应用40个机器学习模型的代码示例 --知识铺
转自:网络
今天和大家一起学习使用 lazypredict 库,我们可以用一行代码在我们的数据集上实现许多 ML 模型,这样我们就可以简要了解哪些模型适合我们的数据集。
步骤 1
使用以下方法安装 lazypredict 库:
pip install lazypredict
第 2 步
导入 pandas 来加载我们的数据集。
import pandas as pd
第 3 步
加载数据集。
df = pd.read_csv('Mal_Customers.csv')
第 4 步
打印数据集的前几行
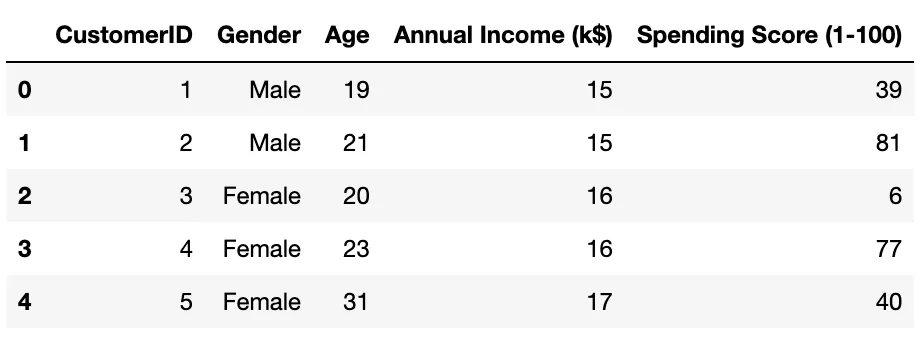
这里 Y 变量是支出分数列,而其余列是 X 变量。
现在,在确定了 X 和 Y 变量之后,我们将它们分成训练和测试数据集。
# 导入 train_test_split,用于分割数据集
from sklearn.model_selection import train_test_split
# 定义 X 和 y 变量
X = df.loc[:, df.columns != 'Spending Score (1-100)']
y = df['Spending Score (1-100)'] # 对数据进行分区。
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
第 5 步
我们导入之前安装的lazypredict库,lazypredict里面有两个类,一个用于分类,一个用于回归。
# 导入 lazypredict
导入 lazypredict
# 从 lazypredict 导入回归类
from lazypredict.Supervised import LazyRegressor
# 从 lazypredict.Supervised 中导入分类类
from lazypredict.Supervised import LazyClassifier
导入后,我们将使用 LazyRegressor,因为我们正在处理回归问题,如果你正在处理分类问题,则这两种类型的问题都需要相同的步骤。
# 使用 LazyRegressor 定义模型
multiple_ML_model = lazyRegressor(verbose=0, ignore_warnings=True, predictions=True)
# 对模型进行拟合,同时预测每个模型的输出结果
models, predictions = multiple_ML_model.fit(X_train, X_test, y_train, y_test)
这里,prediction = True 表示你想要获得每个模型的准确性并想要每个模型的预测值。
模型的变量包含每个模型精度以及一些其他重要信息。
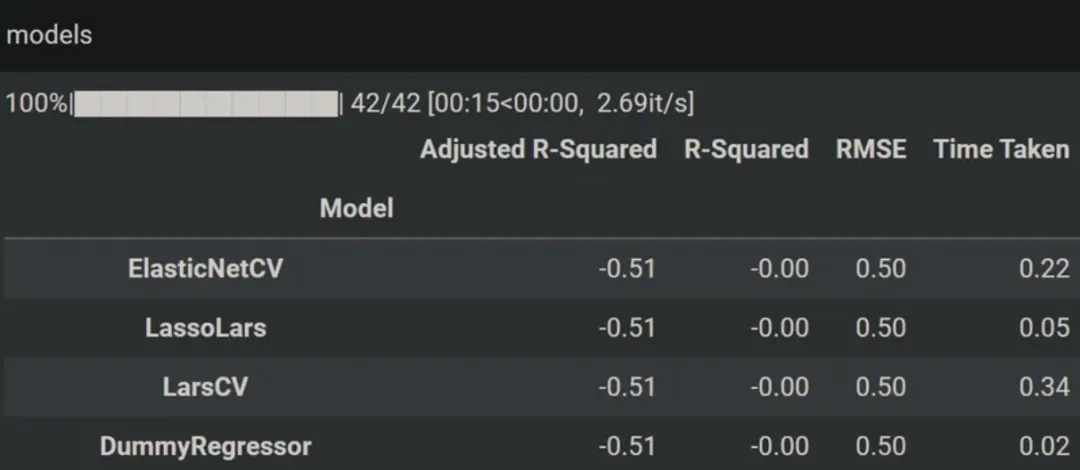
它在我的回归问题上实现了**42 个 ML 模型,**因为本指南更侧重于如何测试许多模型,而不是提高其准确性。所以我对每个模型的准确性不感兴趣。
查看每个模型的预测。
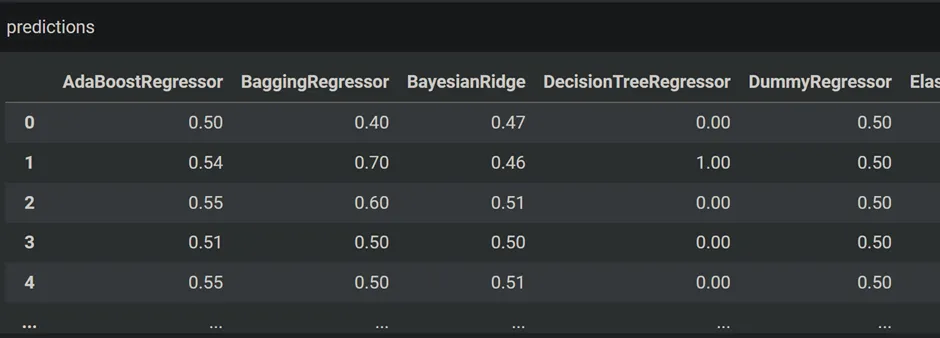
你可以利用这些预测来创建一个混淆矩阵。
如果正在处理分类问题,这就是使用 lazypredict 库的方法。
# 使用 LazyRegressor 定义模型
multiple_ML_model = lazyClassifier(verbose=0,
ignore_warnings=True,
predictions=True)
# 对模型进行拟合,并预测每个模型的输出结果
models, predictions = multiple_ML_model.fit(
X_train, X_test, y_train, y_test)
要记住的要点:
-
这个库仅用于测试目的,为提供有关哪种模型在您的数据集上表现良好的信息。
-
建议使用conda单独建立一个虚拟环境,因为它提供了一个单独的环境,避免与其他环境有版本冲突。
推荐阅读 点击标题可跳转
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240710/%E5%BA%94%E7%94%A840%E4%B8%AA%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E7%9A%84%E4%BB%A3%E7%A0%81%E7%A4%BA%E4%BE%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


