Python股票数据爬取与计算项目 --知识铺
本次是完成一个股票的计算项目,其主要功能如下:
(1)输入股票代码、起止日期后下载股票的日期、股票代码、名称、收盘价、最高价、最低价、开盘价等一系列基本股票数据。
(2)计算异同移动平均线指标(MACD)、布林线(BOLL)的上轨线指标和下轨线指标、平均趋向指标(ADX)、相对强弱指标(RSI)、顺势指标(CCI)、30日和60日的移动平均线指标(MA)等并进行展示。
(3)设计交互界面。
(原项目比这个麻烦一点,但是不符合实用性,并且由于连接了mysql数据库无法普遍使用,我对此做了一点小小更改)
写在前面:
第一次写博客,做的不好多多包涵。本题目来源于个人的一个课程设计,进行了一定改编。
其实这是一个很简单的小项目,特别是做完去回看自己写的代码,会觉得其实也并没有什么太难的地方,但是在自己刚开始写的时候,包括学习爬虫、csv文件的处理、mysql的报错、stockstats的函数等也花费了大量时间,仅以此文记录一下学习生涯。
一、获得股票数据
首先关于股票数据,我选择某财经网站进行爬取,首先因为其有专门的历史数据页面,并且通过URL格式固定。
其次,相比于东方财富有反爬虫部分,该网站并未对爬虫有较多的限制,更加方便爬取。(由于版权问题,代码中的URL已被删除,若需要请自行加入)
关于爬虫部分,首先新建一个GetData模块来放置爬虫类,命名为Download_HistoryStock,在建立该类的self函数时,我们要传入code(股票代码),startDate(开始爬取的时间),endDate(截止时间)三个变量,而这三个变量我们会在交互页面通过用户输入传入,以此满足用户需求。而爬虫的headers只需要打开网页后按F12,选择网络,点击html的那个名称,并拉到最下面则可以查看自己的headers。
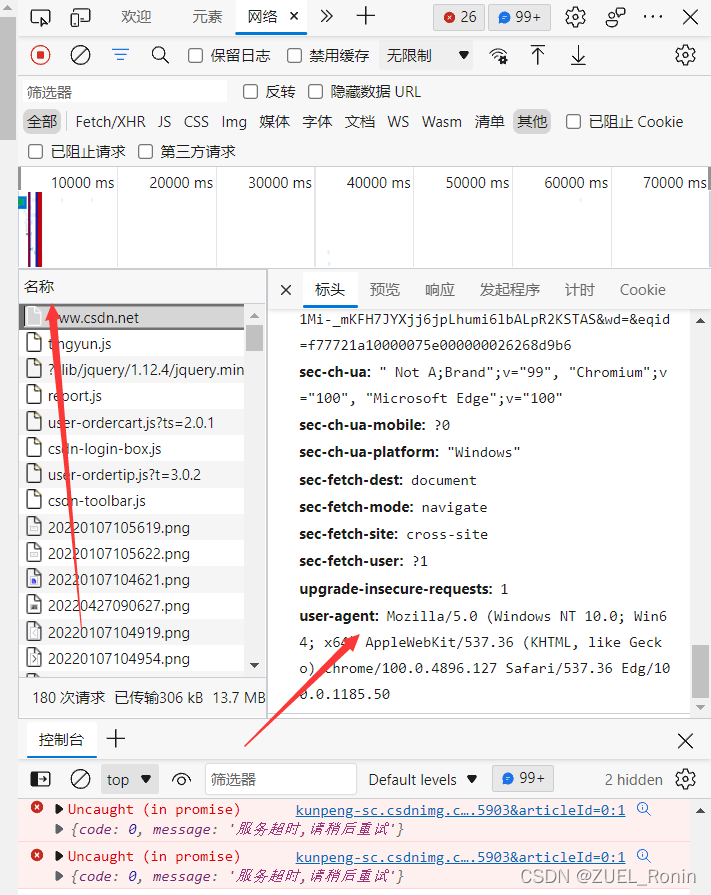
第二个函数即Download(数据下载)函数,为了避免在当前文件夹下数据杂乱,我首先新建了一个文件夹“数据”用于存放下载的股票历史数据。在调试过程中我发现,如果想要读取当前文件夹下的其他文件夹中的文件无法直接打开,open函数只能读取当前文件夹或绝对路径,故我先设置了一个basepath来存放当前文件夹的路径(其中调用了os模块的path.dirname,主要功能是返回当前文件夹的路径)再加上“\\数据”对存放数据的文件夹进行文件读取。接下来使用os.path.exists来先判断一下“数据”文件夹是否存在,如果不存在则使用os.makedirs来创建文件夹。
接下来就是对于网页的爬取部分,通过网页代码中找到网易财经历史数据的URL,通过观察发现网易财经的URL中包含了起止时间和股票代码一共三个会发生改变的变量,故我们将self的三个变量进行替换,即可完成对任意股票URL的爬取,随后我们使用request.get获得网页的内容,并通过循环将其读取到数据文件夹 的“code.csv”文件中。open函数可以在不存在该文件时创建文件,若存在则直接打开,并进行覆盖写入。
源代码如下:
|
|
来看一下执行的结果,以晨光股份(603899)为例:
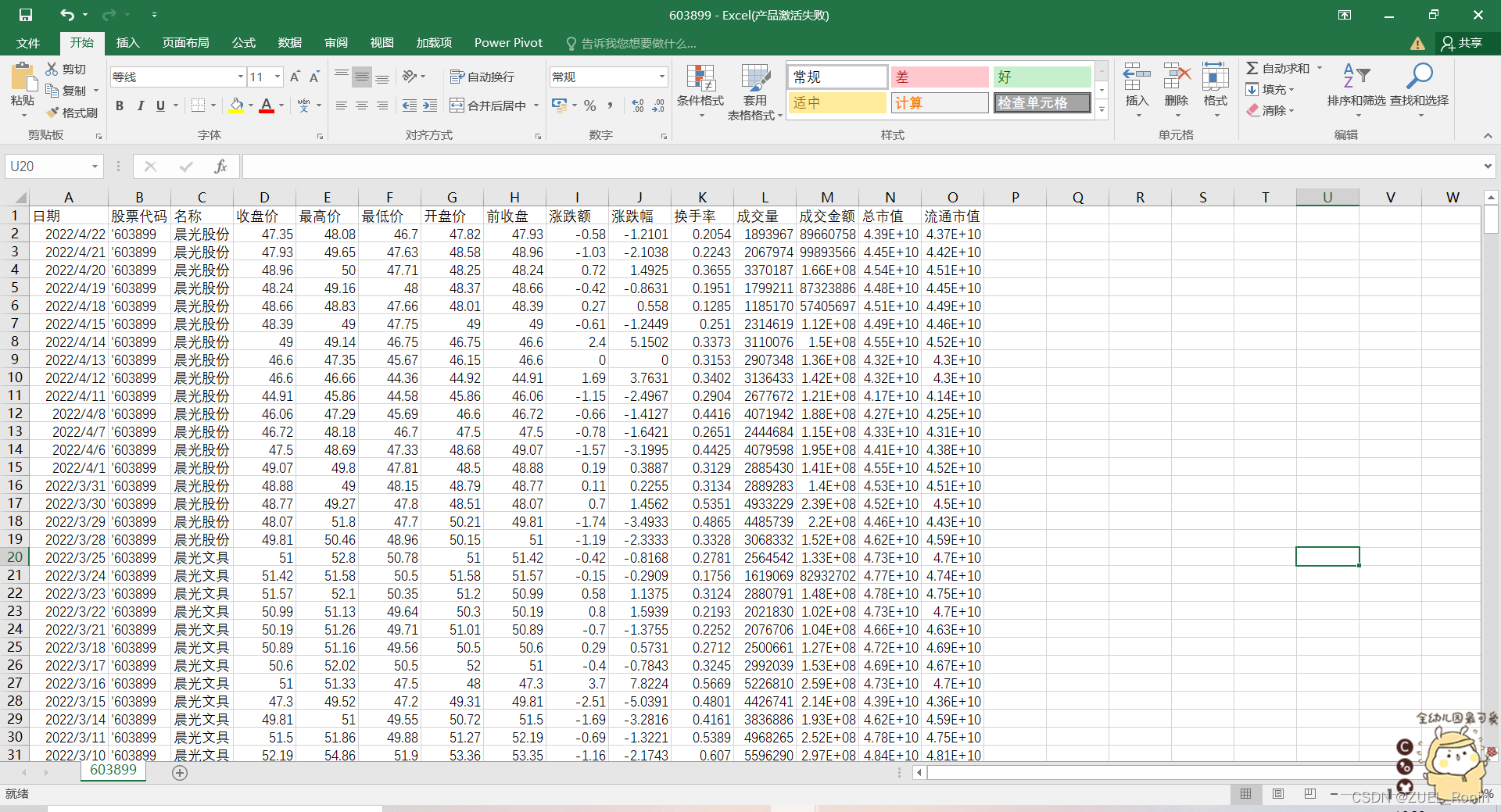
有一点美中不足的是在股票代码中,第一个字符会出现 ‘ ,应该是页面源代码的问题,在后续数据处理中可以用strip()函数将这个删除。
二、数据处理并生成图像
该部分在第一次看到我觉得非常难算,直到发现了一些金融类的python库也可帮忙解决,本次使用的是stockstats库,其安装方式很简单,只需要
|
|
该库的具体介绍比较少,很多用法还需摸索,其源码可以在csdn上找到,共一千多行代码左右,感兴趣的可以看看(顺便学习一下金融知识)。
首先该库可以直接读取csv文件,但是我导入时会报错如下
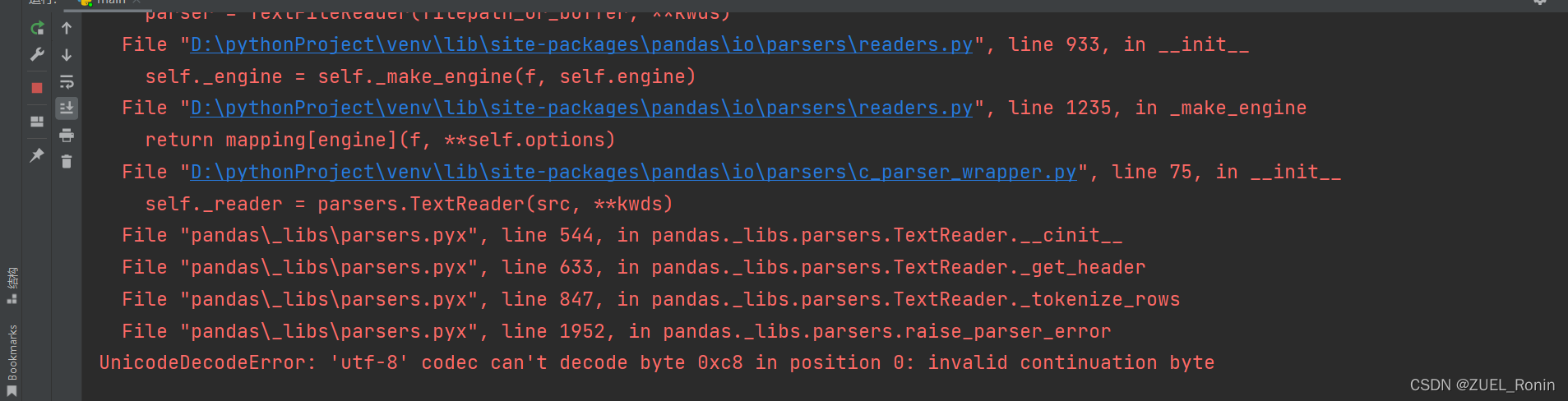
utf-8编码类型不对,然后我去查看了那个stockstats的源码发现(对,就是那个一千多行,看到我头疼的源码),它对csv文件的处理非常死板,标题必须是英文,而我的标题是中文,其次,列名必须严格按照date,open,close,high,low,volume来编写,因此我们需要对csv文件做一个预处理。
这部分主要就是删除多余的列,并将第一行替换为英文内容,多余的列可以直接用drop()来删除,但是根据网上删除行时一直发生错误,也无法直接在最前面加入标题行(注:网上很多对于csv文件的操作似乎都会产生一点问题,也没有太多资料进行查找)。于是,我选择新建一个csv文件,输入标题行后再循环输入该文件的除标题行以外的正文内容,最终完成对csv文件的预处理。
预处理源码如下
|
|
处理完之后则可直接调用stockstats库进行计算相关指标,stockstats库功能非常强大,调用csv文件的代码如下:
|
|
调用计算代码如下:
|
|
但是如今网络上似乎找不到输出具体值的方法,如果直接print()由于输出无法通过索引获得,会导致无法将数据导出计算。于是,我又去读了一下那个长达一千两百行的源码(所以强烈建议大家多读读,能治疗头发过多),最终发现可以通过
|
|
前后都需要说明是哪一个函数,第一次调用get时,又由于前面没有加上macd,导致报错。该函数后面可以加上索引进行导出。
注:macd外面有两个[ ]。
剩下的就是调用stockstats进行数据处理,并通过matplotlib.pyplot库来进行展示。代码如下:
|
|
三、交互页面制作
该部分主要是利用tkinter库进行页面的设置,并读取用户输入的股票代码和起止日期来传导给前面几个部分进行爬取和计算,主要是要进行差错检测,避免用户其不合规的操作导致程序产生错误。(后附页面截图)
|
|
四、结果展示
|
|
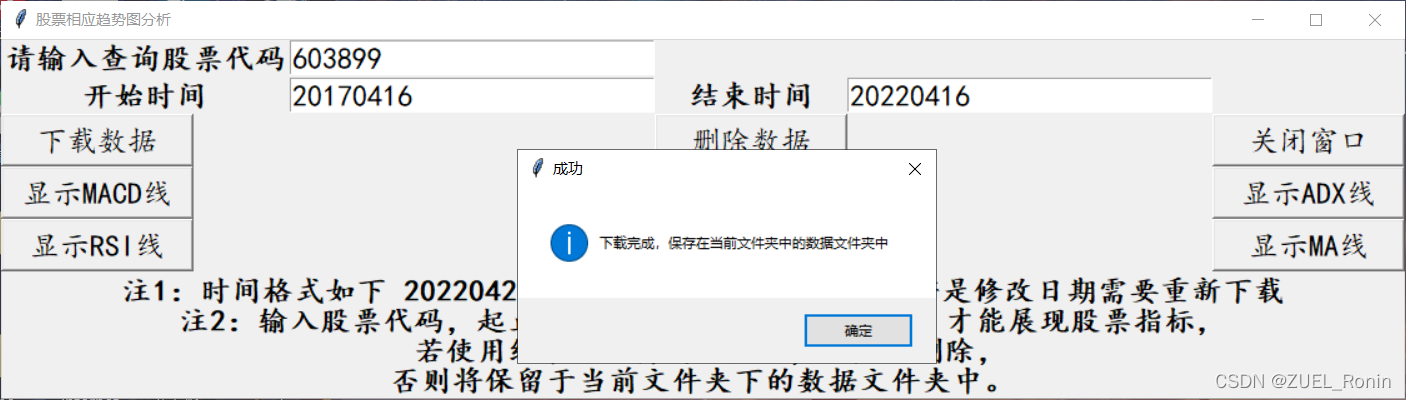
本次以晨光股份(603899)为例
交互页面如下:

输入603899,时间为2017年4月16日-2022年4月16日,首先点击下载数据
显示各个函数线:
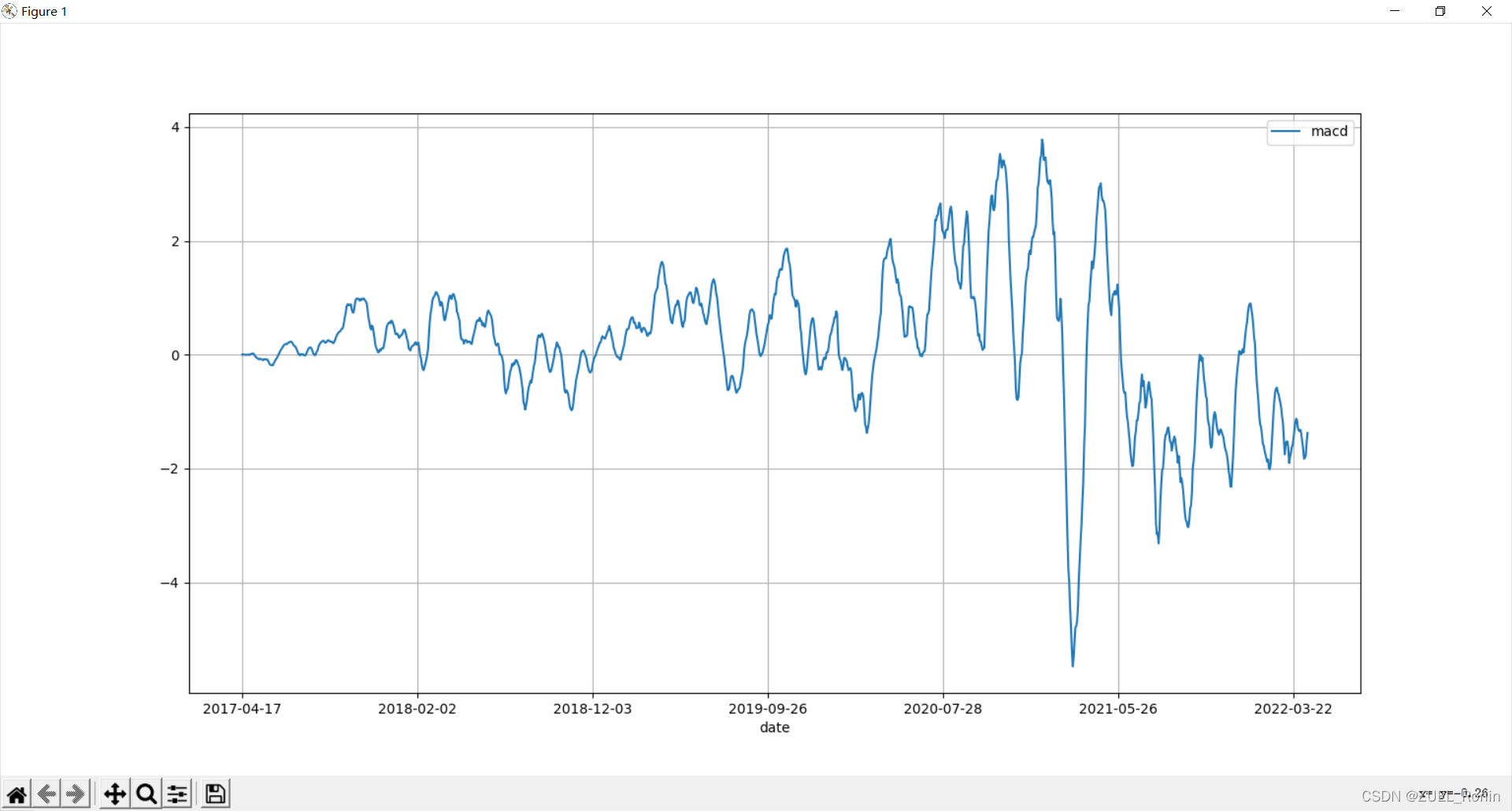
MACD
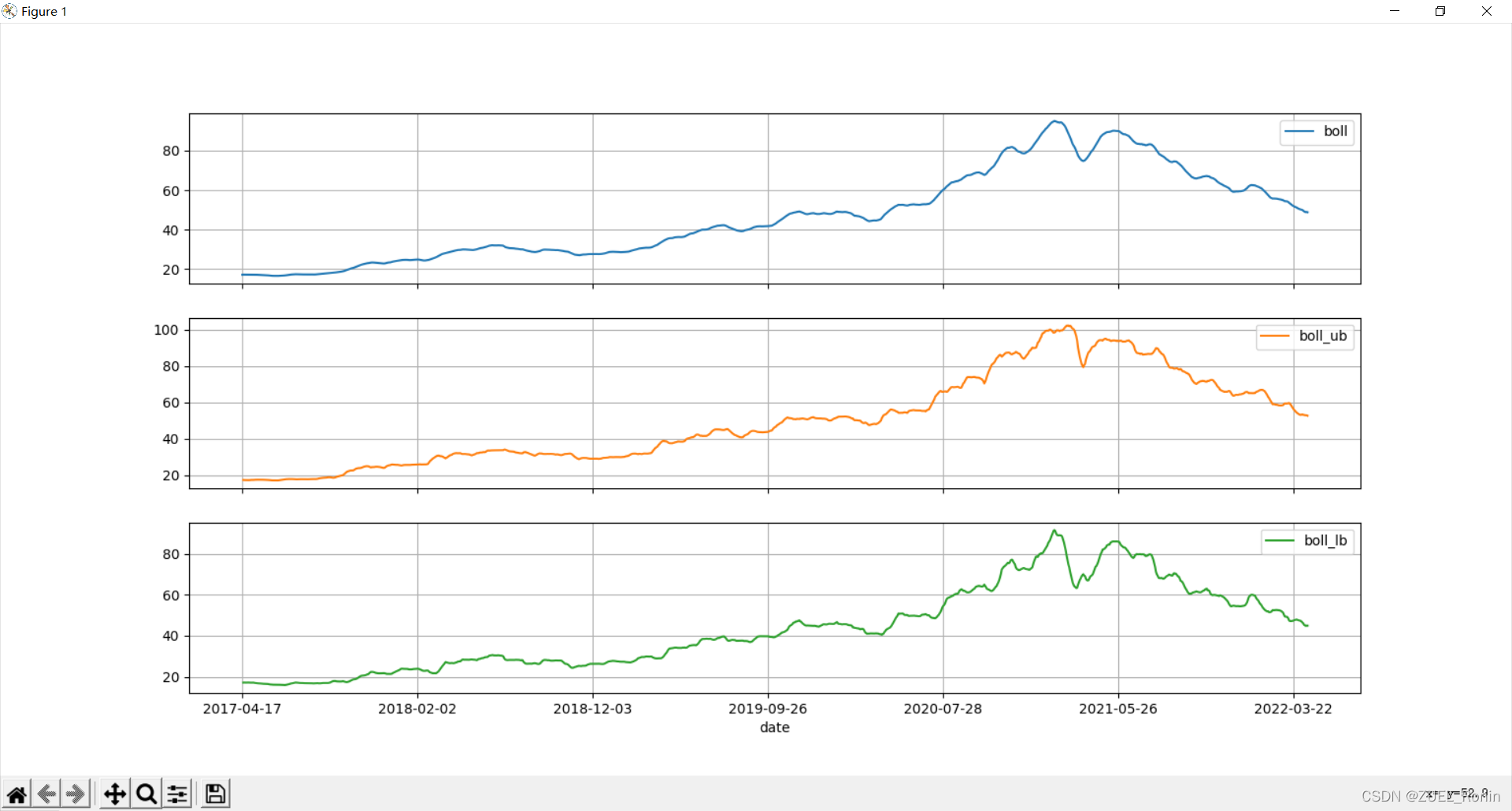
BOLL
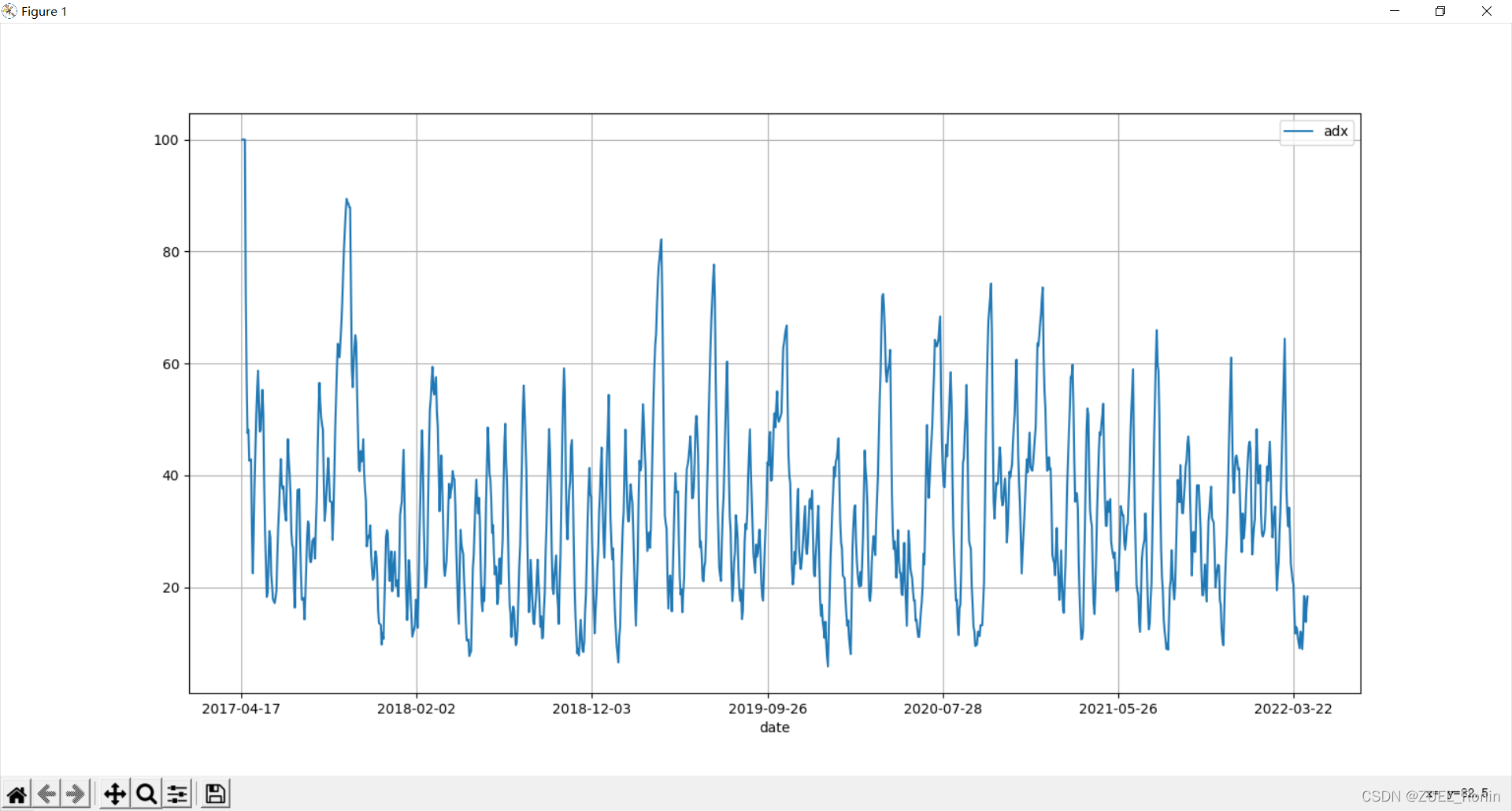
ADX
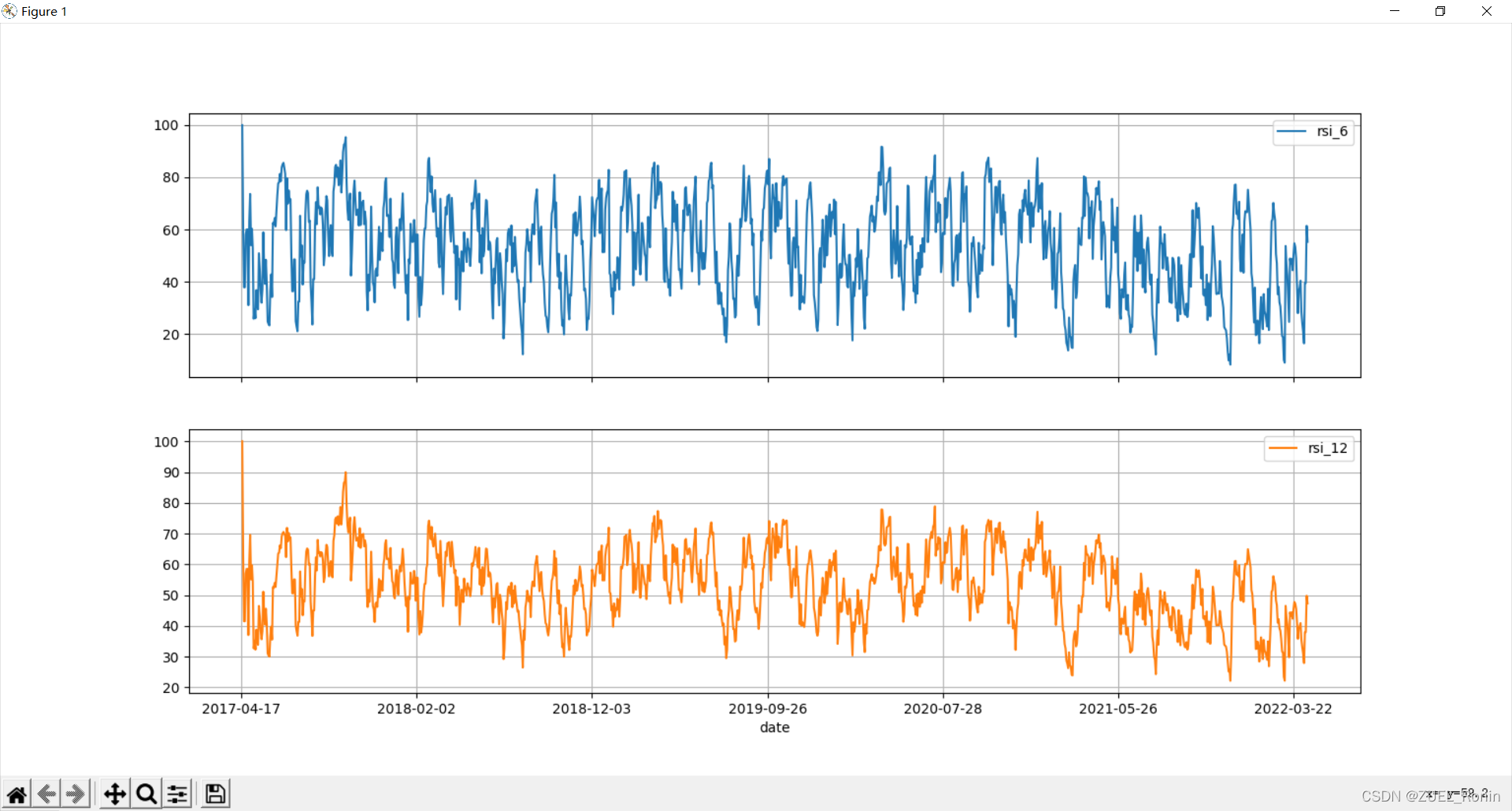
RSI
CCI
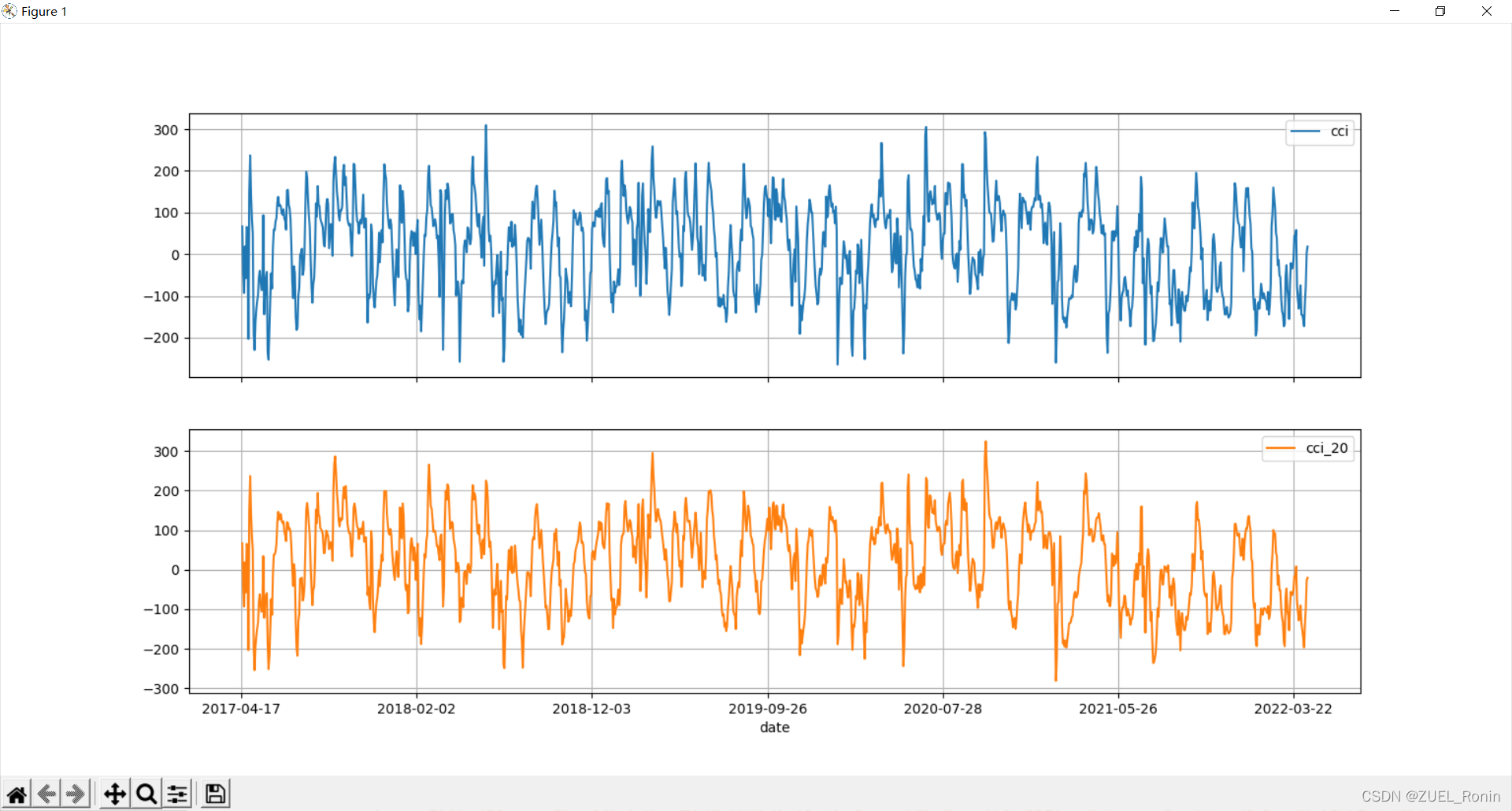
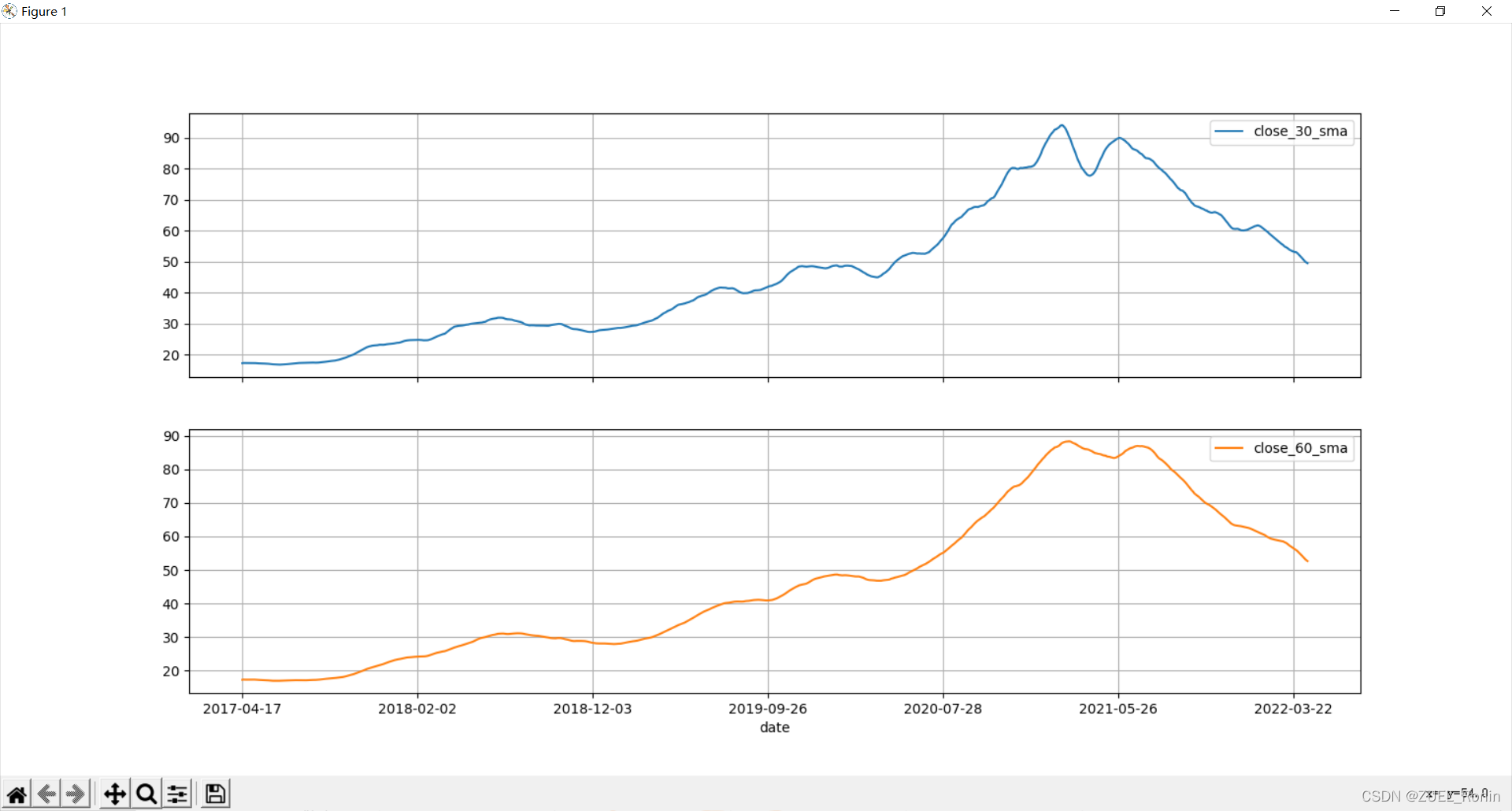
MA
五、最后
本文只是记录一下最近学python的过程,虽然最后呈现出来的比较简单,有很多写的不好的地方,欢迎各位大佬指点。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/stocktactics/post/20240413/Python%E8%82%A1%E7%A5%A8%E6%95%B0%E6%8D%AE%E7%88%AC%E5%8F%96%E4%B8%8E%E8%AE%A1%E7%AE%97%E9%A1%B9%E7%9B%AE--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


