Xinference本地运行大模型bge-reranker-v2-m3教程 --知识铺


Xinference 本地运行大模型
本文介绍了如何使用 Docker 部署 Xinference 推理框架,并演示了启动和运行多种大模型的过程,包括大语言模型、图像生成模型以及多模态模型。同时,还提供了关于嵌入和重排模型的启动指导,为后续 Dify 调用这些模型打下基础。
一、Xinference 简介
Xorbits Inference (Xinference) 是一个开源分布式推理框架,专为执行大规模模型推理而设计。它支持广泛的模型类型,如大语言模型(LLM)、多模态模型和语音识别模型等。Xinference 的主要特性如下:
-
简化部署:一键式操作简化了各类复杂模型的部署流程。
-
前沿模型内置:用户可以轻松下载并部署诸如
Qwen2和chatglm2等众多前沿开源模型。 -
硬件兼容性:支持在CPU与GPU上进行高效推理,以提高集群性能并减少延迟。
-
API灵活性:提供RPC及RESTful API等多种接口,且兼容OpenAI协议,便于系统集成。
-
分布式的架构:允许跨设备与服务器间的分布式部署,支持高并发请求处理,并简化了扩展和缩减规模的操作。
-
第三方服务整合:能够与LangChain等流行的开发库无缝对接,加速基于人工智能应用的构建。
二、通过Docker部署Xinference
请注意,由于docker镜像文件较大,下载过程可能需要较长时间,请耐心等待。
docker pull xprobe/xinference
查看xinference docker镜像文件,目前大小为17.7GB。
root@ip-172-31-83-158:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
xprobe/xinference latest 96b2be814b0f 2 days ago 17.6GB
创建一个目录,用与存放xinference缓存文件和日志文件。
mkdir -p /xinference/data
启动容器时,镜像默认不包含模型文件,需在容器内下载。若要使用已下载的模型,须将宿主机目录挂载至容器,并配置Xinference环境变量:
- XINFERENCE_MODEL_SRC: 设置模型下载仓库,默认为’huggingface’,可改为’modelscope’。
- XINFERENCE_HOME: 指定Xinference存储模型和日志等文件的目录,默认为
<HOME>/.xinference(其中<HOME>为主目录)。
docker run -d \
--name xinference \
-v /xinference/data/.xinference:/root/.xinference \
-v /xinference/data/.cache/huggingface:/root/.cache/huggingface \
-v /xinference/data/.cache/modelscope:/root/.cache/modelscope \
-v /xinference/log:/workspace/xinference/logs \
-e XINFERENCE_HOME=/xinference \
-p 9997:9997 \
--gpus all \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0 --log-level debug
三、Xinference 本地运行大模型
容器启动后,访问公网地址加上9997端口,启动qwen2-instruct模型。
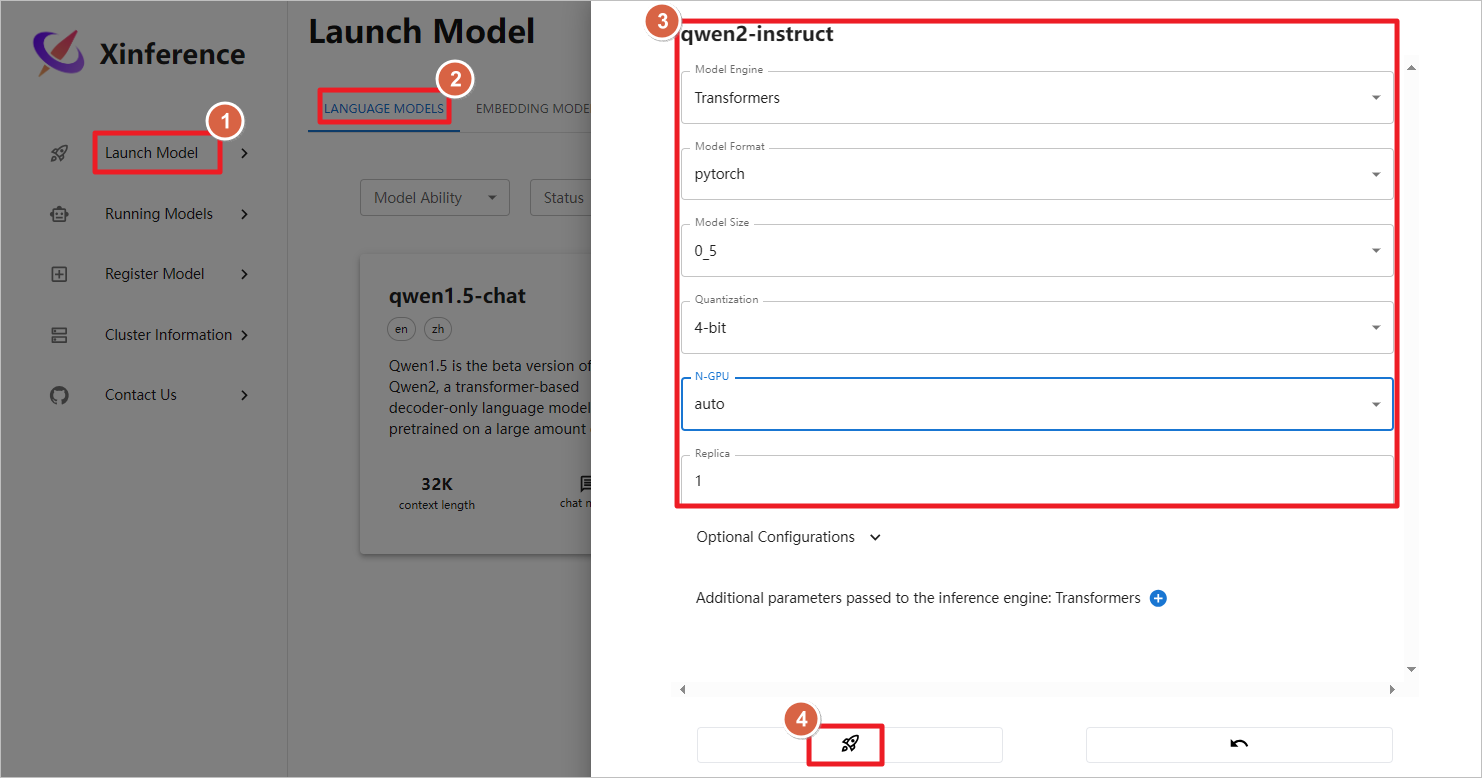
使用Xinference自带的图形化聊天界面。
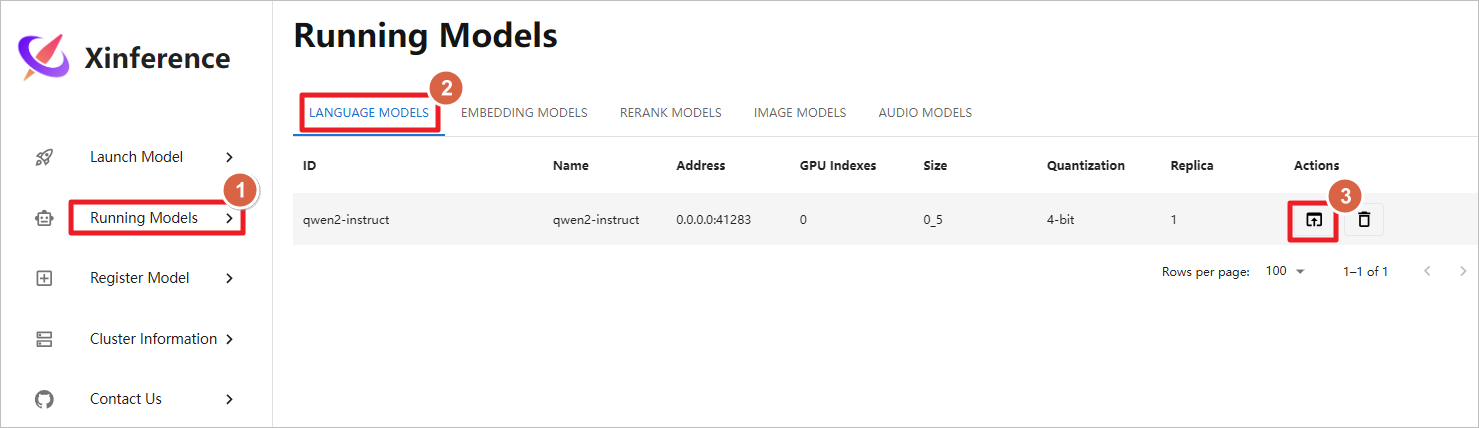
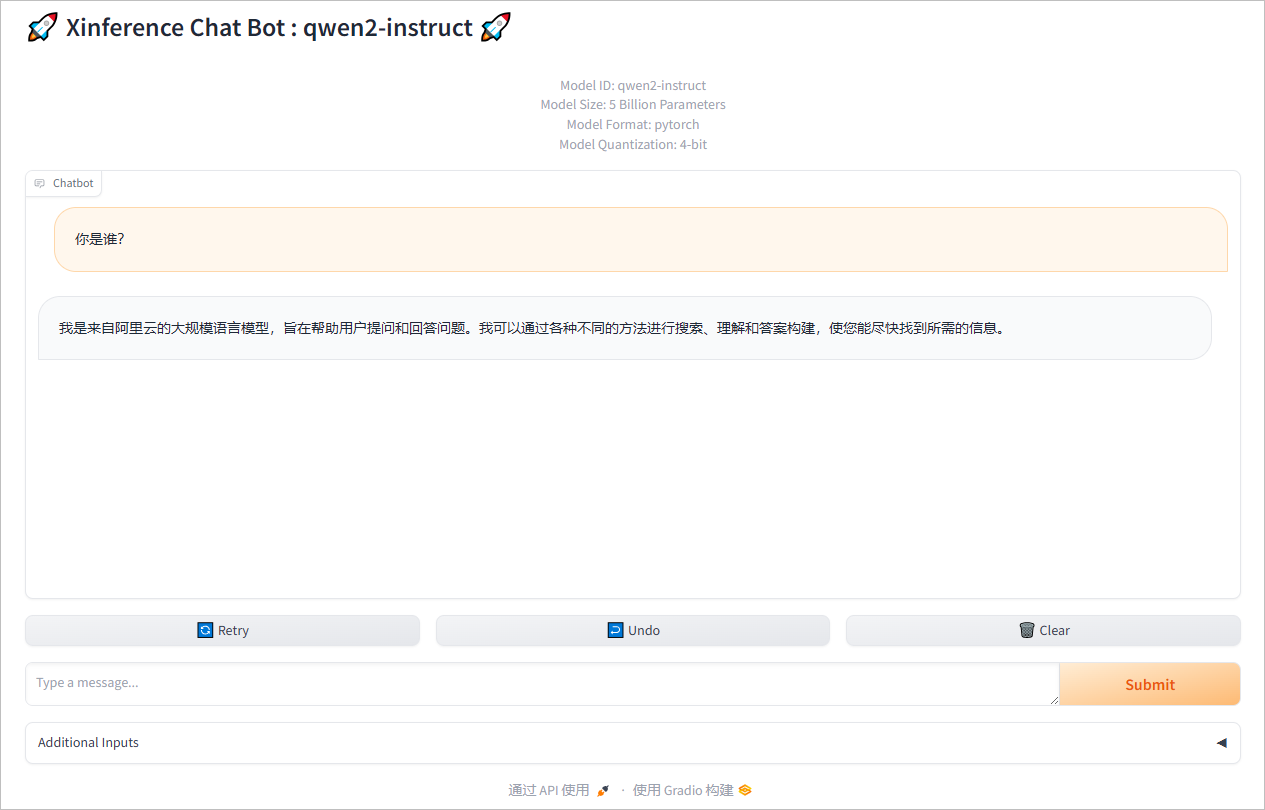
聊天测试。
测试图片生成模型,启动sd-trubo图片生成模型,模型下载和启动的时间较长,需要多等待一会,运行大概需要12G GPU。
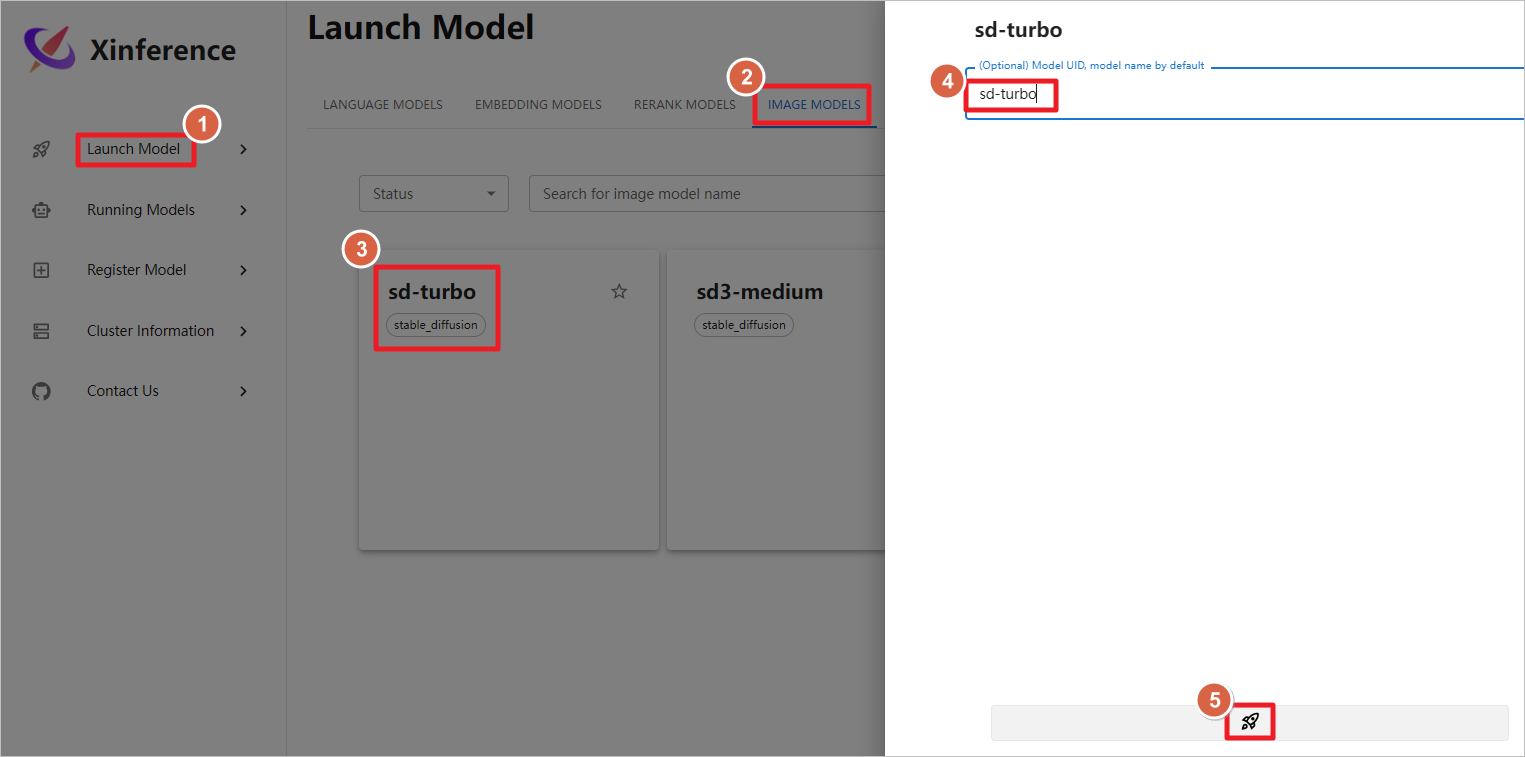
启动图形化聊天界面。
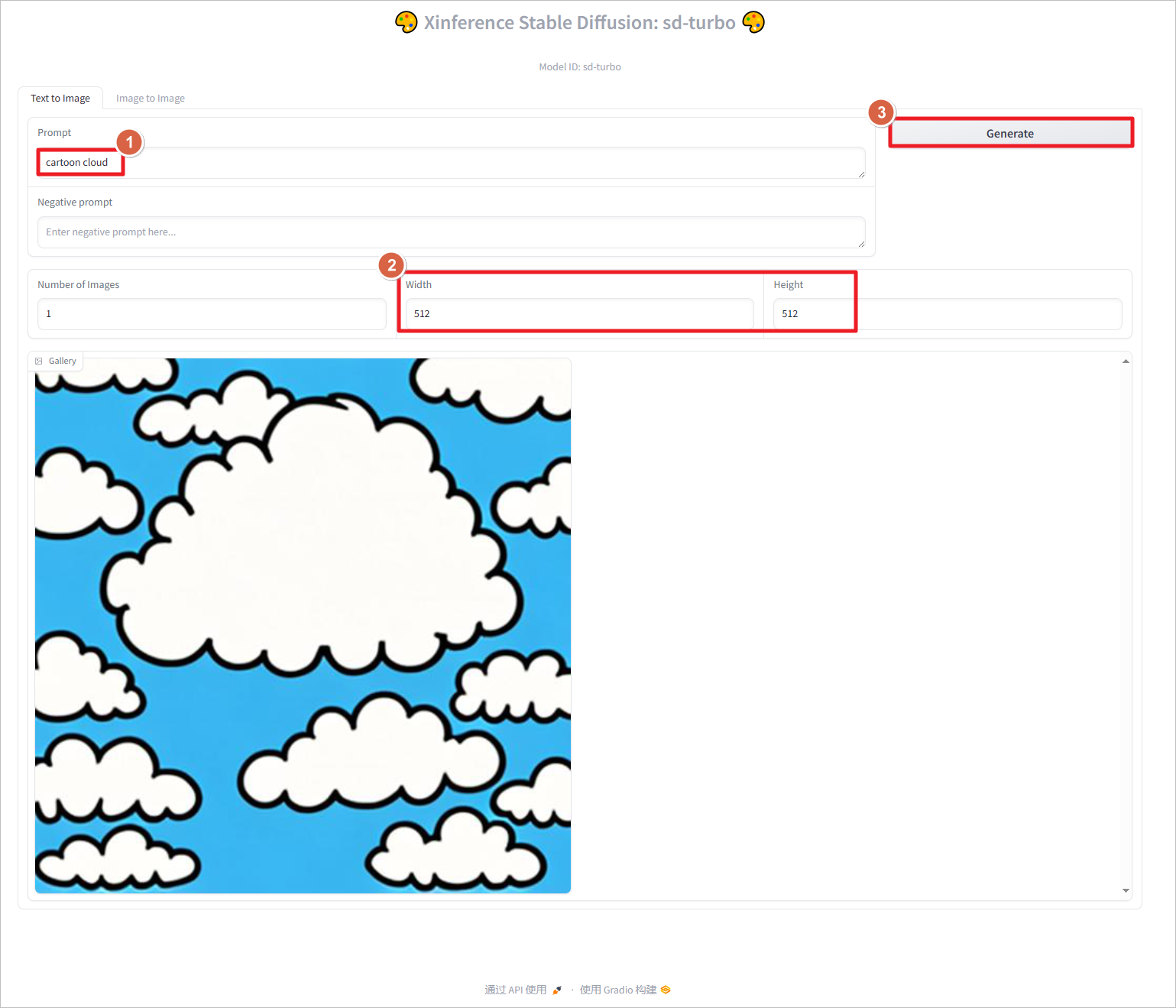
使用提示词cartoon cloud生成图片,设置分辨率为512*512,点击Generate生成图片。图片像素设置的越大,生成的时间越长,占用的GPU越多,设置1024 * 1024像素,大致需要占用6G GPU。
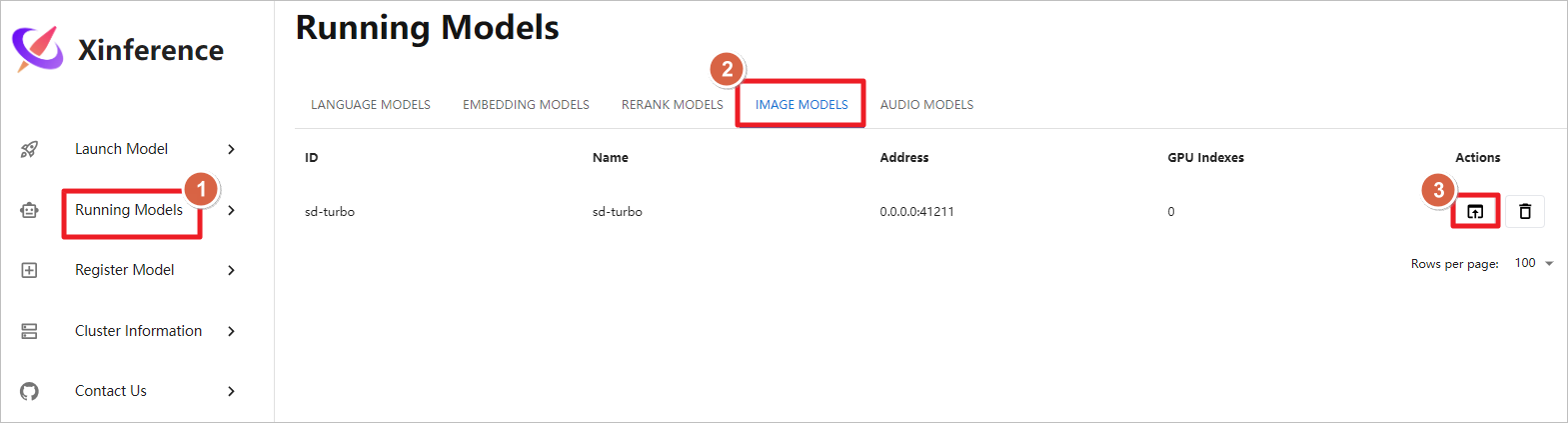
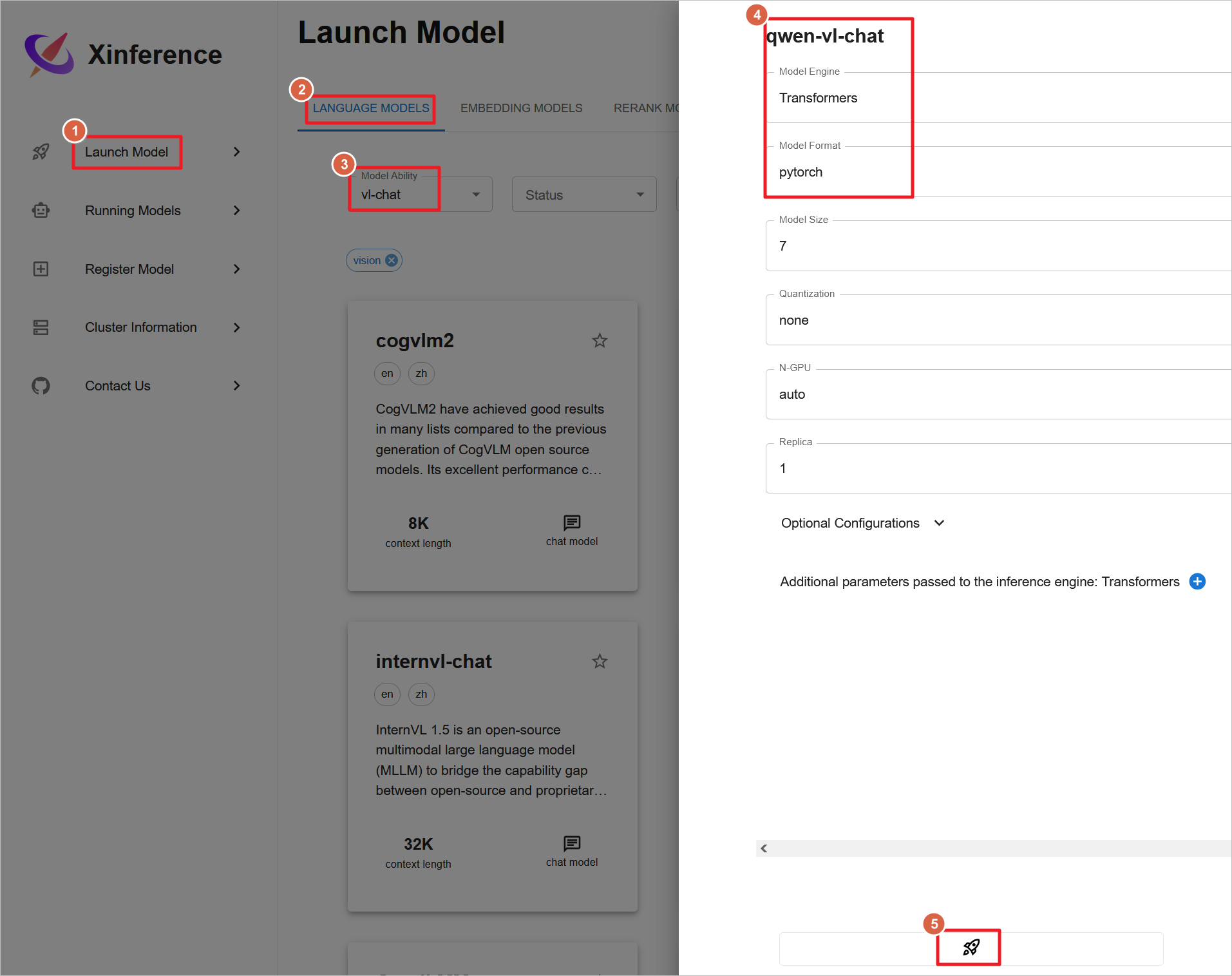
Xinference 目前不支持同时运行多个大型模型。若要测试新的多模态模型,比如启动qwen-vl-chat视觉聊天模型,则需要先停止当前正在运行的任何模型。
-
启动和下载
qwen-vl-chat模型可能耗时较长。 -
运行该模型至少需要20G GPU内存。
-
推荐使用
g5.xlarge实例(配备24G GPU)以满足运行需求。 -
g4dn.xlarge实例由于只提供16G GPU内存,不足以运行此模型。
请确保选择合适的硬件配置来避免因资源不足而导致的问题。
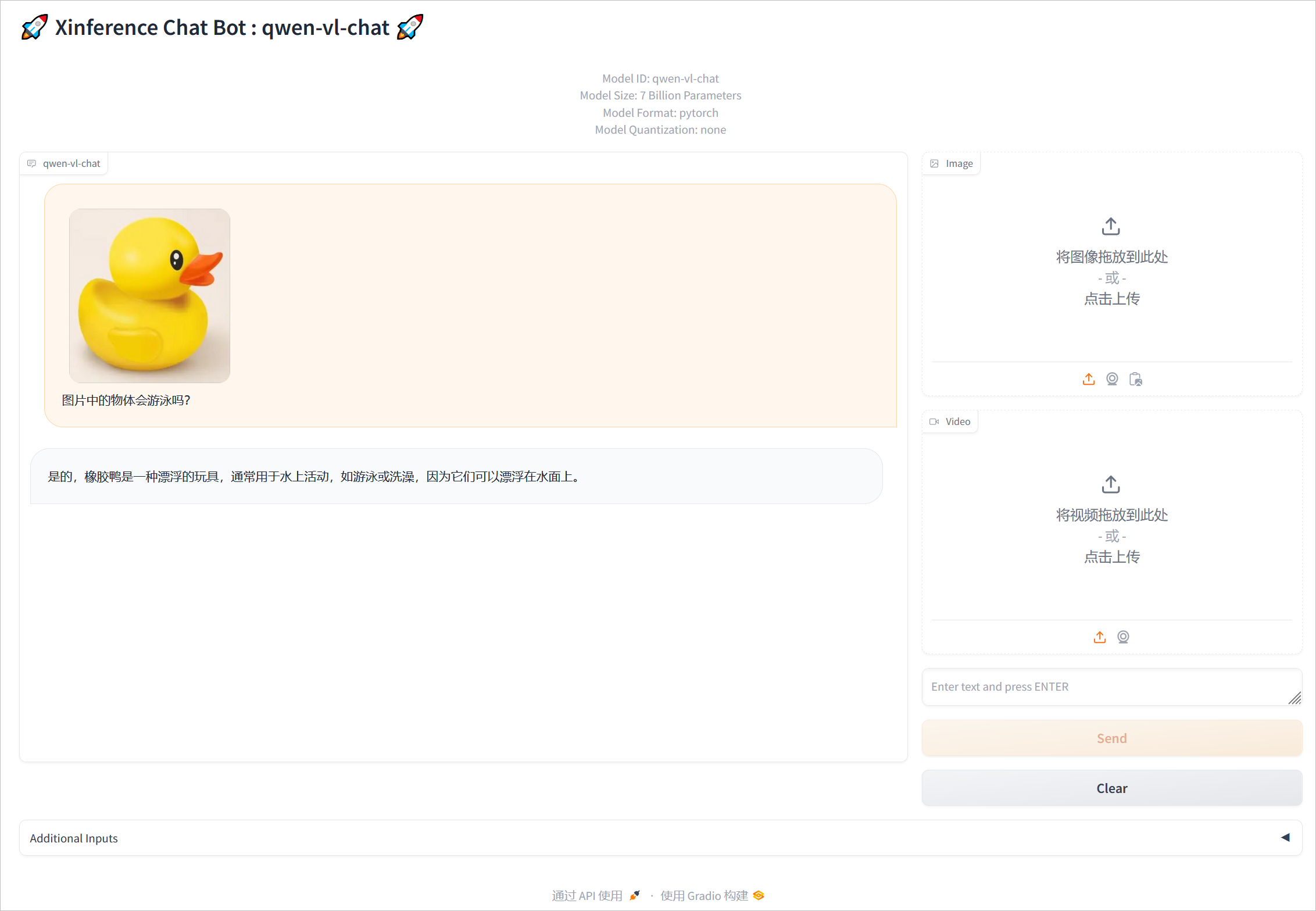
上传图片聊天测试。
四、Xinference 启动嵌入和重排模型
在使用Xinference时,系统限制为只能同时激活一个语音模型、一个图片模型以及一个文本模型。然而,对于嵌入(embedding)模型与重排(reranking)模型,则允许同时启动多个实例。
嵌入模型
- 模型名称:
bge-m3
重排模型
- 模型名称:
bge-reranker-v2-m3
以上配置确保了用户能够在处理特定任务时,利用多样的嵌入功能来丰富数据表示,并通过先进的重排技术提高结果的相关性与准确性。
启动bge-m3嵌入模型,ollama后续可以调用这个模型。
模型正常启动,后续Dify可以调用此嵌入模型。
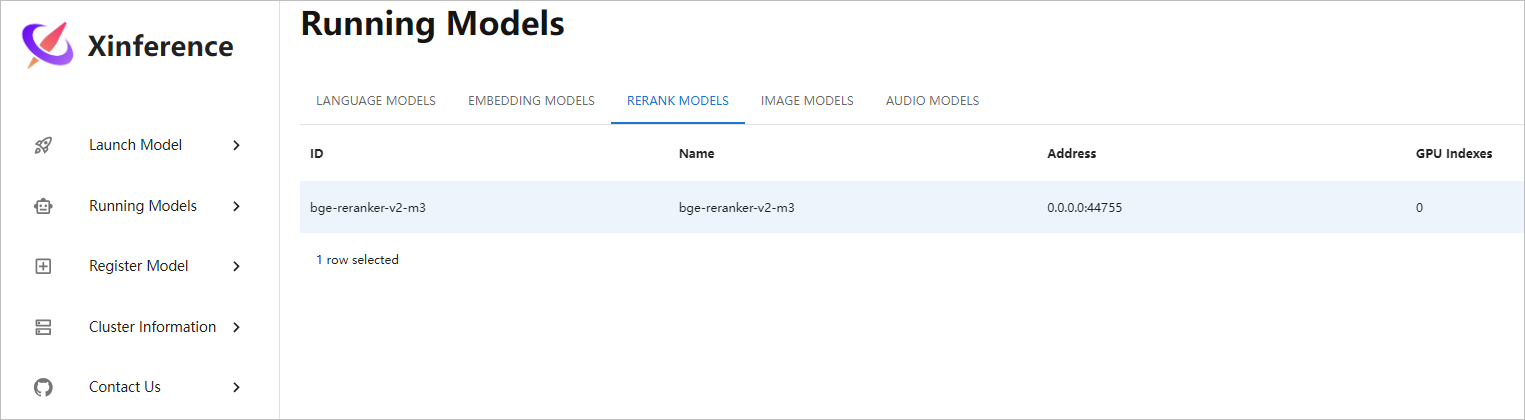
启动bge-reranker-v2-m3重排模型,ollama 后续可以调用这个模型。
模型正常启动,后续Dify可以调用此重排模型。
五、文档链接
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/Xinference%E6%9C%AC%E5%9C%B0%E8%BF%90%E8%A1%8C%E5%A4%A7%E6%A8%A1%E5%9E%8Bbge-reranker-v2-m3%E6%95%99%E7%A8%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com