DDD落地实践指南 --知识铺
引言
在之前的文章讨论了为什么要用DDD后,相信会产生DDD如何落地的疑惑。在经过一段DDD落地实践后我总结了一些经验,这篇文章将带领大家看一下我眼中的DDD。
顶层视图——从一个用户查询推荐商品列表说起
我们以用户登录一个网购平台后从后台获取被推荐商品的场景为例。外部请求进入后台服务后会先经过Interface层,在参数校验并对id为空等非法请求进行拦截后,DTO对象会在被转换成领域对象UserInfo后被传入ApplicationService层。在ApplicationService层里需要经历以下流程:在用户聚合里对UserInfo进行业务上的校验,随后从用户信息的仓储里获取用户画像,用于在推荐聚合里计算出对应被推荐商品的id列表。最后根据商品id通过远程调用从商品微服务里获取商品的详情并返回给调用者。整个流程从最顶层说明了一个请求是如何被一个DDD指导建模的微服务内部和服务间处理的:
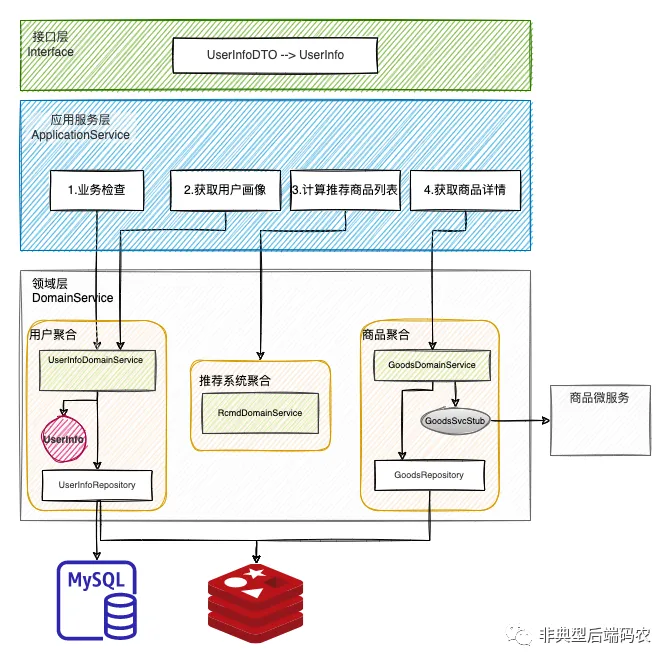
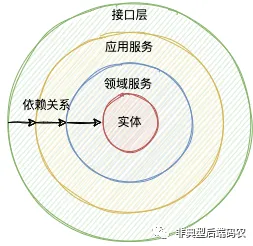
下面将依据整洁架构里的依赖关系,按照实体、领域层、应用服务层到接口层的顺序进行讲解。
领域层里的充血模型——专治贫血模式的失忆症
贫血模型及其失忆症
在过去“数据驱动型”的设计里,ER图几乎承载了所有的业务逻辑,然后利用字典或者一个POJO对象来实现库表在代码层的映射。然而这类对象往往只用来存储数据,而改变对象所存储的数据的代码块,则可能散落到项目里的各个地方。但这种方式有什么弊端呢?
以上述提到的用户信息子模块为例,原来用户信息仅仅记录用户的中文名,这时候只需要简单调用UserInfo::setUserName就可以设置对象的名字。但是到了后期随着需求迭代,产品要求在设置中文名的同时还要记录对应的拼音,这时候除了新加userNamePinyin字段外,还需要先梳理出所有UserInfo::setUserName的调用点,再把转换和设置拼音的步骤追加到相应的位置。
对于调用点很少,且新增加的操作比较简单的情况,可以直接把逻辑平铺到原来的代码块里。但是当调用点很多,且拓展的行为很复杂时,新人会难以快速梳理所有的调用点。在开发需求时,开发者就会像失忆一样无法覆盖所有的情况,很容易出现在某些地方加了新特性,别的调用点忘了修改从而引入新的bug的问题。
充血对象
之所以上述的“失忆症”,是因为行为不够内聚,即相关的操作没有打包成一个代码块,这个问题很多人会想将整个流程的所有操作封装到一个函数里,然而这个解决方案的缺点在于这类封装函数可能被各种不同的调用者“定制化”,最终腐化成一个非常臃肿的函数。比方说一个通用的changUserName函数会慢慢被叠加更多if-else的逻辑,直到最后变成一个四不像的通用函数。
解决这个问题的思路就是把这个行为绑定到对象里,而这个带行为的对象就变成了一个“充血对象”。在将某个行为的实现屏蔽到一个对象方法以后,意味着一个对象除了基本的getter/setter外还能提供更多行为,甚至能够嵌套其他的对象。
下面以用户信息为例:一个用户(UserInfo)除了基本信息外,还会有更多的拓展信息(比如中文名的拼音),我们希望在修改一个用户的名字时,能够顺带修改对应的拼音全部和首字母缩写,因此最后得到的充血对象为:
// 用户的扩展信息
当需要对改名的行为做扩展时,可以将拓展的操作内聚到UserInfo::changeUserName后面。调用者只知道自己给对象赋予了新的名字,而不需要感知还要修改哪些关联的属性,更不需要把这些逻辑平铺自己的流程里。这类带了行为的富领域对象,一般就是领域层里的实体。
仓储模式并不是DAO——尽量避免底层存储污染业务逻辑
承接上文,业务代码里定义的对象是库表的映射。在传统的数据驱动的开发模式里,贫血模式和库表几乎是一一对应的,相应的在开发过程中也会设置一个DAO层来处理数据存储的逻辑。然而在实践过程中我们会发现,持久化中间件的使用习惯会反过来影响或侵入业务层的代码设计,最终导致业务层和DAO层高度耦合。另外,在前面举的充血对象的例子里,出现了对象嵌套的情况,这时候就需要引入仓储模式来保存数据。
DAO(Data Access Object,持久化对象)和仓储模式(Repository)都能达到保存数据的目的(注意这里只是保存不一定是持久化),网上少有对二者做较为细致的对比区分:
DAO比较契合数据驱动型的开发模式,因为在这种模式里,业务代码实际上就是模拟人去执行sql或redis的数据读写操作,因此也被称作“事务型脚本”。DAO接口更多的只是sql语句之类的在代码中的一个抽象,这样会反过来影响代码设计:即业务逻辑和存储相关的逻辑揉合平铺在service方法里。以创建用户为例,缓存中会存储用户信息的副本,而插入的操作是一个upsert操作:
interface UserInfoDAO {
可以看到业务逻辑和保存数据的操作是耦合在一起的,没有做到业务层只处理复杂的业务逻辑,存储层只做存储的逻辑。这样做的优势在于直观易上手,符合开发人员的直觉,这也是Controller-Service-DAO三层架构广为流传的原因。然而劣势就在于业务逻辑几乎都下沉到DAO层,导致DAO层非常厚。而梳理起业务来需要ER图和代码对着一起来看,更别说想要单独对某一部分进行单元测试。更极端一点的,假如哪天不再用sql或者redis了,代码几乎要全部重写。PS:这里插一句题外话,DDD语境下的复杂是指一个对象的状态很多且触发状态扭转的条件很多链路很长,这本身并不意味着一定一要用关系型数据库,更别说一定要设计很多库表已经相应的PO对象。
我们再来看看仓储模式:跟它的名字一样,仓储就是拿来保存数据的,至于有没有持久化,怎么实现持久化,原则上不应该由业务层感知。我在做设计时,会更多的聚焦于业务逻辑,即实体行为的设计、编排,而不过分关注仓储层的实现。在编码实现时我也会先写一个内存版本的Repository,以免存储层的逻辑过分侵入到业务层里。下面还是以创建用户为例进行代码演示:
interface UserInfoRepository {
上面这段代码展示了在仓储模式是怎么落地的,即使后台使用了redis和mysql存储数据,但先读缓存再读DB这个操作也被屏蔽到了Repository的实现后面,业务层不需要也不应该感知到存储的细节。在《实现领域驱动设计》这本书里,Vaughn提到过面向集合的仓储模式:就像我们在用java的Map集合类时,只管往里面存取数据即可,至于是否线程安全,随机读写能力高低这类问题应该由具体的实现类来保证。实战中也是先确定Repository需要对领域层提供什么行为,先把领域层的逻辑写好,利用Repository的Mock实现类自测通过后再组装做更上层的自测。
使用DDD的仓储模式的优势就在能够将存储的行为和业务逻辑进行解耦,但也会引入不好的问题:一个是会引入更多的设计,这是抽象和解耦不可避免的代价;另一个问题是互联网的后台业务需要关注性能,比方说上面如果把检查是否在缓存存在的逻辑都收拢到save接口以后,在校验等前置的业务逻辑执行完成之前没法进入到仓储层的校验。
对于这个问题,我的经验是在Repository里面提供一些可能跟Repository的增删改查无关,但对业务有帮助的一些行为。而为了避免这些行为被滥用,在命名时要保证方法名要有意义,而不建议简单叫做get/setXXX:
interface UserInfoRepository {
聚合和DomainService——一个随时可能被拆出去的微服务
在四层架构的目录结构里,有一个叫做domain的目录。很多地方习惯笼统的叫做领域层,然后把所有的业务逻辑都丢到这一层实现。其实一个领域底下可以细分出很多聚合:聚合负责将业务和逻辑紧密关联的实体和值对象收拢到更细的边界里,并通过对实体的行为进行编排来为调用者提供服务。
传统数据模型里,对象和对象之间的关系是对等的,相关的业务逻辑也是对等的,就像上面展示的UserInfo和UserExtInfo一样。
DDD的每一个聚合都会有一个聚合根,用来串起整个聚合的各个对象。就像如果要操作一个由很多个线团缠在一团的毛球,往往会从一个线头开始,即牵一发而动全身的那一发。聚合根可以是某个具体的对象(如上文展示的UserInfo),也可以是对象的集合组成的上下文,比如对一个舞台剧进行抽象,那舞台就是一个聚合根,舞台上的演员就是具有行为的实体。
整个聚合对外提供的行为是通过DomainService来提供的,比如对用户信息的增删改查都放在UserInfoDomainService来提供,在它的方法里对UserInfo的行为进行编排。跨聚合的逻辑则在更高的层次进行编排,这也是我把聚合叫做“一个随时可能被拆出去的微服务”的原因。
在实际落地时DomainSerivce要围绕着聚合根操作,聚合根所关联的对象状态的变化要保持一致性。简单点说就是,如果几个对象的状态需要在一个事务里进行修改,那这几个对象应当被包含在一个聚合里。如上述展示的UserInoDomainService::createNewUser应当同时保存UserInfo以及关联的扩展信息,而不是单独为扩展信息构建一个UserExtInfoDomainService。
ApplicaitonService层——连通不同聚合操作的主板
上文提到聚合是一个可能会拆分出来单独维护和部署的微服务,但实际上不同聚合的代码放在一个项目里还是拆分成不同项目,这个是由所选的编程语言、运维条件、聚合是否足够复杂等因素综合决定的,并没有一个标准的答案。
当属于不同边界的行为内聚到以后各自的聚合后,不可避免的需要有一个更高级的层次对跨聚合的行为进行编排:如本文开头所演示的,就用户获取被推荐商品的流程就涉及了用户信息,推荐和商品管理三个聚合。这个在更上层编排聚合行为来组成更复杂业务的层级叫做ApplicationService层,也是DDD的项目结构里区别于传统三层的一个较为明显的特征。
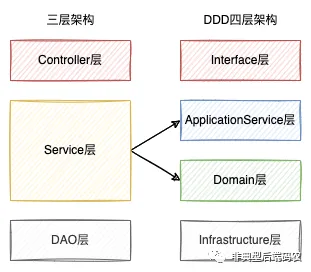
如果阅读过欧创新老师的《DDD实践课》,会接触到自顶向下和自底向上两种设计思路,课程中提到前者适用于全新的系统而后者适用于遗留的待重构的老系统。在我尝试做DDD落地时,我会更倾向于自顶向下的设计思路,且尤为看重ApplicationService层:以设计电路板为例,记得我本科学习单片机时经常会出现板子呈现不符合预期的行为的情况,这时候我会先试试把一些外设元件和另一个已经在其他电路板正常运作的元件做替换,再把换下来的芯片或单独测试其输出电平、或插到另一块已经正常运行的板子上,通过互相校验来定位问题点。同理,在做软件设计时,在聚合划分清晰且Mock工具齐全的前提下,我可以单独对ApplicationService层这块主板和具体的DomainService进行单元测试,再将它们装配起来进行全链路的测试。而这么做的另一个好处是DomainService的实现不会反过来制约上层的设计,即做到依赖倒置。
适配器模式——屏蔽实现的好帮手
前面提到聚合是一个可能被拆分出去的微服务,无论出于尽量避免分布式事务的原则,还是考虑减少服务治理的难度。而那当真正需要拆分时,原来的本地函数调用就需要变成远程调用,这时候往往需要先梳理原来的上下文,增加远程调用所需要的上下文等等,这样的的话远程调用的一些准备会侵入到业务逻辑里,从这开始就又嗅到了代码腐败的味道了。
对于这种情况,我的经验是使用适配器模式屏蔽实现的细节:即站在ApplicationService层的视角,我只关心下层的DomainService能给我提供我需要的行为和数据,而尽量避免下游系统的设计制约我对逻辑的编排。其实这也是面向接口的思想,电路板会为不同的外设提前设置类似DIP,SMD这样的通用插座/接口,对于同一个接口不同的厂家可以有不同的实现,但最后对外暴露行为时还是需要按照预设的接口来。
以调用商品聚合的查询接口为例,早期大单体服务时可以通过本地调用直接查询,后面进行服务拆分后通过rpc调用从下游获取,后面发现性能有瓶颈后考虑加入缓存来提速,然而在ApplicationService层看到的一直是GoodsDomianService::listGoodsByIds:
class GoodsDomainServiceImpl {
在进行DDD设计时,有一个原则是跨聚合调用尽量只传递聚合根id而避免把一个聚合里面的实体传递到另一个聚合里,就像一个表里的外键实际上是另一个表的主键一样。如果一个聚合实在需要更多来自于另一个聚合的信息(比方说订单聚合需要知道来自用户聚合里除了用户id外的更多信息,比如头像、昵称、住址等),则可以为聚合设计一个值对象。这也是一种解耦的手法,即不仅行为需要做到适配,数据也要做到适配。就像我经常跟朋友调侃的:“我在你们眼里是一个叫Tenz的头发多多的SDE,然而回到家在我妈眼里我就只是个连喝汤都不愿意走出房门的懒儿子”。
这种利用冗余的对象来保证聚合间解耦的手法似乎不那么符合技术视角里重复的代码尽量复用的原则,且会引入更多的维护成本。但就业务角度看,这其实是一个事物在不同的上下文里本来就应该有不同的抽象,强行将一个对象用到不同的模块很可能会让对象为了适应不同聚合的需求最终腐化成一个四不像的大对象(就像那些带了很多业务语义的所谓的通用函数一样)。这个“少写几行代码尽量复用”和“冗余代码达到解耦”之间的矛盾需要开发者因地制宜。另外,如果确实出现了这种跨聚合都存在的实体时,开发人员就需要和领域专家一起重新审视之前的领域划分是否合理。
Converter模式——防腐化
对于微服务架构模型,无论是六边形架构还是整洁架构,领域层总是处在最中心的位置,而领域对象(如实体、值对象等)在不同的层级会有不同的抽象:比如在从外部到接口层时对象称作DTO(Data Transfer Object),而进入仓储层之后则可能变成PO(Persistent Object)。我在之前的文章里提到过,传统三层习惯从对外的接口开始设计和编码,DDD习惯先做好领域层的设计再考虑如何对外呈现数据。
传统三层会让对外的协议侵入到业务逻辑里,相信不少开发者都经历过看着入参里密密麻麻铺着一堆参数,但是因为不知道怎样的参数组合会触发哪个逻辑分支导致需要把从Controller到DAO整个链路的几乎所有代码都看一次才能梳理清楚的过程。
在DDD的世界里,对象往往是富领域的,比如UserInfo里面嵌套了UserExtInfo,然而两者其实对应着两张库表,也对应着两个PO对象。在DDD里领域层是最重要的,为了防止外部依赖侵入到业务逻辑里导致腐化,需要引入Converter模式来解决这种阻抗不匹配的问题。
Converter模式有两种实现方式,一种是单独写一个转换函数,另一种则是将转换的行为绑定到实体上。我个人比较习惯后面的方式,因为前者可以保证实体相对干净,而后者虽然外部依赖对实体有轻微的侵入,但因为外部依赖都内聚成实体行为,可以防止扩散到其他地方。
class UserInfo {
CQRS——应对复杂查询
虽然DDD采用富领域模式后能够将现实事物映射出来的对象清晰地划分到所属的上下文里,但是复杂查询的请求往往在整个业务中占较大的比例,身边也有朋友在发现做DDD落地时可能无法应对复杂查询或者容易遇到性能瓶颈。
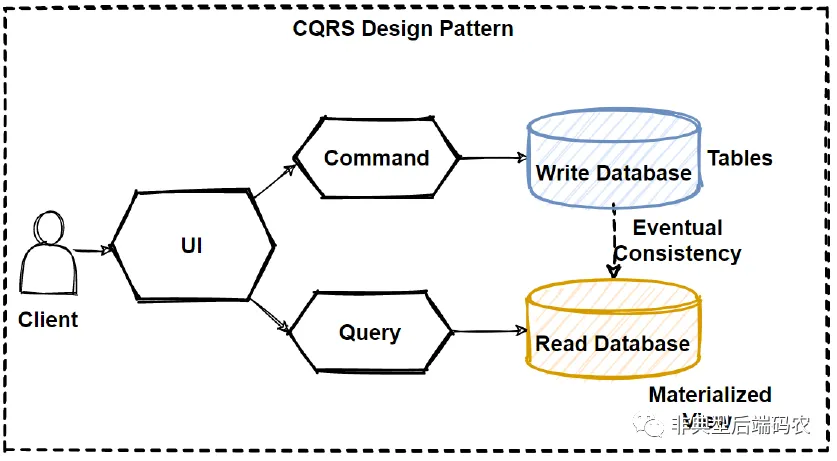
这时候不妨跳出富领域的设计思路,将对外提供的行为划分成命令(Command)和查询(Query)两个路径,命令路径采用富领域模式建模。查询路径可以相对宽松,设计复杂的聚合了来自不同子系统数据的DTO对象,这就是所谓的CQRS模式(Command Query Responsibility Segregation,命令查询职责分离)。
要注意CQRS模式和技术建模上的读写分离是有区别,前者是立足于业务复杂查询的需要复杂对象,而后者则更侧重于围绕着读库或者缓存来增加读请求的并发能力。
在具体实现上常见有两种方案:
-
第一种是直接在当前的项目里增加一个只读用的Repository,这个Repository不需要对应特定的聚合,某种程度上其实就是传统三层里的DAO。这种方案实现成本不高,适用于较小且所涉及的聚合不多的场景。但要注意防止这个仓储不要被滥用到Command的路径里。
-
另一种方案则是用专门的存储中间件,比如ES、Hive等。这个方案适用于非常负责的聚合查询的场景,但弊端则是会引入新的运维成本。
Interface层——对外暴露服务的行为
Interface层比较好理解,就是做简单的参数校验,为外部暴露当前服务的行为。与传统三层的设计思路不同,Interface不是一股脑将底层数据的所有字段透传出去。相反,Interface层对外暴露的接口应该是带语义的。比如对于用户信息管理系统,即使从服务里获取到的用户信息有大部分字段是相同的,但是服务依旧会为不同的入口暴露不同的接口,而不是搞一个大而全的查询接口,通过入参里的标记位来决定当前发起请求的是C端还是运营端。
DDD是个框,什么都能往里面塞
其实初期就“是否利用DDD指导技术建模和编码实现”这件事在团队内部有过分歧。部分开发人员出于实现和上手成本的考虑,认为只需要提前做好服务划分,每个服务内部依旧按传统三层开发。而我早期也曾是一个DDD的狂热信徒。
经过一段时间的落地实践后,两个派系都各自遇到了瓶颈:传统三层的在经过一段时间的需求迭代后开始出现了贫血模式的失忆症,让新人去评估一个需求时不好准确评估工时,且开发过程中出现不好自测且容易把老特性改坏的问题;而过分追求DDD的,容易陷入领域划分的争论或者不停构造各类领域对象的时间泥潭里。
在这之后我更加能体会到“DDD非银弹”的道理,就像一位同事说的:“现在DDD太火了,其实这就是个框,谁都说自己在DDD。”
DDD的初衷,其实是为了建立一套技术人员和非技术的领域专家之间的共同语言。我认为现实事物映射到代码实现最关键的理解是“限界上下文”和“充血模型”的思想,总结起来就是“每个人或物都是有自己的行为的,然而即使是同一个人,在不同的语境下也会有不同的角色和行为”。
至于后面衍生出来的代码模型等等,其实每个团队都会慢慢形成一套自己的规。比起拘泥于命名格式等表象的东西,更重要的还是重新开始习惯用OOP的思想来指导设计。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240710/DDD%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5%E6%8C%87%E5%8D%97--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


