基于MinerU的PDF解析API_structeqtable -- 知识铺 --知识铺
基于MinerU的PDF解析API
- MinerU的GPU镜像构建
- 基于FastAPI的PDF解析接口
产品概述
支持一键启动,已经打包到镜像中,自带模型权重,支持GPU推理加速。在GPU环境下,每页解析的速度比CPU环境下快数十倍。
主要功能
-
删除冗余元素:能够删除页眉、页脚、脚注、页码等元素,确保文本语义连贯。
-
优化多栏布局:对于多栏排版的文档,能够按照人类正常的阅读顺序输出文本。
-
保持文档结构:保留原文档的结构特性,如标题、段落、列表等。
-
多媒体内容提取:可以提取文档中的图像、图片标题、表格、表格标题。
-
数学公式处理:自动识别文档中的数学公式,并将其转换为LaTeX格式。
-
表格转换:自动识别文档中的表格,并将它们转换为LaTeX格式。
-
乱码PDF处理:具备自动检测乱码PDF的功能,并启用OCR技术进行解析。
-
跨平台支持:同时支持Windows、Linux和Mac操作系统。
技术原理
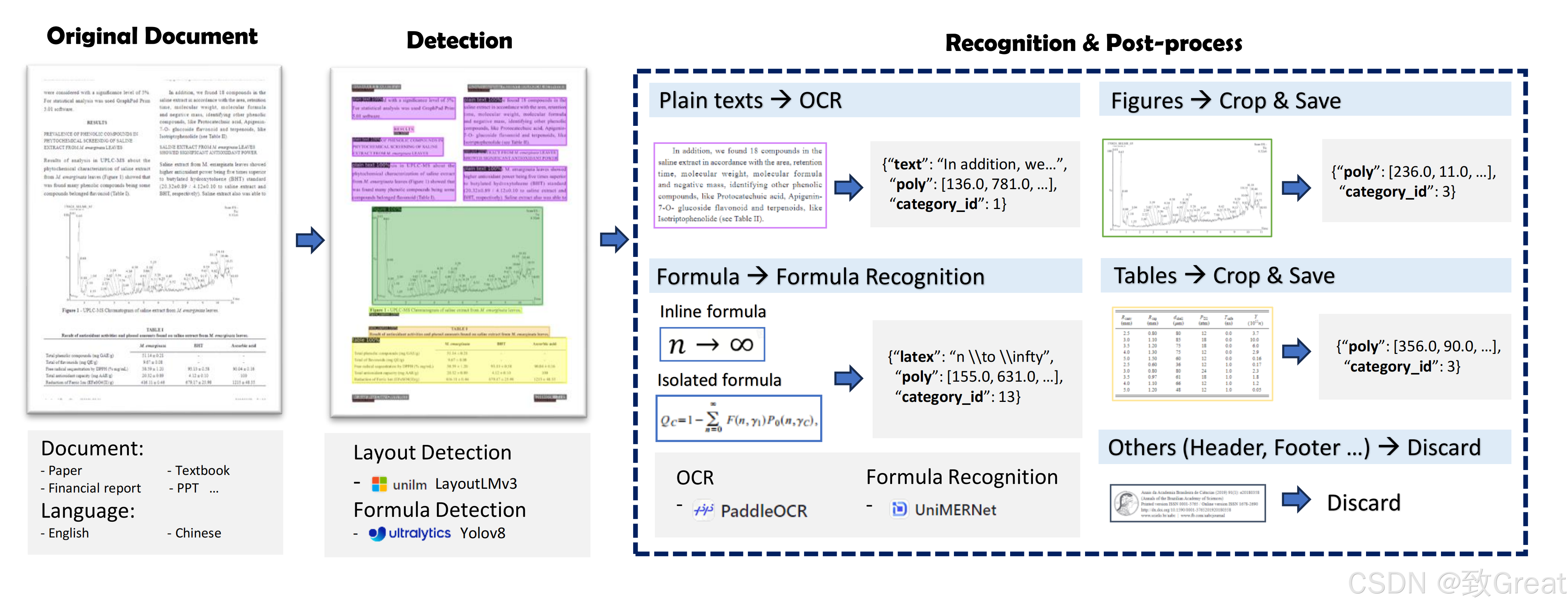
为了高效地从PDF文档中提取高质量的信息,本工具采用了以下核心技术:
-
布局检测:采用
LayoutLMv3模型来识别文档中的不同区域,例如图像、表格、标题和文本块。 -
公式检测与识别:使用
YOLOv8模型检测文档中的公式(包括行内和行间公式),并通过UniMERNet模型进行公式识别。 -
表格识别:利用
StructEqTable模型对文档中的表格进行识别。 -
光学字符识别(OCR):通过
PaddleOCR技术实现对文档中文本的识别,特别是对于乱码PDF文件。 以上技术的综合运用,使得本工具能够在多种环境中高效准确地处理PDF文档。
镜像地址:
阿里云地址:docker pull registry.cn-beijing.aliyuncs.com/quincyqiang/mineru:0.2-models
dockerhub地址:docker pull quincyqiang/mineru:0.2-models
启动命令:
docker run -itd --name=mineru_server --gpus=all -p 8888:8000 quincyqiang/mineru:0.2-models

具体截图请见博客:https://blog.csdn.net/yanqianglifei/article/details/141979684
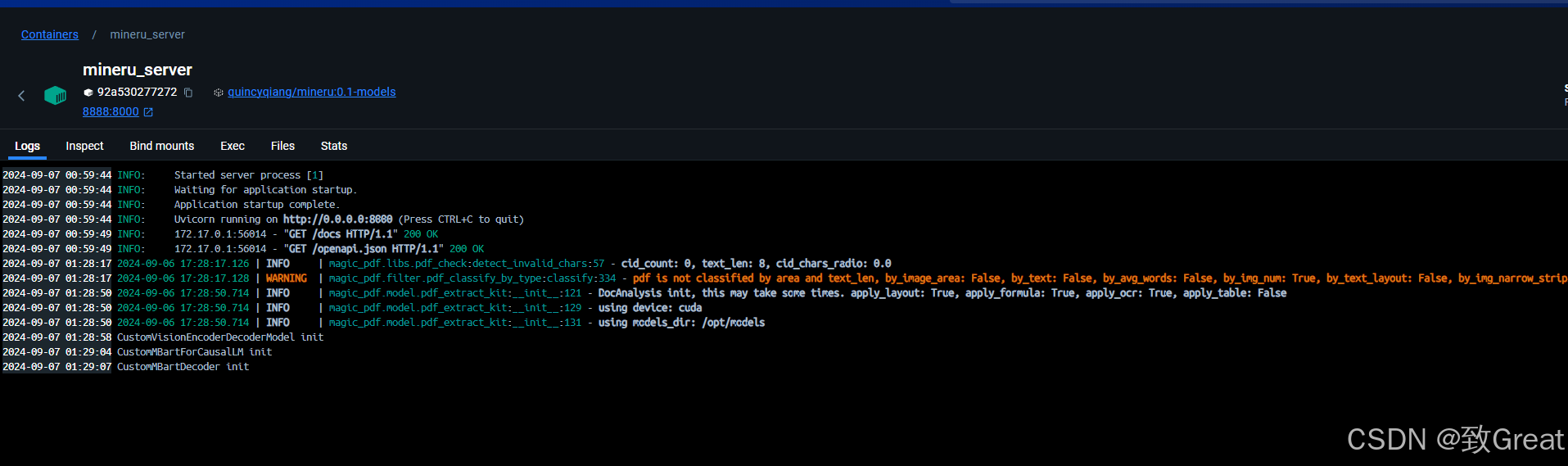
启动日志:
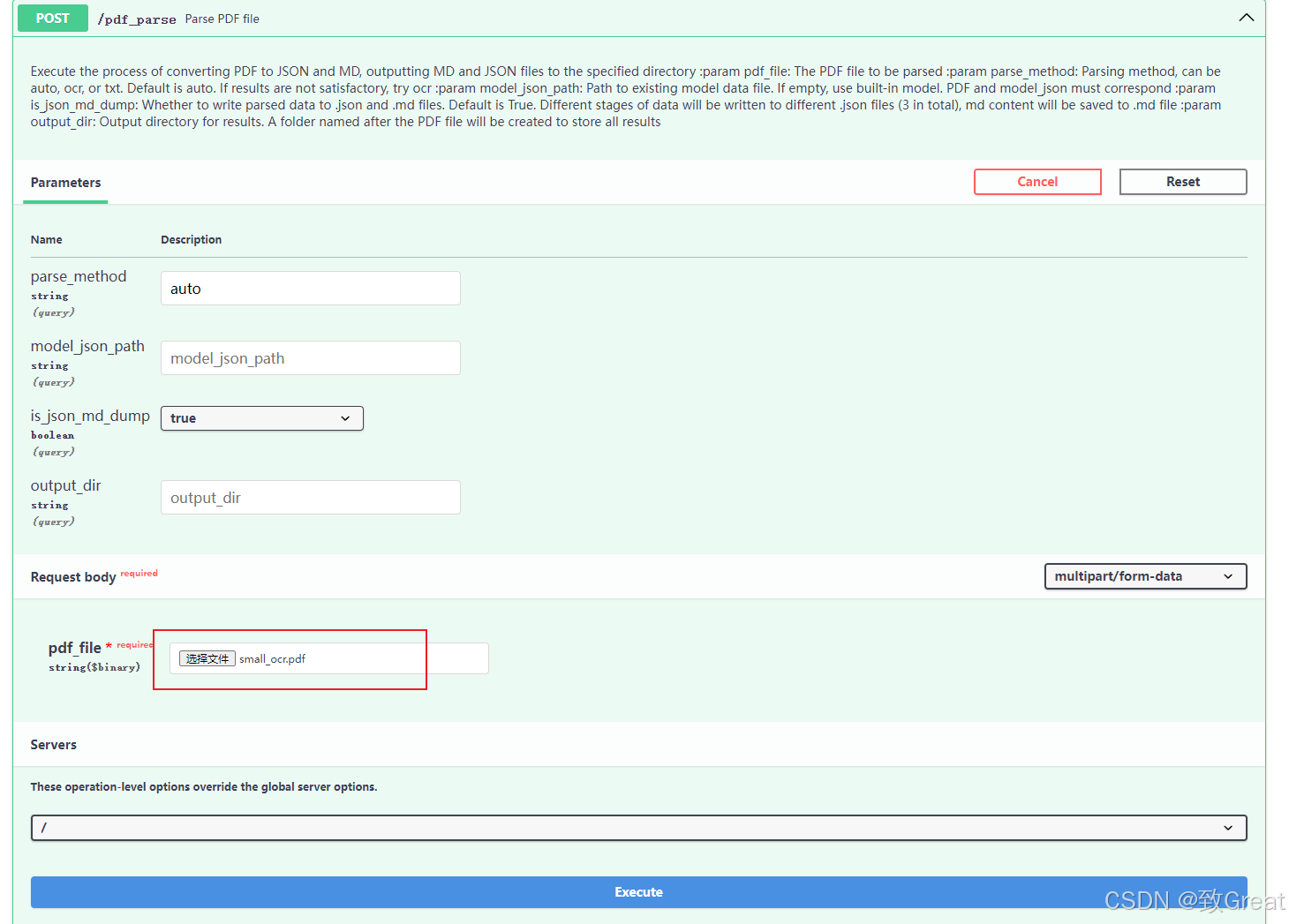
输入参数:
访问地址:
http://localhost:8888/docs
http://127.0.01:8888/docs
解析效果:
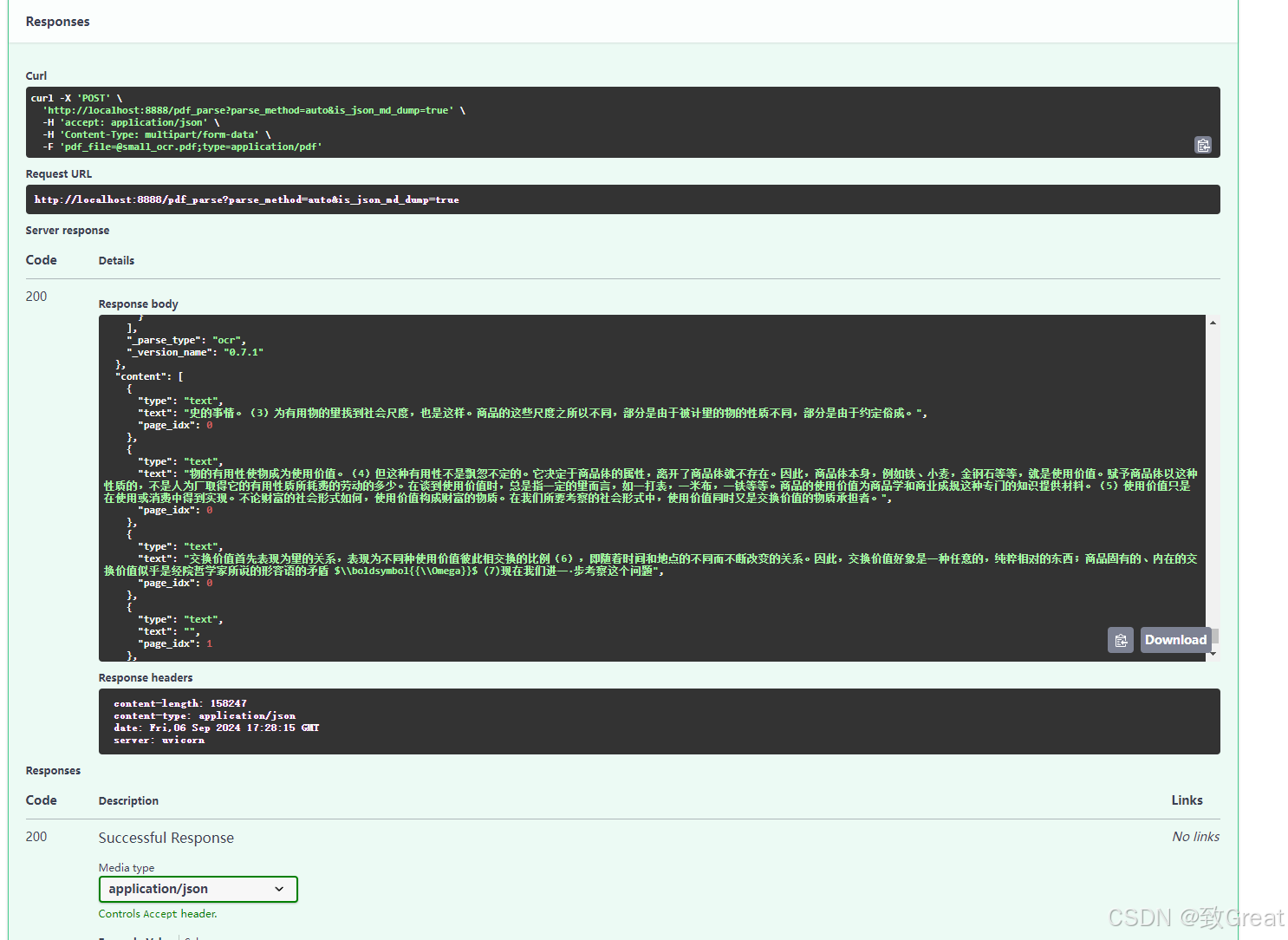
返回内容字段包括:dict_keys([‘layout’, ‘info’, ‘content’])
其中content是一个字典列表:
|
|
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202411/%E5%9F%BA%E4%BA%8EMinerU%E7%9A%84PDF%E8%A7%A3%E6%9E%90API_structeqtable--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com