腾讯开源中文词向量用法介绍 --知识铺
引言
腾讯AI实验室在2021年12月24日推出了其词向量模型的0.2.0版本。这一版本的中文词向量模型在多个方面表现出其独特优势:
- 覆盖面广:模型不仅包含了大量的专业术语和俗语,例如“喀拉喀什河”、“皇帝菜”、“不念僧面念佛面”、“冰火两重天”、“煮酒论英雄”,还覆盖了许多其他模型未包含的词汇。
- 新颖性:模型中融入了近期出现的新词和流行语,如“新冠病毒”、“元宇宙”、“了不起的儿科医生”、“流金岁月”、“凡尔赛文学”和“yyds”。
- 准确性:通过大规模数据和精心设计的训练算法,该模型能够更准确地捕捉和反映中文词语与短语的语义。 想了解更多详情,请访问腾讯AI实验室官网。
下载词向量模型
您可以通过访问下载页面来获取适合您需求的词向量模型。本次发布的模型共有四个版本,您可以根据词嵌入的维度、词汇量大小以及模型文件的大小来选择最适合您的模型。 以下是模型的详细信息:
- 版本:0.2.0
- 维度:200和100
- 词汇量:小型(2,000,000词)和大型(12,287,936词)
- 下载链接:提供了不同大小和维度的模型下载选项
请注意,下载时需选择合适的版本以满足您的具体需求。

下文将以100维、Small、1.8G模型为例进行讲解,下载完成后将得到巨大的文本文件,打开后格式如下图所示。第一行表示词表大小是两百万,每个词的维度是100,从第二行开始表示具体的词语以及对应的100维向量。

使用词向量模型
推荐使用python的gensim库读取使用词向量模型。
- 安装gensim。
|
|
- 载入词向量模型。
|
|
此种方式比较耗时,再第一次载入后,可保存模型的2进制形式,以后可快速加载。
|
|
- 使用词向量模型
|
|
|
|
|
|
|
|
|
|
|
|
高维向量可视化
首先将数据降维到2维或者3维,再利用绘图工具实现可视化。
降维方法采用T-SNE,绘图工具采用matplotlib。
|
|
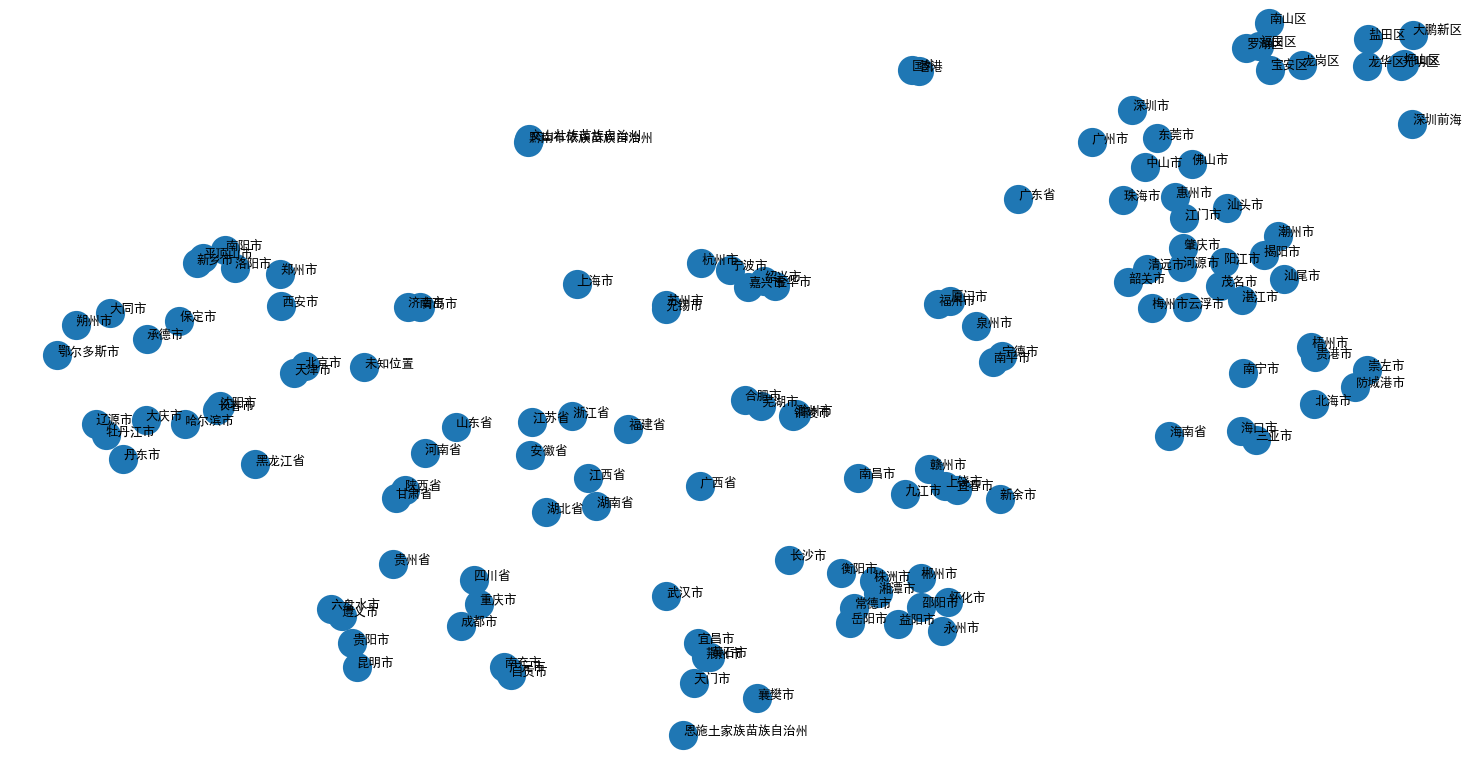
可视化效果如下图所示,省份词聚在一起,各省份内部的市级行政单位也聚在了一起,效果还不错。
参考链接
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E8%85%BE%E8%AE%AF%E5%BC%80%E6%BA%90%E4%B8%AD%E6%96%87%E8%AF%8D%E5%90%91%E9%87%8F%E7%94%A8%E6%B3%95%E4%BB%8B%E7%BB%8D--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


