ABP领域驱动设计中的聚合和聚合根最佳实践 --知识铺
前言
在上一篇文章基于ABP落地领域驱动设计-01.全景图中,我们概述了领域驱动设计(DDD)的理论和解决方案,以及ABP Framework在项目中的应用。本文将深入探讨DDD和ABP Framework的核心技术,特别是聚合和聚合根的最佳实践和原则。
领域对象的重要性
领域对象是DDD的核心组成部分,我们将从聚合和聚合根开始,逐步分析其最佳实践和规则。考虑到内容的丰富性,我们将分多个章节进行详细讨论。
业务场景引入
为了更好地理解聚合和聚合根的概念,我们引入了GitHub的一些概念,例如Issue、Repository、Label和User。这些概念将帮助我们构建业务场景,并展示聚合、聚合根、实体和值对象之间的关系。
聚合和聚合根原则
聚合是DDD中的一个关键概念,它定义了一组相关对象的边界,确保数据的一致性和完整性。聚合根是聚合中的核心对象,负责管理聚合内的对象和业务逻辑。
聚合根的最佳实践
- 只通过ID引用其他聚合:保持聚合的独立性和封装性。
- 用于EF Core和关系型数据库:探讨如何在EF Core框架下实现聚合根。
- 保持聚合根足够小:避免过度复杂的聚合结构。
- 聚合根/实体中的主键:讨论主键在聚合根中的作用。
- 聚合根/实体构造函数:构造函数在聚合根中的重要性。
- 业务逻辑和实体中的异常处理:如何合理处理业务逻辑中的异常。
- 实体中业务逻辑需要用到外部服务:当实体逻辑需要外部服务时的实践方法。
学习资源
为了帮助读者更好地学习和实施DDD,我们提供了以下资源:
-
ABP Framework 研习社(QQ群:726299208):一个分享学习经验和实施DDD经验的社区。
-
示例源码、电子书共享:提供实践DDD时的参考资源。
结语
本文重点讨论了聚合和聚合根的最佳实践和原则,希望能够帮助读者深入理解DDD的核心概念,并在实际项目中应用这些原则。
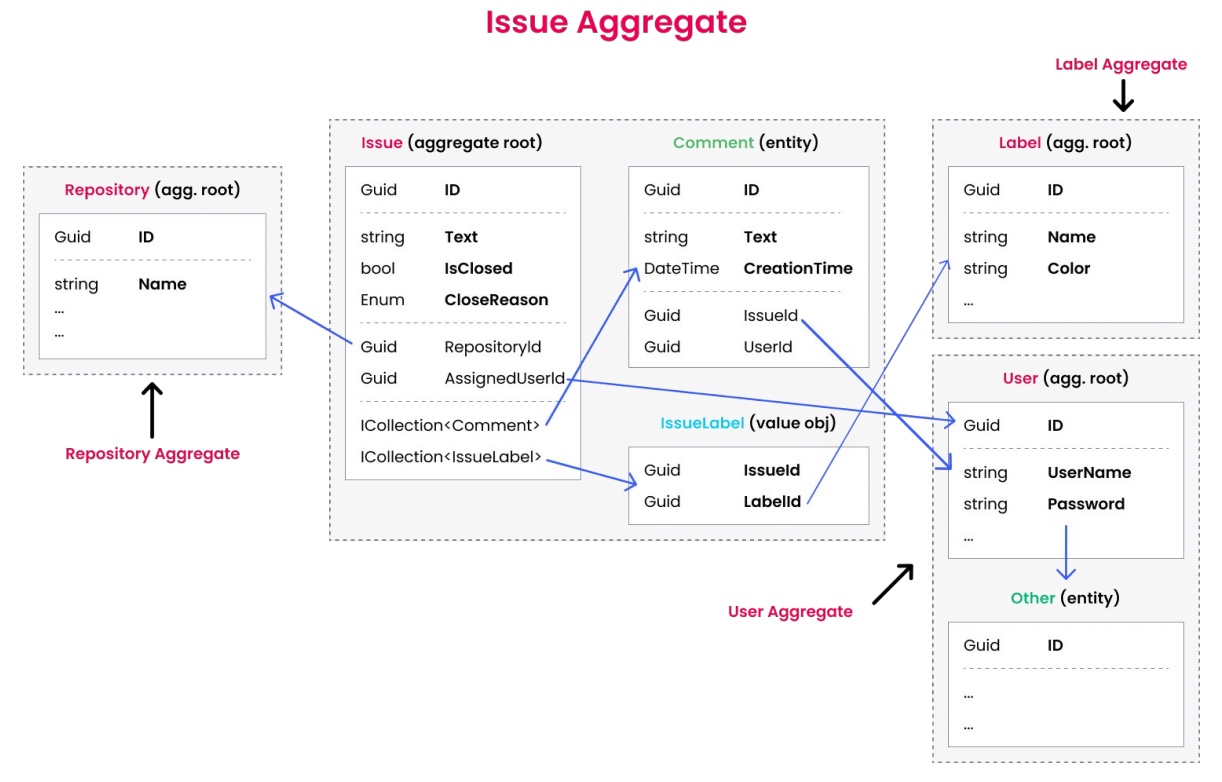
Issue 聚合是由 Issue(聚合根)、Comment(实体)和 IssuelLabel(值对象)组成的集合。因为其他聚合相对简单,所以我们重点分析 Issue 聚合。

聚合设计原则
聚合是领域驱动设计(DDD)中的核心概念之一,它由一系列对象组成,包括实体和值对象,这些对象通过聚合根紧密绑定在一起。本节将详细介绍聚合的相关最佳实践和原则。
聚合根与子集合实体
在DDD中,我们通常使用实体这个术语来指代聚合根和子集合实体,除非需要特别区分它们。
聚合根原则
- 业务规则实现:实体负责实现与其属性相关的业务规则。
- 状态管理:聚合根还负责管理其子集合实体的状态。
- 完整性与有效性:聚合应通过领域规则和规约来保持自身的完整性和有效性。与数据传输对象(DTO)不同,实体具有实现业务逻辑的方法。业务规则应尽可能在实体中实现。
单个单元原则
聚合及其所有子集合作为一个单一的单元被检索和保存。例如,向Issue添加Comment的过程如下:
- 从数据库中获取包含所有子集合的Issue,如Comments和IssueLabels。
- 在Issue类中调用方法添加一个新的Comment,例如
Issue.AddComment(...)。 - 将Issue(包括所有子集合)作为一个单一的数据库更新操作保存到数据库。
业务规则的实现
对于习惯使用EF Core和关系数据的开发者来说,这种模式可能看起来有些奇怪。为什么不直接执行一个SQL插入命令,而要查询所有数据呢?答案是,我们需要在代码中实现业务规则,以保持数据的一致性和完整性。例如,如果有一条业务规则是用户不能对锁定的Issue进行评论,我们如何在不检索数据库数据的情况下检查Issue的锁定状态呢?
MongoDB开发者的视角
MongoDB开发者会发现这个规则非常自然,因为在MongoDB中,一个聚合对象(包括子集合)被保存在一个集合中,而在关系型数据库中,它被分布在几个表中。因此,当你获取一个聚合时,所有的子集合已经作为查询的一部分被检索出来了。
ABP框架的支持
ABP框架有助于在你的应用程序中实现聚合原则,确保业务逻辑的一致性和数据的完整性。
示例:添加Comment到Issue
以下是添加Comment到Issue的示例代码:
csharp// 假设Issue和Comment是已经定义好的类Issue issue = database.GetIssueById(issueId);Comment newComment = new Comment(...);issue.AddComment(newComment);database.SaveIssue(issue);
在这个示例中,我们首先从数据库中获取Issue对象及其所有子集合,然后调用Issue类中的方法来添加一个新的Comment,最后将整个Issue对象保存回数据库,确保所有更改都是原子性的。
|
|
EF Core 与 MongoDB 的聚合配置
1. 聚合方法配置_issueRepository.GetAsync(...) 方法用于从数据库中检索单个 Issue 对象,并默认包含所有子集合。在 MongoDB 中,此操作是直接可用的。然而,使用 EF Core 时,需要进行额外的配置来实现聚合与数据库映射。配置完成后,EF Core 仓储实现将自动处理这些操作。此外,该方法还接受一个可选参数 includeDetails,当设置为 false 时,可以禁用包含子集合对象的行为。
2. 添加评论Issue.AddComment(...) 方法接受 userId 和 text 两个参数,分别代表用户ID和评论内容。该方法将评论添加到 Issue 的 Comments 集合中,并执行必要的业务逻辑验证。
3. 更新数据库使用 _issueRepository.UpdateAsync(...) 保存更改到数据库。EF Core 提供了变更跟踪功能,这意味着在大多数情况下,不需要显式调用 UpdateAsync 方法,因为 ABP 工作单元系统会在应用服务方法执行完毕后自动调用 DbContext.SaveChanges()。但是,如果使用 MongoDB 数据库,则需要显式更新已更改的实体。
4. 编写数据库无关代码要编写与数据库提供程序无关的代码,应始终为要更改的实体调用 UpdateAsync() 方法。
事务边界原则
聚合通常被视为一个事务边界。如果用例仅涉及单个聚合,并且所有更改都作为原子操作保存,则无需显式使用数据库事务。
5. 处理多聚合用例当用例需要更改多个聚合实例时,需要使用数据库事务来确保更新操作的原子性和数据一致性。ABP 框架通过应用程序服务方法显式使用数据库事务,每个方法都是一个工作单元。
可序列化原则
聚合应是可序列化的,并能在网络上作为单个单元传输。例如,MongoDB 将聚合序列化为 Json 文档并保存到数据库中,同时从数据库中读取的 Json 数据也会被反序列化。
6. 领域驱动设计实践尽管在使用关系数据库和 ORM 时,这可能不是必需的,但这是领域驱动设计中的一个重要实践。
聚合和聚合根最佳实践
以下是一些最佳实践,以确保实现上述原则:
7. 通过ID引用其他聚合一个聚合应仅通过其他聚合的 ID 引用它们。这意味着不应添加导航属性到其他聚合。
- 这有助于实现可序列化原则。
- 它防止了不同聚合之间的相互操作,以及聚合业务逻辑的泄露。
示例考虑两个聚合根:GitRepository 和 Issue。它们应仅通过彼此的 ID 进行引用,以保持聚合的独立性和封装性。
|
|
在领域驱动设计(DDD)中,聚合是表示领域模型中一组相关对象的集合。每个聚合都有一个根实体,称为聚合根,它负责管理聚合内的一致性和完整性。以下是对聚合设计的一些要点和建议:
- 聚合根与子实体的关系:
GitRepository作为聚合根,不应直接包含Issue集合,因为它们属于不同的聚合。Issue也不应设置导航属性指向GitRepository,以保持聚合的独立性。
- 数据关联方式:
Issue可以通过RepositoryId与GitRepository建立关联,这种方式是正确的。
- 数据库查询:
- 当需要关联
GitRepository时,可以通过RepositoryId从数据库中查询。
- EF Core 和关系型数据库:
- 在使用 EF Core 和关系型数据库时,开发者可能会发现上述聚合规则的限制性,因为 EF Core 能够处理数据库的读写操作。
- 领域复杂性与潜在问题:
- 尽管如此,我们认为遵循聚合规则有助于降低领域的复杂性并防止潜在问题,因此强烈推荐实施。
- 数据库独立性原则:
- 如果认为可以忽略聚合规则,请参考基于ABP落地领域驱动设计-01.全景图中关于数据库独立性原则的讨论。
- 保持聚合根的简洁性:
- 聚合根应保持简单而小,因为它们将作为一个单元被加载和保存。过大的聚合根可能导致性能问题。
- 示例:
- 以下是一个示例,展示了如何根据聚合的设计原则组织代码和数据结构。 以上内容提供了对聚合设计原则的概述,以及如何在实际开发中应用这些原则。
|
|
在设计软件系统时,聚合(Aggregate)是一种重要的概念,它帮助我们组织和管理数据。以下是对聚合以及聚合根的理解和应用要点:
聚合的定义和应用
- 聚合 是一组相关对象的集合,它们作为一个单一的数据单元被操作以保证数据的一致性。例如,一个Role聚合可能包含多个UserRole值对象,用以跟踪哪些用户被分配了该角色。
聚合的性能问题
- 当一个角色被分配给大量用户时,直接加载所有关联的用户数据会导致严重的性能问题。因此,聚合设计需要考虑性能和数据量。
聚合和非关系型数据库的挑战
- 使用非关系型数据库,如MongoDB时,如果Role和User都维护对方的关系列表,会导致数据一致性难以维护。例如,添加一个新角色到User的Roles列表时,也需要更新Role的Users列表。
确定聚合边界的考虑因素
- 关联性:象是否经常一起使用。
- 性能:查询、加载/保存的效率和内存消耗。
- 数据一致性:保证数据的完整性和一致性。
实际聚合设计原则
- 大多数聚合根不包含子集合。
- 子集合的条目数建议不超过100-150条。如果预计条目数会更多,应考虑将子集合作为独立的聚合根。
聚合根/实体的主键
- 聚合根通常有一个ID属性作为其唯一标识符,推荐使用Guid作为聚合根的主键。
- 聚合内的实体可以使用复合主键。
示例:聚合根和实体
- 以下是一个聚合根和其内部实体的示例结构,展示了如何组织数据以满足上述原则。 示例结构:
|
|
Organization包含Guid类型主键IdOrganizationUser是Organization中的子集合,有复合主键:OrganizationId和UserId。
这并不意味着子集合实体应该总是有复合主键,只有当需要时设置;通常是单一的ID属性。
复合主键实际上是关系型数据库的一个概念,因为子集合实体有自己的表,需要一个主键。另一方面,例如:在MongoDB中,你根本不需要为子集合实体定义主键,因为它们是作为聚合根的一部分来存储的。
聚合根/实体构造函数
构造函数是实体的生命周期开始的地方。一个设计良好的构造函数,担负以下职责:
- 获取所需的实体属性参数,来创建一个有效的实体。应该强制只传递必要的参数,并可以将非必要的属性作为可选参数。
- 检查参数的有效性。
- 初始化子集合。
示例:Issue(聚合根)构造函数
|
|
实体类设计要点
构造函数设计
- 实体类
Issue通过构造函数接收必要的属性值,以创建有效的实体实例。 - 构造函数中进行输入参数的有效性验证,例如使用
Check.NotNullOrWhiteSpace(...)确保非空字符串,否则抛出ArgumentException异常。 - 子集合如
Labels集合的初始化,防止空引用异常。 - 构造函数向基类传递
id参数,不生成Guid,而是通过服务传递。
ORM与无参构造函数
- ORM框架需要无参构造函数,应将其设为私有以避免误用。
实体属性访问与方法
- 示例代码强调了构造函数中对
Title属性的非空验证,但未在属性设置器中实现。 - 为保持实体的完整性和有效性,应将属性设置为私有
private。 - 通过定义公共方法来操作属性,以在设置属性时执行必要的逻辑。
示例:通过方法修改属性
- 展示如何通过公共方法对属性进行修改和验证。
总结
- 通过上述设计,确保了实体类的健壮性和数据的一致性。
|
|
RepositoryId设置器设置为私有private,因为 Issue 不能将 Issue 移动到另一个 Repository 中,该属性创建之后无需更改。Title设置器设置为私有,当需要更改时,可以使用SetTitle方法,这是一种可控的方式。Text和AssignedUserId都有公共设置器,因为这两个字段并没有约束,可以是null或任何值。我们认为没有必要定义单独的方法来设置它们。如果以后需要,可以添加更改方法并将其设置器设置为私有。领域层是内部项目,并不会暴露给客户端使用,所以这种更改不会有问题。IsClosed和IssueCloseReason是成对修改的属性,分别定义Close和ReOpen方法一起修改他们。通过这种方式,可以防止在没有任何理由的情况下关闭一个问题。
业务逻辑和实体中的异常处理
当你在实体中进行验证和实现业务逻辑,经常需要管理异常:
- 创建特定领域异常。
- 必要时在实体方法中抛出这些异常。
示例:
|
|
这里有两个业务规则:
- 锁定的
Issue不能重新打开 - 不能锁定一个关闭的
Issue
Issue 类在这些业务规则中抛出异常 IssueStateException 。
|
|
在开发过程中,异常处理是一个关键环节,它关系到用户体验和系统稳定性。以下是对异常处理的几点讨论:
1. 终端用户异常展示
- 是否展示异常:在某些情况下,向终端用户展示异常信息是必要的,尤其是当异常信息有助于用户理解问题所在时。
- 异常信息本地化:实现本地化异常消息可以通过多种方式,例如使用资源文件或配置中心来存储多语言的异常信息,然后在异常发生时根据用户的语言偏好进行选择。
2. Web 应用程序或 HTTP API 异常处理
- HTTP状态码:对于Web应用程序或HTTP API,合适的HTTP状态码可以向客户端明确表示请求的状态。例如:
400 Bad Request:客户端请求有语法错误,服务器无法理解。401 Unauthorized:请求需要用户的身份验证。403 Forbidden:服务器理解请求客户端的请求,但是拒绝执行此请求。404 Not Found:服务器上没有找到请求的资源。500 Internal Server Error:服务器内部错误,无法完成请求。
3. ABP框架的异常处理系统
- ABP框架提供了一套完善的异常处理机制,可以方便开发者对异常进行捕获、记录和反馈。
示例:业务异常的抛出在ABP框架中,业务异常可以通过特定的方式抛出,以便框架能够识别并进行相应的处理。具体的实现方法会根据框架的版本和配置有所不同。
结论异常处理不仅仅是技术问题,更是用户体验的一部分。合理地处理和反馈异常,可以提升系统的健壮性和用户的满意度。
|
|
在ABP框架中,IssueStateException 类是继承自 BusinessException 类的一个异常类型。当系统在处理请求时遇到禁用状态,框架默认会返回 403 HTTP 状态码;而当发生内部错误时,则会返回 500 HTTP 状态码。
code 属性在异常类中扮演着重要角色,它用作本地化资源文件中的一个键,通过这个键可以检索到相应的本地化消息。
接下来,我们可以对 ReOpen 方法进行修改,以适应特定的业务逻辑需求。具体修改内容如下:
- 首先,确保
ReOpen方法能够正确处理传入的参数,并进行必要的验证。 - 接着,根据业务规则,实现方法的业务逻辑,确保在方法执行过程中能够妥善处理各种异常情况。
- 最后,根据方法执行的结果,返回相应的状态码和消息,以便于前端进行相应的处理。
|
|
建议:使用常量代替魔术字符串
"IssueTracking:CanNotOpenLockedIssue"。
然后在本地化资源中添加一个条目,如下所示:
|
|
在软件开发过程中,异常处理是一个重要的环节。当异常发生时,ABP框架能够自动使用本地化消息向用户显示错误信息,这基于用户的当前语言环境。例如,如果遇到一个异常,并且其异常代码为’IssueTracking:CanNotOpenLockedIssue’,这个代码会被发送到客户端,使得客户端能够以编程方式处理这个错误情况。 在设计实体(Entity)时,如果业务逻辑仅依赖于实体本身的属性,实现起来相对简单。然而,如果业务逻辑需要访问数据库或使用其他服务,而这些服务通常应该通过依赖注入(Dependency Injection)获得,这就带来了一些挑战。因为实体本身不能注入服务。解决这个问题有两种方法:
- 将外部依赖项作为参数传递给实体方法,然后在方法内部实现业务逻辑。
- 创建一个领域服务(Domain Service)来处理复杂的业务逻辑。 领域服务的概念将在后续内容中介绍。现在,让我们先看看如何在实体中实现业务逻辑。以下是一个示例: 业务规则示例:一个用户不能同时分配超过3个未解决的问题。 在实现这个业务规则时,我们可以通过在用户实体中添加一个方法来检查用户是否已经分配了超过3个未解决问题。如果超过了这个数量,我们可以抛出一个异常或返回一个错误信息。
|
|
在软件开发过程中,实现业务逻辑的方式多种多样。本文将探讨一种特定方法,分析其优点和潜在问题,并提出改进建议。
业务逻辑实现方法
业务逻辑的实现通常依赖于实体类和相关服务。以下是实现业务逻辑的一个例子:
-
私有属性设置:
AssignedUserId属性的设置器被设置为私有,以确保其值只能通过特定的方法进行修改。 -
参数验证:
AssignToAsync方法接收一个AppUser实体,确保传递的user.Id是一个有效的用户标识,而不是任意值。 -
服务依赖:
IUserIssueService服务用于获取分配给用户的问题数量,并根据业务规则进行判断,如果规则不满足则抛出异常。
存在的问题
尽管这种方法实现了业务逻辑,但也存在一些问题:
-
实体复杂性:实体类因依赖外部服务而变得复杂。
-
使用难度:用方法时需要注入
IUserIssueService服务,增加了使用难度。
改进建议
为了解决上述问题,可以考虑以下改进措施:
-
减少实体依赖:尽量减少实体类对外部服务的依赖,使实体更加简洁。
-
服务抽象化:将服务逻辑抽象化,通过接口或抽象类来定义服务,降低直接依赖。
学习资源
我们将继续发布关于 DDD(领域驱动设计) 和 ABP Framework 的技术文章,涵盖核心构件实现和综合案例。
ABP Framework 研习社
-
QQ群:726299208
-
专注:ABP Framework 学习和 DDD 实施经验分享。
-
资源:提供示例源码和电子书共享。 欢迎对 ABP Framework 和 DDD 感兴趣的开发者加入我们的社区,共同学习和成长。

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E5%9F%BA%E4%BA%8EABP%E8%90%BD%E5%9C%B0%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1-02.%E8%81%9A%E5%90%88%E5%92%8C%E8%81%9A%E5%90%88%E6%A0%B9%E7%9A%84%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5%E5%92%8C%E5%8E%9F%E5%88%99_abp-%E8%81%9A%E5%90%88%E6%A0%B9--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


