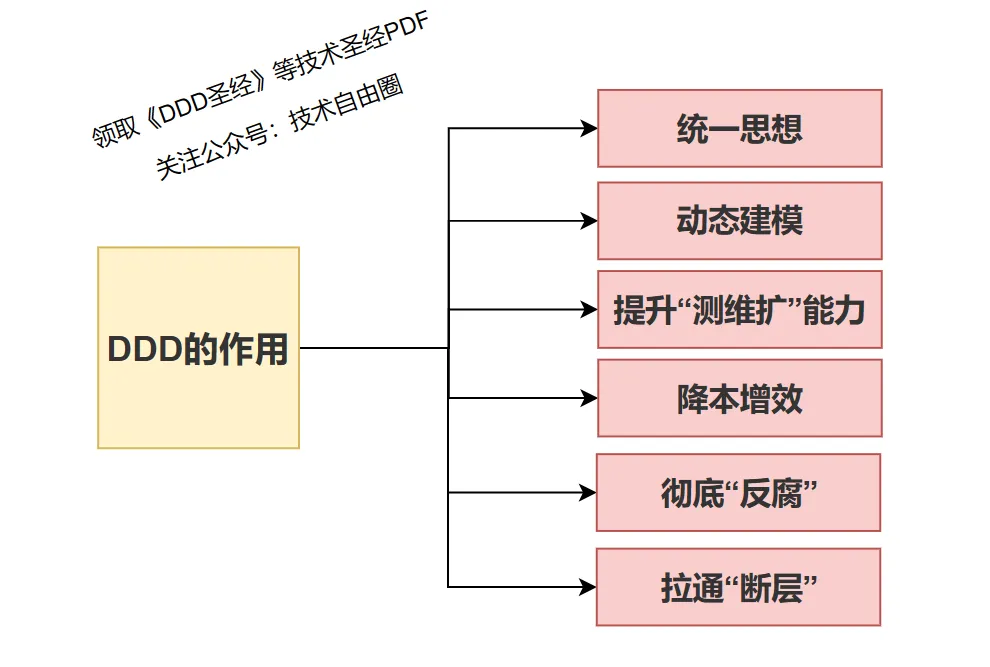
DDD的巨大价值
DDD宏观概念解析
一、统一思想的重要性
统一思想是项目成功的关键。它涉及到业务、产品、开发等多个方面,通过统一的语言和明确的定义,减少理解误差和分歧。DDD工具链在此过程中扮演了重要角色,它通过可视化流程构建知识库,提高了沟通效率,帮助开发人员快速理解业务,从而降低返工概率。
DDD工具链的作用:
- 强化表达:帮助逻辑能力的表达。
- 构建知识库:快速提升产品和技术间的沟通效率。
二、动态建模的必要性
需求是不断变化的,而传统的静态建模方法论和工具已不能满足需求。DDD通过领域事件和命令出发,进行动态建模,反映变化,简化复杂业务领域,显性化隐式流程和字段,实现业务和技术的统一架构演进。
三、拉通“断层”的策略
传统的需求和开发模式存在断层,DDD通过业务主导的自顶向下设计,拉通业务和编码,提升代码的业务反映能力和准确度。
四、彻底“反腐”的设计
领域模型与数据模型分离,通过防腐层架构设计,实现业务代码与基础设施的解耦,提升领域代码的纯度和生命力。
“反腐”设计的好处:
- 提升业务代码与技术的融合。
- 增强领域代码的复用性和标准化。
五、提升“测维扩”能力
DDD通过优化架构,提升了应用的可维护性、可扩展性和可测试性,解决了传统架构面临的问题,如库升级、服务升级等。
DDD落地案例:
- 爱奇艺DDD实践后,显著降低了开发成本和风险。
六、DDD宏观概念详解
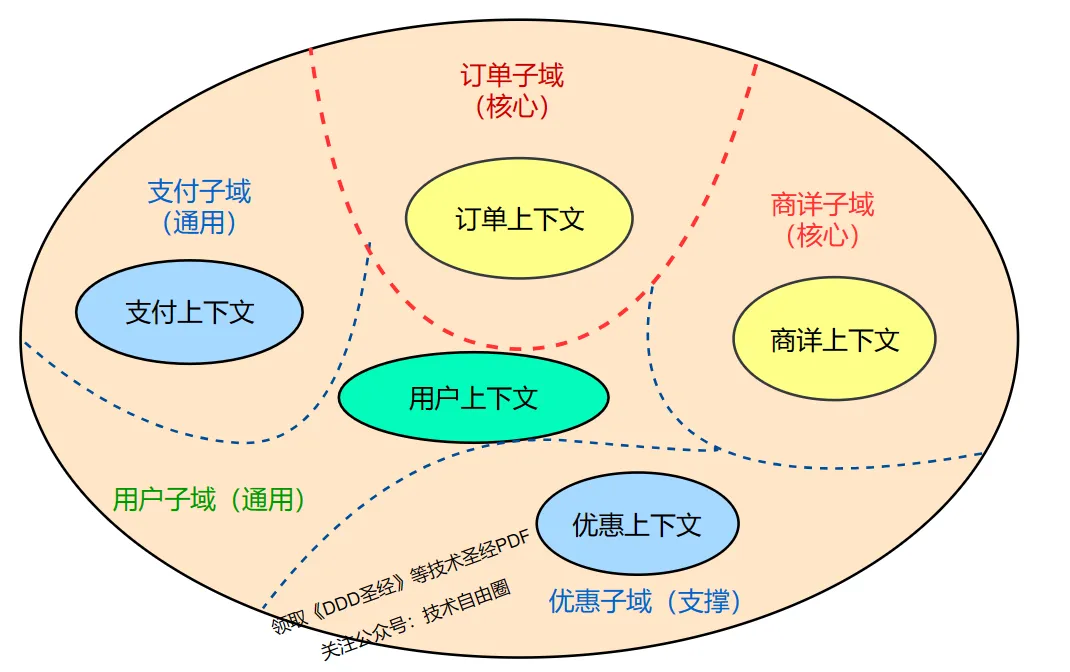
1. 领域与子域
领域指软件的业务范围和逻辑,子域是领域内相互分离的部分,通过接口通信,隐藏内部细节。
2. 限界上下文
限界上下文是子域的边界,内含固定的术语、流程和代号,是领域模型存在的显式边界。
限界上下文包含:
- 实体
- 值对象
- 聚合
- 领域事件
- 领域服务
3. 核心域、支撑域、通用子域
- 核心域:关注的问题空间的业务子域。
- 支撑域:涉及业务但非核心的子域。
- 通用子域:提供数据、接口支持,不涉及具体业务。
核心域的确定是相对的,根据解决问题的需要而定。
总结
DDD作为一种软件设计方法,通过统一思想、动态建模、拉通断层、反腐设计等策略,提升了软件项目的沟通效率、开发质量和可维护性。通过DDD,可以构建出更加健壮、灵活且易于维护的软件系统。
领域驱动设计(DDD)微观概念解析
领域驱动设计(DDD)是一种软件开发方法论,其核心在于构建领域模型并利用分层架构来实现领域逻辑的独立性。下面将对DDD的两个关键概念进行详细解析:
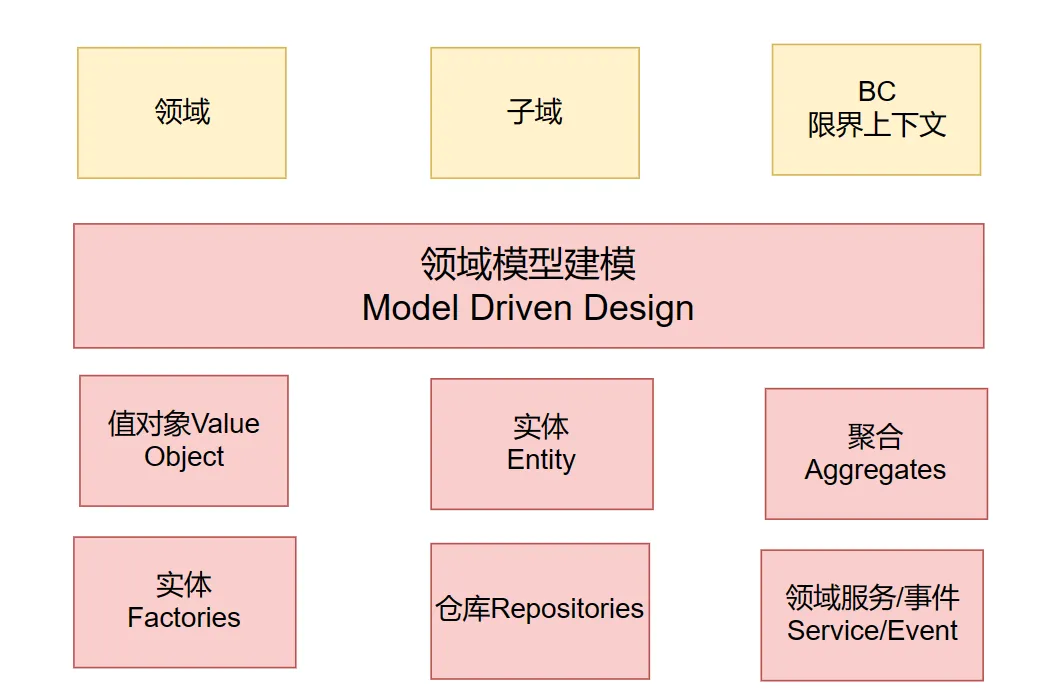
领域模型(Domain Model)
领域模型是将领域知识转化为代码模型的过程,它包括实体(Entity)和值对象(Value Object)两种基本单元。这些模型单元是领域逻辑的载体,封装了业务规则和行为。
实体(Entity)
实体是具有唯一标识符的对象,其生命周期独立于其他对象。它们可以包含属性和行为,并且可以随着时间而变化。
值对象(Value Object)
值对象是描述领域概念的不可变对象,它们通过属性值来定义,而不是通过标识符。值对象通常用于表示领域中的量化数据或概念。
领域服务(Domain Service)
领域服务是执行领域逻辑的无状态操作,它们通常不包含业务状态,而是作为领域模型的补充,处理一些跨实体或值对象的复杂业务逻辑。
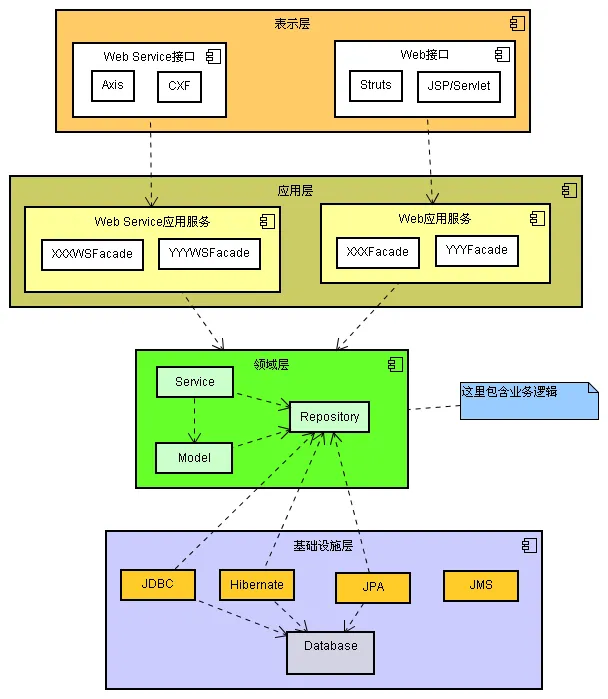
分层架构
分层架构是DDD中的一个关键设计模式,它将应用程序分为多个层次,每一层都有其特定的职责:
- 表示层(Presentation Layer) - 负责处理用户界面和展示逻辑。
- 应用层(Application Layer) - 定义软件要完成的任务,并协调领域层来完成这些任务。
- 领域层(Domain Layer) - 包含业务逻辑和领域模型,是DDD的核心。
- 基础设施层(Infrastructure Layer) - 提供技术能力支持,如数据库访问、消息传递等。 通过这种分层,DDD能够确保领域逻辑的清晰和独立,同时使得系统更加模块化和易于维护。
结论
领域驱动设计通过构建精确的领域模型和采用分层架构,提高了软件的质量和可维护性,使得软件能够更好地反映和服务于其业务领域。
领域驱动设计(DDD)概念解析
实体(Entity)
实体是具有唯一标识的核心领域对象,其唯一性在整个软件生命周期中保持不变。在领域驱动设计(DDD)中,实体不仅包含数据,还包含业务逻辑。实体的可变性体现在其状态和行为上,即使属性发生变化,实体本身仍然是同一个。
特点
- 唯一性:由唯一标识符(ID)保证。
- 可变性:状态和行为的变化不影响其唯一性。
示例
商品实体通过唯一的商品ID标识,无论数据如何变化,ID保持不变。
值对象(Value Object)
值对象是依附于实体的属性集合,用于表达领域中的特定概念。它们没有唯一标识,通过属性值来识别。
特点
- 无唯一性:属性值的集合,不关注唯一性。
- 等值性:属性完全相同则视为相同对象。
示例
用户地址可以作为值对象,包含省市区等属性。
聚合(Aggregate)
聚合是多个实体和值对象的协同工作组织,是数据修改和持久化的基本单元,保证事务一致性。
特点
- 聚合根:聚合内的管理者,代表聚合的入口。
- 一致性:聚合内的对象作为一个整体进行操作。
示例
订单聚合包含订单实体和地址值对象,订单ID作为聚合根。
聚合根(Aggregate Root)
聚合根是聚合的管理者,作为聚合的入口点,负责内部对象的协调和管理。
角色
- 实体:具有属性和行为。
- 管理者:协调聚合内的对象。
- 接口人:实现聚合间的业务协同。
服务(Services)
服务用于协调领域对象之间的关系,并提供操作给客户端。
分类
- 领域服务(Domain Service):处理不属于特定实体或值对象的业务逻辑。
- 应用服务(Application Service):作为展现层与领域层的桥梁,负责业务用例的执行顺序和结果拼装。
特点
- 领域服务:无状态,涉及多个领域对象。
- 应用服务:处理事务、安全等,隐藏领域层复杂性。
领域事件/命令
领域事件表示领域中发生的事件,是领域模型的重要组成部分。
作用
- 触发业务流程。
- 记录领域状态变化。
通过上述概念的解析,可以更好地理解和应用DDD原则,以实现高内聚、低耦合的系统设计。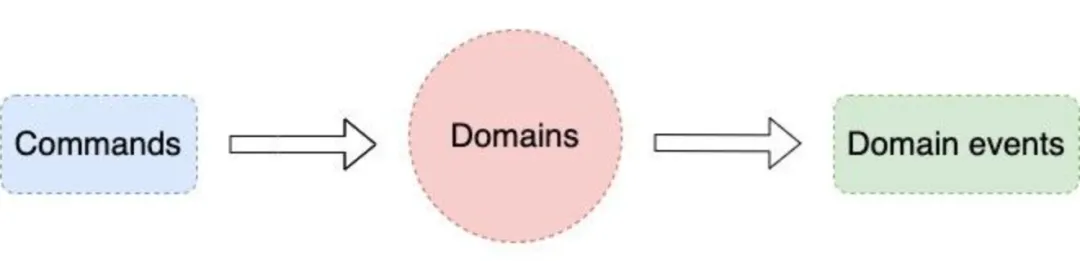
领域事件与DDD设计
领域事件概述
领域事件是程序事件的一种,通常发生在领域模型中,其主要作用是实现领域对象与repository或service的异步解耦。领域事件的触发,可以使得领域对象在不直接依赖于repository或service的情况下,通过事件机制实现业务逻辑的触发和处理。
领域事件的四个关键步骤
- 事件发布:构建并发布具有唯一标识的事件。
- 事件存储:在发布前存储事件,便于后续处理或重试。
- 事件分发:在服务内部直接发布给订阅者,跨服务则需要消息中间件如Kafka、RabbitMQ。
- 事件处理:存储事件后,进行相应的业务逻辑处理。
-
领域事件的应用场景
例如,在用户下订单成功后,系统可以发布一个领域事件,由积分系统和优惠券系统监听并相应地进行积分增长和优惠券赠送。
资源仓储/资源库(Repository)
资源仓储是领域模型与数据模型之间的桥梁,主要用于聚合的持久化和检索。它确保聚合作为一个整体被存取,隔离了领域模型和数据模型,使得开发者可以专注于领域逻辑而无需关心数据的持久化细节。
工厂(Factory)
工厂模式用于封装创建复杂对象或聚合所需的逻辑,隐藏创建对象的细节,简化客户端的创建过程。当对象的创建逻辑复杂或可能变化时,推荐使用工厂模式。
DDD建模理论
尼恩在其著作《DDD学习圣经》中提出了DDD建模的两个阶段和四个标准动作,为领域驱动设计提供了理论指导和实践方法。
DDD建模的两个阶段
- 领域分析:理解和定义业务领域的概念、行为和关系。
- 领域设计:基于分析结果,设计领域模型和架构。
DDD建模的四个标准动作
- 识别领域概念:明确业务中的实体、值对象、聚合等。
- 定义领域行为:确定领域对象的行为和职责。
- 划分领域边界:确定不同领域模型的职责和界限。
- 实现领域交互:设计领域对象之间的交互方式和通信机制。
通过上述理论,尼恩为DDD建模提供了清晰的框架和方法论,帮助开发者更好地理解和实践领域驱动设计。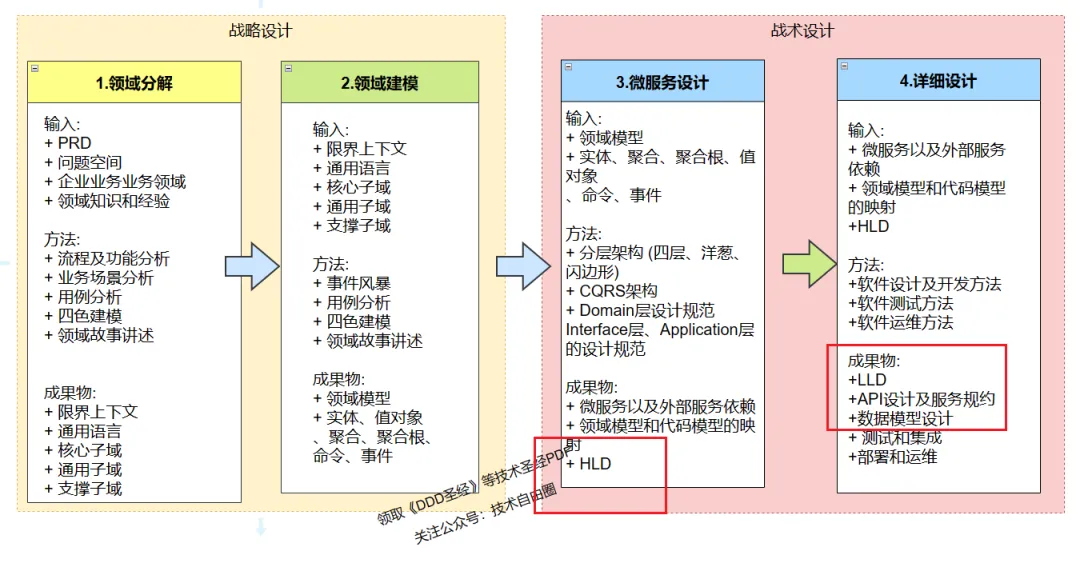
DDD建模的四个标准动作,具体请参见 尼恩《DDD学习圣经》以及配套视频。
DDD的四种模型: 什么是贫血模型?什么是充血模型?
接下来,看看DDD四种模型
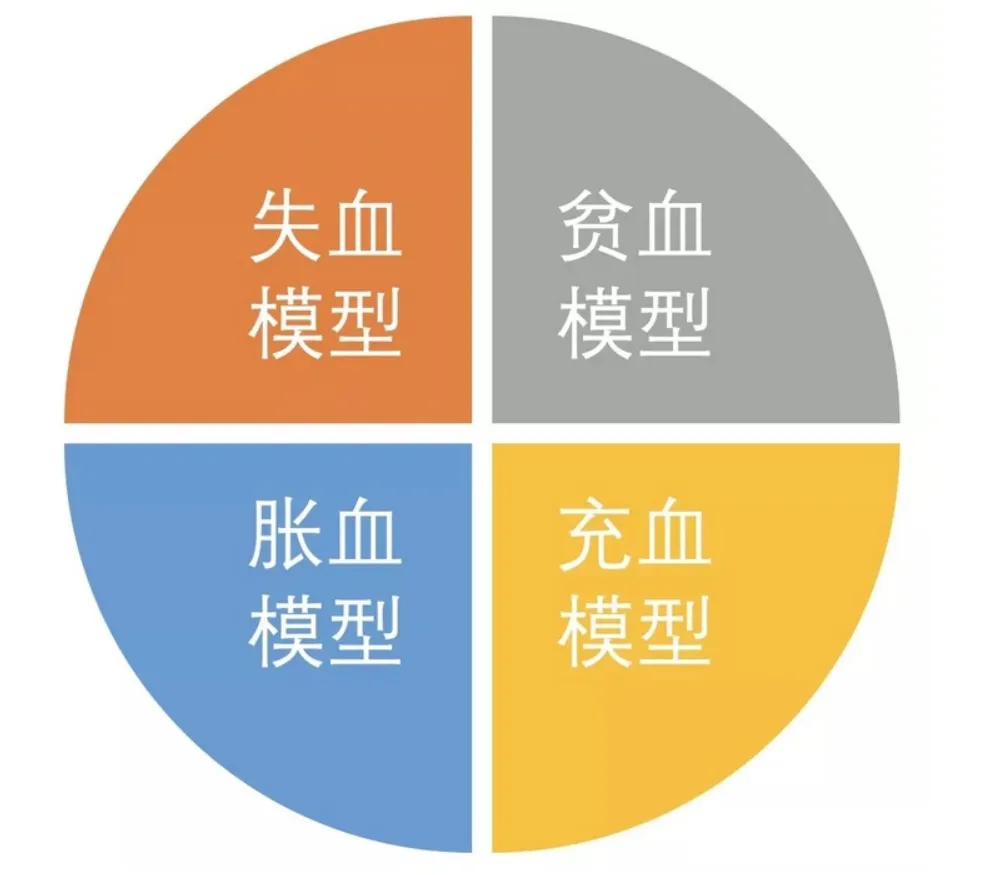
失血模型
领域模型中只有简单的get set方法,是对一个实体最简单的封装,其他所有的业务行为由服务类来完成。
pojo里边光秃秃的,get和set方法都没有
<section>@Data
@ToString
public class User {
private Long id;
private String username;
private String password;
private Integer status;
private Date createdAt;
private Date updatedAt;
private Integer isDeleted;
}
</section>
而且,其他所有的业务行为由服务类来完成,
<section>public class UserService{
public boolean isActive(User user){
return user.getStatus().equals(StatusEnum.ACTIVE.getCode());
}
}
</section>
贫血模型概述
贫血模型(Anemic Domain Model)是一种软件设计模式,它将领域对象简化为只有getter和setter方法的简单数据结构(Plain Old Java Objects,简称POJOs)。这种模型中,领域对象不包含业务逻辑,而是将所有业务逻辑放置在业务逻辑层(Business Logic Layer)中。
领域对象(Domain Object)
领域对象是软件系统中的实体,它们具有属性和行为。在贫血模型中,领域对象通常只包含属性的定义和getter/setter方法,而不包含业务逻辑。例如,一个人可以有姓名、性别、年龄等属性,以及走路、吃饭等行为。
业务逻辑层(Business Logic Layer)
业务逻辑层负责实现业务规则和业务流程。在贫血模型中,这一层包含了所有与领域对象相关的业务逻辑,不包括对象状态变化的逻辑。业务逻辑层通过服务类(Service Classes)来实现领域对象的行为和组合逻辑。
依赖关系
在贫血模型中,领域对象不依赖于持久层(Data Access Layer)。相反,业务逻辑层中的服务类可能会依赖于领域对象的行为。
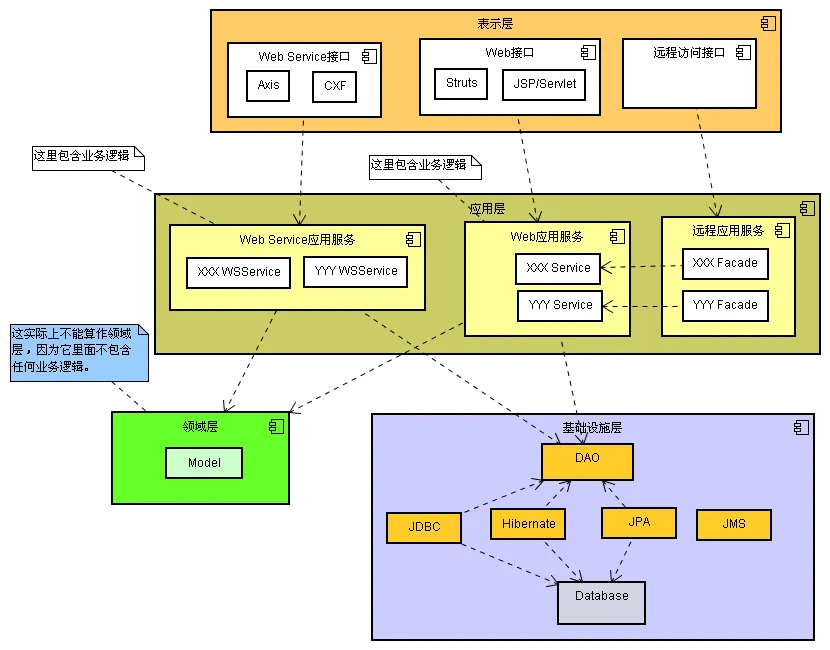
架构层次结构
- 客户端(Client):与用户交互的界面或服务。
- 业务门面服务(Business Facade Service):作为客户端和服务层之间的桥梁,封装业务逻辑层的细节。
- 业务逻辑服务(Business Logic Service):包含业务逻辑,依赖于领域对象的行为。
- 数据访问服务(Data Access Service):负责与数据库交互,实现数据的持久化。
总结
贫血模型通过将业务逻辑与领域对象分离,使得领域对象保持简单,而业务逻辑集中在业务逻辑层。这种分离有助于降低系统的复杂性,提高代码的可维护性和可测试性。
<section>@Data
@ToString
public class User {
private Long id;
private String username;
private String password;
private Integer status;
private Date createdAt;
private Date updatedAt;
private Integer isDeleted;
public boolean isActive(User user){
return user.getStatus().equals(StatusEnum.ACTIVE.getCode());
}
public void setUsername(String username){
return username.trim();
}
}
</section>
贫血模型在失血模型基础之上,领域对象的包含一些状态变化,但是停留在内存层面,不关心数据持久化。
贫血模型所有的业务逻辑都不包含在内而是放在Business Logic层。
 在软件开发中,贫血模型和充血模型是两种常见的架构模式。下面将分别介绍这两种模型的特点和应用。
在软件开发中,贫血模型和充血模型是两种常见的架构模式。下面将分别介绍这两种模型的特点和应用。
贫血模型
贫血模型是一种传统的数据驱动开发方式,其核心特点如下:
- 层次结构清晰:系统分为Client、Business Facade、Business Logic和Data Access Object等多个层次,各层之间保持单向依赖。
- 领域对象作为传输介质:领域对象主要用于数据传输,不影响层次结构的划分。
- Spring框架的应用:在使用Spring框架时,通常采用贫血模型。Domain类仅用于存储数据,而Spring主要负责管理逻辑层的注入和管理。 然而,如果试图在Domain类中加入业务逻辑,将面临以下问题:
- Bean管理复杂性:Spring在构造数据bean时,可能会遇到bean之间的引用问题,导致复杂的嵌套构造器调用。
充血模型
充血模型是在贫血模型的基础上发展而来,其主要特点包括:
- 数据持久化:在负责数据持久化的同时,充血模型还承担了部分业务逻辑的处理。
总结
两种模型各有优缺点,选择哪一种取决于具体的项目需求和开发团队的偏好。在设计系统架构时,应综合考虑模型的特点和适用场景。
<section>@Data
@ToString
public class User {
private Long id;
private String username;
private String password;
private Integer status;
private Date createdAt;
private Date updatedAt;
private Integer isDeleted;
private UserRepository userRepository;
public boolean isActive(User user){
return user.getStatus().equals(StatusEnum.ACTIVE.getCode());
}
public void setUsername(String username){
this.username = username.trim();
userRepository.update(user);
}
}
</section>
充血模型是一种软件架构设计模式,它强调将业务逻辑集中在领域对象(Domain Object)中,而应用服务层(Business Logic)则主要负责事务管理、权限控制等辅助功能。以下是对充血模型层次结构的详细描述:
充血模型层次结构
- 客户端(Client) - 客户端是用户与系统的交互界面,负责发送请求和接收响应。
- 业务门面(Business Facade) - 业务门面作为客户端和业务逻辑之间的接口,它可能包含一些简单的业务逻辑封装,但主要作用是协调不同业务逻辑的调用。
- 业务逻辑层(Business Logic) - 这一层主要负责事务的控制和权限的管理,同时对业务流程进行简单的封装。
- 领域对象(Domain Object) - 领域对象是充血模型的核心,包含了大部分的业务逻辑。它们是具有行为的业务实体,能够独立完成特定的业务任务。
- 数据访问对象(Data Access Object) - 数据访问对象负责与数据库或其他数据存储进行交互,提供数据的读取和写入功能。 这种层次结构的设计使得业务逻辑更加集中和模块化,有助于提高代码的可维护性和可扩展性。
领域驱动设计(DDD)与微服务架构
领域驱动设计(DDD)是一种软件开发方法,它通过创建丰富的领域模型来解决复杂的业务问题。而微服务架构是一种将应用程序作为一组小型服务的架构风格,每个服务运行在其独立的进程中,并通常围绕业务功能构建。
一、DDD与微服务的关系
DDD提供了一套方法论来指导微服务的拆分和设计,帮助开发者更好地理解和建模业务领域,从而实现微服务架构中服务的合理划分。
二、贫血模型与充血模型的比较
2.1 定义
- 贫血模型:业务逻辑通常集中在Service层,领域对象(如Entity和VO/DTO)不包含业务逻辑。
- 充血模型:业务逻辑分布在领域对象中,每个对象都包含其状态和行为,形成自闭环。
2.2 优缺点
- 贫血模型:
- 优点:事务边界清晰,易于理解和维护。
- 缺点:对象状态与行为分离,缺乏面向对象的设计思维。
- 充血模型:
- 优点:面向对象设计,业务逻辑组织清晰,易于复用。
- 缺点:实现复杂,需要深入理解领域模型。
三、DDD实施的挑战与优势
3.1 挑战
- 需要领域专家深入参与,确保模型的准确性。
- 错误的领域模型可能导致项目风险。
3.2 优势
- 提升代码的业务纯度,降低升级工作量。
- 增强代码的可测试性、可维护性和可扩展性。
四、微服务拆分的原则
微服务拆分应遵循以下原则:
- 单一职责原则:每个服务负责一个单一的业务功能。
- 松耦合:服务之间通过定义良好的接口进行通信,避免直接依赖。
- 领域驱动原则:基于业务领域进行服务划分,而非数据或技术。
五、DDD在面试中的应用
在面试中,对DDD的深入理解和实践经验可以展示候选人的技术深度和解决问题的能力。面试官通常会询问:
- DDD的落地经验。
- 对DDD的理解。
- 如何使用DDD设计特定模块。
六、学习资源与案例
尼恩的《DDD学习圣经》及相关文章提供了系统化的DDD学习路径和丰富的实操案例,帮助读者从理论到实践全面掌握DDD。
七、结语
掌握DDD不仅能够帮助开发者在面试中获得优势,更能在实际工作中提升软件质量和开发效率。尼恩的《Java面试宝典》和相关文章是学习DDD的宝贵资源。
考文献 - 《DDD学习圣经》
- 阿里DDD大佬系列文章 - 各种DDD落地案例分析
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1%E5%8F%8A%E5%85%B6%E6%A8%A1%E5%9E%8B%E6%A6%82%E5%BF%B5%E8%A7%A3%E6%9E%90--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


