最新开源的解析效果非常好的PDF解析工具MinerU(pdf2md pdf2json) -- 知识铺 --知识铺
MinerU是一款功能强大的PDF解析工具,它不仅支持将PDF文件转换为markdown格式,还能处理图片和表格等元素。在文档解析领域,MinerU表现出色,尤其适合用于RAG(Retrieval-Augmented Generation)任务中。尽管其GitHub上的star数尚未达到很高的水平,但根据实际测试结果来看,MinerU的效果远超许多其他开源工具。本文将详细介绍MinerU的功能特点、使用场景以及如何在Windows环境下安装和使用该软件。
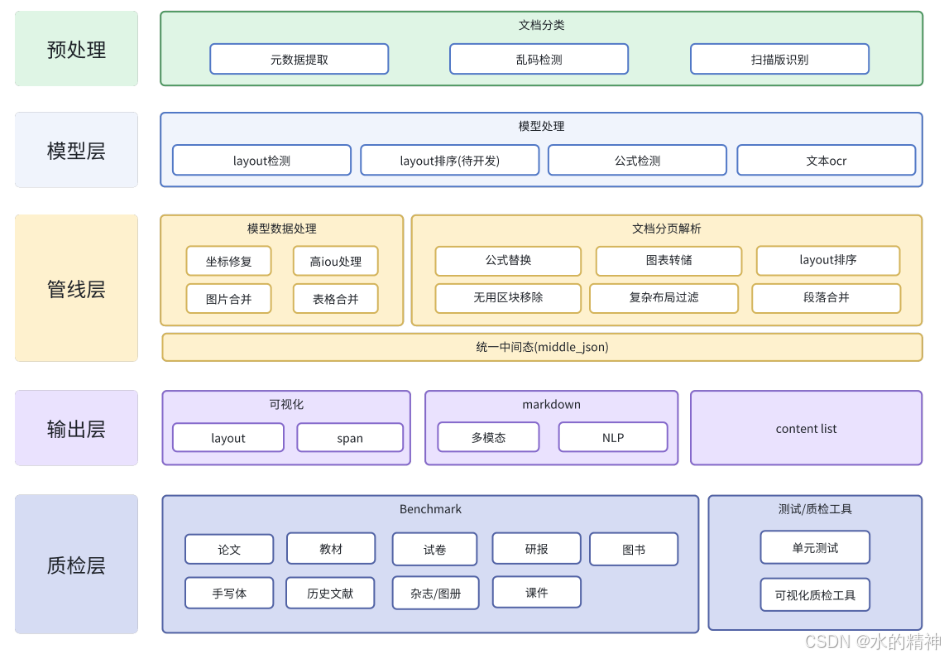
解析效果总结
在考虑是否安装解析系统之前,我们先来评估一下它的实际表现。通过初步观察解析效果,可以帮助我们决定这些优缺点是否符合我们的需求。
缺点
-
问题1:解析速度慢
-
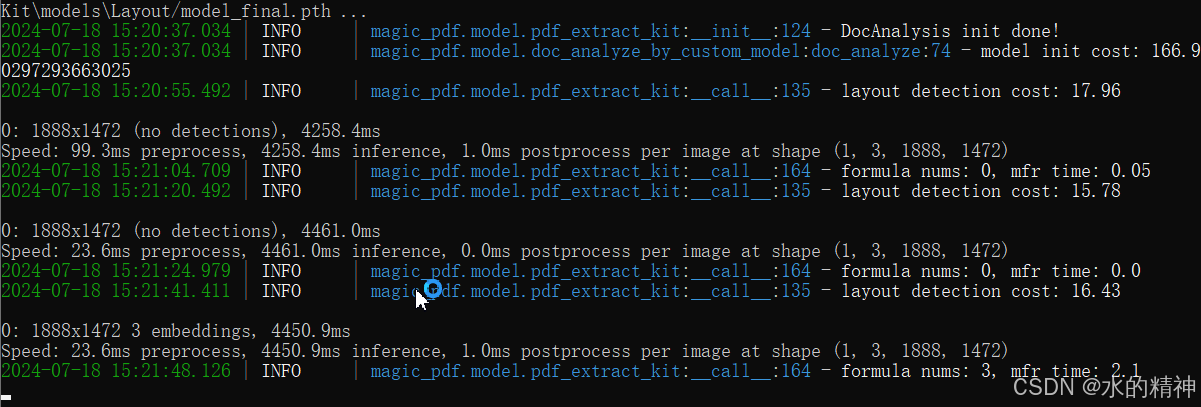
当前使用的环境是基于CPU的,处理大约6页文档需要花费2到3分钟的时间。
-
整个解析流程分为三个阶段:首先是版面分析,接着进行OCR(光学字符识别),最后是公式检测。
-
模型初始化过程需要大约167秒,这是一次性的开销。一旦初始化完成,后续每处理一页文档平均需要16秒左右。
-
需要特别注意的是,上述时间是在特定硬件配置下的测试结果,不同的硬件条件可能会有不同的性能表现。
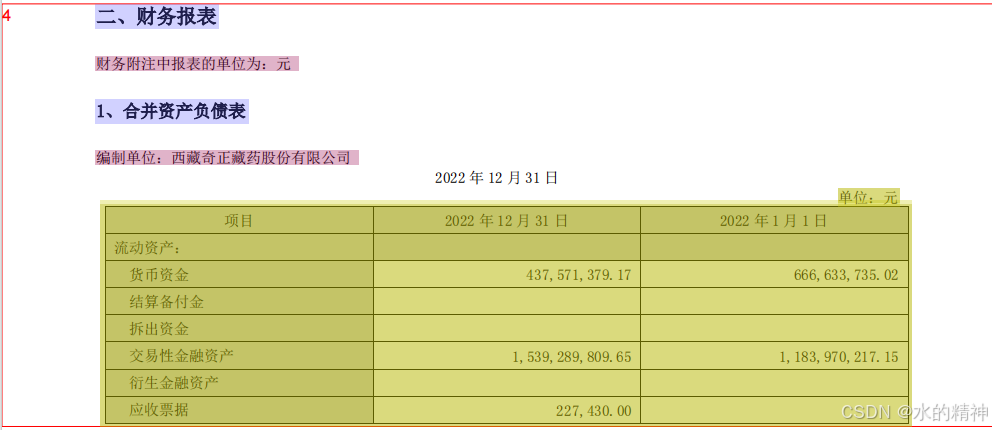
问题2:表格解析成图片
把表格处理成了图片
原文件如下所示
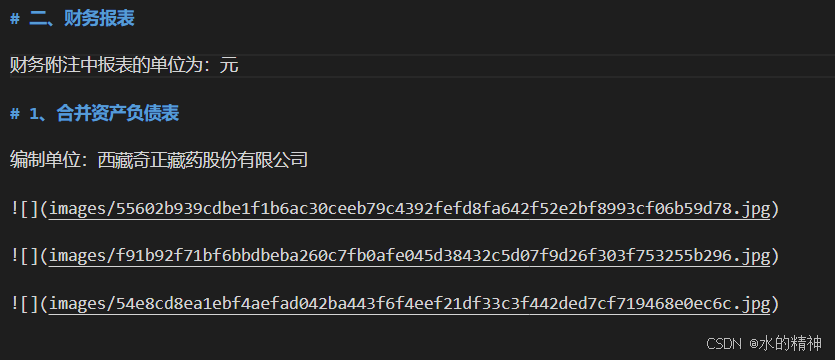
解析结果如下所示
原文件如下
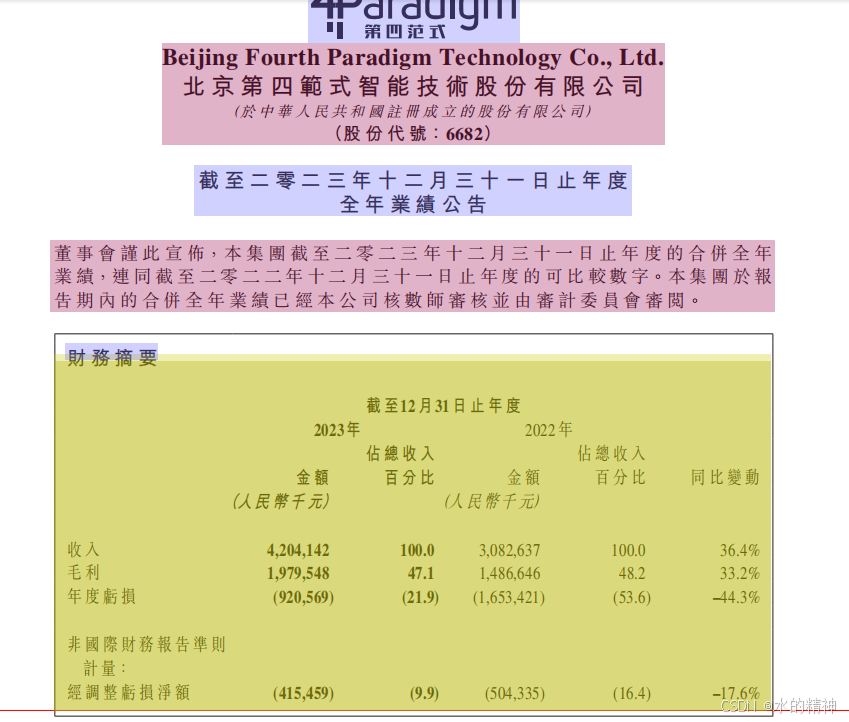
解析后的结果
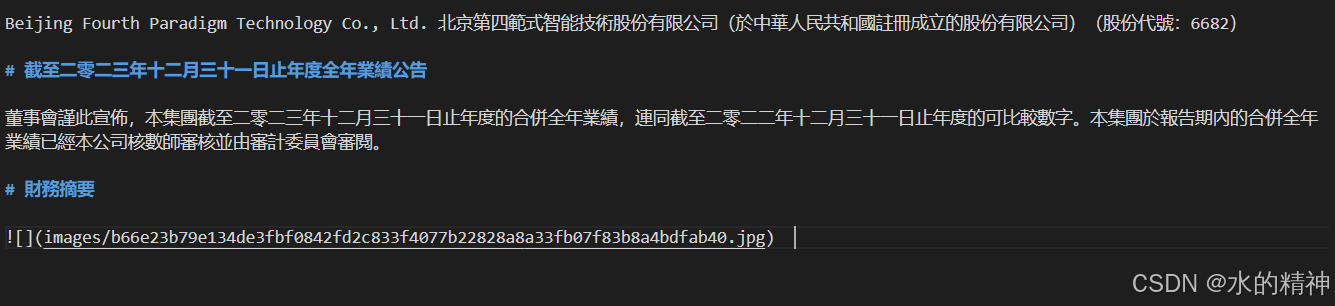
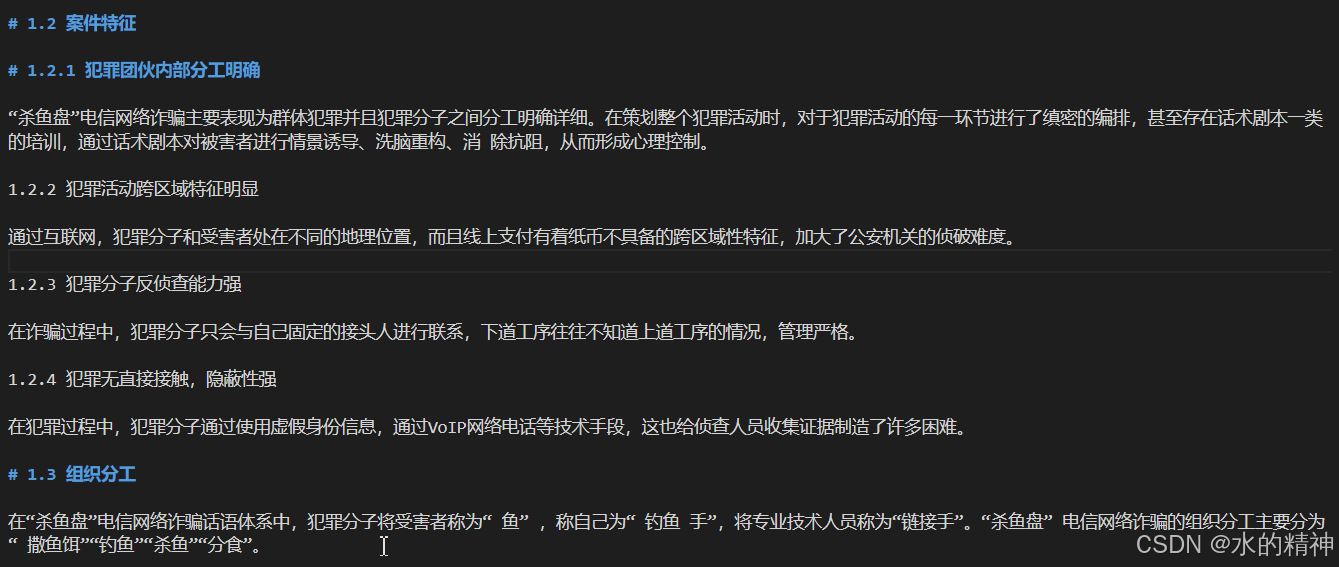
问题3:标题识别不准确,且没有分层
原文件
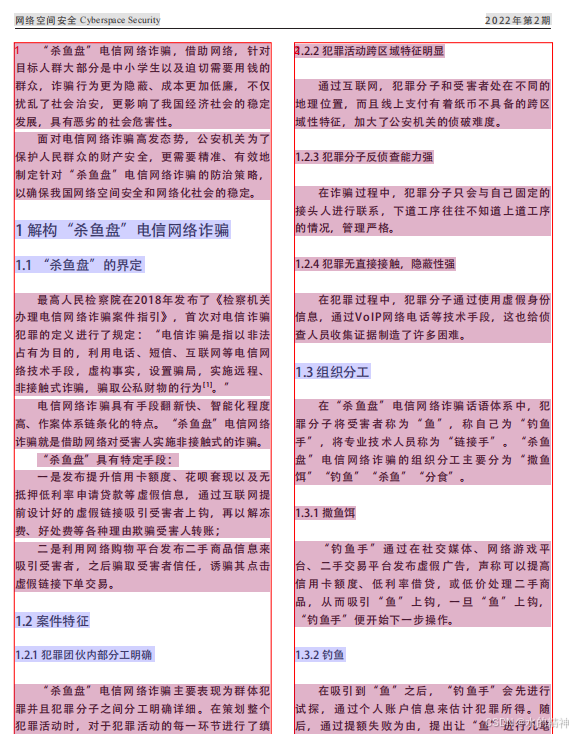
解析后的结果
问题4:财报中的表格没有识别出来
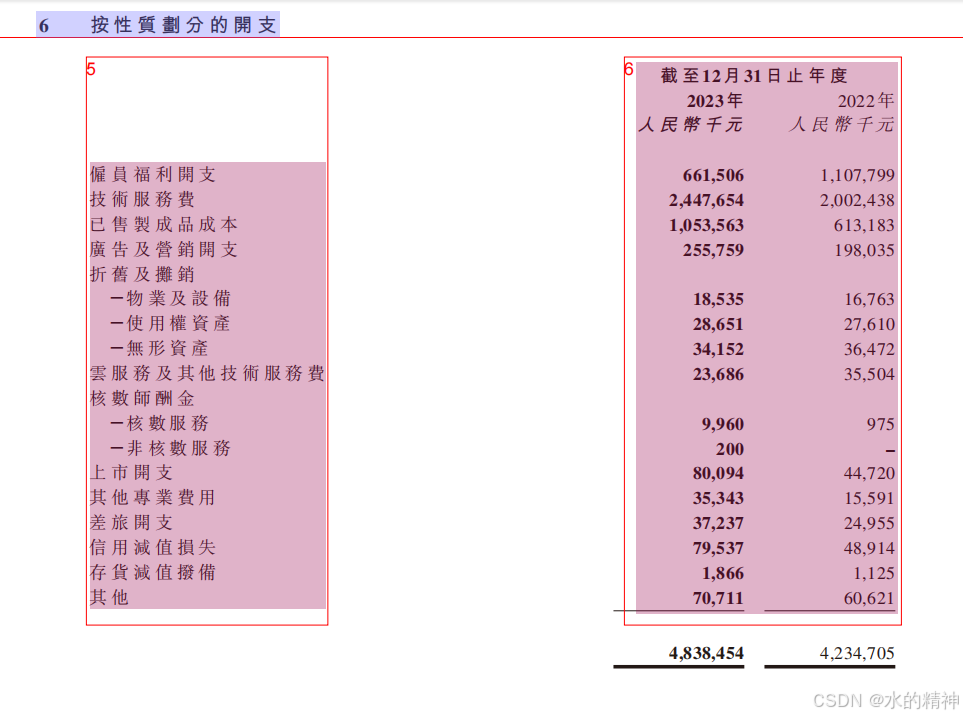
优点
优点1:论文版面分析准确
-
表格和图表定位准确,测试了一篇论文,所有位置均正确。
-
准确获取到了表格和图片的标题(caption)。
-
支持多栏布局,解析顺序正确。
优点2:处理复杂页面效果佳
- 即使页面包含混乱的杂志内容、多栏以及图片,解析效果依然良好,保持了正确的阅读顺序。
优点3:多语言支持
-
测试了中文和英文文档,均能有效解析。
-
根据GitHub上的描述,支持176种语言。
优点4:获取并单独存储表格和图片的标题
- 能够识别并单独保存表格和图片的标题,便于后续引用和管理。
优点5:页眉页脚及脚注识别准确
- 在转换为Markdown格式时,页眉、页脚和脚注已被正确移除,不影响正文阅读。
优点6:段落结构优化
- 段落合并合理,输出结果多为自然段落,易于阅读。
优点7:支持公式解析
- 能够解析数学公式等复杂内容,适合学术文献处理。
优点8:跨平台与环境兼容性
-
支持Windows、Linux、Mac操作系统。
-
兼容CPU和GPU运行环境。
安装MinerU
虚拟化环境
|
|
安装配置
|
|
提示:建议在具备科学上网能力的环境下进行此步骤,以确保依赖项能够顺利下载。
|
|
下载模型
- 注意:如果未下载模型,将会导致错误。请确保完成模型下载。

这里为了方便,使用git来从魔搭上拉取
<code id="code-lang-cobol">git clone https://www.modelscope.cn/wanderkid/PDF-Extract-Kit.git
如果想要使用其它的方式拉取,参考
MinerU/docs/how_to_download_models_zh_cn.md at master · opendatalab/MinerU · GitHub
修改配置文件
在仓库根目录可以获得 MinerU/magic-pdf.template.json at master · opendatalab/MinerU · GitHub 文件
这里解释一下这个命令,实际上是把配置文件发在了c盘的user目录下。
cp magic-pdf.template.json ~/magic-pdf.json
修改配置文件的内容,如下图所示。 output-dir是解析后的文件结果存放的目录。 models-dir是下载的模型的地址。
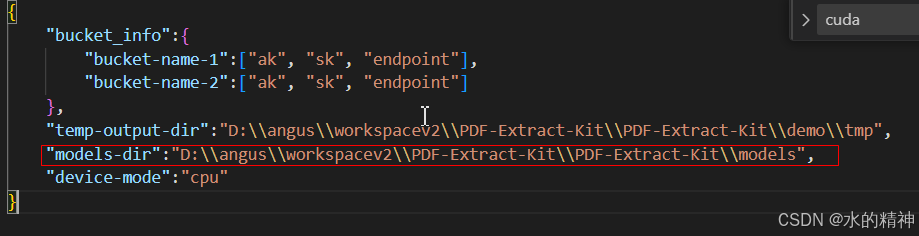
如果您不确定配置文件应该放置在哪个位置,可以通过尝试启动程序来获取提示。当您运行以下命令时,如果配置文件未被正确找到,程序将会报错,指出配置文件的位置问题。
|
|
请将上述命令中的 page1.pdf 替换为您自己的PDF文件名。根据程序返回的错误信息,您可以确定配置文件应放置的确切位置,并将配置文件移至该处。
测试解析效果
一旦配置文件正确放置,您便可以继续进行PDF的解析测试。使用以下命令执行带有内部模型的解析操作:
|
|
请确保将 aaaaaaa.pdf 替换为实际需要解析的PDF文件名。此命令将帮助您验证解析过程是否按预期正常工作。
解析后得到的结果
包含了md结构,json结构,和版面分析的结果
md

layout

- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202411/%E6%9C%80%E6%96%B0%E5%BC%80%E6%BA%90%E7%9A%84%E8%A7%A3%E6%9E%90%E6%95%88%E6%9E%9C%E9%9D%9E%E5%B8%B8%E5%A5%BD%E7%9A%84PDF%E8%A7%A3%E6%9E%90%E5%B7%A5%E5%85%B7MinerUpdf2md-pdf2json--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com