DDD领域驱动设计四重边界知识概述 --知识铺
在DDD(领域驱动设计)中,四重边界是指分析边界、设计边界、实现边界和运行边界。这四个边界定义了软件开发的不同阶段应遵循的原则和策略。
分析边界 (Analysis Boundary):确定业务问题范围,定义问题域。
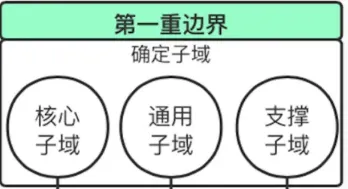
设计边界 (Design Boundary):根据领域模型划分限界上下文。
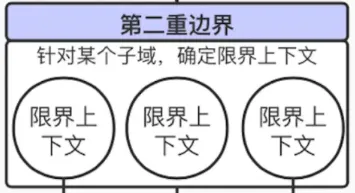
实现边界 (Implementation Boundary):确保软件实现符合目标的领域编程模型。
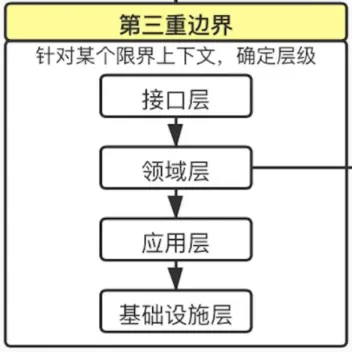
聚合边界 (Aggregate Boundary):引入聚合的设计作为隔离领域模型的最小单元。
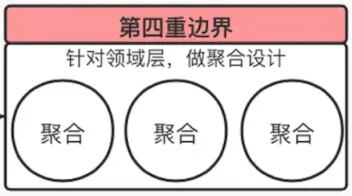
总结在一张图里如下:
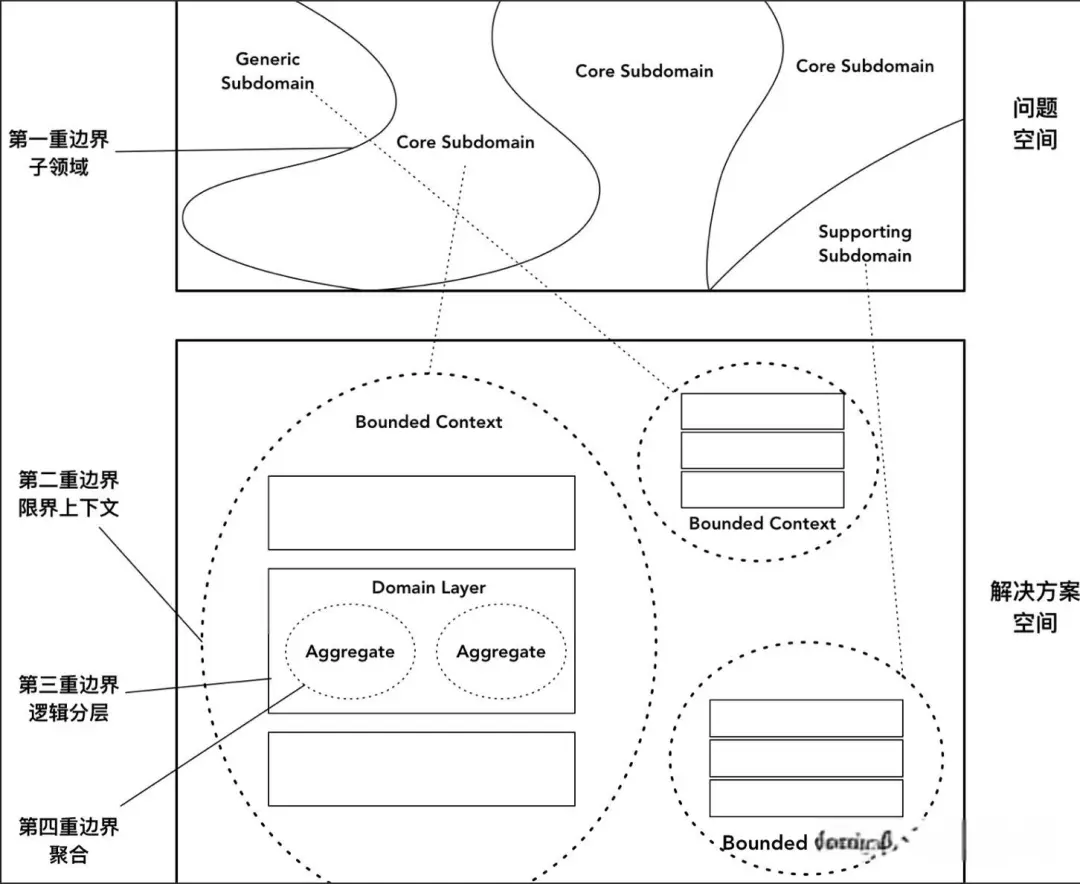
第一重边界
第一重边界划分的核心是公司业务价值 从分析需求一开始,我们就需要通过确定项目的愿景与目标,划定问题空间,由此确定核心子领域、通用子领域与支撑子领域。这是领域驱动设计的第一重边界。它帮助团队看清主次,理清了问题域中领域逻辑的优先级,同时促使团队在宏观层次的全局分析阶段能够将设计的注意力放在领域和对领域模型的理解上,满足领域驱动设计的要求。
那如何理解核心域、通用域和支撑域呢?
核心域:决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。
通用域:没有太多个性化诉求,同时被多个子域使用的通用功能子域是通用域。比如认证、权限等,这类应用很容易买到,没有企业特点限制,无需太多定制化。
支撑域:既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,但又是必需的支撑域。支撑域具有企业特性,但不具通用性,例如数据代码类的数据字典等系统;在业务域中,会有一些比较重要的业务,但却不是核心,那么它便是一个支撑子域。创建支撑子域的原因在于它们专注于业务的某个方面。
第二重边界
进入解决方案空间,战略设计获得的限界上下文成为了领域驱动设计的第二重边界。引入限界上下文的目的,不在于如何划分,而在于如何控制边界, 康威定律认为:“任何组织在设计一套系统(广义概念上的系统)时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。” 在康威定律中起到关键杠杆作用的是沟通成本。如果同一个限界上下文的工作交给了两个不同的团队分工完成,为了合力解决问题,就必然需要这两个团队进行密切的沟通。然而,团队间的沟通成本显然要高于团队内的沟通成本,为了降低日趋增高的成本,就需要重新划分团队。反过来,如果让同一个团队分头做两个限界上下文的工作,则会因为工作的弱相关性带来自然而然的团队隔离。
观察角度的不同,限界上下文划定的边界也有所不同。大体可以分为如下三个方面: 领域逻层面:限界上下文确定了领域模型的业务边界,维护了模型的完整性与一致性,从而降低系统的业务复杂度。团队合作层面:限界上下文确定了开发团队的工作边界,建立了团队之间的合作模式,避免团队之间的沟通变得混乱,从而降低系统的管理复杂度。技术实现层面:限界上下文确定了系统架构的应用边界,保证了系统层和上下文领域层各自的一致性,建立了上下文之间的集成方式,从而降低系统的技术复杂度。这三种边界体现了限界上下文对不同边界的控制力。业务边界是对领域模型的控制,工作边界是对开发协作的控制,应用边是对技术风险的控制。引入限界上下文的目的,其实不在于如何划分边界,而在于如何控制边界。 限界上下文意味着安全:对限界上下文是可控制的,就意味着你的系统架构与组织结构都是可控的 架构在划分限界上下文时,不能只满足于业务边界的确立,还得从控制技术复杂度的角度来考虑技术实现,从而做出对系统质量属性的响应与承诺。
第三重边界
在限界上下文内部,基础设施层、应用层与领域层之间的隔离成为了领域驱动设计的第三重边界。
系统分层的依赖倒置:在最早的传统四层架构中,基础层是被其它层依赖的,它位于最核心的位置 ,那按照分层架构的思想,它应该就是核心,但实际上领域才是软件的核心,所以这种依赖是有问题的。所以诞生了依赖倒置的设计,优化了传统的四层架构,实现了各层对基础层的解耦。
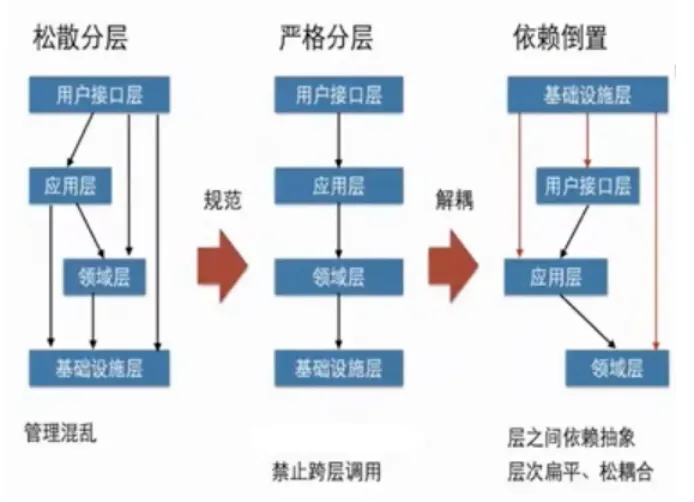
分层架构仅仅是对限界上下文的逻辑划分,在编码实现时,逻辑层或许会以模块的形式表现,但是也可能将整个限界上下文作为一个模块,每个层不过是命名空间的差异,定义为模块内的一个包。不管是物理分离的模块,还是逻辑分离的包,只要能保证限界上下文在六边形边界的保护下能够维持内部结构的清晰,就能降低架构腐蚀的风险。
依据整洁架构遵循的“稳定依赖原则”,领域层不能依赖于外层。因此,出口端口只能放在领域层。事实上,领域驱动设计也是如此要求的,它在领域模型中定义了资源库(Repository),用于管理聚合的生命周期,同时,它也将作为抽象的访问外部数据库的出口端口。
将资源库放在领域层确有论据佐证,毕竟,在抹掉数据库技术的实现细节后,资源库的接口方法就是对聚合领域模型对象的管理,包括查询、修改、增加与删除行为,这些行为也可视为领域逻辑的一部分。
然而,限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢?如果依然放在领域层,就很难自圆其说。例如,出口端口EventPublisher支持将事件消息发布到消息队列,要将这样的接口放在领域层,就显得不伦不类了。倘若不放在位于内部核心的领域层,就只能放在领域层外部,这又违背了整洁架构思想。
既然出口端口的位置如此尴尬,而且很明显出和入不太对称,所以我们干脆就把出和入对称下,将端口和适配器统一掉,组合成“网关”。
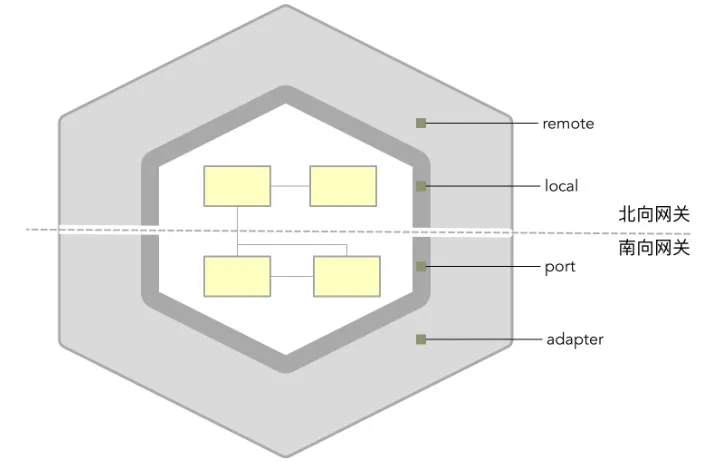
上面的对称架构虽脱胎于六边形架构与领域驱动设计分层架构,却又有别于二者。
对称架构北向网关定义的远程网关与本地网关同时承担了端口与适配器的职责,这实际上改变了六边形架构端口-适配器的风格;领域层与南北网关层的内外分层结构,以及南向网关规定的端口与适配器的分离,又与领域驱动设计的分层架构渐行渐远。
既然已经改变,就根据思想,重新抽象下架构图
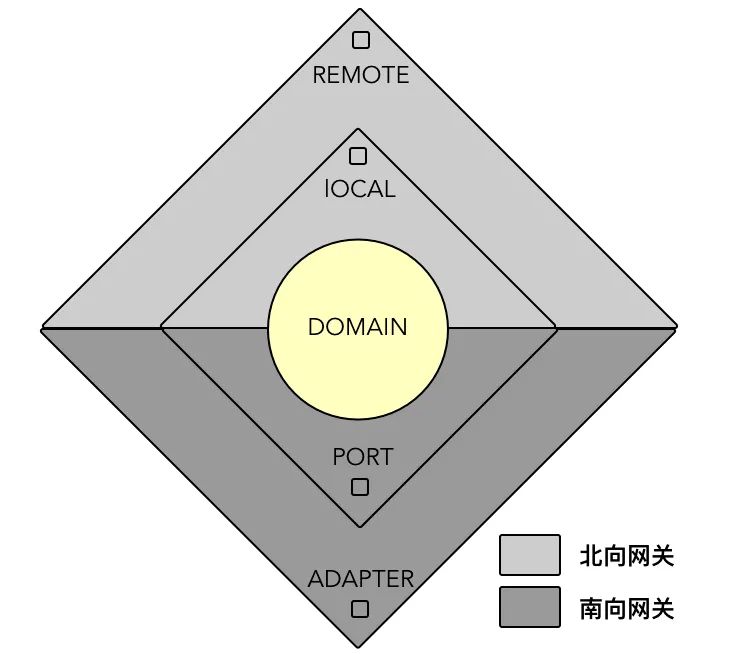
就得到了菱形对称架构,主要体现了南北网关的对称关系。
第四重边界
第四重边界若要维持领域内核的稳定性,高内聚与低耦合是其根本要则。虽然职责分配的不合理在应用层边界的隔离下可以将影响降到最低,但总是在调整与修改的领域模型无法维护领域概念的完整性和一致性;为此,领域模型引入了聚合这一最小的设计单元,它从完整性与一致性对领域模型进行了有效的隔离,成为了领域驱动设计的第四重边界。
聚合根本质是个实体,用来保证内部实体规则的正确性和数据一致性。外部对象只能通过 id 来引用聚合根,不能引用聚合根内部的实体。聚合根之间不能共享一个数据库事务,他们之间的数据一致性需要通过最终一致性来保证。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240723/DDD%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1%E5%9B%9B%E9%87%8D%E8%BE%B9%E7%95%8C%E7%9F%A5%E8%AF%86%E6%A6%82%E8%BF%B0--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


