AI套件与向量数据库结合打造知识问答服务教程 --知识铺
如何使用腾讯云向量数据库构建知识库问答服务
概述本教程详细介绍了如何利用腾讯云向量数据库(Tencent Cloud VectorDB)结合大型语言模型(LLM)进行一站式文档检索和相似性检索,从而构建专属领域的知识库问答服务。
背景大型语言模型(LLM)是自然语言处理(NLP)服务的核心,具有强大的文本处理能力。尽管LLM涵盖了广泛的通用知识,但在特定领域知识的应用上仍有局限。为了弥补这一不足,我们可以通过特定的提示和领域知识的注入,引导LLM更准确地理解并回答特定领域的问题。
实现步骤
- 知识库构建:将特定领域的文档上传至腾讯云向量数据库,进行文件拆分和向量化处理。
- 数据存储:将处理后的向量化数据存储在数据库中,以便于后续检索。
- 向量检索:利用腾讯云向量数据库的Embedding功能,将用户的问题转化为向量,并在数据库中检索出最相似的语料。
- 逻辑匹配:将检索到的语料与用户问题结合,输入LLM进行逻辑匹配和答案生成。
技术优势
- 领域扩展性:通过向量数据库的向量化处理,LLM可以扩展到新的领域知识。
- 检索效率:向量数据库的相似性检索提供了快速的文档匹配能力。
- 智能问答:结合LLM的理解和生成能力,实现高质量的问答服务。
结构图

注意事项
- 确保上传的文档质量,以提高向量化的准确性。
- 考虑领域知识的专业性,合理设计提示以引导LLM。
通过上述步骤,我们可以构建一个高效、智能的领域知识库问答服务,帮助用户快速获取所需信息。
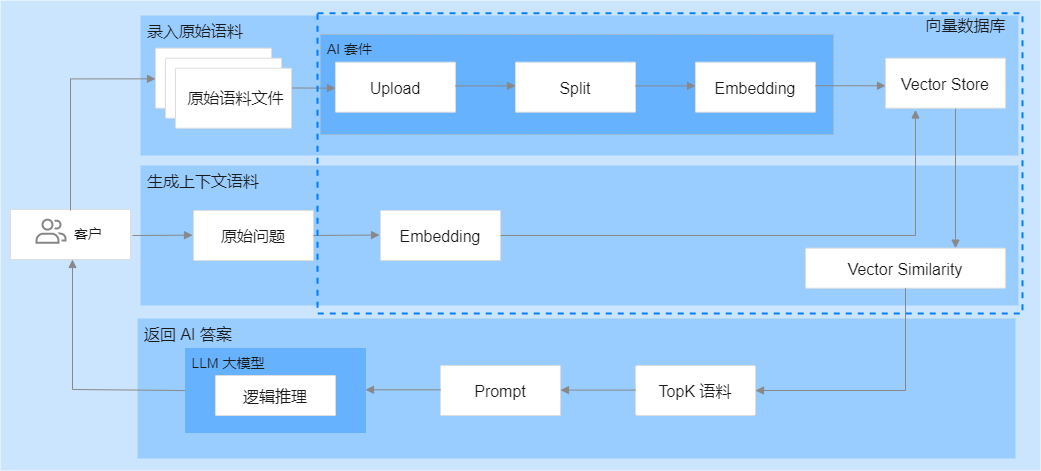
腾讯云向量数据库AI套件提供了一套全面的向量检索解决方案。它包括数据分割和嵌入服务,用户无需自行编写代码即可实现数据的拆分和向量化,这大大减少了算法工程的投入,简化了实现过程,降低了业务接入的难度。此外,通过上下文语料的有效指导,相似性检索能够更精确地引导大型语言模型(LLM)生成更准确的答案,从而提高回答的准确性。腾讯云向量数据库还采用了灵活的存储策略,允许根据需求的变化及时优化和更新知识库,确保系统的稳定性。
实现步骤
步骤1:导入Python SDK依赖库
在开始使用腾讯云向量数据库的AI套件之前,首先需要导入所需的Python SDK依赖库。这通常包括安装和配置相关的包,以确保后续步骤的顺利进行。
|
|
步骤2:创建客户端对象,连接数据库实例
|
|
步骤3:知识库初始化
声明 knowledgeInit() 函数,初始化知识库。
1. 为腾讯云向量数据库专有知识库创建一个 AI 类数据库 testdb。
2. 在已创建的 AI 类数据库中,创建集合视图 knowledge。
|
|
步骤4:传入问题进行知识内容相似性检索
声明 searchKnowlege() 函数,传入用户 question,返回知识库中与用户 question 最相似的内容。
|
|
步骤5:利用大语言模型生成问题答案
概述在人工智能领域,大语言模型(LLM)通过分析和学习大量文本数据,能够生成接近人类水平的语言输出。本步骤将展示如何将用户问题与知识库检索的相似性语料相结合,以提高答案的准确性。
操作步骤
- 问题输入:首先,将用户的问题输入系统。
- 知识库检索:系统检索与用户问题相关的相似性语料。
- 语料分析:分析检索到的语料,提取关键信息。
- 逻辑推理:利用大语言模型进行逻辑推理,结合用户问题和关键信息生成答案。
模型示例以Baichuan2-Turbo为例,该模型能够通过上述步骤,更有效地生成准确的答案。
注意事项
- 确保问题与语料的相关性,以提高答案的准确性。
- 逻辑推理过程中,需要考虑语料的多样性和复杂性。
结论通过结合用户问题和知识库检索的相似性语料,大语言模型能够生成更加准确和有逻辑性的答案。
|
|
步骤6:构建 main() 函数
3. 将检索结果的 Topk 条 knowledges 与 输入的问题 question 进行内容组装。
|
|
腾讯云向量数据库的 Embedding 功能解析
1. 问题背景在腾讯云向量数据库产品文档中,提到了大语言模型(LLM)在没有相关数据的情况下,会出现’幻觉’问题,这导致其在回答相关问题时效果不佳。
2. 解决方案通过使用腾讯云向量数据库 AI 套件搭建知识库,对大语言模型进行知识补充,可以显著提高问题回答的准确性。
3. 效果对比以下是三个问题的回答效果对比,展示了知识补充后的提升:
- 问题1:什么是腾讯云向量数据库的 Embedding 功能?
- 原始回答:(此处应为大语言模型在没有知识补充时生成的答案,但原文未提供)
- 补充知识后的回答:Embedding 是一种将高维数据转换为低维向量的技术,它使得数据能够在向量空间中进行更有效的分析和处理。
4. 结论通过向大语言模型提供额外的知识库支持,可以解决其在特定领域的’幻觉’问题,从而提高其在专业问题上的回答质量。
5. 注意事项
- 确保在使用大语言模型时,补充相关的专业知识库。
- 持续优化和更新知识库,以保持模型的准确性和时效性。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
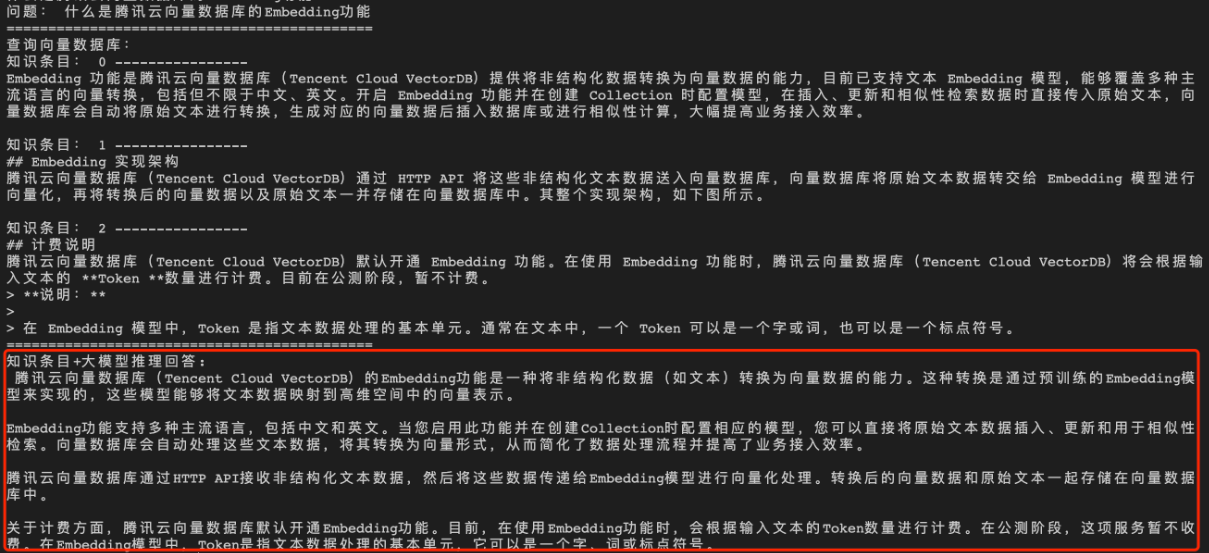
问题2:什么是腾讯云向量数据库中的 AI 套件?
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
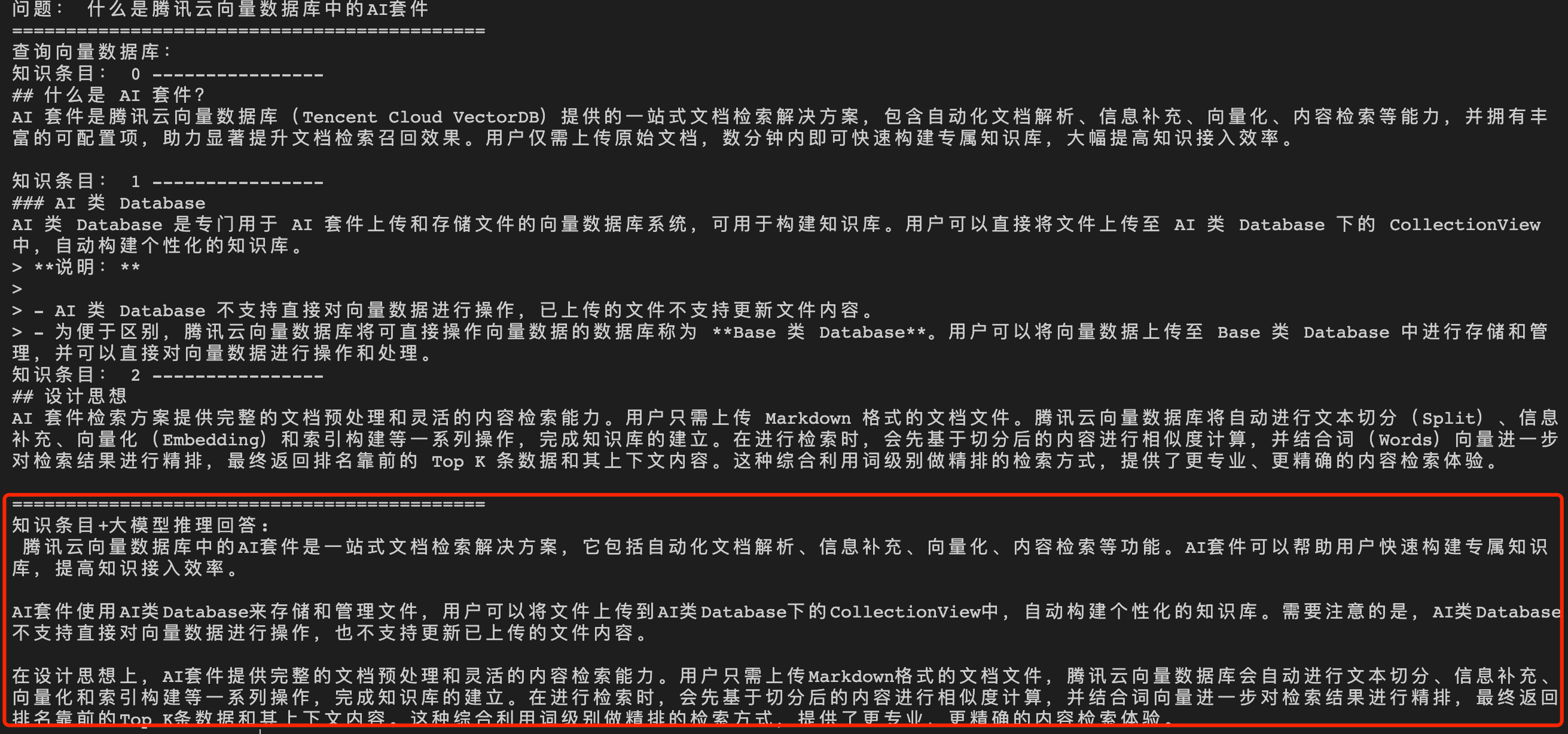
问题3:腾讯云向量数据库支持的最大 QPS
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
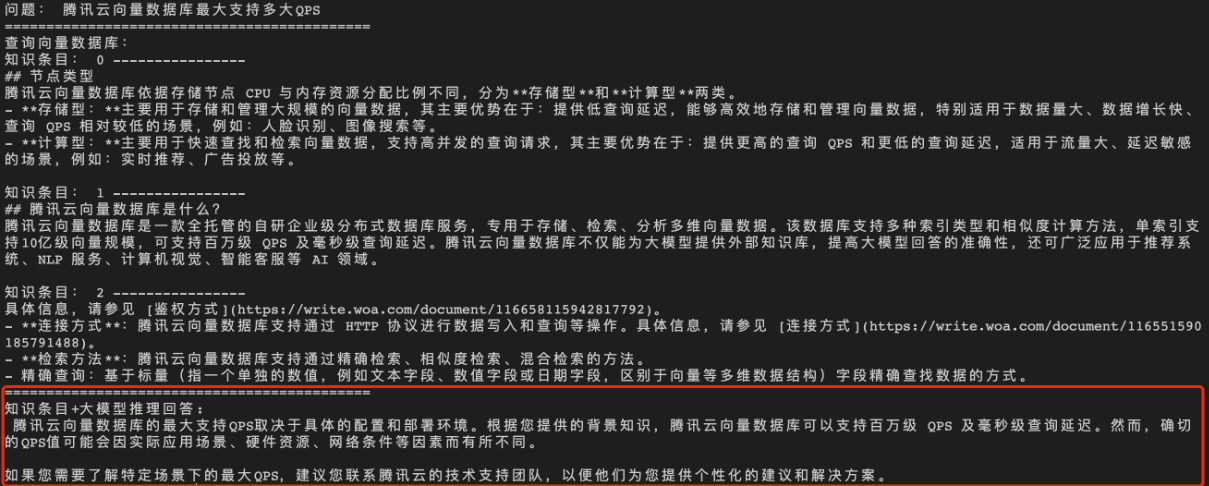
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240730/%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93-%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93-AI-%E5%A5%97%E4%BB%B6-+-LLM-%E5%A4%A7%E6%A8%A1%E5%9E%8B%E6%89%93%E9%80%A0%E4%B8%93%E5%B1%9E%E7%9F%A5%E8%AF%86%E7%9A%84%E9%97%AE%E7%AD%94%E6%9C%8D%E5%8A%A1-%E5%AE%9E%E8%B7%B5%E6%95%99%E7%A8%8B-%E6%96%87%E6%A1%A3%E4%B8%AD%E5%BF%83--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


