大白话讲解Word2Vec原理 --知识铺
词向量
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
在自然语言处理中,我们经常需要将文本数据转换为机器学习模型能够理解的数值形式。One-Hot 编码是一种常见的转换方法,它通过将每个词或实体转换为一个二进制向量来实现。然而,One-Hot 编码存在一些局限性。
One-Hot 编码的问题
- 随机编码:One-Hot 编码是随机的,这使得向量之间相互独立,无法反映出实体之间的潜在关联。
- 维度灾难:随着语料库中词汇数量的增加,向量的维度也会随之增加,导致维度过高,计算复杂度大。
Vector Representations 的优势Vector Representations,如 Word2Vec,提供了一种替代方案,它能够将 One-Hot 编码转换为低维度的连续值向量。这种转换具有以下优点:
- 稠密向量:转换后的向量是稠密的,而不是稀疏的。
- 语义关联:意思相近的词会被映射到向量空间中相近的位置,从而反映出实体之间的关联。
降维与可视化通过主成分分析(PCA)等降维技术,我们可以将嵌入后的高维向量转换为低维向量,然后进行可视化。这样,我们不仅能够减少计算复杂度,还能够直观地展示城市之间的相对位置关系。
如果将城市名称的嵌入向量通过PCA降维后进行可视化,我们可能会得到如下的展示效果:城市名称在二维或三维空间中被展示出来,相近的城市在向量空间中的位置也相近。
结论使用 Vector Representations 替代 One-Hot 编码,不仅可以解决维度灾难问题,还可以揭示实体之间的内在联系,为自然语言处理任务提供了更丰富的语义信息。

在对城市地理和地位关系的分析中,我们发现华盛顿和纽约在地理位置上相近,而北京和上海也表现出类似的聚集现象。更有趣的是,北京到上海的距离与华盛顿到纽约的距离相差无几,这表明模型不仅捕捉到了城市的地理位置,还理解了它们在社会经济结构中的地位。
模型解析
word2vec模型可以被看作是神经网络的简化版本。它通过学习词汇之间的相似性来构建词向量,从而在数学空间中表达词汇的语义关系。
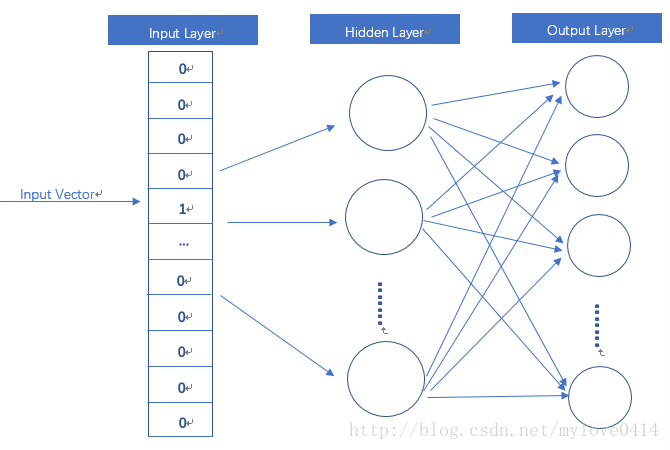
在神经网络中,One-Hot Vector 是一种常用的编码方式,它能够将离散的类别数据转换为数值型数据,便于神经网络进行处理。在本例中,输入层(Input Layer)采用 One-Hot Vector 作为输入数据的表示形式。
隐藏层(Hidden Layer)在本模型中不使用激活函数,即所有的单元都是线性的。这意味着隐藏层的输出是输入数据的线性变换。
输出层(Output Layer)的维度与输入层相同,并且采用 Softmax 回归作为激活函数。Softmax 函数可以将输出层的输出转换为概率分布,使得每个类别的输出值都在 0 到 1 之间,并且所有类别的输出值之和为 1。
在这种模型中,我们所关注的密集向量(dense vector)实际上是隐藏层的输出。有时,人们会将输入层和隐藏层之间的权重称为密集向量,实际上这两者是相同的概念。
模型结构概述:
- 输入层:使用 One-Hot Vector 编码。
- 隐藏层:无激活函数,线性单元。
- 输出层:维度与输入层相同,Softmax 回归。
- 密集向量:隐藏层输出,等同于输入层与隐藏层间的权重矩阵。

CBOW与Skip-Gram模式
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。
这里假设滑窗尺寸为1(滑窗尺寸……这个……不懂自己google吧-_-|||)
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
训练优化
额,到这里,你可能会注意到,这个训练过程的参数规模非常巨大。假设语料库中有30000个不同的单词,hidden layer取128,word2vec两个权值矩阵维度都是[30000,128],在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。而且,你需要大量的训练数据来调整许多权重,避免过度拟合。数以百万计的重量数十亿倍的训练样本意味着训练这个模型将是一个野兽。
一般来说,有Hierarchical Softmax、Negative Sampling等方式来解决。
推荐点其他word2vec学习资料吧
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E5%A4%A7%E7%99%BD%E8%AF%9D%E8%AE%B2%E8%A7%A3word2vec%E5%88%B0%E5%BA%95%E5%9C%A8%E5%81%9A%E4%BA%9B%E4%BB%80%E4%B9%88--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


