大模型 RAG 基础:信息检索、文本向量化及 BGE-M3 embedding 实践(2024) -- 知识铺 --知识铺
Published at 2024-08-04 | Last Update 2024-08-19
本文整理一些文本向量化(embedding)和信息检索的知识,它们是如今大模型生成文本时常用的技术 —— “增强检索生成”(RAG)—— 的基础:

本文详细介绍了信息检索技术的发展阶段、不同类型的文本向量化(embedding)技术,以及如何将这些技术应用于增强检索生成(RAG)模型。以下是文章内容的结构化总结:
信息检索技术发展阶段
信息检索技术的发展可以分为三个阶段:
- 基于统计信息的关键字匹配(1970s-2010s)
-
Sparse Embedding:大部分字段为0的向量表示。
-
典型算法:TF-IDF、BM25。
- 基于深度学习的上下文和语义理解
-
Dense Embedding:大部分字段非零的向量表示。
-
关键技术:Word2Vec(2013年)、BERT(2019年)。
- 学习型表示:结合稀疏表示和深度学习的优点。
- Learned Sparse Embedding:结合上下文语义和稀疏表示。
三种Embedding技术的对比
- Sparse Embedding (Lexical Matching)
- 适用于关键词匹配任务。
- Dense Embedding (例如BERT-based)
- 适用于语义搜索任务。
- Learned Sparse Embedding
- 结合了稀疏表示的精确度和密集表示的语义丰富性。
BERT工作原理详解
BERT模型基于Transformer架构,通过self-attention机制捕捉单词间的关联性,输出dense vector,用于语义搜索。
BGE-M3模型
BGE-M3是一种基于BERT的learned sparse embedding模型,通过以下步骤生成稀疏向量:
-
Token Importance Estimation:评估每个token的重要性。
-
线性变换:计算每个token的重要性权重。
-
激活函数:使用ReLU激活函数增强稀疏性。
RAG技术应用
RAG技术通过以下步骤增强大模型的文本生成效果:
- 搭建高质量文档数据库,并进行embedding。
- 针对用户输入进行数据库检索,寻找最相似的文本段落。
- 将找到的文本段落用于辅助大模型生成最终输出文本。
总结
本文概述了信息检索技术的发展、不同类型的文本向量化技术,以及如何将这些技术应用于RAG模型,以提高文本生成的质量和相关性。
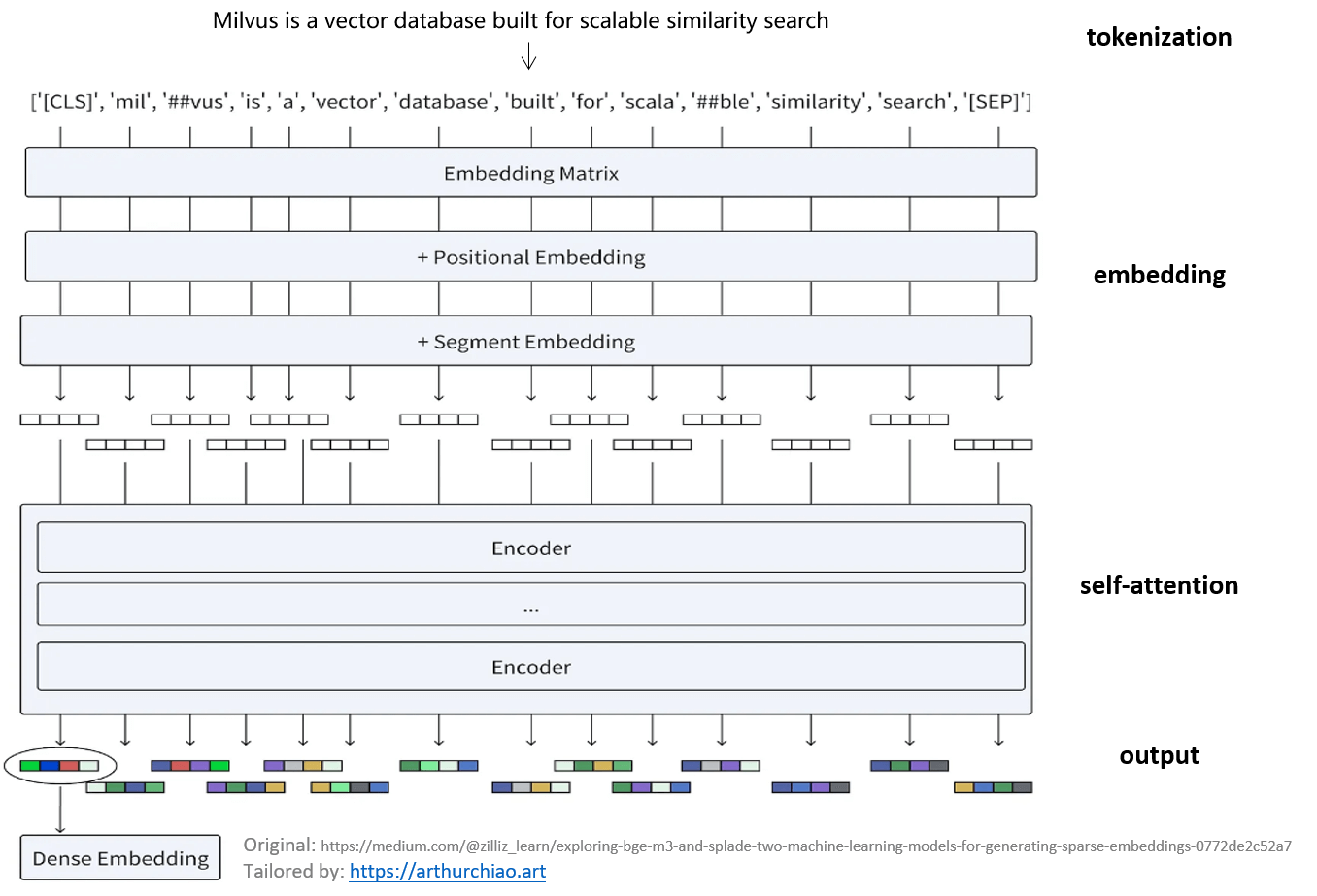
BERT Dense Embedding 的生成过程
BERT (Bidirectional Encoder Representations from Transformers) 是一种预训练的深度学习模型,它通过多层 Transformer 编码器来生成文本的密集向量表示。以下是 BERT 如何生成 dense embedding 的步骤:
1. Tokenization
-
输入文本到 tokens:首先,原始文本被分解成一系列称为 tokens 的单元,这些是文本的基本组成单位。
-
添加特殊 token:在 token 序列的开始处添加
[CLS]token,用于句子级别的分类任务,在需要时还可以用[SEP]token 来分隔不同的句子。
2. Embedding
- 转换为向量:每个 token 被映射到一个高维向量空间中的点,这是通过预先训练好的 embedding matrix 完成的。
3. Encoding
- 上下文编码:这些向量通过由多个堆叠的 Transformer 编码器层处理,每层包含 self-attention 机制和前馈神经网络。这个过程允许模型基于整个序列的信息来更新每个 token 的向量表示。
4. Output
- 输出 dense embeddings:经过编码后的结果是一系列最终的 embedding vectors,它们捕捉了单个单词的意义以及其在整个句子中的关系。
基于 BERT Dense Embedding 的信息检索
一旦有了文本的 dense embedding,就可以使用它们来进行高效的信息检索。例如,要找到与给定查询最相关的文档,可以计算查询的 embedding 与文档库中所有文档的 embeddings 之间的相似度(如余弦相似度),然后选择相似度最高的文档作为检索结果。
句子相似度判断
- 判断两个句子的相似度也遵循同样的原理:将两个句子分别转化为 BERT embeddings,然后比较这两个向量间的距离或相似度得分。

BGE-M3是一种基于BERT的稀疏嵌入模型,它通过精细的方法捕捉每个token的重要性。该模型的设计和特点包括:1. Token importance estimation:与BERT只关注第一个token([CLS])不同,BGE-M3关注序列中的每个token Hi;2. 线性变换:在编码器的输出层上增加一个线性层,计算每个token的importance weights Wlex;3. 激活函数:Wlex和Hi的乘积经过Rectified Linear Unit (ReLU)激活函数,得到每个token的术语权重Wt。ReLU的结果是非负的,有助于embedding的稀疏性。4. Learned sparse embedding:以上输出的是一个sparse embedding,其中每个token都有一个相关的weights,表明在整个输入文本上下文中的重要性。

BGE-M3 实战
4.1 相似度判断(检索)
在BGE-M3模型中,用于生成嵌入的方法能够支持不同类型的检索方式。具体而言,在M3-Embedding框架下:
-
[CLS]标记的嵌入被用来进行密集检索。 -
其他标记的嵌入则用于稀疏检索以及多向量检索。 这种设计允许模型更有效地处理信息检索任务,通过结合密集和稀疏两种检索方式的优点,提升了检索的准确性和效率。对于希望利用BGE-M3模型执行相似度判断或检索应用的开发者来说,理解这一点是非常重要的。
$ pip install FlagEmbedding peft sentencepiece
来自官方的代码,稍作修改:
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('/root/bge-m3', use_fp16=True)
queries = ["What is BGE M3?",
"Defination of BM25"]
docs = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
query_embeddings = model.encode(queries, batch_size=12, max_length=8192,)['dense_vecs']
docs_embeddings = model.encode(docs)['dense_vecs']
similarity = query_embeddings @ docs_embeddings.T
print(similarity)
这个例子是两个问题,分别去匹配两个答案,看彼此之间的相似度(四种组合),运行结果:
[[0.626 0.348 ]
[0.3499 0.678 ]]
- 问题 1 和答案 1 相似度是 0.6265
- 问题 2 和答案 2 相似度是 0.678
- 问题 1 和答案 2,以及问题 2 和答案 1,相似度只有 0.3x
符合预期。
4.2 精调(fine-tune)
精调的目的是让正样本和负样本的分数差变大。
4.2.1 官方文档
4.2.2 训练数据格式及要求
- 文件为
jsonl格式,每行一个 sample; - 每个 sample 的格式:
{"query": str, "pos": List[str], "neg":List[str]}query:用户问题;pos:正样本列表,简单说就是期望给到用户的回答;不能为空,也就是说必需得有正样本;neg:负样本列表,是避免给到用户的回答。- 空要写成
"neg": [""],写"neg": []会报错。 - 另外为空时试过删掉
"neg": []也不行,必须得留着这个字段。
- 空要写成
注意:
- 不是标准 json 格式,所以 python 直接导出一个 json 文件作为训练数据集是不行的。
- sample 不能分行,一个 sample 一行。
4.2.3 精调命令及参数配置
从 huggingface 或国内的 modelscope 下载 BGE-M3 模型,
$ git lfs install
$ git clone https://www.modelscope.cn/Xorbits/bge-m3.git
精调命令:
$ cat sft.sh
#!/bin/bash
num_gpus=1
output_dir=/root/bge-sft-output
model_path=/root/bge-m3
train_data=/data/share/bge-dataset
batch_size=2
query_max_len=128 # max 8192
passage_max_len=1024 # max 8192
torchrun --nproc_per_node $num_gpus \
-m FlagEmbedding.BGE_M3.run \
--output_dir $output_dir \
--model_name_or_path $model_path \
--train_data $train_data \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size $batch_size \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len $query_max_len \
--passage_max_len $passage_max_len \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--same_task_within_batch True \
--save_steps 10000 \
--unified_finetuning True \
--use_self_distill True
参数配置注意事项
1. Query 和 Document 的最大长度
-
query_max_len:支持的最长 query,最大值为8192。 -
passage_max_len:支持的最长文档(一条 pos 或 neg 记录)长度,最大值为8192。 这两个参数对应 tokenizer 的max_length,tokenizer 最大支持长度为 8192(参考模型目录下的tokenizer_config.json)。
2. 并行度配置
batch_size:直接影响显存占用大小和精调速度。 BGE-M3 运行时显存占用是恒定的,可以尝试不同的 batch size 配置,以充分利用显存。
3. 保存 Checkpoint 的频率
save_steps:多少个 step 保存一次 checkpoint,默认值 500 可能太小,每个 checkpoint 大小约为~7GB,过多可能导致磁盘空间不足。 精调速度取决于 GPU 算力、显存和参数配置,精调开始后会显示预估完成时间,通常较为准确。
4. 测试精调效果
使用 4.1 节的代码,稍作修改,针对每个 query 和 pos/neg 计算相似度得分,然后对测试集进行测试,观察相似性分数是否有提升。数据集质量良好时,精调后区分度会有提升。
5. CPU 运行速度优化
5.1 将模型转换为 ONNX 格式
在 CPU 上运行模型时,根据 BERT 工程经验,转换为 ONNX 格式后速度可提升数倍,尤其是在 Intel CPU 上(Intel 公司对社区库进行了优化合并)。 尽管 BGE-M3 官方没有提供转 ONNX 的文档,但根据第三方库 第三方库 可以成功转换(需要稍微修改代码,从本地加载模型),效果待验证。
6. rerank 增强
6.1 rerank/reranker 介绍
rerank 意为“重新排序”,对 embedding model 检索得到的多个结果重新计算相似性分数,给出排名。这是一个可选模块,用于增强检索结果,返回相似度最高的结果给用户。
6.2 另一种相似度模型
reranker 是一类计算相似度的模型,例如 这个列表 中的模型。
-
bge-reranker-v2-m3:与 bge-m3 配套的 reranker。
-
bge-reranker-v2-gemma:与 google gemma-2b 配套的 reranker。 这些模型的原理与 BGE-M3 这种
embedding model有所不同。
6.3 cross-encoder vs. bi-encoder
以两个句子的相似度检测为例,cross-encoder 和 bi-encoder 有不同的工作原理。
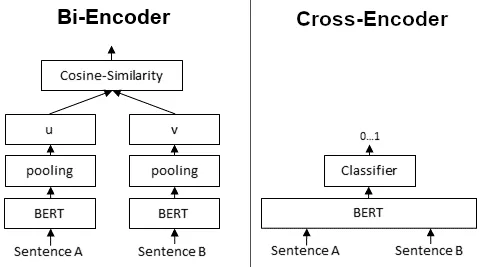
Fig. bi-encoder embedding model vs. cross-encoder model. Image source
- BGE-M3 属于左边那种,所谓的
bi-encoder embedding model, 简单说就是两个句子分别输入模型,得到各自的embedding, 然后根据 embedding vector 计算相似度; - reranker 属于右边那种,所谓的
cross-encoder model,直接得到结果; 如果对 BERT 的工作原理比较熟悉(见 BERT paper),就会明白这其实就是 BERT 判别两个句子 (next sentense prediction, NSP)任务的延伸。
5.2 embedding 和 reranker 工作流
- 用户输入
query和 doc 列表doc1/doc2/doc3/..., - BGE-M3 计算相似分,返回 topN,例如
[{doc1, score1}, {doc2, score2}, {doc3, score3}],其中score1 >= score2 >= score3, - reranker 接受
query和 BGE-M3 的结果,用自己的模型重新计算query和doc1/doc2/doc3的相似度分数。
5.3 BGE-M3 得到相似分之后,为什么要通过 reranker 再计算一遍?
这里可能有个疑问:step 2 不是已经检索出最相关的 N 个 doc 了吗? 为什么又要进入 step3,用另外一个完全不同的模型(reranker)再计算一种相似分呢?
简单来说,embdding 和 rerank 都是 NLP 中理解给定的两个句子(或文本片段)的关系的编码技术。 再参考刚才的图,
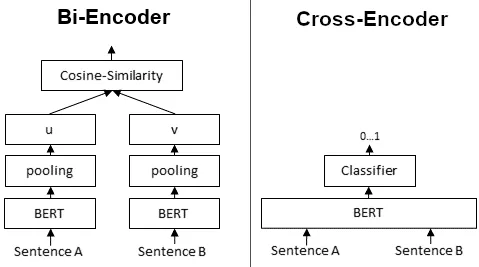
本文探讨了两种常见的文本嵌入模型:双编码器(bi-encoder)和交叉编码器(cross-encoder)。这两种模型在处理文本相似度任务时各有特点。
双编码器(Bi-Encoder)
双编码器模型分别对两个句子进行编码,生成两个独立的嵌入向量,然后计算这两个向量之间的相似度。这种方法的优点是速度快,因为只需要对每个句子单独编码一次。然而,由于它没有考虑两个句子之间的交互关系,其准确性相对较低。
交叉编码器(Cross-Encoder)
交叉编码器模型则不同,它在编码过程中同时考虑两个句子,输出一个相似度分数。这意味着两个句子是彼此依赖的,它们被“合并”成一个句子进行编码。这种方法的准确性较高,但速度较慢,因为它需要更多的计算资源来处理两个句子的交互信息。
总结
总的来说,双编码器模型适用于快速粗排的场景,而交叉编码器模型更适合于需要高精度的细排场景。理解这两种模型的差异对于选择合适的文本相似度计算方法至关重要。
参考资料


- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/202410/%E5%A4%A7%E6%A8%A1%E5%9E%8B-RAG-%E5%9F%BA%E7%A1%80%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2%E6%96%87%E6%9C%AC%E5%90%91%E9%87%8F%E5%8C%96%E5%8F%8A-BGE-M3-embedding-%E5%AE%9E%E8%B7%B52024--%E7%9F%A5%E8%AF%86%E9%93%BA--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com