遇上使用和构建搜索引擎
作者:Hironsan
编译:ronghuaiyang
导读: 强强联合,看看是否能有1+1>2的效果。
在这篇文章中,我们使用一个预先训练好的BERT模型和Elasticsearch来构建一个搜索引擎。Elasticsearch最近发布了带有矢量字段的文本相似性搜索。另一方面,你可以使用BERT将文本转换为固定长度的向量。一旦我们通过BERT将文档转换成向量并存储到Elasticsearch中,我们就可以使用Elasticsearch和BERT搜索类似的文档。
本文使用Elasticsearch和BERT按照以下架构实现了一个搜索引擎。这里,我们使用Docker将整个系统划分为三个部分:application, BERT和Elasticsearch。这样做的目的是为了更容易地扩展每个服务。
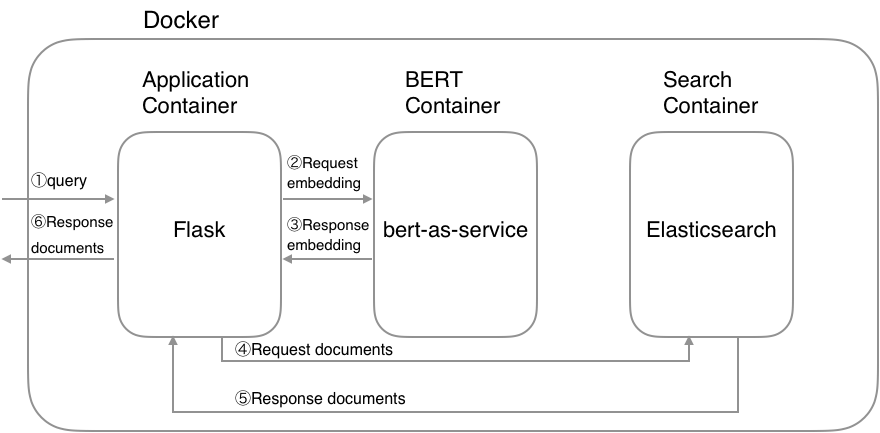
我在这篇文章中只展示了重要的部分,整个系统都在 <span>docker-compose.yaml</span 中。在以下的GitHub存储库中: https://github.com/Hironsan/bertsearch。
1. 下载预训练BERT模型
首先,下载一个预先训练好的BERT模型。以下命令是下载英文版本的例子:
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zip
2. 设置环境变量
你需要设置一个预先训练好的BERT模型和Elasticsearch的索引名作为环境变量。这些变量在Docker容器中使用。下面的示例将 jobsearch 指定为索引名,以及. /cased_L-12_H-768_A-12 为模型路径:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch
3. 启动Docker容器
现在,我们使用Docker compose来启动Docker容器。这里要启动三个容器:application容器、BERT容器和Elasticsearch容器。
$ docker-compose up
注意,我建议你分配更多的内存(超过8GB)给Docker。因为BERT容器需要大内存。
4. 创建Elasticsearch索引
您可以使用create index API向Elasticsearch集群添加新的索引。创建索引时,你可以指定以下内容:
- 设置索引
- 索引中字段的映射
- 索引别名
例如,如果你想创建带有“title”、“text”和“text_vector”字段的“jobsearch”索引,可以通过以下命令创建索引:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"title": {
"type": "text"
},
"text": {
"type": "text"
},
"text_vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
注意: <span>text_vector</span 的 <span>dims</span 值必须与预先训练的BERT模型的dims匹配。
5. 创建文档
一旦创建了索引,就可以为某个文档建立索引了。这里的要点是使用BERT将文档转换为向量。得到的向量存储在 <span>text_vector</span 字段中。让我们把你的数据转换成一个JSON文档:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
"Title","Description"
"Saleswoman","lorem ipsum"
"Software Developer","lorem ipsum"
"Chief Financial Officer","lorem ipsum"
"General Manager","lorem ipsum"
"Network Administrator","lorem ipsum"
脚本执行完成后,可以得到如下的JSON文档:
# documents.jsonl
{"_op_type": "index", "_index": "jobsearch", "text": "lorem ipsum", "title": "Saleswoman", "text_vector": [...]}
{"_op_type": "index", "_index": "jobsearch", "text": "lorem ipsum", "title": "Software Developer", "text_vector
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%81%87%E4%B8%8A%E4%BD%BF%E7%94%A8%E5%92%8C%E6%9E%84%E5%BB%BA%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


