岗位精选面试题
添加微信:julyedufu77,回复 “ 7 ”,领取最新升级版《名企AI面试100题》电子书!!
11、当参数量 » 样本量时候, 神经网络是如何预防过拟合?
- 正则化 2. Early Stopping 3. Dropout 4. 数据增强
过拟合即在训练误差很小,而泛化误差很大,神经网络时避免过拟合的方法:
- 正则化
正则化的思想十分简单明了。由于模型过拟合极有可能是因为我们的模型过于复杂。因此,我们需要让我们的模型在训练的时候,在对损失函数进行最小化的同时,也需要让对参数添加限制,这个限制也就是正则化惩罚项。
假设我们模型的损失函数为:
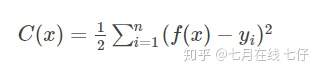
加入正则项 L 后,损失函数为:
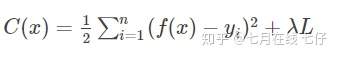
常用的正则化有两种:L1正则和L2正则
L1正则表达式:
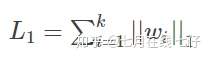
其中w代表模型的参数,k代表模型参数的个数。
L2正则表达式:
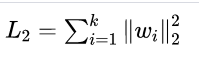
其中w代表模型的参数,k代表模型参数的个数。
L1正则与L2正则的思想就是不能够一味的去减小损失函数,你还得考虑到模型的复杂性,通过限制参数的大小,来限制其产生较为简单的模型,这样就可以降低产生过拟合的风险。
它们的区别在于L1更容易得到稀疏解。为什么呢?我们先看看一个直观的例子:
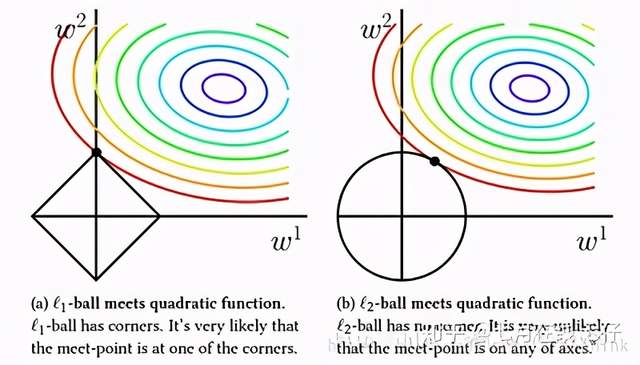
假设我们模型只有 w1,w2两个参数,上图中左图中黑色的正方形是L1正则项的等值线,而彩色的圆圈是模型损失的等值线;右图中黑色圆圈是L2正则项的等值线,彩色圆圈是同样模型损失的等值线。因为我们引入正则项之后,我们要在模型损失和正则化损失之间折中,因此我们去的点是正则项损失的等值线和模型损失的等值线相交处。通过上图我们可以观察到,使用L1正则项时,两者相交点常在坐标轴上,也就是 w1,w2中常会出现0;而L2正则项与等值线常相交于象限内,也即为 w1,w2非0。因此L1正则项时更容易得到稀疏解的。
而使用L1正则项的另一个好处是:由于L1正则项求解参数时更容易得到稀疏解,也就意味着求出的参数中含有0较多。因此它自动帮你选择了模型所需要的特征。L1正则化的学习方式是一种嵌入式特征学习方式,它选取特征和模型训练时一起进行的。
12、什么是感受野?
某一层特征图中的一个cell,对应到原始输入的响应的大小区域。
什么是感受野
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,kernel size 均为3×3,stride均为1,绿色标记的是Layer2 每个神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1 上 3×3 大小的区域,Layer3 每个神经元看到Layer2 上 3×3 大小的区域,该区域可以又看到Layer1 上 5×5 大小的区域。
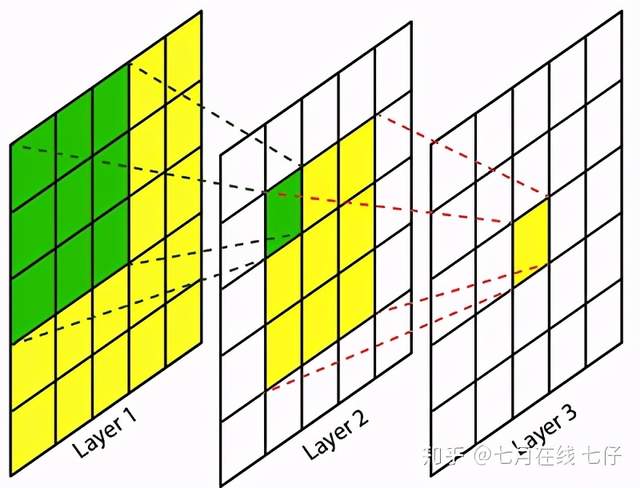
所以,感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
13、简述你对CBIR(Content-based Image Retrieval基于内容的图像检索)的理解
通过对比特征点\特征值的相似度,判断两个图片是否相近
基于内容的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B2%97%E4%BD%8D%E7%B2%BE%E9%80%89%E9%9D%A2%E8%AF%95%E9%A2%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


