数据特征采样在MySQL同步一致性校验的实践 --知识铺
作者:vivo 互联网存储研发团队 - Shang Yongxing
本文介绍了当前DTS应用中,MySQL数据同步使用到的数据一致性校验工具,并对它的实现思路进行分享。
一、背景
在 MySQL 的使用过程中,经常会因为如集群拆分、数据传输、数据聚合等原因产生流动和数据复制。而在通常的数据复制过程中,因为涉及到目标的写入不可控、服务应用的未知问题、人为导致的异常缺陷等,很难保证复制产生的数据与源完全一致。除了通过完善流程与服务应用的能力和可靠性来保障数据一致性外,也需要提供快速有效的数据校验机制,便于发现存在异常的数据位置,服务于后续可能的自动重试或人工修订。
而具体到我们目前使用的数据传输服务DTS(MySQL部分),需要考虑的点:
-
端对端从源集群到目标集群的外部数据校验
-
内部数据校验机制,确保同步的数据正确可靠
二、选型参考
数据一致性校验,即对DTS的数据同步任务在目标产生(复制)的表数据,与在源库的原始数据进行对比,并给出对比结果。若存在不一致的情况则给出具体不一致的数据块,方便用户快速对不一致数据进行处理。它的基本原则是作为独立一个环节,既不能影响同步本身,也不能影响业务数据库的正常使用。
为了达成数据一致性的校验,需要具备以下的能力:
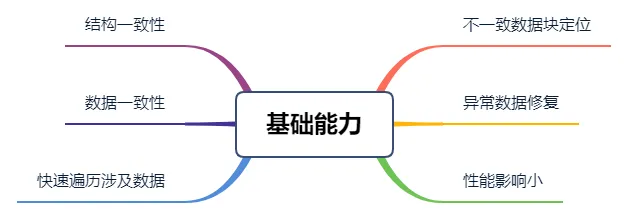
-
校验的范围应当包括库表对象的结构、实际行数据已经其它被任务定义包含在内的内容(索引、视图、存储过程等)。
-
校验应当在保证较小地侵入影响数据库的同时,尽快完成涉及数据的对比检查。
-
校验应当具备精确定位不一致数据块的位置的能力,用于支持后续进行的数据修订。
三、端对端的数据一致性校验
3.1 现有问题
在数据传输的场景中,相关的数据大概率分散在无关的不同实例上,这种情况下想要对两端的数据进行对比分析,比较包括结构、索引、列数据等维度,当然可以通过最直接的逐行逐列地遍历各个表方式,这种方式最直观且可以最精确地对比相关的数据,但显然如果数据总量或数据列的规模较大时,这种逐行对比的方式会存在下列问题:
-
执行耗时长
-
结果时效性差,增量场景几乎无法使用
一般来说如果无法接受“全量”性质的扫描带来的时间开销,可以将“全量”转换为“部分”的验证,本质上一些数据同步场景后执行的点检就是数据的部分校验,这种方式完成速度快,可用于关键数据的快速验证,但这种形式也存在明显的问题:
-
数据集覆盖度难以平衡
-
如果确实存在一些不一致的情况,可能会被遗漏
针对这些问题,也许可以采取一些额外的校验保障,例如数据集大小(行数等)的校验,一定程度上可以降低数据不完整的错判风险。
那么回到我们的实际使用场景中,为了解决数据可靠性的问题,我们调研了几种比较主流的MySQL数据校验方案:
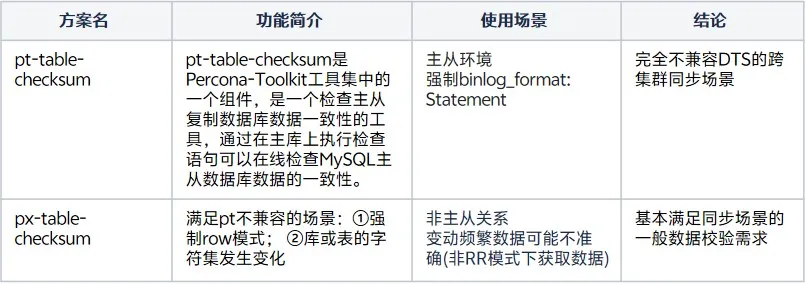
pt本身更常被运维用于检查集群内主从的表数据是否一致,这显然与数据传输的场景存在较大的出入,不符合我们的实际需求。
px在实现上更满足数据传输场景的需求,同时包括上述两者在内,一些公用云的MySQL类型数据库的数据一致性校验也是采用类似部分采用数据进行比对的形式:
- 表的数据分块
- 部分支持动态分块大小来调整负载
- 分块级的数据特征计算→简化对比规模
这个思路在数据遍历的完整性和效率方面均做了一定的取舍,相当于是一种中间状态。
而为了达成满足一些定制场景以及提高使用效率的目的,我们最终是采用了px-table-checksum的实现思路来完成的数据校验实现,接下来以一个具体的表结构来介绍进行数据对比的思路。
sysbench在MySQL的压测场景产生的一种表结构如下:
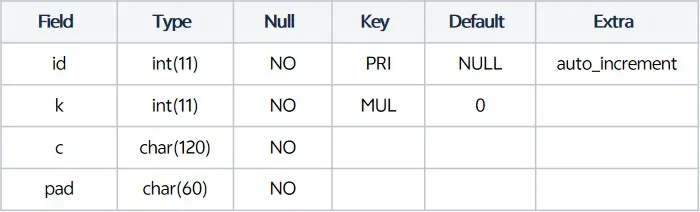
前文我们已经提到虽然直接使用全表逐行对比会存在时间消耗较大的问题,但如果业务属性上源和目标的表发生变化的频率很低(定时更新类),这种校验也是可以发挥作用的:
SELECT id, k, c, pad FROM sbtest1 limit n;
基于这样简易的抽取逻辑进行逐行的比对是可以做到完全校验的,代价就是时间上的开销非常大。
3.2 实现思路
而我们将要采取的分块获取数据的方式则是在这一基础上进行了优化,我们逐步介绍逻辑,首先这里假定使用的分块大小为10行–chunk_size=10
1.数据分块
mysql> SELECT * FROM sbtest1 FORCE INDEX(`PRIMARY`) WHERE ((`id`>= 1) AND ((`id`) <= 10));
2.按列聚合
mysql> SELECT CONCAT_WS('#', `id`, `k`, CRC32(`c`), CRC32(`pad`), CONCAT(ISNULL(`pad`))) AS CRC FROM `sbtest1` FORCE INDEX(`PRIMARY`) WHERE ((`id`>= 1) AND ((`id`) <= 10));
3. 按行聚合
在前一步的基础上,可以再计算一次当前聚合列的CRC32值使长度减少(因为按列聚合时使用的group_concat可能会存在长度的限制,这也是需要关注的问题)
mysql> SELECT CRC32(CONCAT_WS('#', `id`, `k`, CRC32(`c`), CRC32(`pad`), CONCAT(ISNULL(`pad`)))) AS CRC FROM `sbtest1` FORCE INDEX(`PRIMARY`) WHERE ((`id`>= 1) AND ((`id`) <= 10));
4.特征计算
到这一部分为止,我们可以将这种类型的CRC值作为这10行4列数据块的一种“特征”,用它来代表这部分数据,可以进一步进行压缩来提高比对效率,可选md5或继续CRC32等计算方式。
mysql> SELECT CRC32(GROUP_CONCAT(CRC32(CONCAT_WS('#', `id`, `k`, CRC32(`c`), CRC32(`pad`), CONCAT(ISNULL(`pad`)))))) AS CRC FROM `sbtest1` FORCE INDEX(`PRIMARY`) WHERE ((`id`>= 1) AND ((`id`) <= 10));
实际使用中使用更大的数据块来进行映射,能加快校验的速度:
-
数据块越大,特征的精度越低,但匹配校验的速度越快,对源和目标的负载越大。
-
数据快越小,特征的精度越高,但匹配校验的速度越慢,对源和目标的负载越小。
相对应的,以上是在源计算对应块的特征,在目标以同样的形式计算可以得到一个“类似”的结果,通过对它进行比对,可以判断两块数据的特征是否一致。 但这同样也有一些问题:
-
概率上存在特征值相同但数据存在差异的情况,无法避免。
-
比对的块依赖主键ID,不允许在目标存在主键覆盖的情况(源的数据因主键冲突被跳过)。
若存在数据不一致(块之间的CRC32值不一致),此时可以基于当前chunk的上下边界(upper/lower bound)进行进一步切分,通过精确的数据对比来定位到不一致的行。
数据最终一致性
前文中的例子更偏向于一个单纯的全量数据抽取场景,如果目标的数据存在一定程度上的变化时,如何对应处理呢?
差异块的重复校验
我们需要解决两个问题:尽可能在机制上确保数据不会出错,若存在异常或无法处理的情况应当以中断同步为优先选择;同时需要在端对端数据校验的基础上覆盖增量的数据同步场景。
数据校验任务并不是持续运行的场景,它应当是在低峰期、同步延迟1秒内或在业务要求的情况下发生的行为,那么基于数据同步的最终一致性特征,当增量场景下校验出某些块存在差异时:
例如:
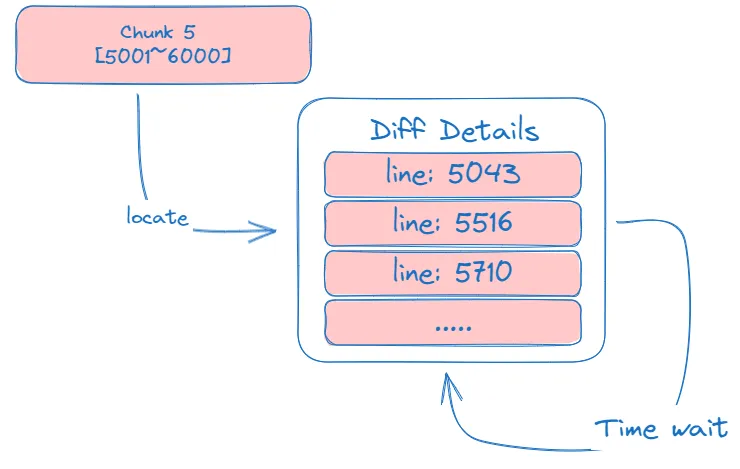
两侧的chunk[1001-2000]存在差异,那么需要按照精细拆分地形式定位到具体的差异行, 一般基于binlog的延迟在0秒(1秒内)时,行的差异数量是有限的,可以对其进行全部的记录或抽样记录。
在一定的时间间隔后重新校验上一次记录中的差异行,判断是否最终达成了一致;
可能存在特殊的场景,只频繁更新某一行,导致校验一直无法判断两端一致。
四、总结与思考
经过一定时间的线上实际应用,这种方案确实可以解决绝大部分(99%以上)的校验需求,不论是纯粹的全量还是涉及到增量的场景,都可以完成定点形式的数据一致性校验能力,但总的来说,它也存在可以优化改进的点:
-
本质上,块的特征计算值(MD5或CRC32)一致,还是存在内容实际不一致的可能性,虽然这部分概率很低,需要在当前基础上寻找更精确可靠的采样计算方式。
-
目前提供的一致性校验方案,只能支持同构型的数据库间,例如本文介绍的mysql->mysql(pg,tidb等),DTS支持的其它数据场景(redis->redis/kv)也是类似的情况,对于异构数据(例如订阅),暂时就没有比较好的方案可以做端对端的校验,需要使用方抽检部分或核心数据。
END
添加👇下面微信,拉你进群与大佬一起探讨云原生!

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240710/%E6%95%B0%E6%8D%AE%E7%89%B9%E5%BE%81%E9%87%87%E6%A0%B7%E5%9C%A8MySQL%E5%90%8C%E6%AD%A5%E4%B8%80%E8%87%B4%E6%80%A7%E6%A0%A1%E9%AA%8C%E7%9A%84%E5%AE%9E%E8%B7%B5--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


