爬取豆瓣电影 Top250
爬虫是标配了,看数据那一刻很有趣。第一个就从最最最简单最基础的爬虫开始写起吧!
项目地址:https://github.com/go-crawler/douban-movie
目标
我们的目标站点是 豆瓣电影 Top250,估计大家都很眼熟了
本次爬取 8 个字段,用于简单的概括分析。具体的字段如下:
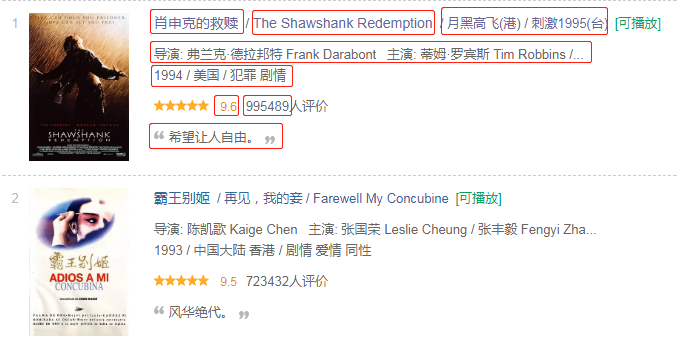
简单的分析一下目标源
- 一页共 25 条
- 含分页(共 10 页)且分页规则是正常的
- 每一项的数据字段排序都是规则且不变
开始
由于量不大,我们的爬取步骤如下
- 分析页面,获取所有的分页
- 分析页面,循环爬取所有页面的电影信息
- 爬取的电影信息入库
安装
$ go get -u github.com/PuerkitoBio/goquery
运行
$ go run main.go
代码片段
1、获取所有分页
|
|
2、分析豆瓣电影信息
|
|
数据
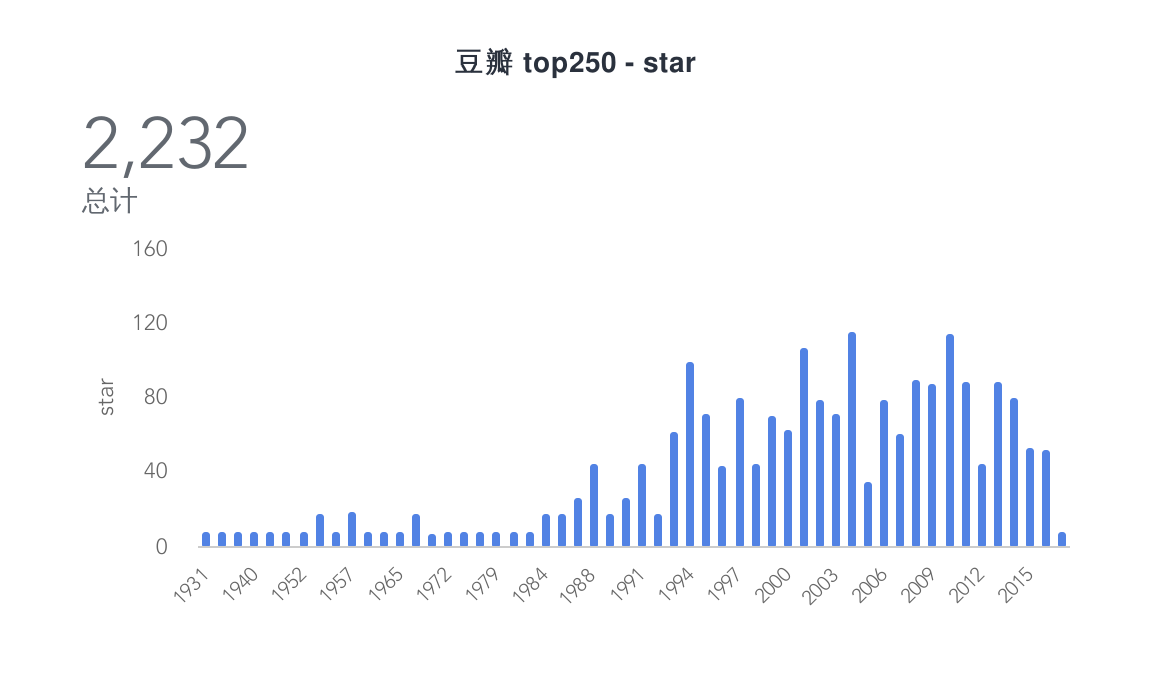
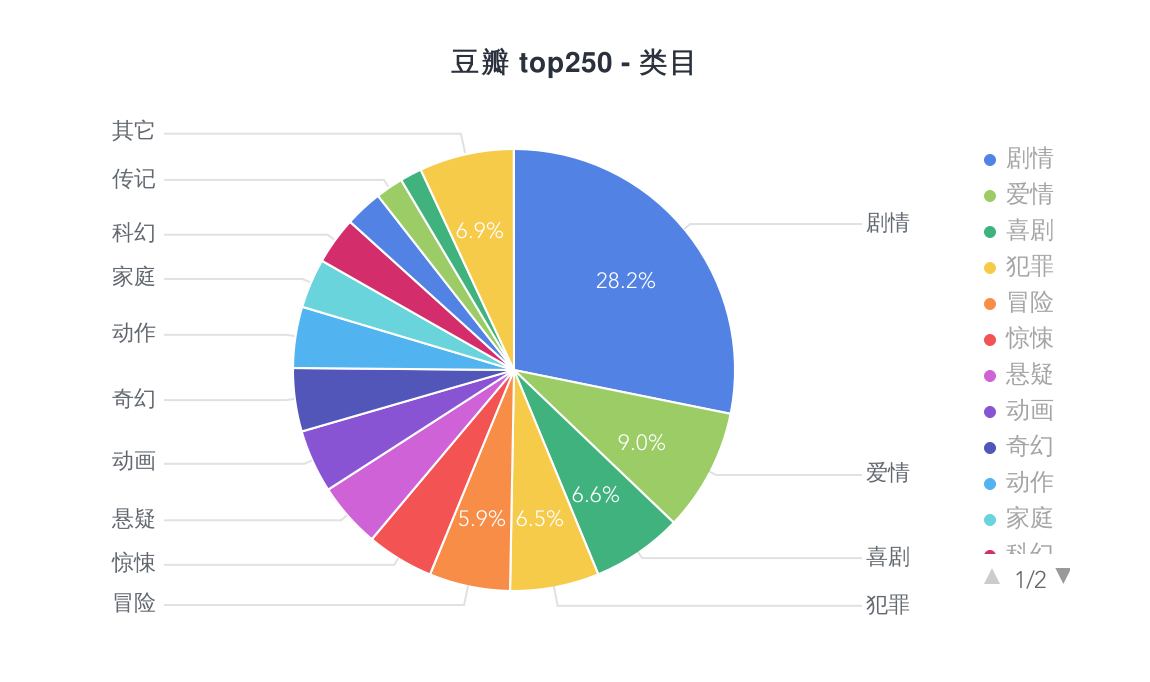

看到这些数据,你有什么想法呢,真是好奇 :=)
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/go/posts/go/crawler/2018-03-21-douban-top250/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


