架构师必备:DDD之落地实践 --知识铺
领域驱动设计(DDD)入门指南
引言在软件开发过程中,我们常常遇到一些棘手的问题,尤其是在维护和扩展大型系统时。传统的三层架构虽然常见,但它存在诸多不足,例如:
- 面向数据而非面向对象的建模方式- 过程编程而非面向对象编程- 服务层代码冗长且难以维护- 代码高耦合,难以应对变化- 业务逻辑难以理解,缺乏文档支持 为了解决这些问题,领域驱动设计(DDD)提供了一种新的思考和设计方法。
领域驱动设计(DDD)概述DDD是一种软件开发方法论,它强调以业务领域为中心进行软件开发。它的核心优势包括:
- 面向领域建模:将现实世界的业务概念直接映射到代码中,使代码更贴近业务需求。- 高内聚:领域逻辑集中在特定的领域模型中,易于理解和维护。- 低耦合:技术细节的变化对业务逻辑的影响较小,有利于构建插件式架构。- 可读性和可维护性:代码结构清晰,易于扩展和移植。
DDD在SpringBoot中的实践将DDD应用于SpringBoot项目,可以遵循以下步骤:
1. 代码分层在DDD中,代码分层是基础。通常包括:
- 基础设施层:与特定技术实现相关的代码,如数据库访问。- 领域层:包含业务逻辑和领域模型。- 应用层:协调领域层和基础设施层,实现应用程序的业务逻辑。- 用户界面层:与用户交互的界面。
2. 领域模型设计设计领域模型时,应关注实体、值对象、聚合、领域服务等概念。
- 实体:具有唯一标识和生命周期的对象。- 值对象:描述领域概念的不可变对象。- 聚合:一组相关对象的集合,由根实体和子实体组成。- 领域服务:执行领域逻辑的服务。
3. 领域事件利用领域事件来处理业务流程中的异步操作或触发其他业务逻辑。
4. 应用服务应用服务作为领域层和用户界面层之间的桥梁,负责调用领域层的方法来完成业务需求。
5. 仓储和工厂仓储用于数据的持久化操作,工厂用于创建复杂的领域对象。
结语DDD不仅仅是一种设计思想,更是一种实践方法。通过DDD,我们可以构建出更易于理解和维护的软件系统。希望本文能够帮助你更好地理解DDD,并将其应用于实际项目中。
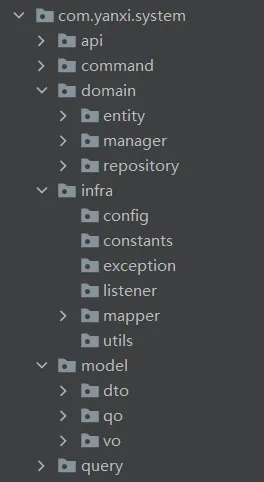
在软件开发过程中,合理的代码分层是提高代码可维护性和可扩展性的关键。以下是对代码分层结构的详细描述:
1. 用户接口层(API层)- 此层负责接收用户的输入并返回响应结果。在项目中,api包承担了这一角色,它相当于传统的controller层,但为了简化命名,我们省略了controller后缀。
2. 应用层- 应用层是业务逻辑的入口,这里我们采用了命令模式,将命令和查询分离成两个不同的包:command和query。如果业务逻辑较为简单,不使用命令模式,可以将它们合并为一个service包。
3. 领域层- 领域层是业务逻辑的核心,domain包在这里扮演了重要角色。我们使用JPA(Java Persistence API)来实现对领域模型的持久化,它对DDD(领域驱动设计)提供了良好的支持。
4. 基础设施层- infra包是基础设施层的代表,这里存放了所有公用组件。如果遵循DIP(依赖倒置原则),那么具体的实现类也应该放在这里。
5. Model模型层- model包用于存放不同层之间传递的对象。经过多次尝试,我们发现将这些对象统一放在一个包下更为合适,这有助于服务间的调用和对象的共用。
层级关系及模型传递- 在多层架构中,每一层都应该只与它的直接上下层交互。模型对象在层与层之间的传递,有助于保持每一层的独立性和职责清晰。
以上就是代码分层的详细说明,希望这有助于您更好地理解项目的结构和设计原则。
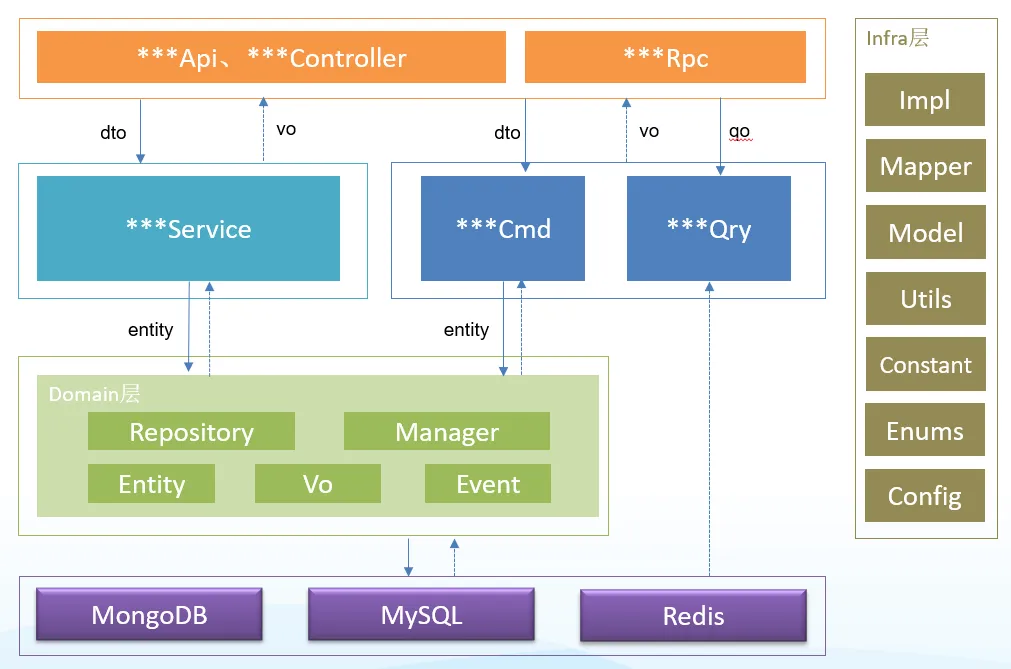
分层及调用关系
3、分层详细说明
-
api包(controller)
@Tag(name = "用户", description = "用户")
@RestController
@RequestMapping(value = "/api/sys-user")
public class SysUserApi extends BaseApi {
@ApiResult
@Operation(summary = "根据ID查询用户")
@GetMapping("/{id}")
public SysUserVo get(@PathVariable Long id) {
return queryExecutor.execute(new SysUserByIdQry(id));
}
@Pagination(total = true)
@ApiResult
@Operation(summary = "分页查询用户")
@GetMapping
public List<SysUserVo> getList(SysUserQo sysUserQo) {
return queryExecutor.execute(new SysUserListQry(sysUserQo));
}
@ApiResult
@Operation(summary = "新增用户")
@PostMapping
public void save(@Valid @RequestBody SysUserDto sysUserDto) {
commandExecutor.execute(new SysUserCommonCmd(sysUserDto));
}
}
在BaseApi中,我们封装了两个命令执行类:queryExecutor和commandExecutor。这样的设计允许我们在调用应用层时,根据需要执行不同的命令,而无需通过@Autowired引入不同的服务。 我们引入了@ApiResult这个自定义注解,它的作用是对返回结果进行统一封装,使得返回的数据格式更加规范和统一。 另外,我们还使用了@Pagination注解,它能够自动将分页参数存入线程变量中。在后续的查询过程中,这些分页参数将被自动获取,并且在返回结果统一封装时,会附加上分页信息,这大大提升了分页操作的便捷性。 在数据传输对象方面,我们定义了Qo(Query Object)作为查询参数对象,Dto(Data Transfer Object)用于增删改等命令参数对象,而Vo(View Object)作为返回对象。这里需要特别注意的是,Entity对象绝对不能直接暴露到这一层,必须先转换为Vo再进行返回,以保证数据的安全性和封装性。 在BaseApi层,每个方法通常只包含一行执行命令的语句,这意味着在大多数情况下,这里不进行复杂的业务逻辑处理。当然,这也有例外的情况,需要根据具体业务需求来决定。
@AllArgsConstructor
public class SysDeptAddCmd implements Command<Void> {
private SysDeptDto sysDeptDto;
@Override
public Void execute(Executor executor) {
// 获取命令的接收者:领域服务
SysDeptManager receiver = executor.getReceiver(SysDeptManager.class);
// 对象模型转换,由DTO转为Entity,使用了MapStruct
SysDept sysDept = SysDeptMapper.INSTANCE.toSysDept(sysDeptDto);
// 使用JPA保存
receiver.save(sysDept);
return null;
}
}
命令模式设计概述
命令模式是一种行为设计模式,它将操作封装成对象,从而允许用户使用不同的请求、队列或日志请求来参数化其他对象,并支持可撤销的操作。以下是命令模式在软件开发中的一些关键实践:
1. 增删改命令层
- 这一层非常薄,主要作为工作组织者,不包含复杂的业务逻辑。
- 它负责调用领域服务和充血对象的方法。
2. 命令模式实现
- 通过实现自定义的
Command接口,接口中的泛型定义了命令执行的返回值类型。
3. 参数接收方式- 使用属性和构造方法接收参数,可以利用Lombok注解简化代码。
4. 单一职责原则- 每个命令类中只包含一个execute方法,虽然这可能导致命令类数量增多,但符合单一职责原则。
5. 领域服务获取- 通过executor.getReceiver方法来获取对应的领域服务(例如manager)。
6. DTO与领域层的关系- DTO(数据传输对象)不应直接作用于领域层,需要先转换为领域实体(Entity)。
- 转换过程中推荐使用MapStruct工具,后续将详细介绍。
7. query包- 此包可能包含与查询相关的命令和处理逻辑,但具体内容未在原始信息中提及。
以上概述了命令模式在实际开发中的应用,包括其结构、实现方式以及与领域服务的交互。
@AllArgsConstructor
public class SysDeptByIdQry extends CommonQry<SysDeptVo> {
private Long id;
@Override
public SysDeptVo execute(Executor executor) {
if (id == null) {
throw new BusinessException("部门ID不能为空");
}
QSysDept sysDept = QSysDept.sysDept;
return queryFactory.select(this.fields())
.from(sysDept)
.where(sysDept.deleted.eq(false), sysDept.id.eq(id))
.fetchOne();
}
/**
* 部门VO映射
*
* @return QBean<SysDeptVo>
*/
public static QBean<SysDeptVo> fields() {
QSysDept sysDept = QSysDept.sysDept;
return Projections.fields(
SysDeptVo.class,
sysDept.deptName,
sysDept.orderNum,
sysDept.id
);
}
}
在软件开发过程中,采用领域驱动设计(DDD)模式可以显著提升业务逻辑的表达力和代码的维护性。以下是对DDD实践的一些总结和心得体会:
命令模式与QueryDSL的使用1. 命令模式:基于自定义的CommonQry基类实现,该基类实现了Command接口,并封装了分页方法。使用泛型指定返回值类型,以确保类型安全。2. QueryDSL:由于JPA在处理复杂查询时的局限性,QueryDSL提供了一种更为灵活和强大的查询构建方式。以下是一个QueryDSL的基本使用示例。
domain包的设计要点1. Entity类与数据库表:Entity类自动映射到数据库表,维护Entity类以屏蔽数据库层面的复杂性。2. 关系映射注解:根据业务需求,灵活使用@OneToMany、@OneToOne等JPA注解。3. 聚合根设计:聚合根不宜过大,通常一个聚合根包含一个实体,避免过度设计。4. 面向对象设计:避免使用贫血模型,将业务逻辑封装在领域对象中,不将repository类直接放入领域对象。5. 领域服务:业务逻辑应集中在领域服务(manager)中,通过抽象和提取方法以供应用层调用。6. 领域事件:适当使用领域事件,利用JPA的@DomainEvents注解在Entity中触发事件。
心得体会1. DDD的优势:通过DDD,可以更深入地理解业务,使代码更好地反映业务需求。2. 代码设计原则:编写低耦合、符合单一职责、开闭原则的代码,带来愉悦的编程体验。3. 前期投入:虽然DDD在初期可能需要更多的代码量和开发投入,但考虑到系统的可维护性和扩展性,这种投入是值得的。
投入的具体方面- 领域划分:合理划分业务领域,明确领域边界。- 实体设计:精心设计Entity类,确保其符合业务需求。- 数据对象:创建大量的DTO、VO等数据对象,以支持不同层级间的数据传输。- 数据转换:实现数据对象之间的转换逻辑,确保数据的一致性和正确性。- 命令类:定义命令类以封装业务操作,提高代码的可读性和可维护性。
尽管DDD在初期可能会增加开发工作量,但对于中等复杂度以上的系统,这种设计方法能够带来长期的益处。
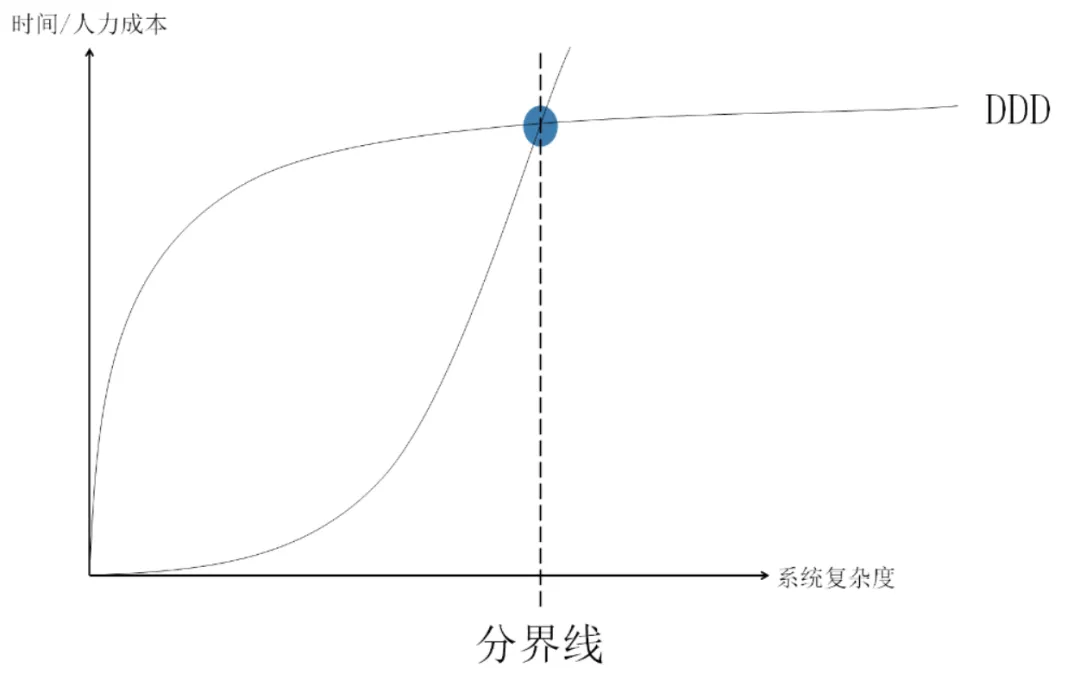
小结
以上简单介绍了下我对DDD的理解和实践,并通过实际的代码展现了如何在SpringBoot中应用DDD,希望能为大家提供一个思路。
受篇幅限制,部分说明可能并不是很详细,大家如果有问题可留言。
写在最后
欢迎加入Java技术指北读者交流群,聊天学习摸鱼为主,不定时会分享一些技术要点和优质学习资源,有一群有趣有料的小伙伴在等你哦!进群方式:公众号后台回复 888 ,按提示操作即可进群。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E6%9E%B6%E6%9E%84%E5%B8%88%E5%BF%85%E5%A4%87DDD%E4%B9%8B%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


