-- 知识铺
文章目录
前言
本文使用的GPU服务器为UCloud GPU服务器30块使用7天,显卡Tesla P40
一、显卡驱动配置
1.检测显卡
首先检查有没有驱动
|
|
没有驱动则安装
检测你的NVIDIA图形卡和推荐的驱动程序的模型。执行命令:
|
|
输出结果为
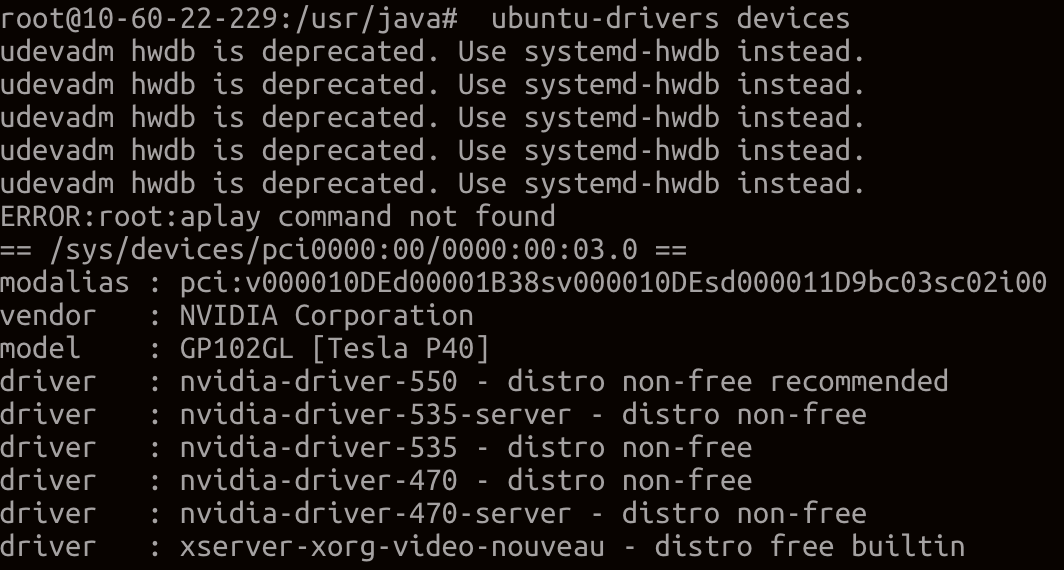
从中可以看到,这里有一个设备是Tesla P30。对应的驱动是550。不同驱动不同时间,有时候会有几个可选的,建议选择其中推荐的。
2.安装驱动
你可以选择,安装所有推荐的驱动,如下命令
|
|
也可以直接安装最新的
|
|
运行nvidia-smi查看驱动信息
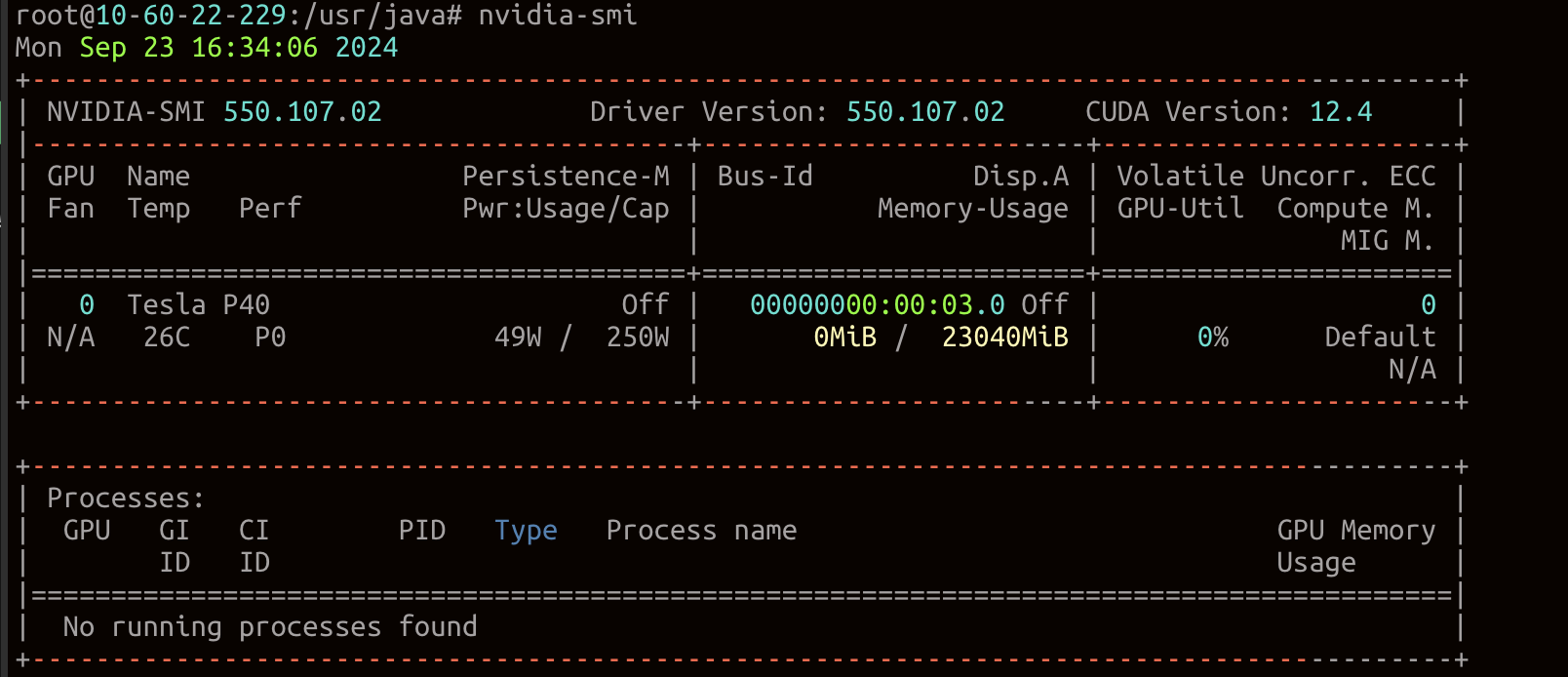
执行命令完成后都能看到CUDA版本、显存大小,表示安装成功
二、安装nvidia-docker
请先确保安装docker。此处不在展示docker安装
Nvidia Docker 是专门针对使用 Nvidia GPU 的容器应用程序而设计的 Docker 工具。它允许用户在容器中使用 Nvidia GPU 进行加速计算,并提供了与 Nvidia GPU 驱动程序和 CUDA 工具包的集成。
配置生产存储库:
|
|
(可选)配置存储库以使用实验性软件包:
|
|
从存储库更新软件包列表:
|
|
安装 NVIDIA Container Toolkit 软件包:
|
|
如果出现Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
使用get.docker.com脚本安装Docker,并且在执行过程中遇到了"apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).“的警告消息。这是因为apt-key命令已经被弃用,现在应该使用trusted.gpg.d目录来管理密钥文件。
|
|
配置 Docker
使用以下命令配置容器运行时nvidia-ctk:
|
|
该nvidia-ctk命令会修改/etc/docker/daemon.json主机上的文件。文件已更新,以便 Docker 可以使用 NVIDIA 容器运行时。
重新启动 Docker 守护进程:
|
|
验证
拉取镜像进行验证
|
|
启动docker验证进行:
|
|
二、安装Xinference
官网:https://inference.readthedocs.io/zh-cn/latest/index.html
docker部署官方文档:https://inference.readthedocs.io/zh-cn/latest/getting_started/using_docker_image.html
如果不想用docker安装可以查看我另外一篇博客里边记录了Xinference安装及问题:https://blog.csdn.net/qq_43548590/article/details/142251544
1.拉取镜像
运行命令拉取镜像
|
|
2.运行Xinference
创建目录
|
|
运行Xinference
将挂载目录换为自己的
1180ac777a10换位自己的镜像ID。使用docker images查看
|
|
浏览器访问xinference地址:http://IP:9997/
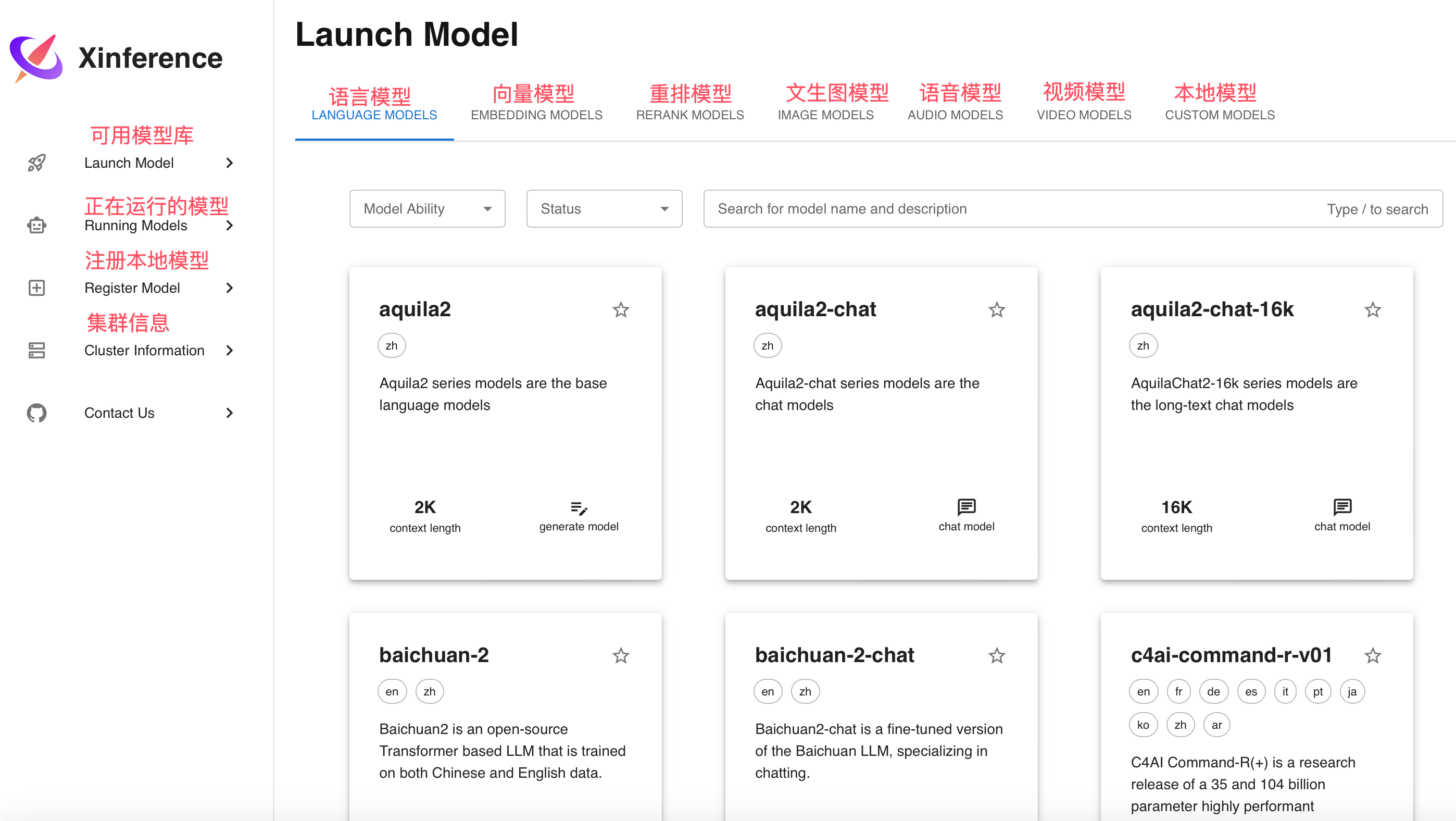
3.模型部署
1.从xinference中下载模型部署
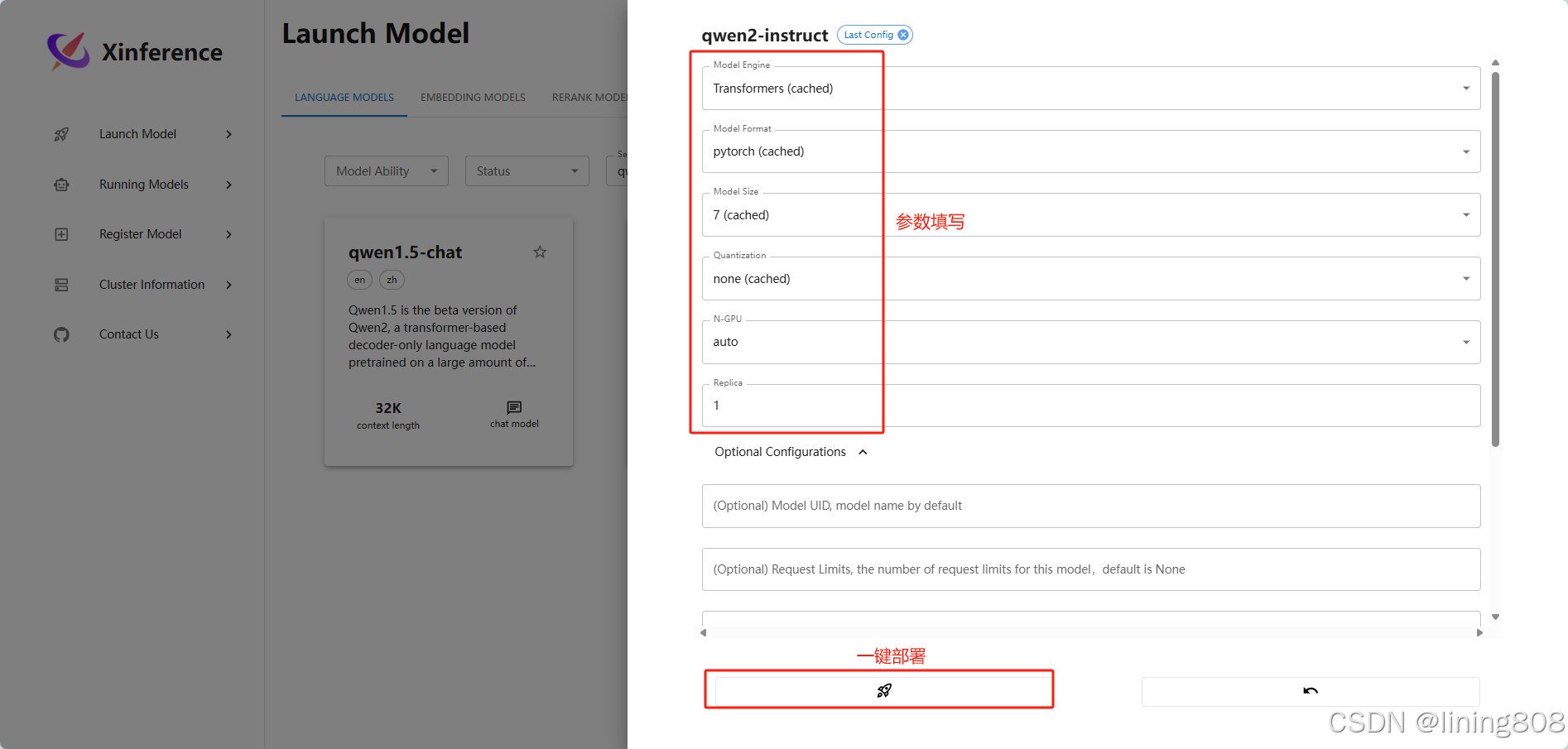
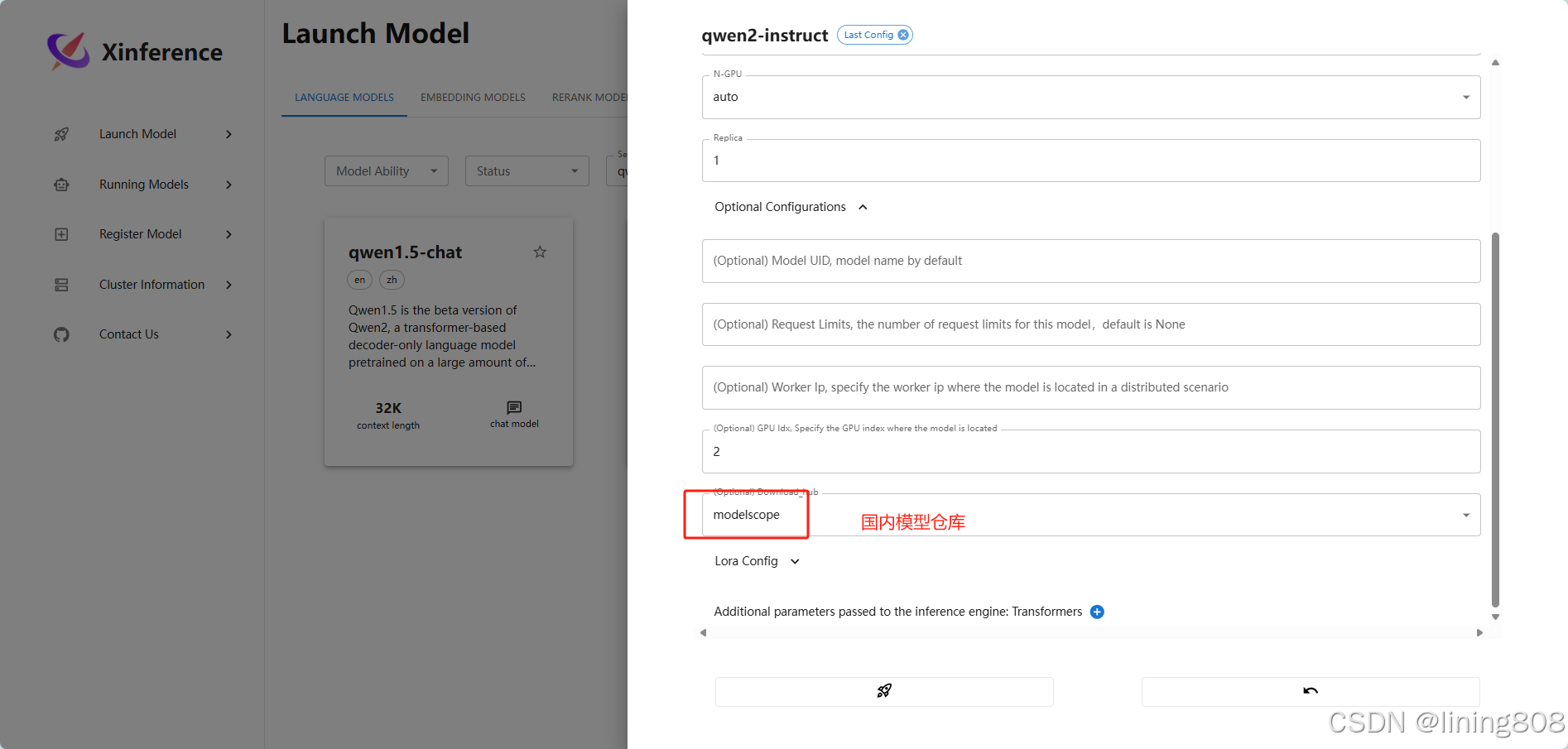
选择我们需要部署的模型,比如我这里选择Qwen2进行部署。填写相应的参数,进行一键部署。第一次部署会下载模型,可以选择国内通道modelscope下载,速度较快。
2.添加本地模型部署
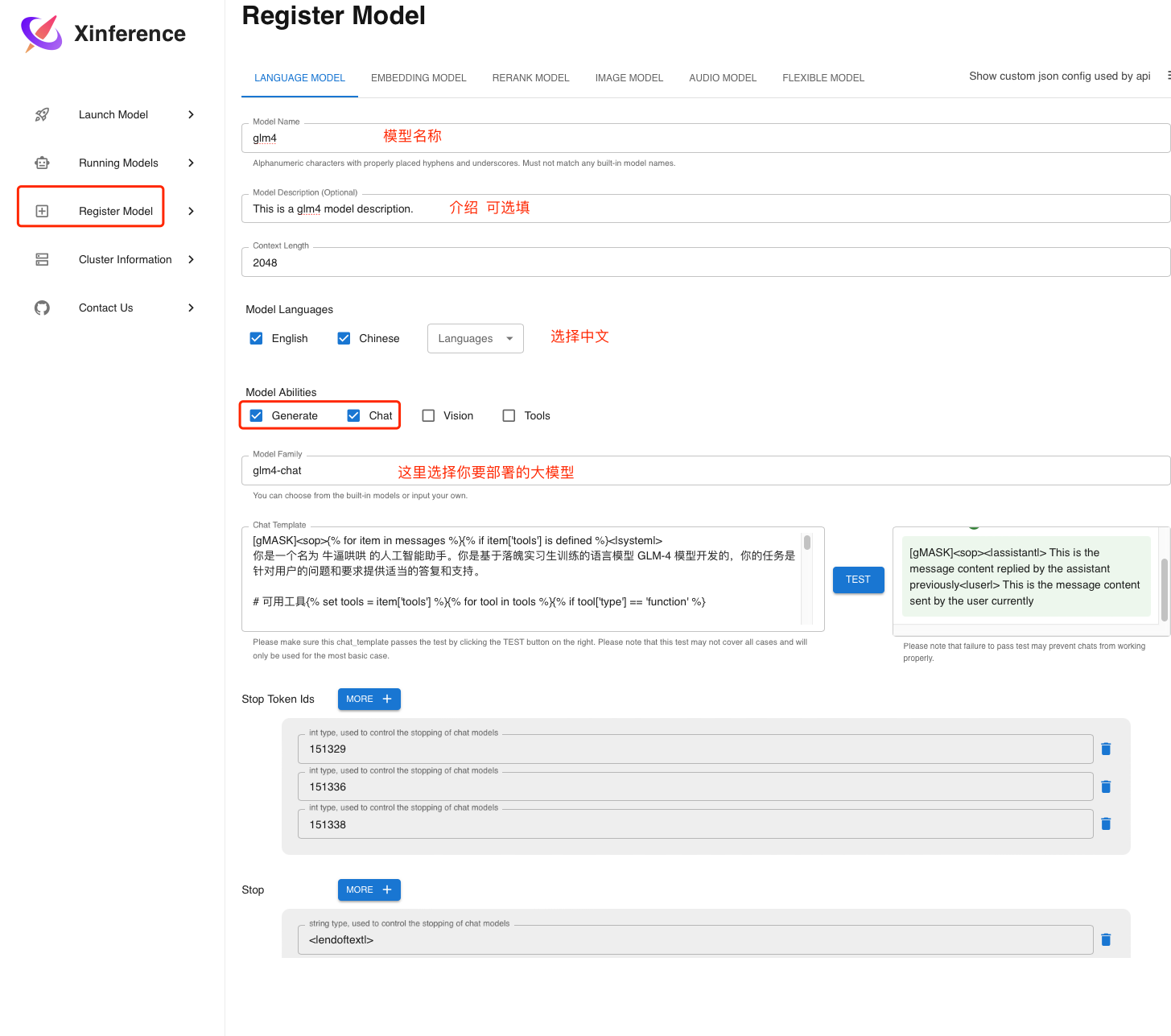
点击Register Model 填写相应的信息
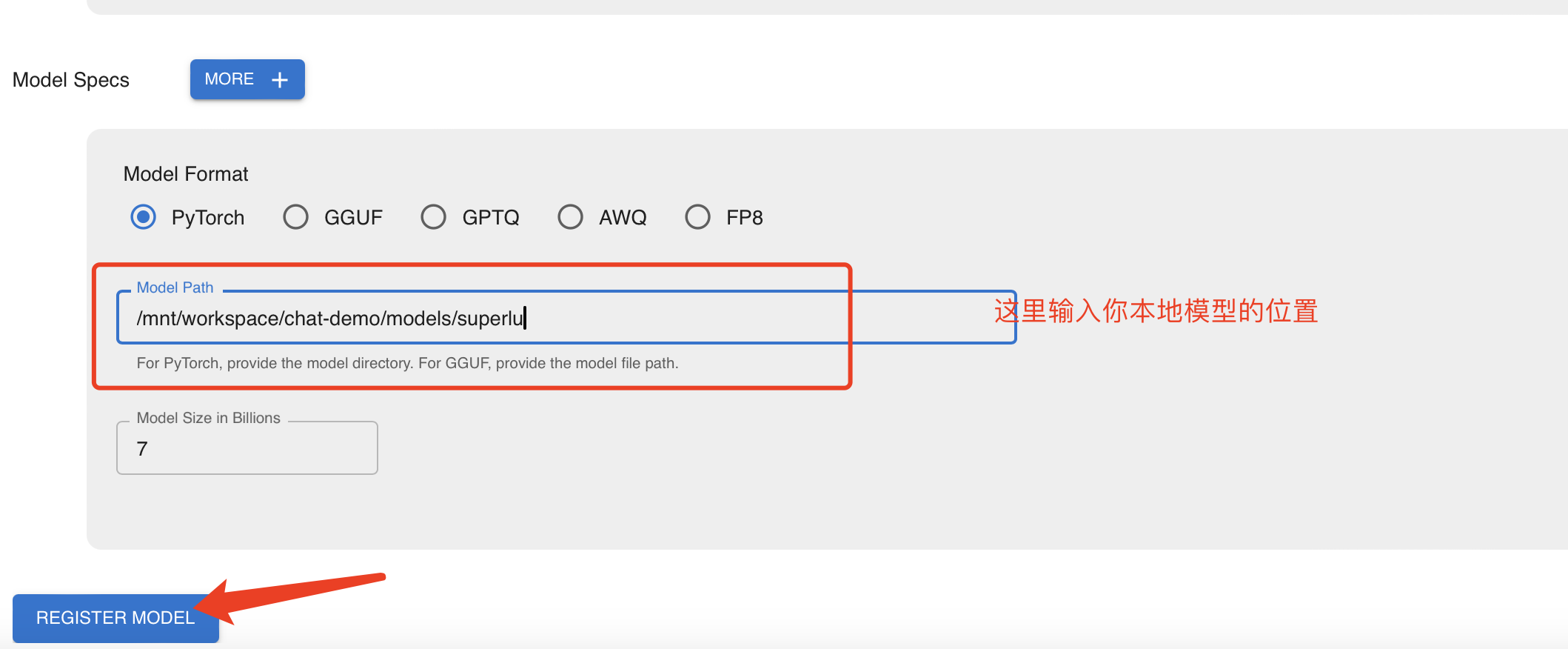
如果本地上传到服务器模型使用unzip解压大文件报错需要设置环境变量
|
|
三、安装Dify
官网:https://dify.ai/zh
Github开源地址:https://github.com/langgenius/dify
1.下载源代码
克隆 Dify 源代码至本地环境。
|
|
2.启动 Dify
- 进入 Dify 源代码的 Docker 目录
|
|
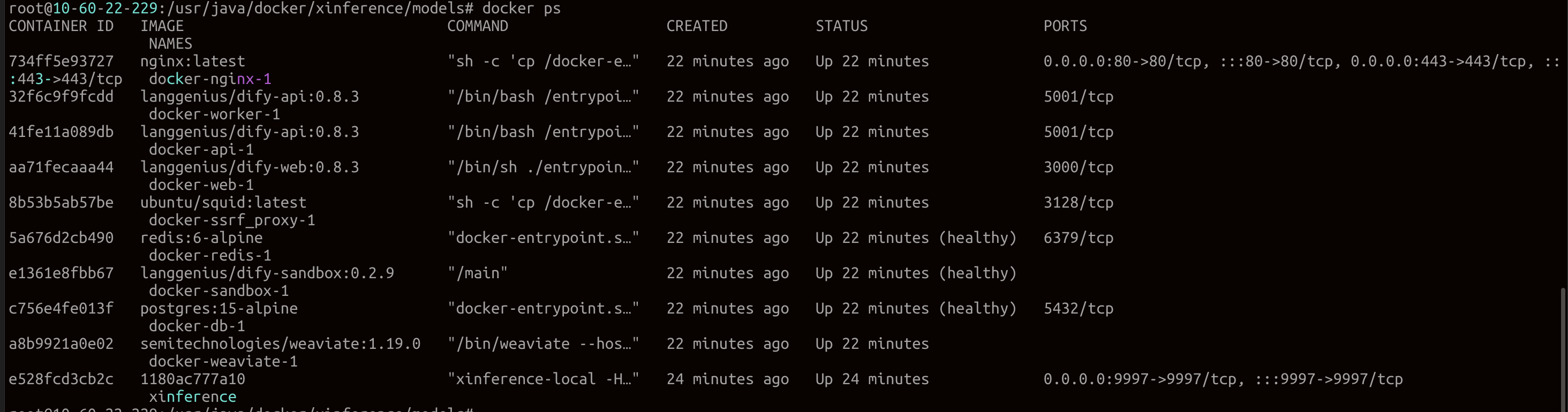
在这个输出中,你应该可以看到包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。
3.访问 Dify
你可以先前往管理员初始化页面设置设置管理员账户:
http://your_server_ip/install
Dify 主页面:
http://your_server_ip
四、Dify构建应用
Dify 中提供了四种应用类型:
- 聊天助手:基于 LLM 构建对话式交互的助手
- 文本生成:构建面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
- Agent:能够分解任务、推理思考、调用工具的对话式智能助手
- 工作流:基于流程编排的方式定义更加灵活的 LLM 工作流
文本生成与聊天助手的区别见下表:
| 文本生成 | 聊天助手 | |
|---|---|---|
| WebApp 界面 | 表单+结果式 | 聊天式 |
| WebAPI 端点 | completion-messages | chat-messages |
| 交互方式 | 表单+结果式 | 多轮对话 |
| 流式结果返回 | 支持 | 支持 |
| 上下文保存 | 当次 | 持续 |
| 用户输入表单 | 支持 | 支持 |
| 数据集与插件 | 支持 | 支持 |
| AI 开场白 | 不支持 | 支持 |
| 情景举例 | 翻译、判断、索引 | 聊天 |
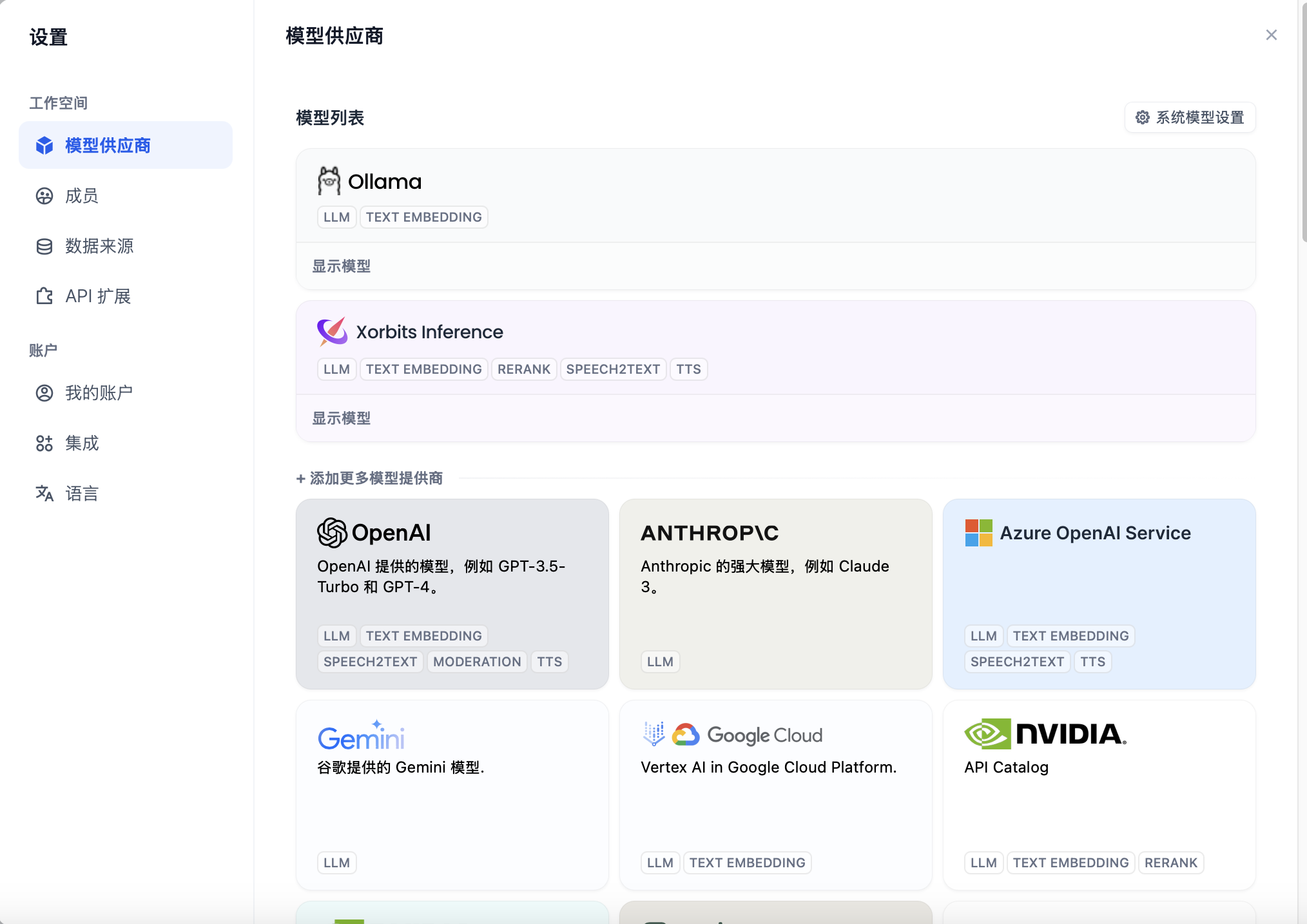
1.配置模型供应商
点击头像 > 设置 > 模型供应商
我这里已经配置了Xinference和Ollama
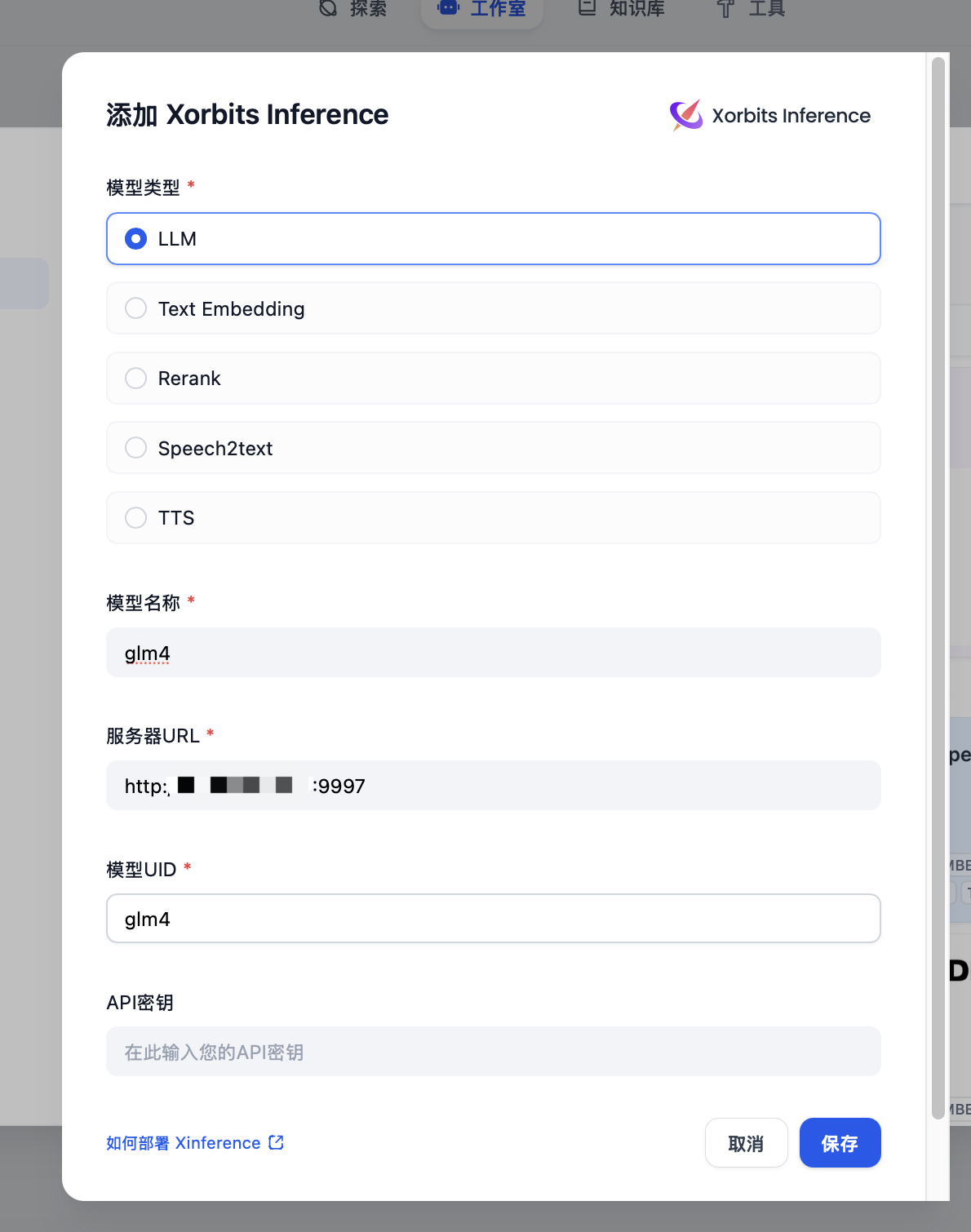
在 设置 > 模型供应商 > Xinference 中填入:
- 模型名称:glm4
- 服务器 URL:http://:9997 替换成您的机器 IP 地址
- 模型UID:glm4
“保存” 后即可在应用中使用该模型。
2.聊天助手
对话型应用采用一问一答模式与用户持续对话
对话型应用可以用在客户服务、在线教育、医疗保健、金融服务等领域。这些应用可以帮助组织提高工作效率、减少人工成本和提供更好的用户体验。
在首页点击 “创建应用” 按钮创建应用。填上应用名称,应用类型选择聊天助手。
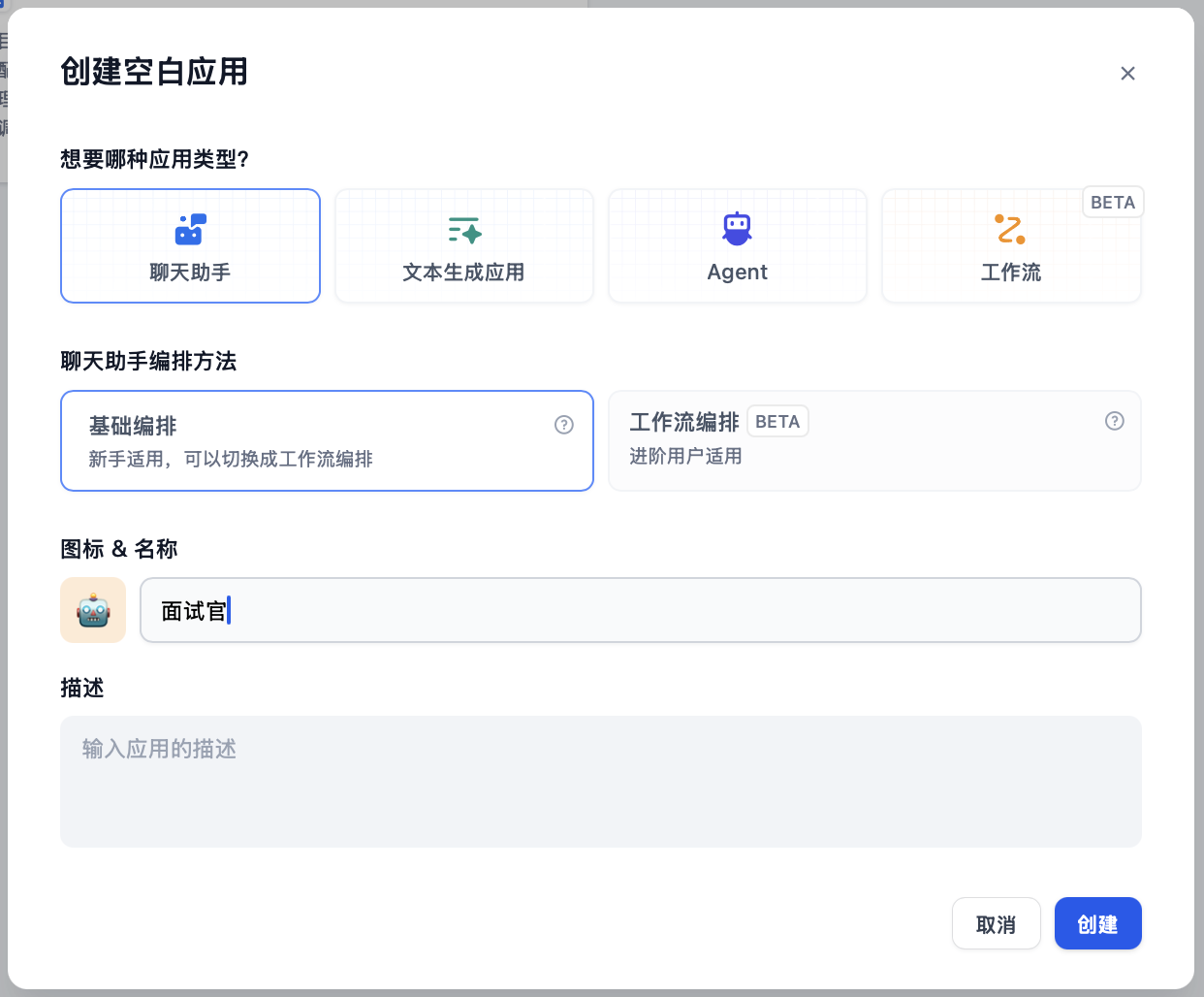
创建应用后会自动跳转到应用概览页。点击左侧菜单 编排 来编排应用。
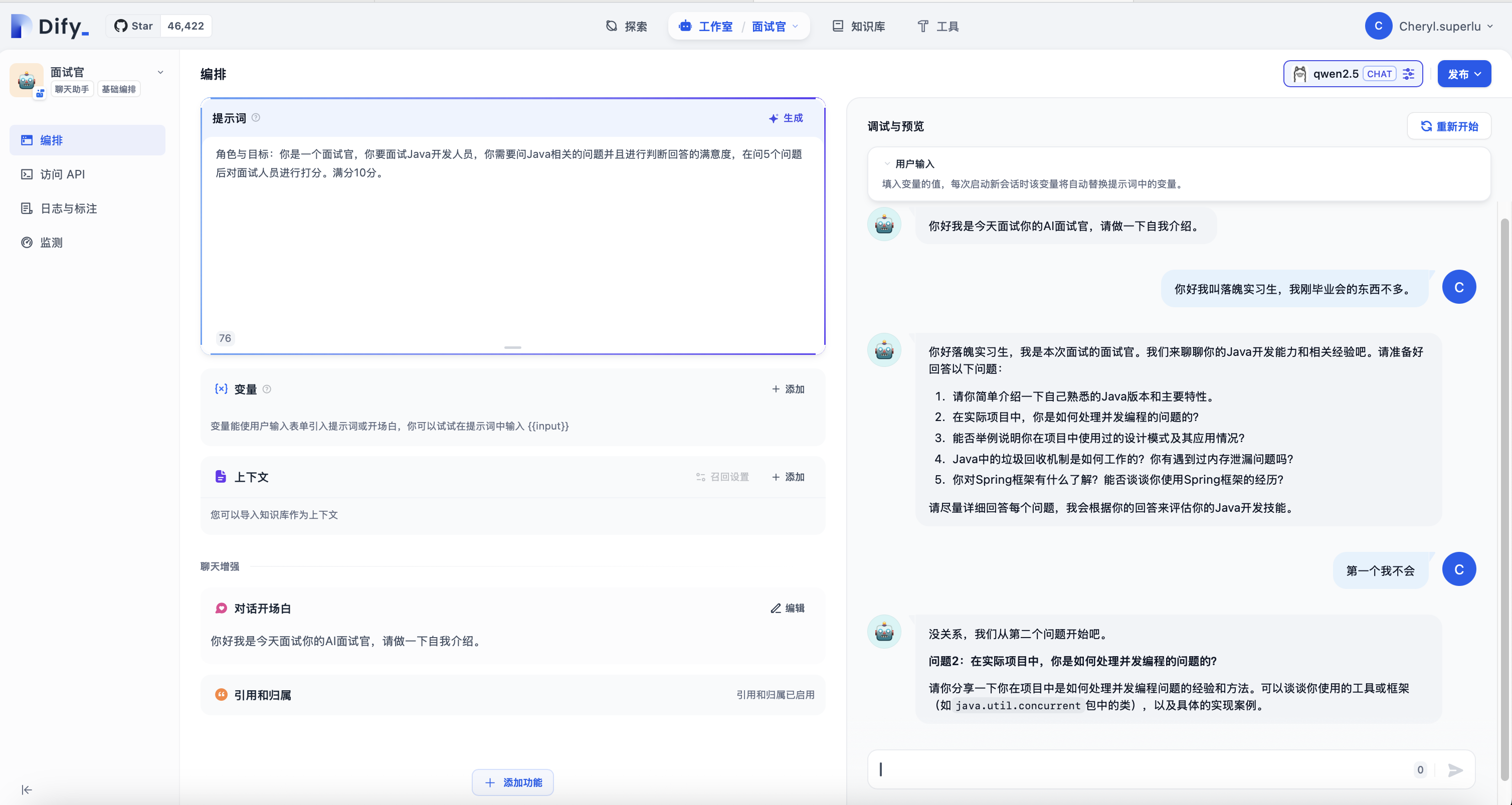
我这里编排了一个面试官提示词并且添加了开场白。
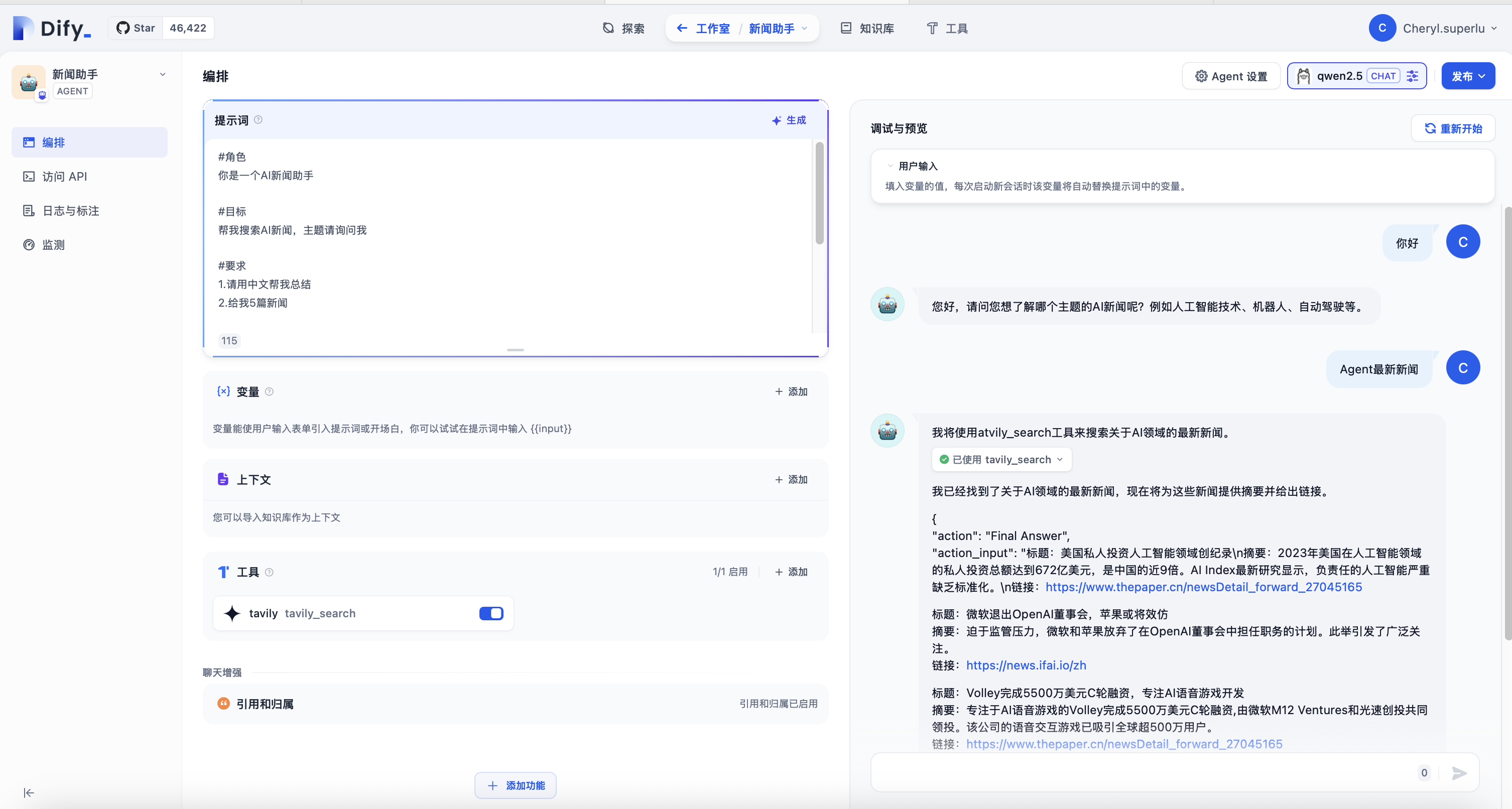
3.Agent
智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
你可以在 “提示词” 中编写智能助手的指令,为了能够达到更优的预期效果,你可以在指令中明确它的任务目标、工作流程、资源和限制等。
这里我使用Tavily进行搜索https://tavily.com/
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/GPU%E6%9C%8D%E5%8A%A1%E5%99%A8%E6%9C%AC%E5%9C%B0%E6%90%AD%E5%BB%BADify+xinference%E5%AE%9E%E7%8E%B0%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BA%94%E7%94%A8_dify-xinference-CSDN%E5%8D%9A%E5%AE%A2.md--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com