运用Dify、Xinference与Ollama构建知识库 --知识铺
记录下运用Dify + xinference + ollama打造带重排序(Rerank)步骤的知识库问答,更好的是—-即使在我的3060M上其也能完全本地运行并有不错的效果!3060M本地运行llama3-9B的生成速度参照前文。
git clone https://github.com/langgenius/dify.git
cd dify/docker
docker compose up -d
随后访问本地的http://localhost根据网页提示进行一步步设置就行了。
xinference
创建一个docker-compose.yaml:
services:
xinference:
image: xprobe/xinference:v0.11.2
environment:
- XINFERENCE_HOME=/root/.xinference
- HUGGING_FACE_HUB_TOKEN=hf_114514
volumes:
- /mnt/Games/Model:/root/.xinference
ports:
- "9998:9997"
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
command: xinference-local -H 0.0.0.0
注意这儿我挂载了一个volumes上去以将模型文件保存在本地(否则每次容器重启都要下载一次),以及定义了HUGGING_FACE_HUB_TOKEN,这样就可以从🤗上拉取一些需要权限访问的模型(比如llama3)了。
快捷启动
再写一个简单的bash脚本快捷启动这两个容器:
#!/bin/bash
cd /home/menghuan/Documents/Xinference
echo "Xinference"
docker compose up -d
echo "dify"
cd /home/menghuan/Documents/dify
docker compose up -d
sleep 10
curl -X 'POST' \
'http://127.0.0.1:9998/v1/models' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model_engine": "xinference",
"model_uid": "bge-reranker-v2-m3",
"model_name": "bge-reranker-v2-m3",
"gpu_idx": 0,
"model_type": "rerank"
}'
echo "done!"
首先,您需要配置Dify。这个过程相对简单,但有几个关键点需要注意:xinference的模型UID默认情况下是等于其模型名字的。因此,在更改系统模型设置时,请确保了解这一点,因为这决定了默认情况下会使用哪个模型。当然,您也可以为单个工作流或知识库自定义其聊天或向量化模型。 接下来,为了实现开机启动后自动运行这两个脚本,您需要进行以下操作:
- 确保您的脚本已经正确编写并保存在适当的位置。2. 根据您的操作系统(如Windows、Linux等),找到相应的开机启动设置。3. 添加新任务以在开机时运行您的脚本。
最后,不要忘记检查和测试这些设置,以确保它们在系统重启后能够正常工作。
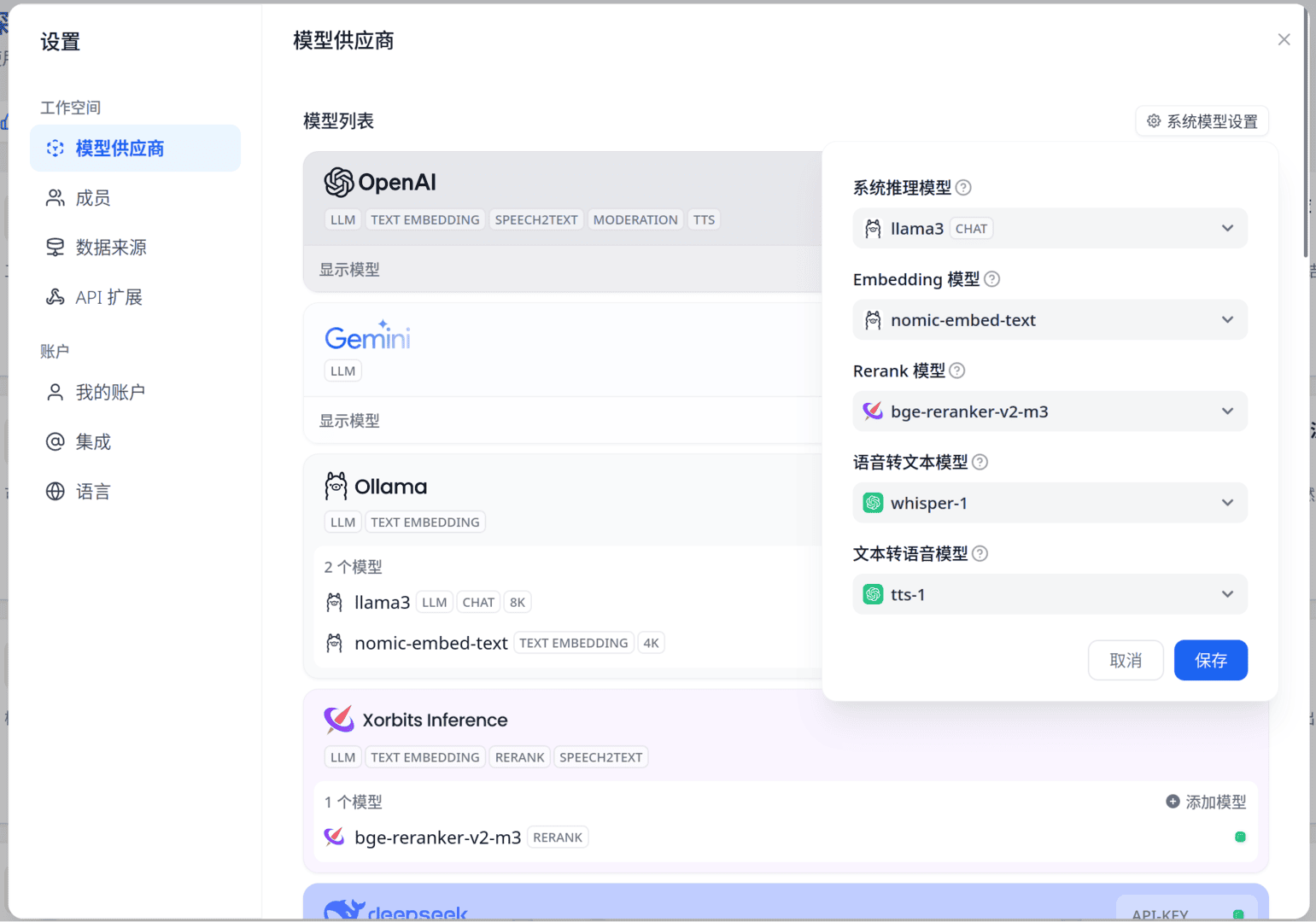
不得不承认某些问题还是得在线大模型才能回答,llama3-8B还是参数量稍微小了点
随后从模板创建一个知识库(芝士学爆!),选择多路召回以使用重排版。
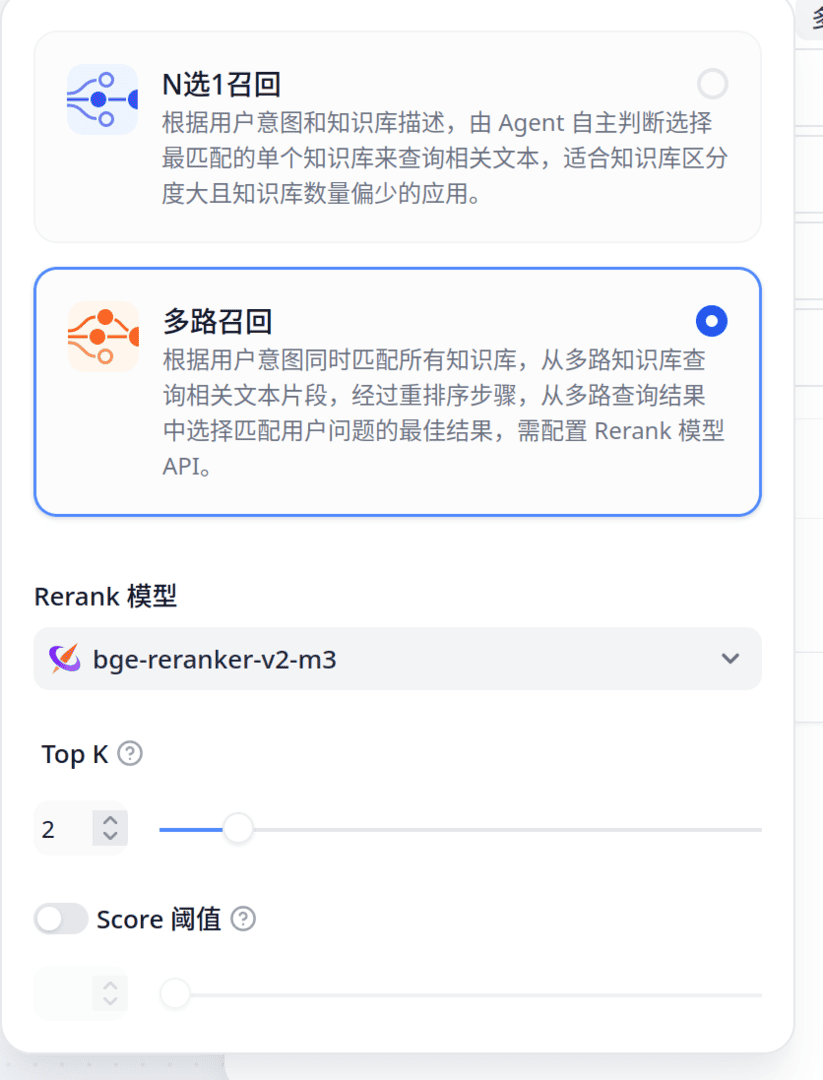
当然记得先往知识库里加点文件
重要
注意上图中N选1召回中含有一个对整个工作流默认LLM的全局选项!没想到藏在这儿
随后就尽情想用芝士学爆吧:
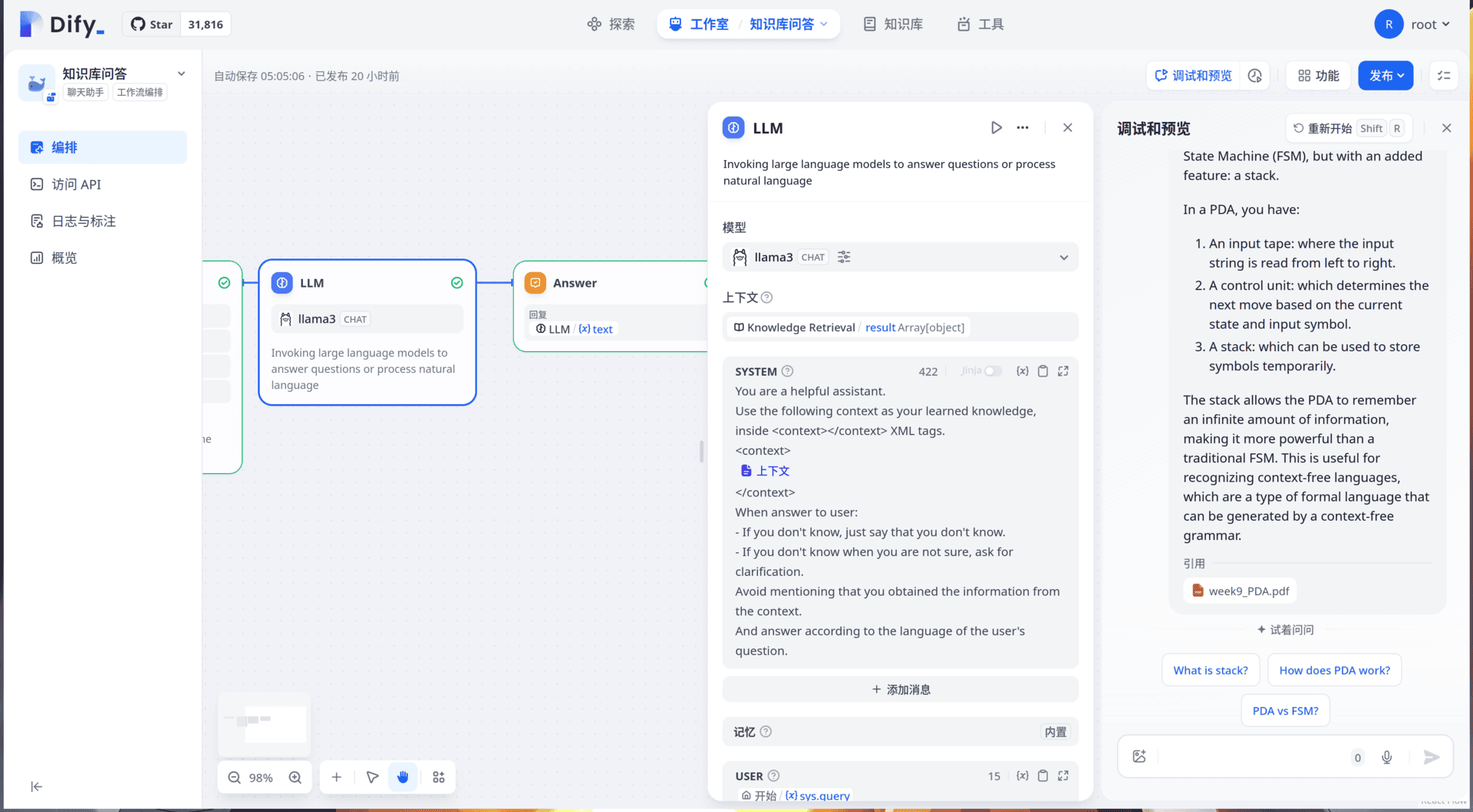
知识库很好的补全了llama3-8B的短板
题外话:对PDF文件的预处理
值得注意的是dify并没有对pdf进行预处理(例如OCR),检索一圈发现好像确实也没什么特别好的库或者方法…于是自己搓了一个,其会先对PDF中的图片进行OCR,随后处理下文本并按照原有页数输出。不过其设计的目标就是为增强知识库的索引…所以以格式pdf输出时其格式可能对人类不是特别友好(不过知识库能完全读取)。至少个人测试其效果很不错。
安装,这儿使用easyocr作为OCR引擎(当然你也可以自定义OCR函数):
pip install 'pdfdeal[easyocr]'
随后对我./PPT的文件处理下:
import os
from pdfdeal import deal_pdf
for root, dirs, files in os.walk("./PPT"):
for file in files:
file_path = os.path.join(root, file)
deal_pdf(
input=file_path, output="pdf", language=["en"], path="./Output", GPU=True
)
print(f"Deal with {file_path} successfully!")
题外话:电子邮件
鉴于LLM(大型语言模型)、向量编码和重排版模型都能在本地运行,这引发了一个思考:是否可以将一些包含隐私信息的文件,比如电子邮件,也整合到知识库中?这个想法看起来是可行的,我计划在未来找时间进一步研究这个问题。
电子邮件整合到知识库的可行性
目前,LLM、向量编码和重排版模型的本地运行能力为电子邮件等隐私文件的整合提供了可能。这是一个值得探索的方向,我将在未来的研究中进一步探讨其可行性和实施细节。
后续研究计划
-
技术研究:研究如何安全地将电子邮件等隐私文件整合到知识库中,同时确保数据的安全性和隐私性。
-
安全性考量:探讨在整合过程中如何保护用户数据不被泄露,包括使用加密技术和访问控制等措施。
-
用户体验:考虑如何优化用户体验,使得用户能够方便地管理和检索他们的电子邮件等隐私文件。
结论
将电子邮件等隐私文件整合到知识库中是一个有前景的想法,需要进一步的技术研究和安全性考量。我将在未来的研究中详细探讨这一主题。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/%E8%BF%90%E7%94%A8DifyXinference%E4%B8%8EOllama%E6%9E%84%E5%BB%BA%E7%9F%A5%E8%AF%86%E5%BA%93--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com