大模型时代知识图谱赋能高血压智能诊疗实践 --知识铺

导读 本文将分享知识图谱构建、推理与问答技术,在高血压智能诊疗场景中的一些探索和实践。首先以“精准用药决策”这个问题为例,介绍高血压诊疗场景中面临的“以知识为驱动”的复杂决策任务的特点,并对当前医学领域中该类任务在通用大模型上的表现进行评测,介绍大模型在该类问题上的不足之处。然后从知识图谱建模、推理与问答三个方面,围绕高血压智能诊疗领域,递进讲解构建层次化超关系知识图谱、神经符号精准推理以及结合大模型驱动的可解释智能问答相关工作。最后,介绍相关技术在实际场景的落地应用情况,并探讨在未来方向上的思考。
今天的介绍会围绕下面六点展开:
1. 医学诊疗复杂决策任务
2. 层次化超关系知识建模
3. 神经符号多跳逻辑推理
4. 大模型驱动的智能问答
5. 高血压智能诊疗的实践
6. Q&A
分享嘉宾|鄂海红 北京邮电大学 北京邮电大学教授,博士生导师,教育部信息网络工程研究中心副主任
编辑整理|王吉东
内容校对|李瑶
出品社区|DataFun
01
医学诊疗复杂决策任务
1. 为什么选择高血压智能诊疗
在高血压知识图谱研究工作初期,有幸遇到了北京安贞医院的匡泽民主任,在这样的契机下,我们了解到高血压是重大的公共卫生问题,一方面是患者的基数巨大,带来的潜在危害也大;另一方面,当前基层医疗机构的临床服务能力薄弱,难以应对重大基数的患者人群,因此急需这类智能诊疗服务来缓解医疗资源的紧缺。

而高血压智能诊疗,在决策的过程中,需要非常专业的医学知识进行精密的推理和决策,才能有效地形成准确的医学诊疗结论。一方面,我们会面临类型多、表示难的知识建模挑战;另一方面,我们又希望模型的推理精准,且过程具有可解释性。
2. 高血压诊疗推理决策难
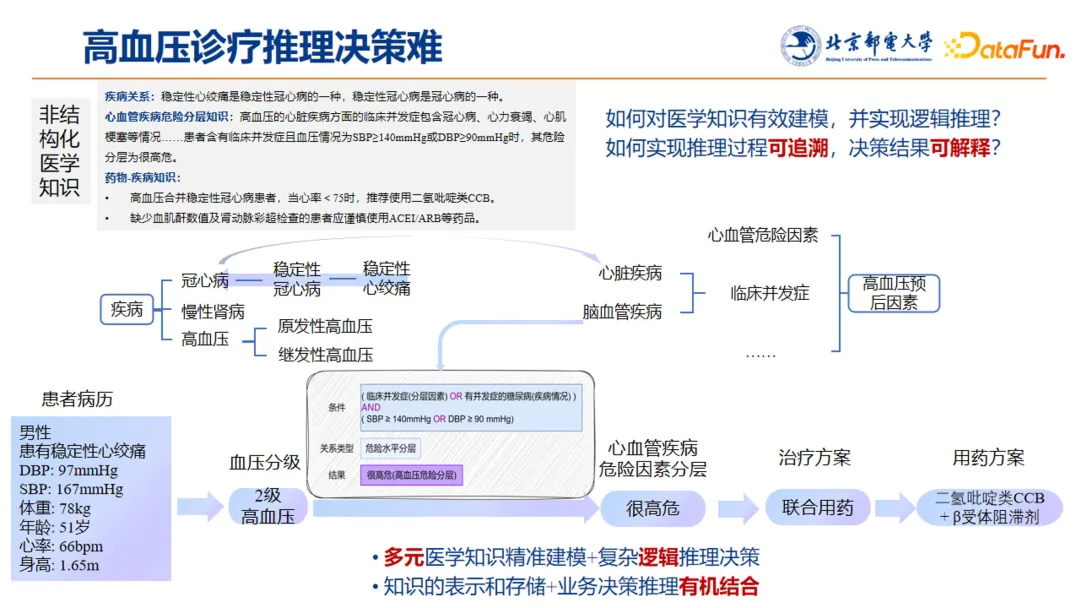
上图左下角描述了一个患者的病例。在实际临床诊断中,医生看到该患者的病历之后,会逐步进行以下诊断步骤:
-
血压分级
-
心血管疾病危险因素分层
-
判断是否需要用药,以及用单药还是联合用药
-
制定和决策具体用药方案
上述这类多步决策任务,依赖的知识非常多,比如疾病关系、心血管疾病危险因素分层知识、药物-疾病知识等。
以“心血管疾病危险因素分层”为例,其决策依据是,当患者患有临床并发症,且血压的高压大于 140 或低压大于 90 的情况下,其危险分层判断为“很高危”。该患者的实际情况是“稳定性心绞痛”,而诊断指南的表述是“临床并发症”,因此需要一套中间结构化的知识进行表达。“稳定性心绞痛”可向上追溯到“冠心病”,而冠心病作为心脏疾病,属于临床并发症。综上,该患者情况为有临床并发症,且血压高压大于 140,因此危险分层为“很高危”。
基于患者现在的血压水平,以及并发症有冠心病,进而决策需要联合用药,同时需要考虑疾病药物知识:高血压合并冠心病的患者,当心率小于 75 的时候,推荐使用 CCB;同时,由于该患者未提供血肌酐的检查,因此慎用 ARB 和 ACEI。
虽然高血压诊断本身看起来难度其实并不大,但是在实际的临床诊断中,很多患者的血压却并没有得到有效的控制,主要是因为个性化精准用药尚未有效普及。因此团队的研究工作主要在于,希望通过实现 AI 数字医生赋能基层医疗服务及养老服务,实现患者精准用药,有效控制血压,避免发生卒中等危及生命情况。
以上是该研发项目的初衷,我们围绕这项工作已经陆续开展了 5-6 年的研究。
3. 实现“智慧—复杂决策”仍有漫长道路
大模型时代,为垂域 AI 的实现提供了更好的语义理解和文本生成智能基座。我们先一起来看看,在复杂的高血压智能诊疗场景中,大模型的能力如何?
(1)GPT4

将上述男性患者的信息描述输入到 GPT4 大模型中,得到的诊断结果是二级高血压。这个结论其实是正确的,但是给出的治疗建议,以及药物治疗、监测与随访所描述的内容,实际上是来源于一篇医学文献的概述描述,即概括性地表达了高血压患者可以使用的药物,但是并没有针对该患者生成个性化的诊疗方案。此外,对于心血管危险评估方面的结论(即“很高危”这一结论),以及 CCB 加 β-阻滞剂等治疗方案,大模型均没有提供出来。
(2)部分医学大模型
我们还进一步测试了一些国产医学大模型,这些大模型给出了相关高血压的医学概念的解释,以及药物一般选择的方向,并提出患者在治疗上需要谨慎。但是对于血压分级、危险分层和药物治疗方案等都没有给出。
综上,无论是 GPT4,还是领域微调后的医学大模型,在高血压精准用药领域得出的结论都不够理想,因此实现智慧的复杂决策,在医学这种垂直场景中仍有漫长的道路。
(3)基于知识图谱的高血压智能诊疗引擎
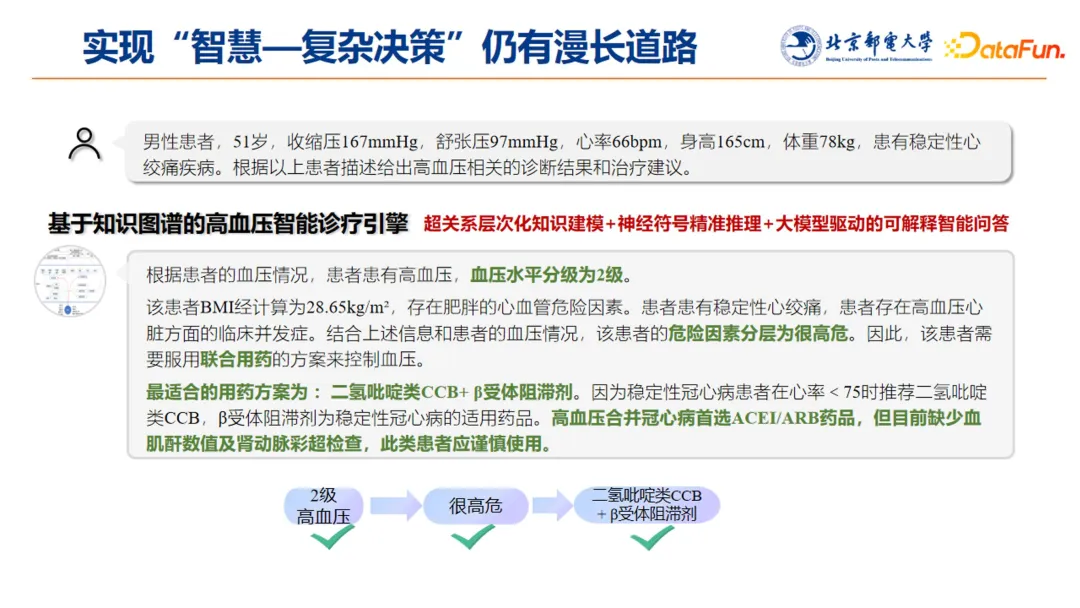
上图是我们研发的“基于知识图谱的高血压智能诊疗引擎”给出的答案,能够正确识别出该患者的血压分级是二级,危险因素是很高危,需要联合用药,最适用的药物方案为 CCB 加 β-阻滞剂。同时还提供了诊断依据,即不仅给出结论,还给出了可解释性的回答。
这个工作的结果是得益于我们开展的超关系层次化知识图谱的建模,神经符号精准推理方法的研究,以及结合大模型驱动来做可解释的智能问答。
4. 近期研究进展
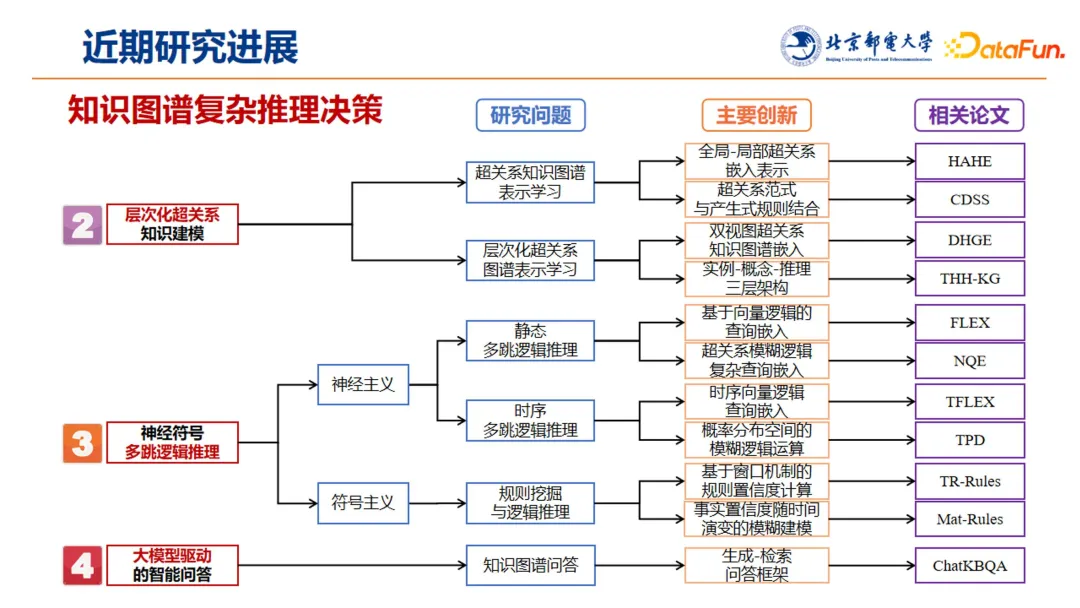
实验室团队近期围绕知识图谱的复杂推理决策,开展了层次化超关系的知识建模,多跳逻辑推理以及大模型驱动的智能问答等方面的工作。本文会对每个方向,选择 2-3 个代表性的工作来介绍,并且在最后会针对 ChatKBQA(即大模型驱动的智能问答)展开较为详细的介绍。
02
层次化超关系知识建模
1. 层次化超关系知识建模
首先介绍层次化超关系知识建模的工作,该项工作从两个方面展开:
-
超关系知识图谱建模
-
层次化的表示学习
这项工作主要的创新性成果包括:
-
全局-局部超关系的嵌入表示——HAHE
-
超关系范式与产生式规则结合的高血压决策——CDSS
-
双视图超关系知识图谱嵌入——DHGE
-
实例-概念-推理三层架构——THH-KG
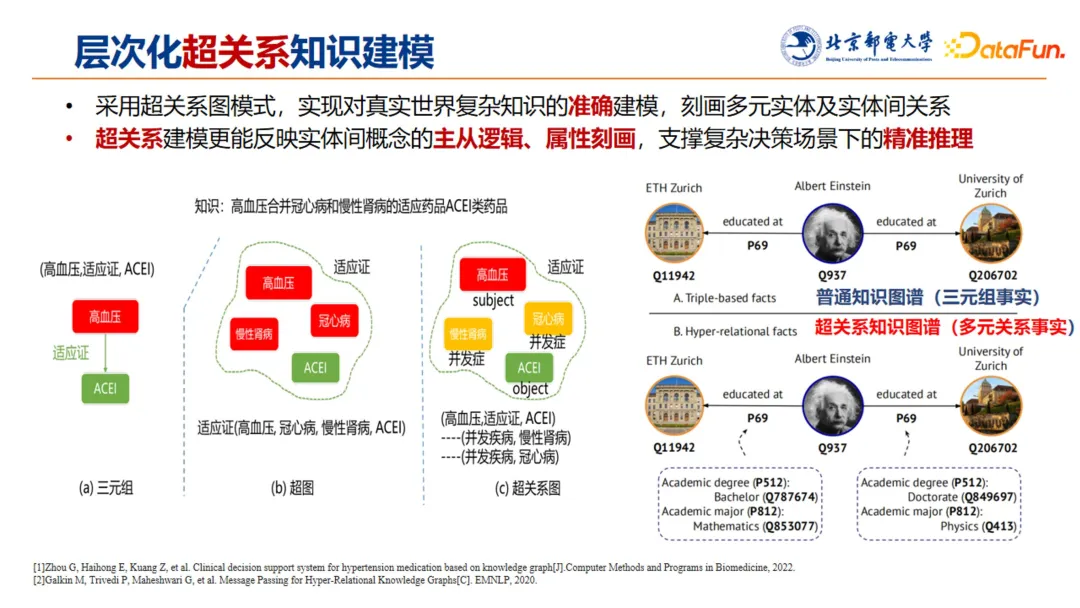
传统的三元组往往难以有效刻画真实世界中的复杂知识。以上图左侧为例,高血压合并冠心病和慢性肾病的适用药物是 ACEI 类药品。如果使用最简单的三元组,得到的知识结构化建模其实是不准确的,会带来误差,基于此进行推理,无法有效得出正确结论。另一方面,使用超图模式,又不能有效刻画主从逻辑。
实际上,这条知识的正确刻画应该是高血压并发慢性肾病和冠心病时适用于 ACEI,使用我们提出的超关系图这种方式,来建模高血压的问题,能更有效地反映真实世界中的复杂知识,进一步能够支持复杂决策下的精准推理。
2. 超关系知识建模结构
基于以上原因,在高血压领域采用超关系的方式进行建模。
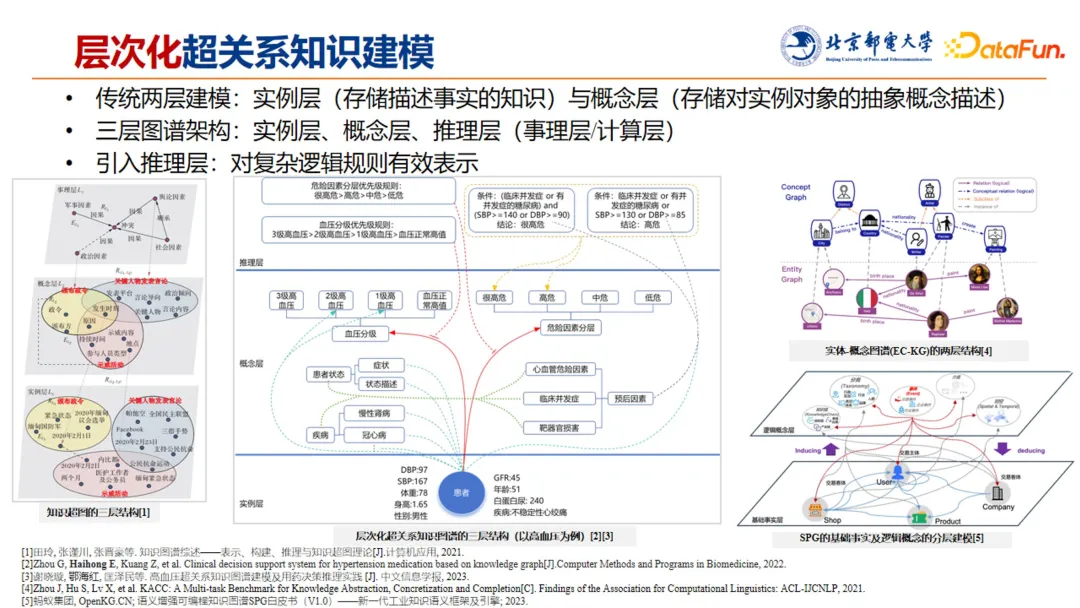
传统的两层建模是将知识图谱建模成实例层和概念层(如上图中右侧的两张图所示):实例层描述客观事实,概念层对客观事实进行概念抽象描述。然而,使用这种两层描述,只能反映患者的实例和医学知识的表达,但无法表示患者的血压状态、并发症情况、危险分层等复杂逻辑规则,因此很难完成最后的推理计算。
在此基础上,受到田林老师在 2021 年提出的知识超图三层架构表述的启发,团队提出了三层建模架构,在传统的实例层和概念层的基础上加入推理层(也叫计算层),用来进行第三层复杂逻辑规则的表示,并支撑后续推理工作。
3. 超关系知识图谱表示学习
本节介绍建模工作的一些相关成果。
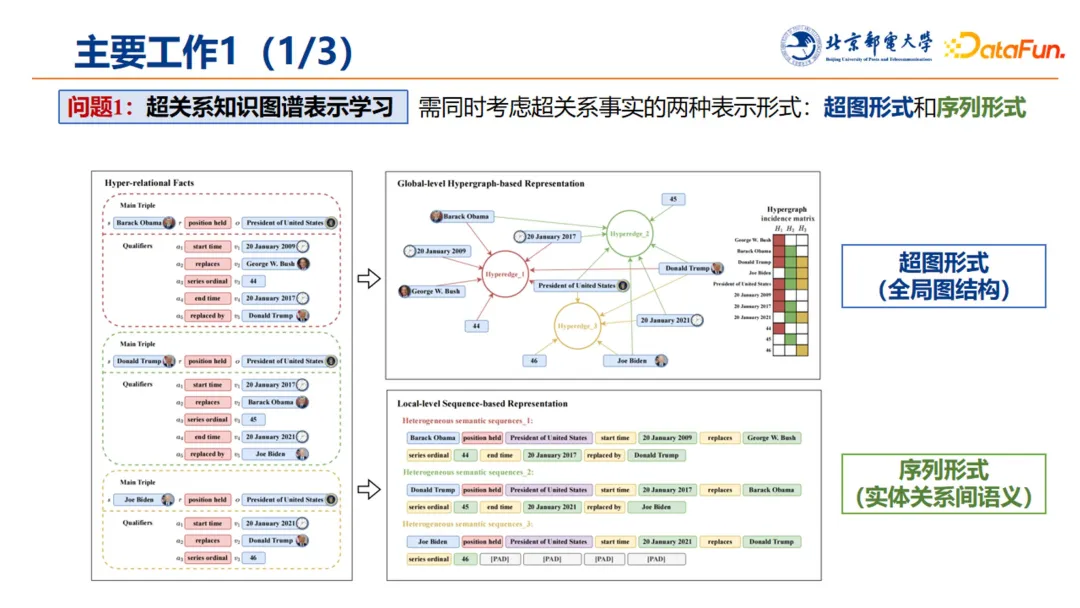
首先是传统二元表示无法有效刻画知识,并提出了超关系知识图谱的建模。在建模过程中,我们需要同时考虑超关系事实的两种表示形式:
-
超图形式:采用全局的图结构;
-
序列形式:刻画实体关系间的语义信息。
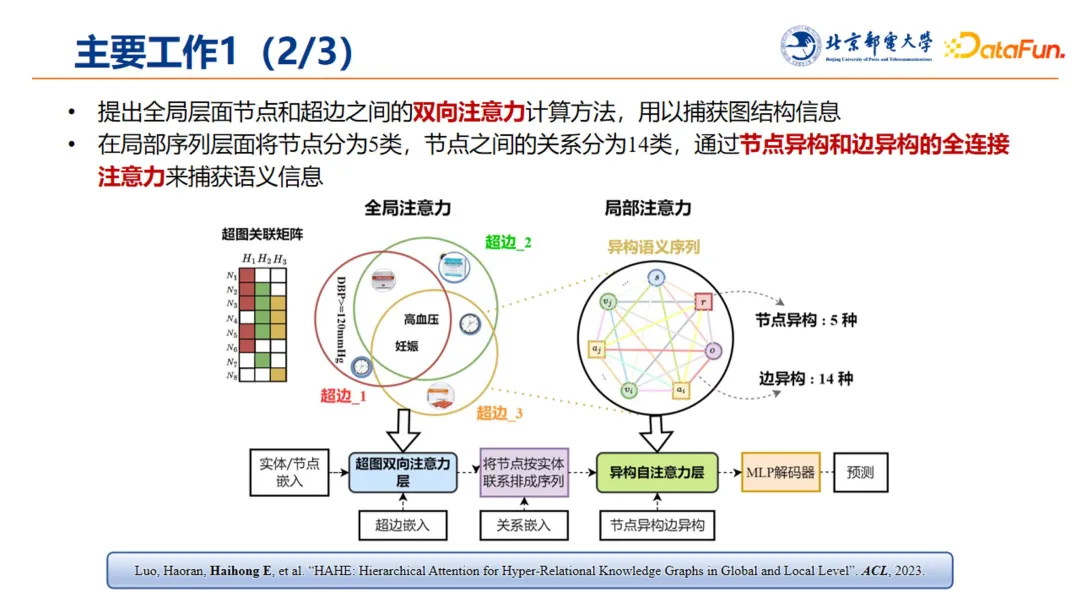
在这样的思想下,团队提出全局层面节点和超边之间的双向注意力计算方法,用于捕获图的结构信息。在局部序列层面上,将节点分成 5 类,关系分成 14 类,通过节点异构和边异构的全连接注意力来捕获语义信息。
可以关注在去年发表在 ACL2023 的文章,了解 HAHE 的相关工作:
Luo, Haoran, Haihong E, et al. “HAHE: Hierarchical Attention for Hyper-Relational Knowledge Graphs in Global and Local Level”. ACL, 2023
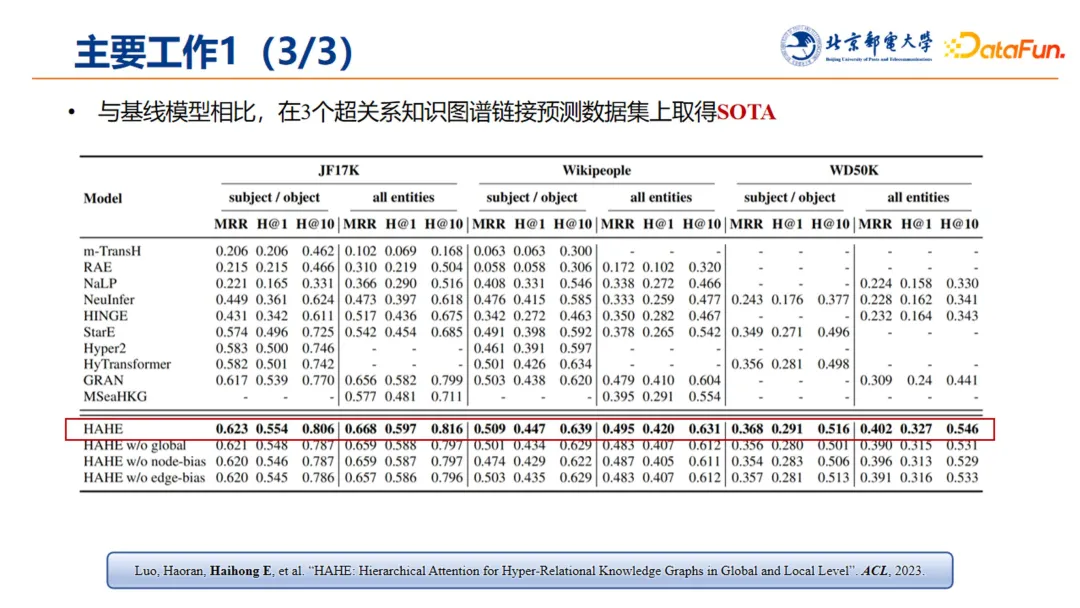
与基线模型相比,HAHE 在三个超关系知识图谱链接预测任务上取得了 SOTA 的表现。
4. 层次化超关系图谱建模与表示学习
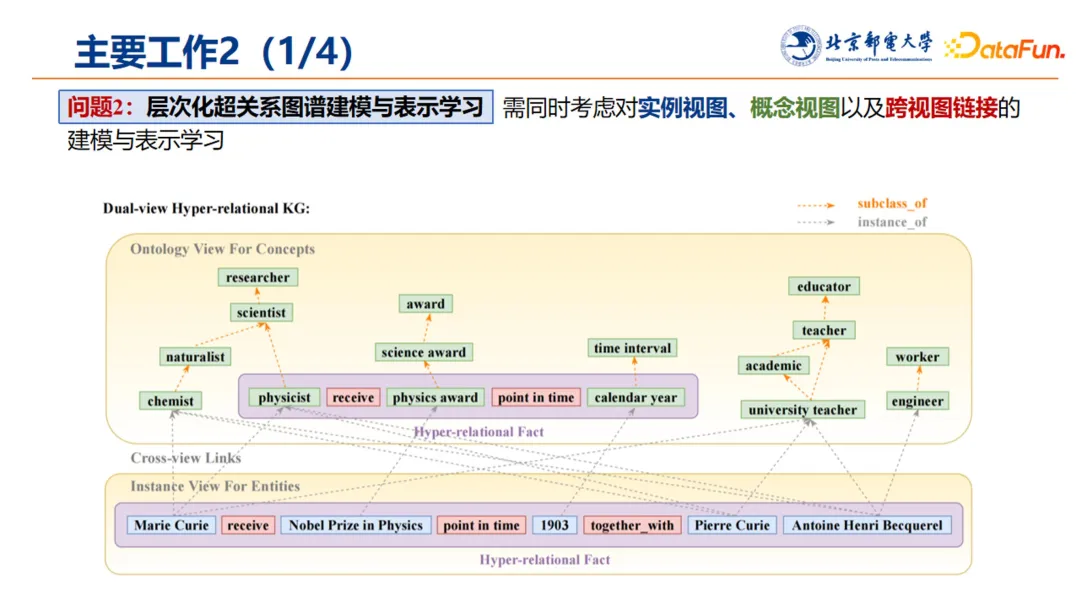
对于层次化超关系图谱建模,需要同时考虑实例视图、概念视图以及跨视图链接的建模与表示学习。当然,在 HAHE 工作过程中,受制于公开数据集知识建模的不完备情况,缺少知识数据完整地对第三层(推理计算层)进行建模;因此这部分工作以两层入手,着力解决两层层次化知识图谱建模以及层次化跨视图链接任务的有效表示,并进行链接推理。
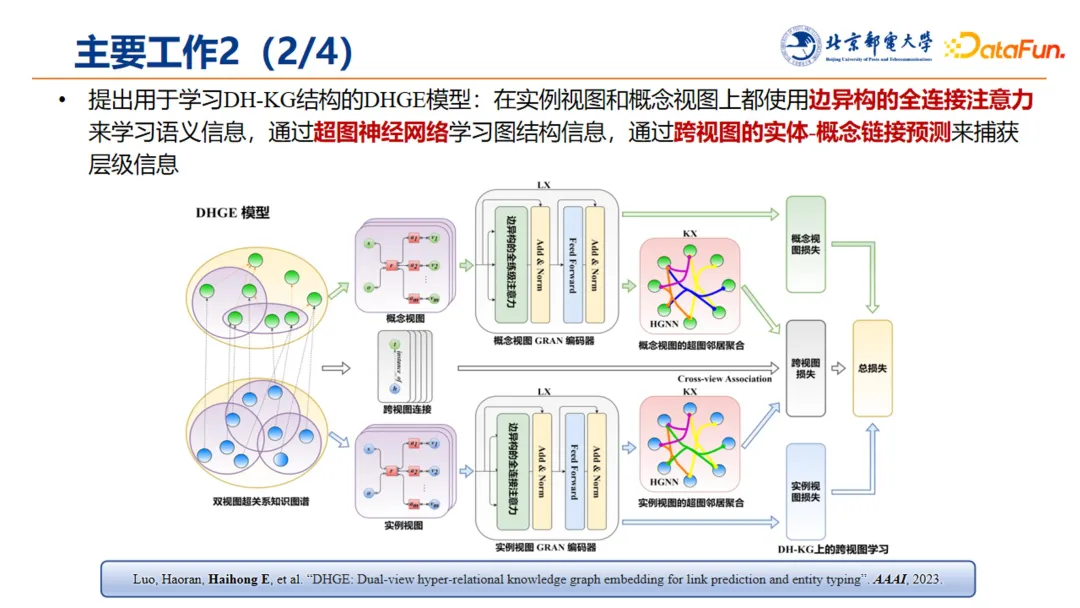
团队提出了用于学习 DH-KG 结构的 DHGE 模型,在实例视图和概念视图上都使用边异构的全连接注意力来学习语义信息,通过超图神经网络学习图结构信息,通过跨视图的实体-概念链接预测捕获层级信息。
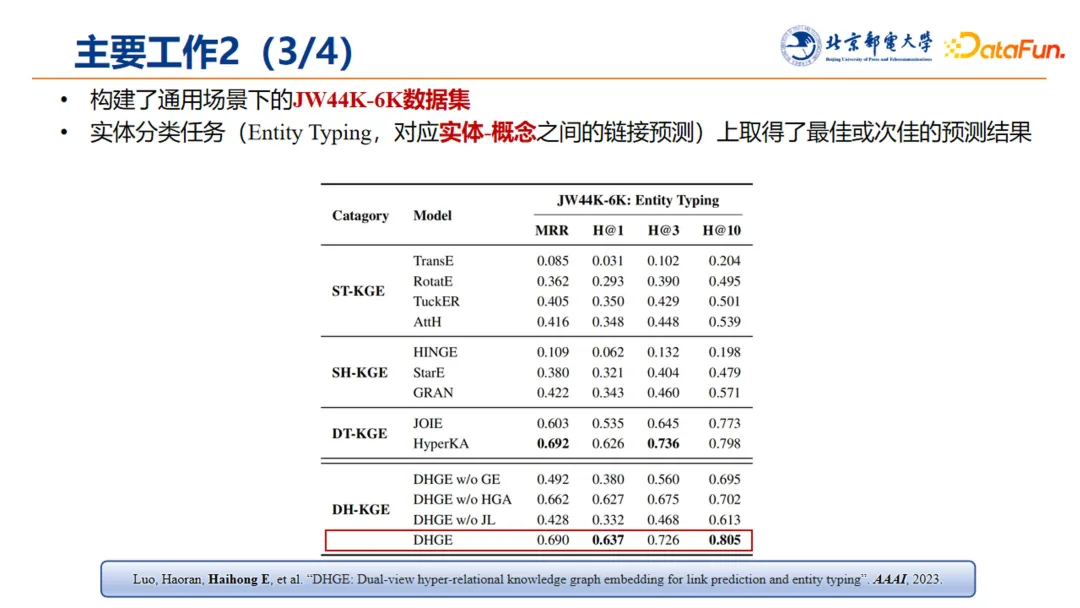
为验证该方法的效果,构建了通用场景下的 JW44K-6K 数据集。该方法在实体分类任务(即实体和概念之间的链接预测)中取得了良好的预测结果,从而证明了该方法的有效性。
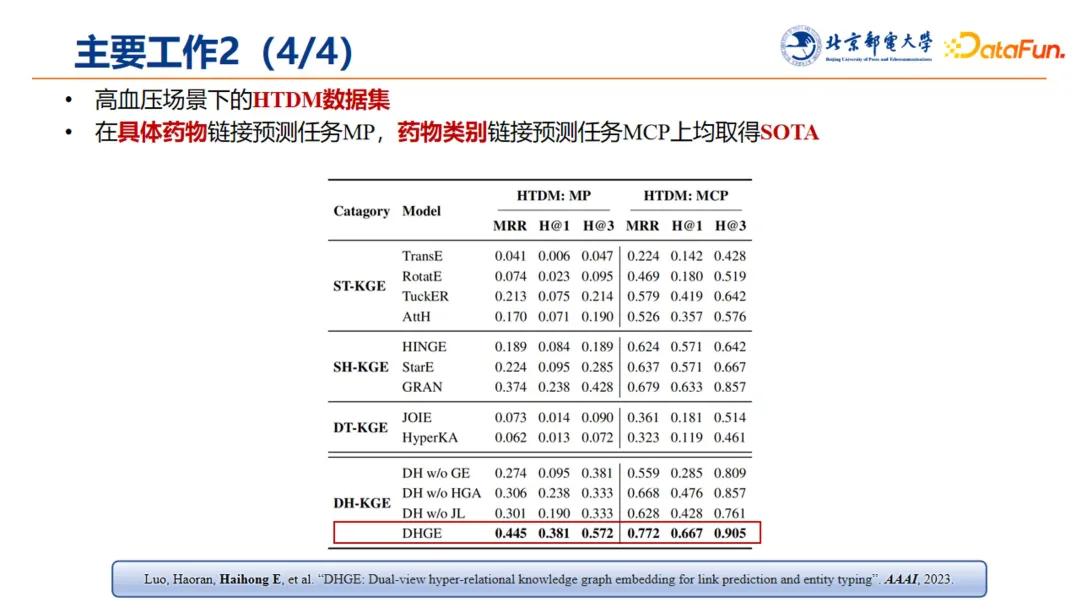
进一步,结合高血压场景下的探索,构建了高血压任务的数据集,将该任务建模成具体药物链接预测任务 MP,和药物类别链接预测任务 MCP。我们的方法在这两项预测任务中均取得了 SOTA 的表现。
该 DHGE 工作已经发表在 AAAI2023 上:
Luo, Haoran, Haihong E, et al. “DHGE: Dual-view hyper-relational knowledge graph embedding for link prediction and entity typing”.AAAI, 2023
03
神经符号多跳逻辑推理
1. 多跳逻辑推理任务
多跳逻辑推理任务分为神经和符号两个方向,而在神经方向上又分成静态多跳逻辑推理和时序多跳逻辑推理两类。对于静态多跳逻辑推理,提出了基于向量逻辑的查询嵌入表示,以及超关系模糊逻辑的复杂查询嵌入表示;对于时序任务,进一步思考了时序向量逻辑,以及概率分布空间下的模糊逻辑运算方式,从而进行时序多跳逻辑推理。
对于上述两条技术路线,我们也在思考这两条技术路线的融合,希望在表述清楚医学决策逻辑的成立条件以及与或非的情况下,如何推理结论,实现对输入的自然语言进行有效的知识推理从而得到有效的诊断结论。
本节主要介绍我们的 FLEX、NQE 和 TFLEX 的工作。
2. 静态多跳逻辑推理
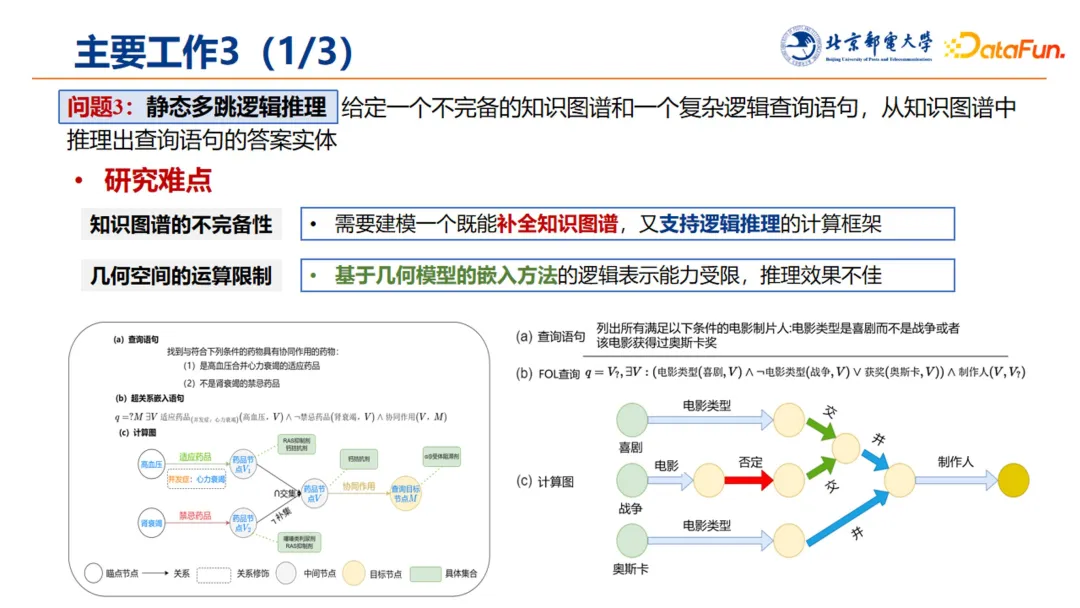
在多跳逻辑推理任务中,首先考虑静态问题,其含义是,给定一个不完备的知识图谱和一个复杂逻辑查询语句,从知识图谱中推理出查询语句的答案实体。
这项工作遇到的挑战包括:
-
知识图谱的不完备性:需要建模一个工作中既能够有效的补全知识图谱,又能够进行逻辑的、推理的、运算的计算框架;
-
几何空间的运算限制:基于几何模型的嵌入方法,其逻辑表示能力受限,推理效果不佳。
基于此,我们提出了 FLEX 框架。
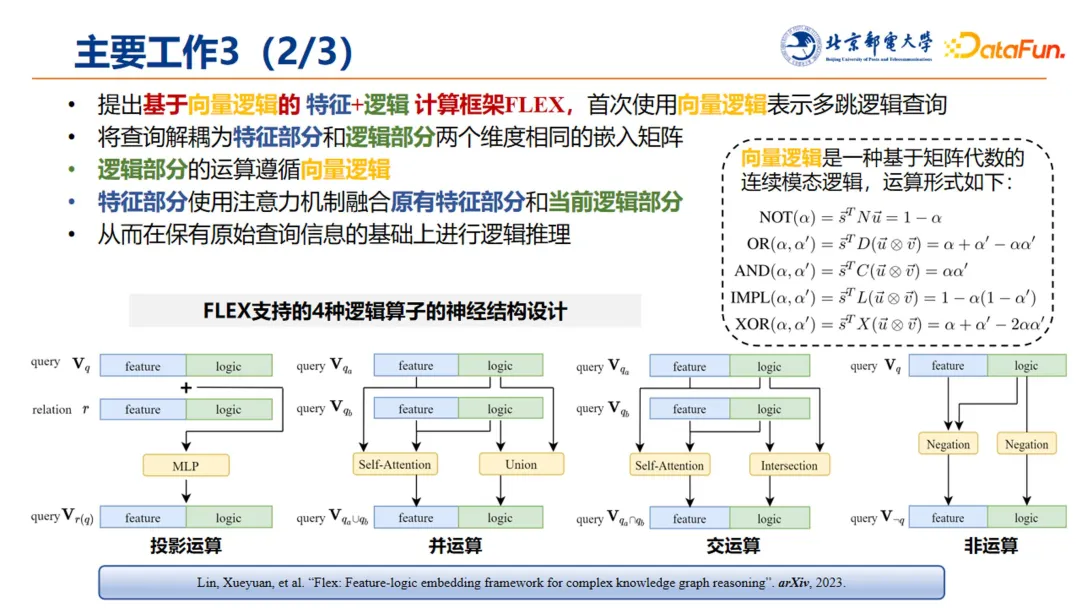
FLEX 框架针对已有方法的不足和局限性,采用基于向量逻辑的特征+逻辑的计算框架,该框架首次使用向量逻辑表示多跳逻辑查询,将查询解耦成特征部分(即语义刻画)和逻辑部分(包括投影运算,以及并、交、非等一阶逻辑运算)两个维度相同的嵌入矩阵。逻辑部分的运算遵循向量逻辑,而特征部分则使用注意力机制融合原有特征部分和当前逻辑部分,从而在保有原始查询信息的基础上进行逻辑推理。
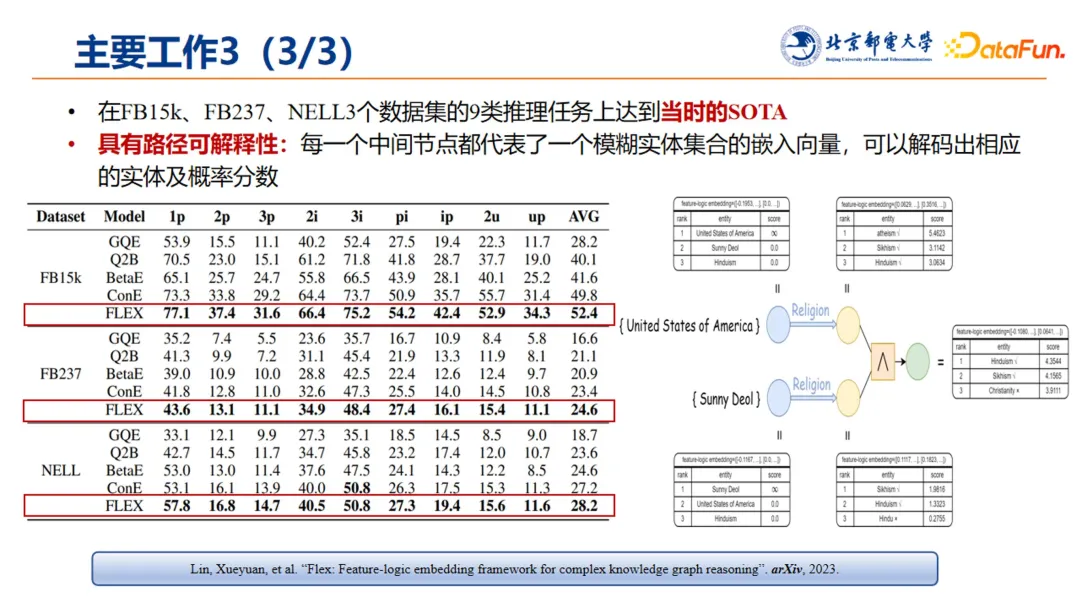
我们采用了全新的框架和思想来解决问题,尤其是对逻辑推理中的逻辑算子实现了完备的刻画。这项工作在 FB15k、FB237、NELL 这 3 个数据集的 9 类推理任务上达到了当时的 SOTA。
此外,每个中间节点都代表一个模糊实体集合的嵌入向量,可以解码出相应的实体和概率分数,使模型具备路径可解释性。这项工作目前可以通过 arXiv 上的预印版来了解:
Lin, Xueyuan, et al. “Flex: Feature-logic embedding framework for complex knowledge graph reasoning”. arXiv, 2023.
3. 超关系多跳逻辑推理
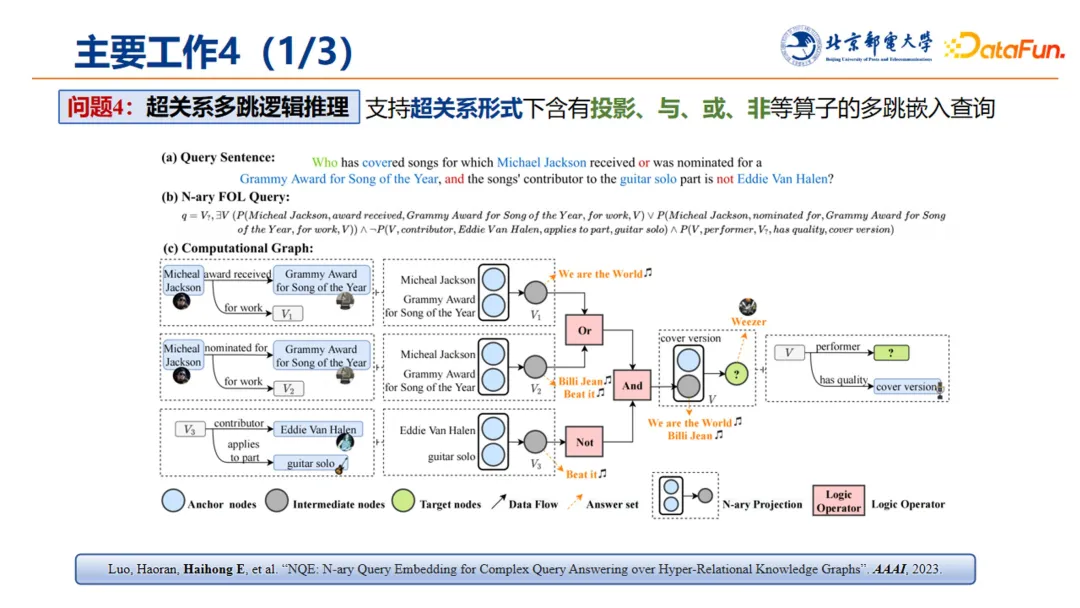
在上述工作的基础上,进一步结合高血压场景中提出的超关系建模这一范式,进行超关系多跳逻辑推理。在超关系场景下,主要问题在于,需要支持超图形式下的投影,以及与、或、非等算子的多跳嵌入查询。
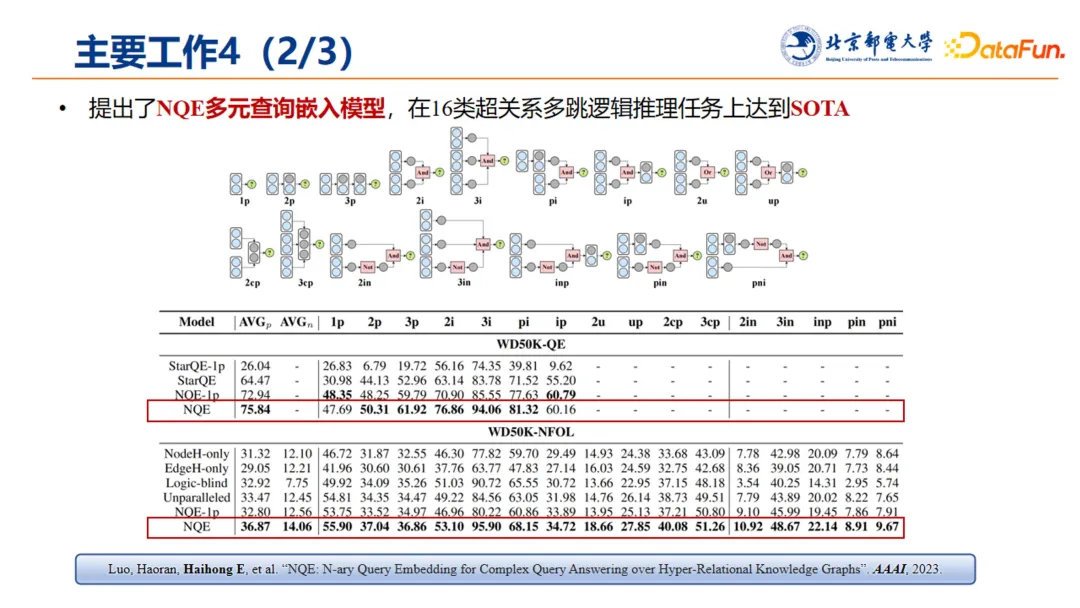
基于上述背景,提出了 NQE 多元查询嵌入模型,实现了在 16 类超关系多跳逻辑推理任务上达到 SOTA 表现。这项工作发表在 2023 年的 AAAI 上:
Luo, Haoran, Haihong E, et al. “NOE: N-ary Query Embedding for Complex Query Answering over Hype-Relational Knowledge Graphs”. AAAI, 2023
论文中可以看到实验的结果,也反映出我们方法的效果。

FLEX 工作的目标是在多跳逻辑查询推理过程中,能够最终反映出可解释性的路径,这也是我们工作的一个特点。
4. 时序多跳逻辑推理
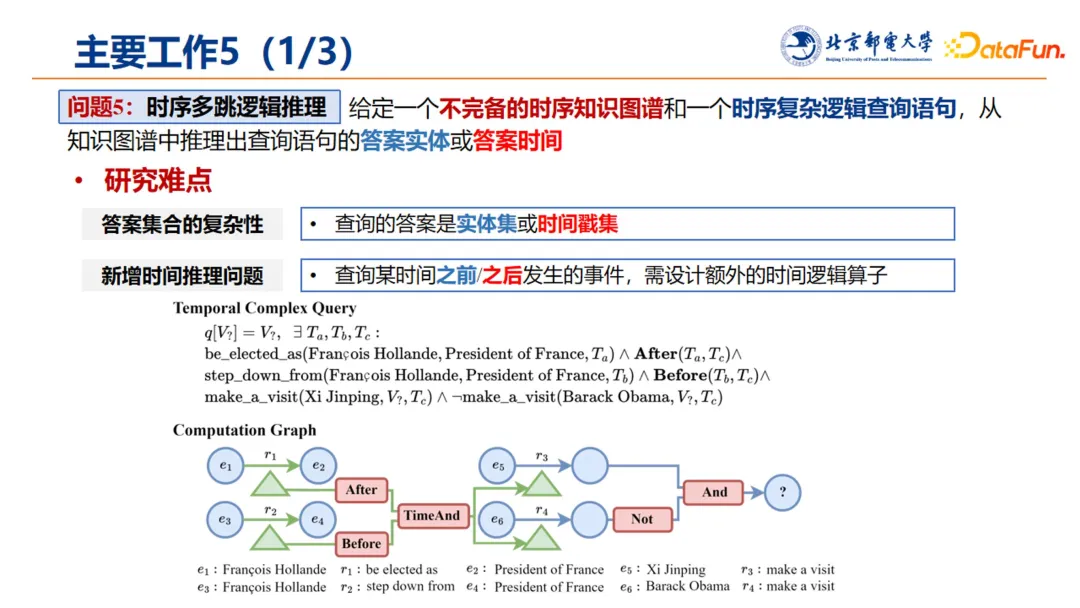
时序多跳逻辑推理指的是,给定一个不完备的时序知识图谱和一个时序复杂逻辑查询语句,从知识图谱中推理出查询语句的答案实体或者是答案时间。因此,问题的复杂性进一步增加:查询答案既要包含实体集,又要包含时间戳集,还要新增时间推理问题,如查询某时间点之前或之后发生某件事件的概率,这样就需要额外设计时间逻辑算子。

将前文提到的 FLEX 工作扩展到时序场景,提出了 TFLEX,将特征+逻辑计算框架拓展到了时序知识图谱场景,引入了时序特征+时序逻辑,形成了四重特征表示框架,使用注意力机制保证特征与逻辑之间的联系。
此外,针对时间先后问题,提出 2 种拓展的时间算子 Before、After,设计时序模糊逻辑来实现时间算子,最终实现时间逻辑的推理。
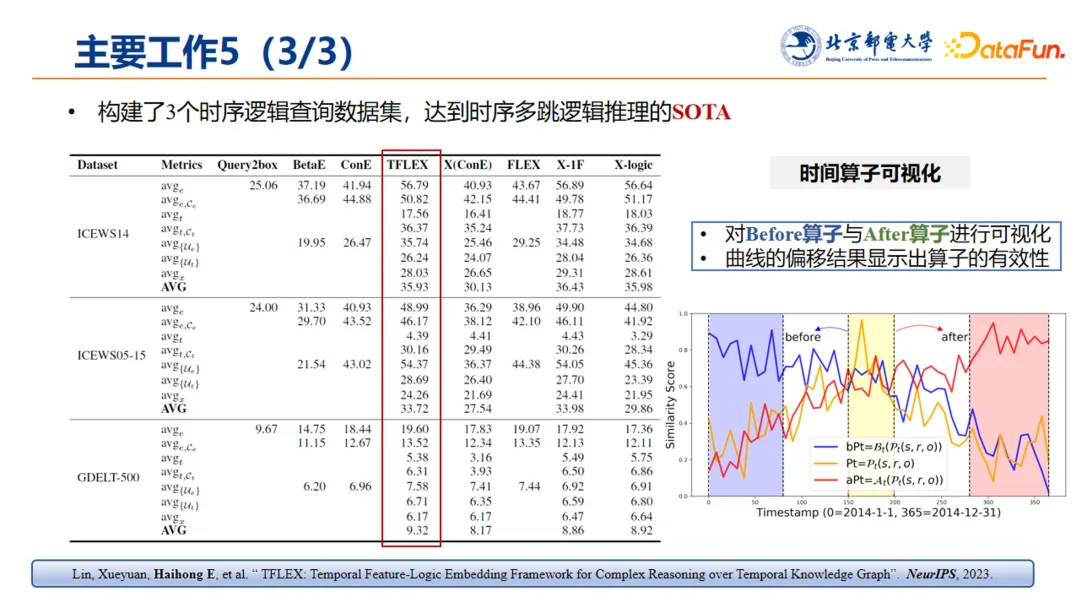
这项工作构建了 3 个时序逻辑查询数据集,通过实验证明该方法在时序多跳逻辑推理上达到 SOTA 表现。
进一步,论文中还提供了 before 算子和 after 算子的可视化,通过可视化的展现曲线的偏移结果,显示出算子的有效性,以及 before 算子和 after 算子的刻画能力。
TFLEX 方法已经发表在 NeurIPS2023(在这个方向上我们还持续开展了后续工作,待发表后和同行们继续分享):
Lin,Xueyuan, HaihongE,et al." TFLE%: Temporal Feature Lozic Embedding Framework for Complex Reasoning over Temporal Knowledge Graph". NeurIPS, 2023
04
大模型驱动的智能问答
1. 方法路径
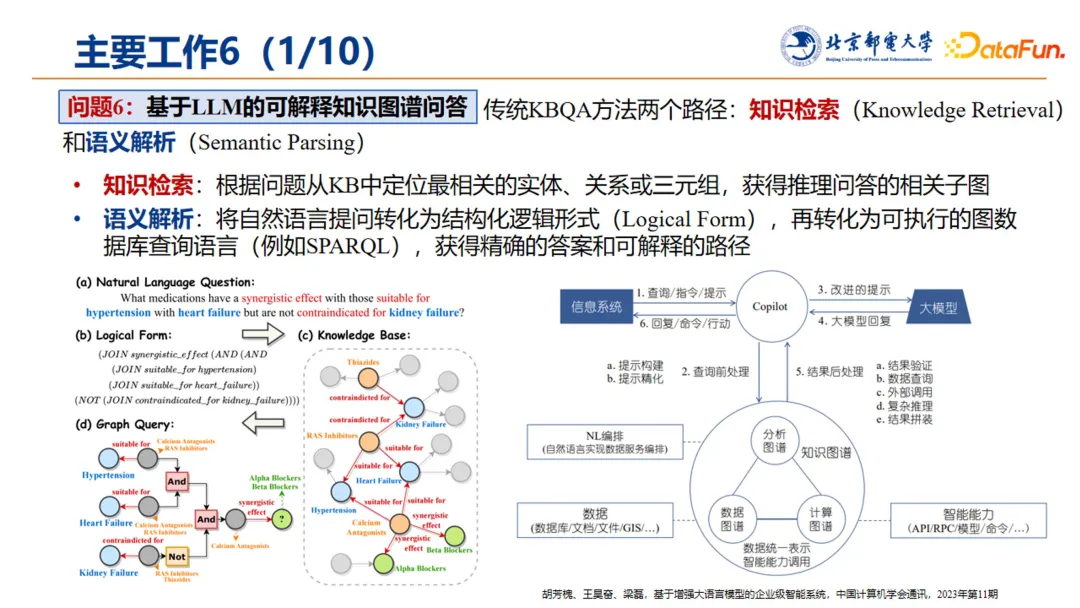
最后介绍一下大模型驱动的智能问答。在解决知识图谱的问答领域,传统的 KBQA 问答问题有知识检索和语义解析这两个解决路径:
-
知识检索:根据问题从知识图谱中定位最相关的实体、关系或三元组,获得推理问答的相关子图。
-
语义解析:将自然语言提问转化为结构化逻辑形式(Logical Form),再转化为可执行的图数据库查询语句(如 SPARQL),获得精准的答案,以及可解释性的路径。
2. 研究难点
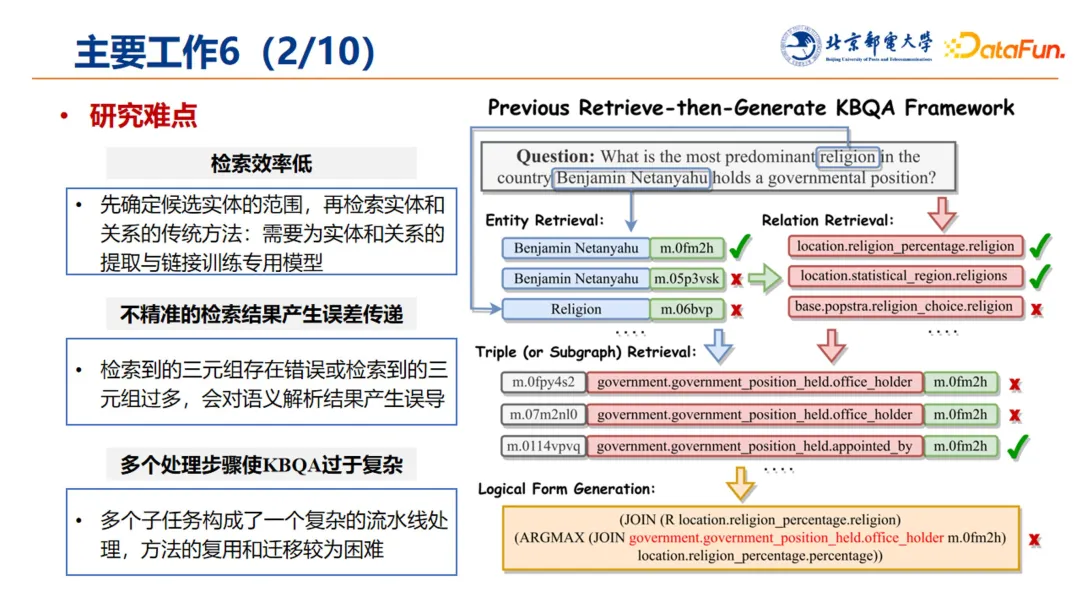
上述传统工作存在一些难点和不足:
-
检索效率低:先确定候选实体的范围,再检索实体和关系的传统方法,需要为实体和关系的提取与链接训练专用模型。
-
不精准的检索结果产生误差传递:检索到的三元组存在错误或检索到的三元组过多,会对语义解析结果产生误导。
-
多个处理步骤使 KBQA 过于复杂:多个子任务构成了一个复杂的流水线处理,方法的复用和迁移较为困难。
3. ChatKBQA 框架的提出
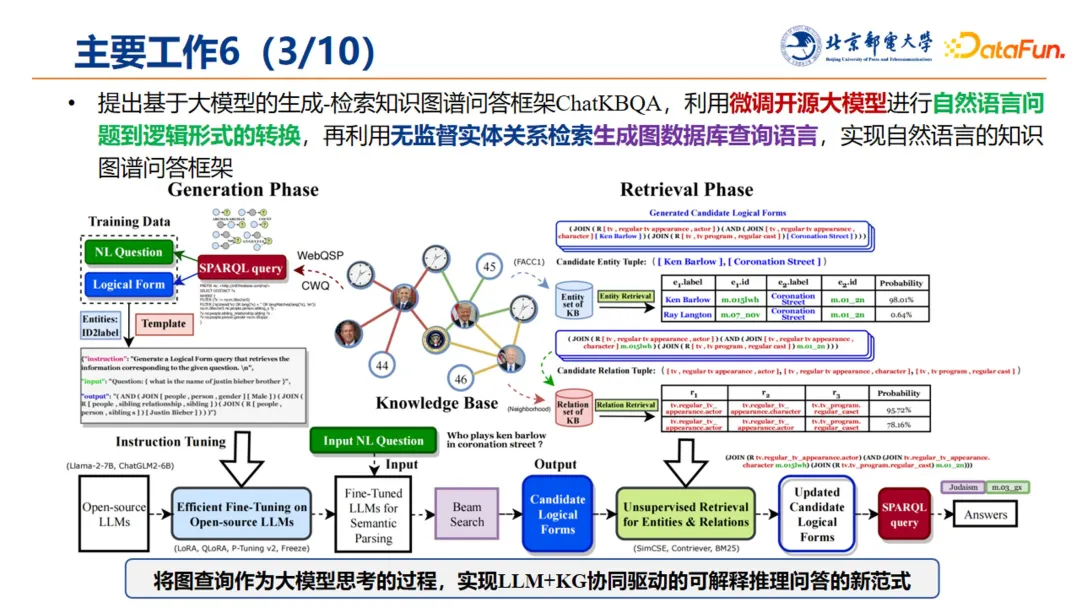
结合大语言模型,我们提出了基于大模型的生成-检索式知识图谱问答框架 ChatKBQA,将图查询作为大模型的思考过程,利用微调的开源大模型进行自然语言问题到逻辑形式的转换,再利用无监督实体关系检索生成图数据库查询语言,实现自然语言的知识图谱问答框架。
4. 大模型的微调
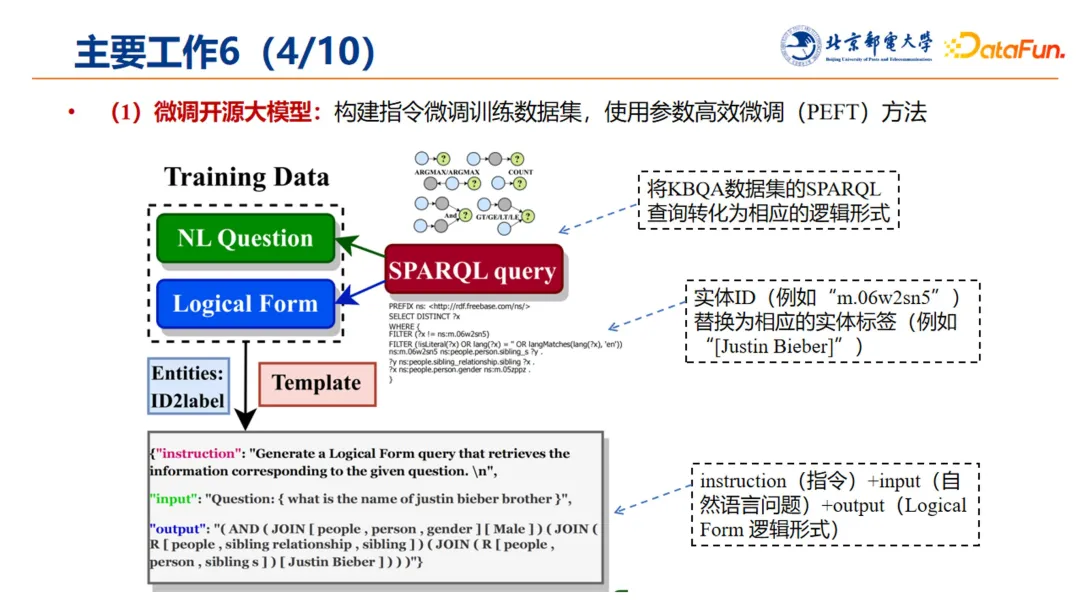
首先,对开源大模型进行微调,从而让模型生成的 Logical Form 足够精准。为构建微调的指令数据集,将传统 KBQA 数据集 SPARQL 的查询转化为相应的逻辑形式,再将逻辑形式中的实体 ID 替换为具有语义含义的实体标签;这样就将数据集构建成上图左下角所示的包含指令、输入(自然语言问题)和输出(Logical Form)的逻辑形式,从而实现在借助已有 KBQA 数据集得到微调大模型对应的训练数据,进行大模型的微调。
5. 逻辑形式的转换
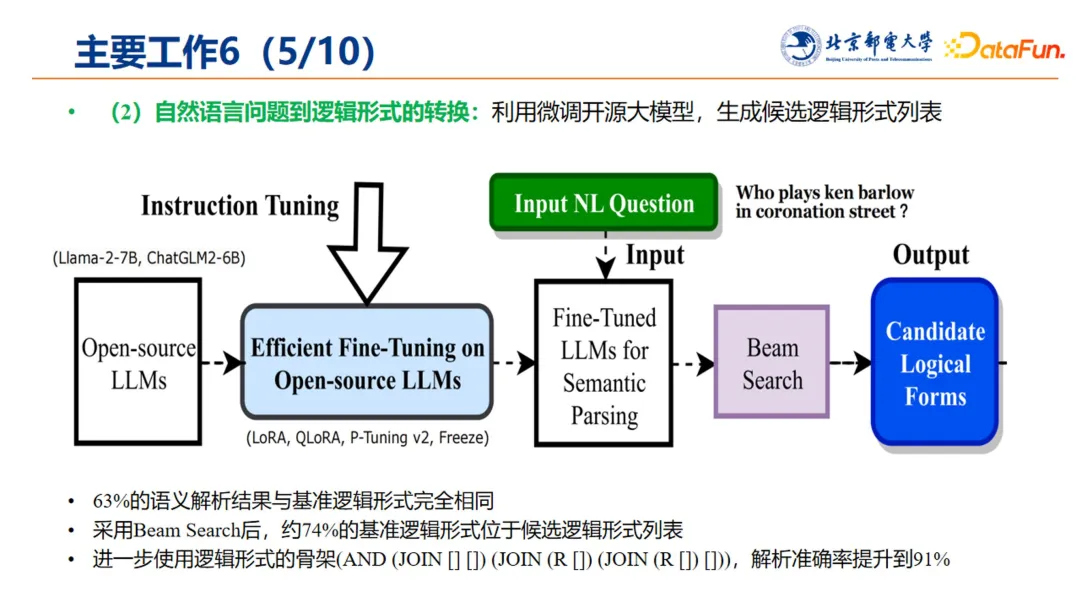
微调后的开源大模型为自然语言问题到逻辑形式的转换提供了工具。
在这个实验中可以看到:
-
63% 的语义解析结果与基准逻辑形式完全相同,说明了微调后的开源大模型的使用效果。
-
采用 Beam Search 后,约 74% 的基准逻辑形式位于候选逻辑形式列表中。
-
使用逻辑形式的骨架(AND (JOIN [][])(JOIN (R [])(JOIN (R [])[]))进行替换后,解析的准确率提升到 91%,为后续的实现提供了重要的基础,并进一步得到候选逻辑形式中的实体和关系。
6. 无监督实体关系检索

采用无监督实体关系检索的方式进行检索和替换,得到最终要执行的候选逻辑形式。这种方式可以避免额外的训练,通过选择在语义上与候选集最相似的前 K 个答案集,经检索得到最终的候选逻辑形式的列表。
7. 图数据库查询语言生成
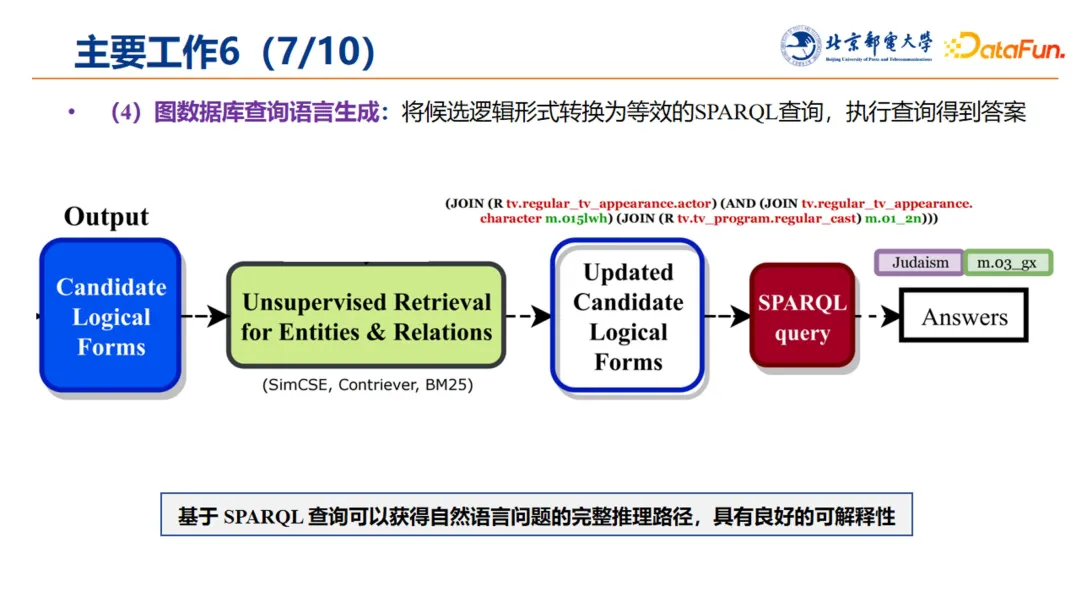
在上述基础上,依次遍历逻辑形式,将候选逻辑形式转换为等效的 SPARQL 查询语句。当找到可以对知识库进行执行的第一个 SPARQL 查询语句后,经过执行该语句最终得到检索答案。
基于 SPARQL 的查询,可以获得自然语言问题的完整推理路径,因此具有良好的可解释性。
8. 模型表现
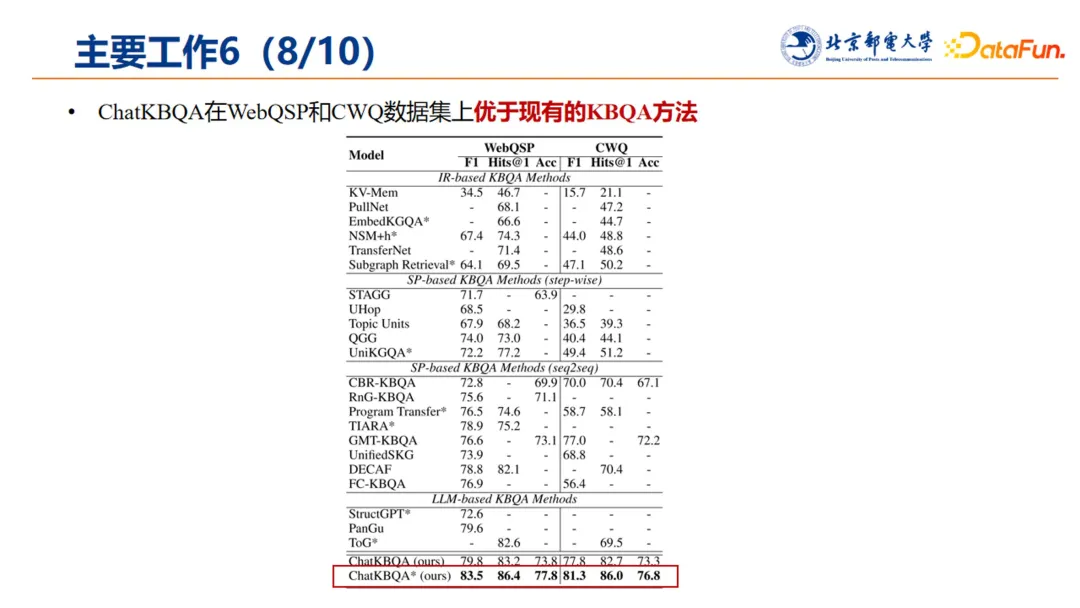
ChatKBQA 在 WebQSP 和 CWQ 数据集进行了评测,效果优于传统 KBQA 方法;推测该方法基于大模型基座,因此具备更优的语义理解能力。
9. 模型特性
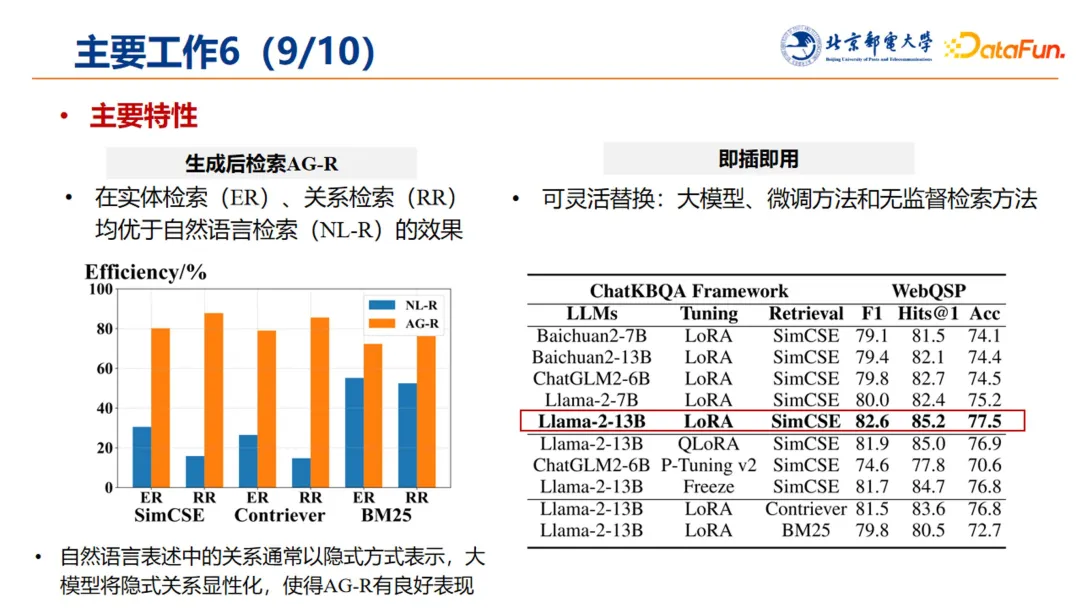
这项工作所提出的 ChatKBQA 框架,主要有两个特性:
(1)生成后检索 AG-R
-
在实体检索(ER)和关系检索(RR)上均优于自然语言检索(NL-R)的效果。
-
究其原因,推测自然语言表述中的关系通常以隐式表示,而大模型通过其语义理解能力,将隐式关系显性化,使得生成后检索具有良好的表现。
(2)即插即用
-
该框架是个即插即用的框架,可以灵活替换基座大模型及其微调方法,以及无监督检索方法等。
-
该框架在垂域落地时,具有良好的灵活性。
10. 工作成果
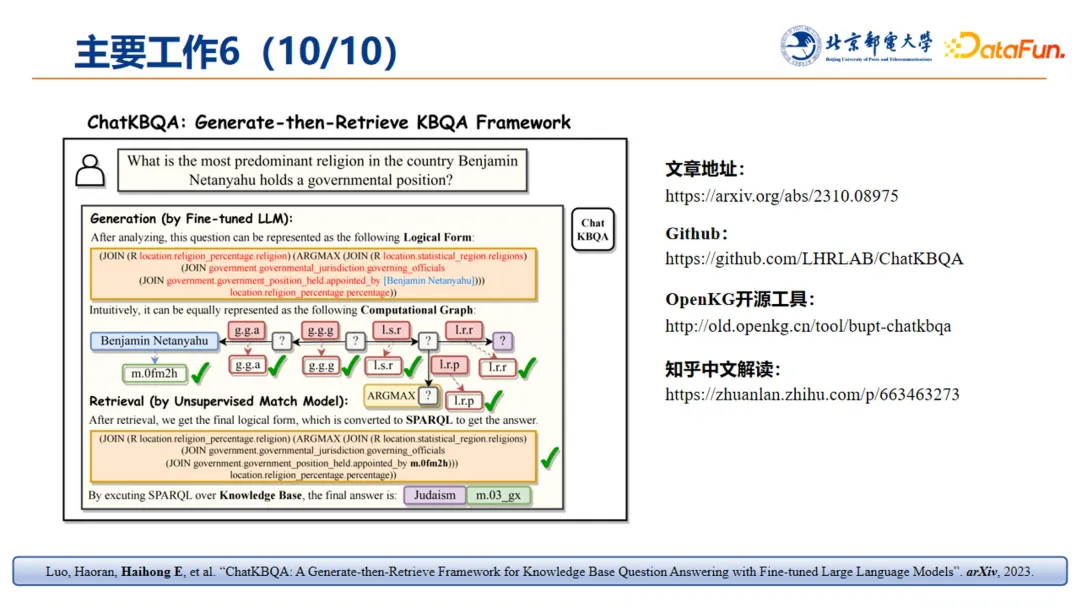
这项工作在去年暑假期间完成后,就在 github 以及 OpenKG 上进行了开源,获得了很多同行的关注。这篇文章有 arXiv 预印版,以及知乎的中文解读版,欢迎关注这方面工作的同行去了解,并开展进一步的交流合作。(备注:这项工作后续录用为 findings of ACL 2024。)
05
高血压智能诊疗的实践
1. 高血压智能诊疗决策支持系统与服务平台

我们研究的医学知识图谱的起源,是要解决高血压智能诊疗问题,伴随着模型算法研究的同时,也在进行系统的开发。
团队与匡泽民主任持续合作,将中国高血压防治指南进行知识结构化,构建了国内首个高精度、高质量的超关系高血压用药知识图谱,进而基于该知识图谱研发了相应的决策知识系统和服务平台,经过 7 位医生参与可行性试验,验证了该方法的有效性,并在 Q1 期刊上发表了在医学人工智能领域的相关论文。
这项工作具体化地展现出研究工作如何真正在垂直的专科领域中进行有效的实现。
这篇论文欢迎同行关注:
Zhou, Gengxian, Haihong E, et al.“Clinical decision support system for hypertension medication based on knowledge graph". Computer Methods and Programs in Biomedicine, 2022
目前这项工作形成的平台系统在北京安贞医院、河北省石家庄中医院等 18 所医院和社区开展应用,为 4000 余名患者提供高血压慢病管理服务。
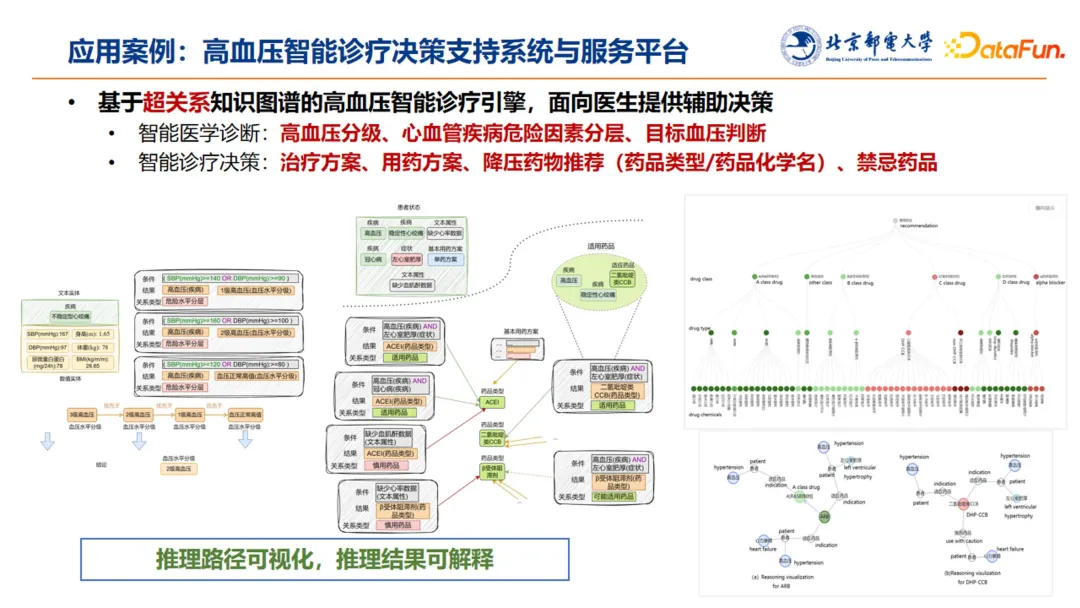
这项工作的核心是研发了基于超关系知识图谱的高血压智能诊疗引擎,面向医生提供辅助决策,包括智能医学诊断和智能诊疗决策两部分:
-
智能医学诊断:高血压分级,心血管疾病的危险因素分层、目标血压判断;
-
智能诊疗决策:治疗方案、用药方案、降压药推荐(药品类型、药品化学名)、禁忌药品。
上图展示了知识结构化的表示,左侧是高血压分级诊断,中间是用药方案。此外,由于推理路径可视化,且推理结果可解释,因此大大增强了模型推理决策结果的可信性。
2. 高血压慢性病管理服务
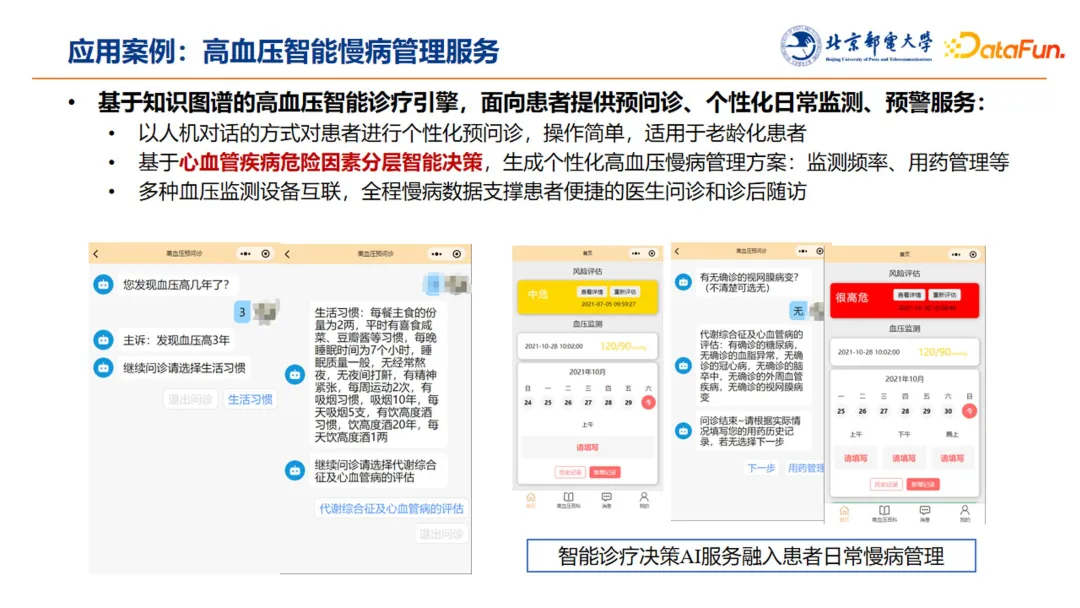
同时我们也将这项工作赋能到患者场景,面向患者侧研发相应小程序,提供预问诊、个性化日常监测和预警服务:
-
以人机对话的方式对患者进行个性化预问诊,操作简单,适用于老龄化患者;
-
基于心血管疾病危险因素分层智能决策,生成个性化高血压慢病管理方案,包括监测频率、用药管理等;
-
多种血压监测设备互联,全程慢病数据支撑患者便捷的医生问诊和诊后随访。
3. 联合研究合作医学专家

在此特别感谢常年合作的匡泽民主任医师,我们工作的起点,就是源自与匡主任的合作,而这项合作已持续 5-6 年时间,以高血压智能诊疗这一话题为载体,开展知识图谱相关的研究工作。在此附上匡泽民主任的电子邮箱,欢迎在医学领域开展探索工作的同行联系我们。
4. 未来工作
最后简要介绍我们对未来工作的思索。
(1)大模型如何高效驱动垂直领域的层次化超关系知识图谱构建?
-
借助大模型的语义理解能力和知识图谱的强结构、强语义的自动 prompts 和样本构建能力
-
帮助知识图谱形成统一的知识抽取框架,加速数据的知识化
不管是结构化的患者数据还是非结构化的医学指南,都是信息的来源;信息被高质量地建模成强语义、强结构,成为知识的有效载体;然后基于知识实现复杂场景下的决策推理。因此需要进一步探索高效、低成本的利用大模型的能力,以及知识图谱本身的强结构、强语义能力,进行垂域的层次化、超关系知识图谱的构建,来加速数据的知识化,助力复杂决策推理能力的提升。
(2)如何在不完备的知识图谱上实现更加精准且可解释的多跳逻辑推理?
- 高效融合:神经网络多跳逻辑查询的泛化推理能力 + 符号逻辑规则查询推理的精准与可解释性
同时,由于难以在一定周期内完成知识图谱的构建,因此推理工作始终会面临在不完备的知识图谱上进行精准的、具有可解释性的多跳逻辑推理。这就推动我们不断思索和探索神经网络模式下的泛化推理能力,以及符号逻辑推理的精准性和可解释性的高效融合。
(3)如何协同大模型与垂域知识图谱,从智能问答走向垂域智慧决策?
-
如何利用大模型驱动多任务 Agent 协同执行复杂领域任务
-
如何应用高质量垂域知识图谱约束大模型可控生成,实现知识的智能化
借助大模型的能力,协同大模型与垂域知识图谱,从过去的智能问答,或是简单的一两跳逻辑推理,真正走向垂域的复杂的多步智慧决策。一方面,大模型驱动多任务 Agent 协同执行复杂领域任务;另一方面,应用高质量垂直知识图谱约束大模型的可控生成,实现知识的智能化。
(4)如何将高血压智能诊疗方案推广到广泛医学决策场景,实现真正的 AI 数字医生?
-
垂域超关系知识图谱的高质量、低成本建模
-
神经与符号逻辑高效融合的泛化、精准推理
-
大模型与知识图谱协同的复杂医学决策服务
结合自身在高血压智能诊疗方向上的研究,希望我们的工作能够推广到广泛的医学决策场景,最终研发出多学科 AI 数字医生,赋能于基层的诊疗,赋能于养老健康等急需医疗资源的行业和领域。
第一是利用垂域超关系知识图谱进行高质量、低成本建模;第二是将神经与符号逻辑高效融合,最终实现有泛化能力的精准推理;第三是大模型和知识图谱协同工作,支持复杂医学决策的服务。
以上就是本次分享的内容。在此附上我的微信和邮箱,欢迎同行交流,不限于医学领域研究方向,也希望我们以医学为主题进行的研究工作,可以赋能金融、互联网等更多行业领域。
邮箱:ehaihong@bupt.edu.cn
微信:87837001

06
Q&A
Q1**:现在图数据库比** RDF 数据库****更流行,所以在 KBQA 中选择 SPARQL 而不选择 cypher 的主要是考虑什么?
A1:首先,采用哪种形式的图数据库进行知识存储,这一点在前期做了很多探索工作;现在采用的比较多的形式,使用属性图数据库如 TuGraph,对于用 cypher 方式还是 SPARQL 方式,其实并没有限制。因为对于大模型而言,其生成的逻辑的 Logical Form 后,进一步生成 SPARQL,还是生成 cypher,这种 code 的能力都很强,所以这不是关键点,只是恰好在构建这项实验的时候选择了这条路径来进行验证,发现没有局限性,就一直沿用下来。
Q2**:大模型在医疗行业生成的内容可能会产生一些不确定、不准确的信息;除了文中提到的大模型+知识图谱这种解决方案之外,还有没有其他可以借鉴的方案?如果需要应用在其他专科领域的疾病中,需要如何开展?**
A2:在大模型出现之前,基于匡主任提出的问题,我们一直在尝试、探索和研发高血压医生大脑来赋能基层医生的诊疗服务;到今天为止,正在开展的评测大模型仍然没能有效解决多步复杂推理任务。这是一个特别关键的点。假如基于患者的血压分级进一步判断是否为高血压患者,并一直推理到最终用药,前面存在很多步的诊断过程,因此不能依赖大模型这种不可控甚至存在幻觉的思考方式,而一定要将这个问题进行进一步的拆解,将隐式信息显性化。使用图思索的方式,使其具有思考能力,将复杂问题拆解成多个步骤,协同 Agent 来解决问题,这是个目前大家一致认为有不错前景的方向。
Q3**:文中提到的医疗数据集适用于哪些场景?**
A3:对于医疗数据集的问题。在其他领域,本文分享的工作,特别适合医学场景,因为医学场景会有很强的前置医学文献,以及很强的医生共识和医学指南,因此其知识的严谨程度较高;而且大家的共识很多已经在临床上成为一线治疗方法,有很多医生已经达成相关标准,因此非常适合使用完备的知识表示(即层次化超关系的完备表示)完成数据的建模,并引导决策推理。而大模型可以解决泛化性自然语言的输入和输出,因此将两者结合最终能够让问题得到有效的解决。
以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION

鄂海红

北京邮电大学

北京邮电大学教授,博士生导师,教育部信息网络工程研究中心副主任

鄂海红,北京邮电大学教授,博士生导师,教育部信息网络工程研究中心副主任,中国科学技术情报学会科研诚信建设工作委员会副主任委员,中国计算机学会数据治理发展委员会执行委员。主要研究知识图谱与大模型协同的数据要素治理和复杂推理决策。累计主持国家重点研发计划课题、国家自然科学基金项目以及省部级课题、企事业合作项目 30 余项。累计发表 EI/SCI 高水平学术论文 100 余篇,获国家发明专利授权 81 项,专利许可实施 21 项。科技创新成果已在医疗健康、科技服务、金融、政务等多个行业实现规模化商用,超关系层次化知识图谱构建、推理与问答技术在多家医院临床决策支持系统(CDSS)落地应用,获聘北京市昌平区首批“科技副总”,荣获中国商业联合会中国服务业创新奖特等奖,教育部高等学校科学研究优秀成果奖进步奖二等奖,中国计算机学会科技成果奖技术发明一等奖,中国通信标准化协会科学技术奖三等奖。
活动推荐


往期推荐
[
字节跳动系统智能运维实践 | DataFun大会分享回顾
[
实时智能全托管-云器Lakehouse重新定义多维数据分析
[
Blaze:SparkSQL Native算子优化在快手的深度优化及大规模应用实践
[
数据赋能实战:企业产品与业务的升级之道!
[
Spark 内核的设计原理
[
沐瞳指标管理与智能分析
[
信贷场景广告投放优化实践
[
数据仓库模型管理与标签资产价值评估实践
[
DataFunCon 2024·北京站首日圆满收官
[
LLM+Data:大模型在大数据领域应用新范式

点个在看你最好看
SPRING HAS ARRIVED

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek001/post/20240710/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E6%97%B6%E4%BB%A3%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E8%B5%8B%E8%83%BD%E9%AB%98%E8%A1%80%E5%8E%8B%E6%99%BA%E8%83%BD%E8%AF%8A%E7%96%97%E5%AE%9E%E8%B7%B5--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


